
https://github.com/kohaku-lab/KohakuRAG
KohakuRAG: A simple RAG framework with hierarchical document indexing
https://arxiv.org/pdf/2603.07612一、RAG的三大痛点
检索增强生成(RAG)已成为解决大模型幻觉和知识时效性的标准方案,但在高精度引用场景中,传统RAG面临三重挑战:
| 痛点 | 具体问题 |
|---|---|
| 结构丢失 | 扁平分块破坏文档层级,难以精准定位引用来源 |
| 词汇鸿沟 | 用户问"PUE",文档写"power usage effectiveness",单查询检索漏检 |
| 答案不稳定 | 单次推理结果随机波动,引用选择不一致 |
WattBot 2025挑战赛 正是检验这些痛点的试金石:32篇AI能耗技术文档(约50万token),回答300道技术问题,要求数值误差≤0.1%、引用精确、证据不足时主动弃权。KohakuRAG以0.861分夺得公私榜双第一,且是唯一保持双榜第一的团队。
二、方案:三层架构破解难题
KohakuRAG提出层次化索引 + 多查询检索 + 集成推理的三层架构:
2.1 层次化索引:保留文档结构
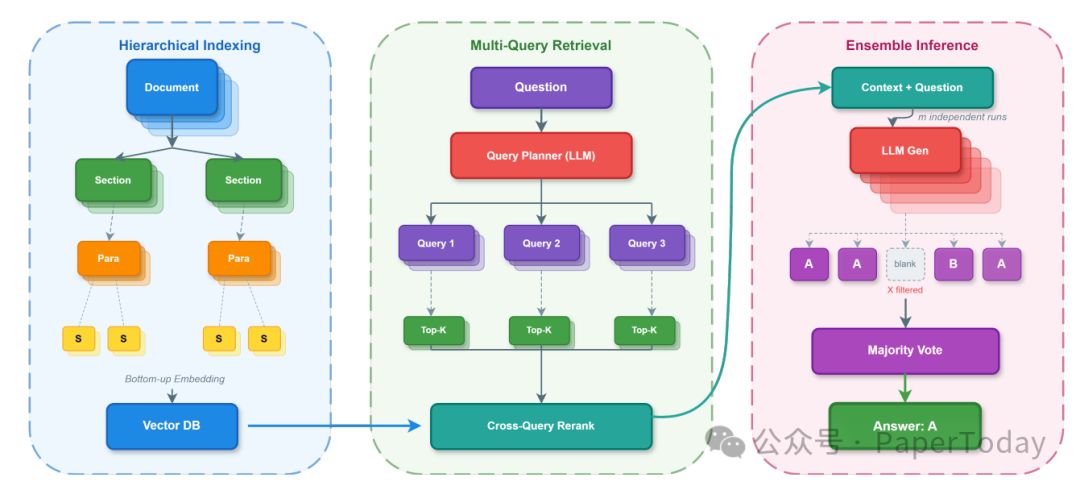
将文档解析为四级树结构(文档→章节→段落→句子),自底向上聚合embedding:
-
句子节点:直接编码
-
上层节点:子节点长度加权平均
优势:天然提供多粒度引用边界,段落/章节级embedding捕获组合语义。
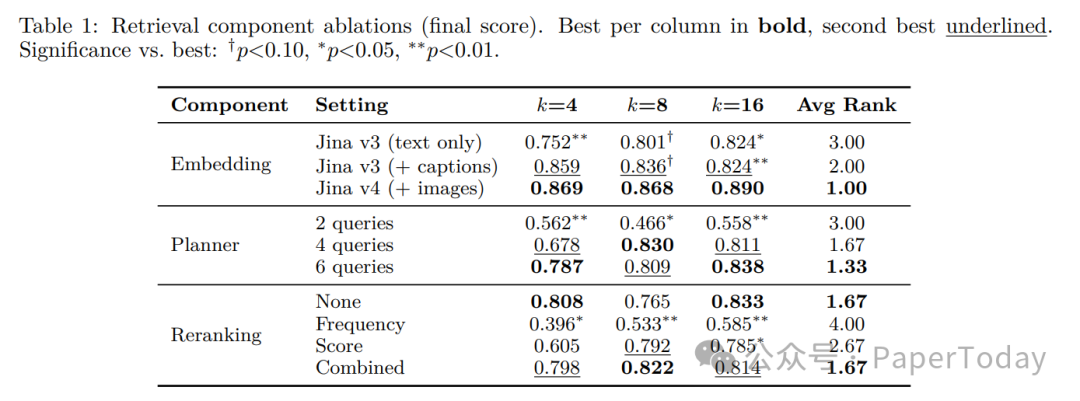
📊 Table 1 显示:Jina v4多模态embedding(+图片)在k=16时达到0.890,比纯文本提升6.6pp
2.2 多查询检索:弥合词汇鸿沟
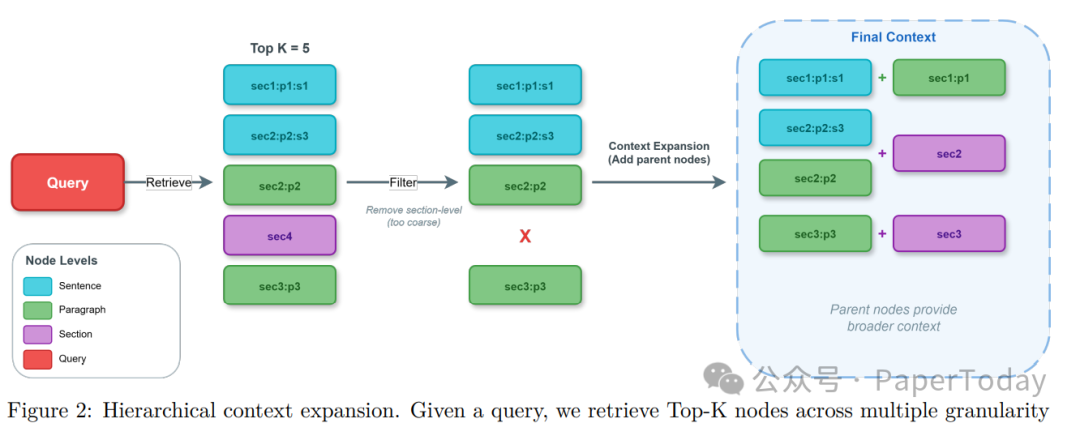
LLM查询规划器将问题扩展为n个语义相关查询(如"PUE"扩展为"Power Usage Effectiveness"、"energy efficiency ratio"),每个查询独立检索Top-K。
跨查询重排序:利用共识信号------被更多查询命中的节点排名更高。支持三种策略:
-
Frequency:按命中查询数排序
-
Score:按累计相似度排序
-
Combined:归一化后加权融合
2.3 集成推理:稳定答案输出
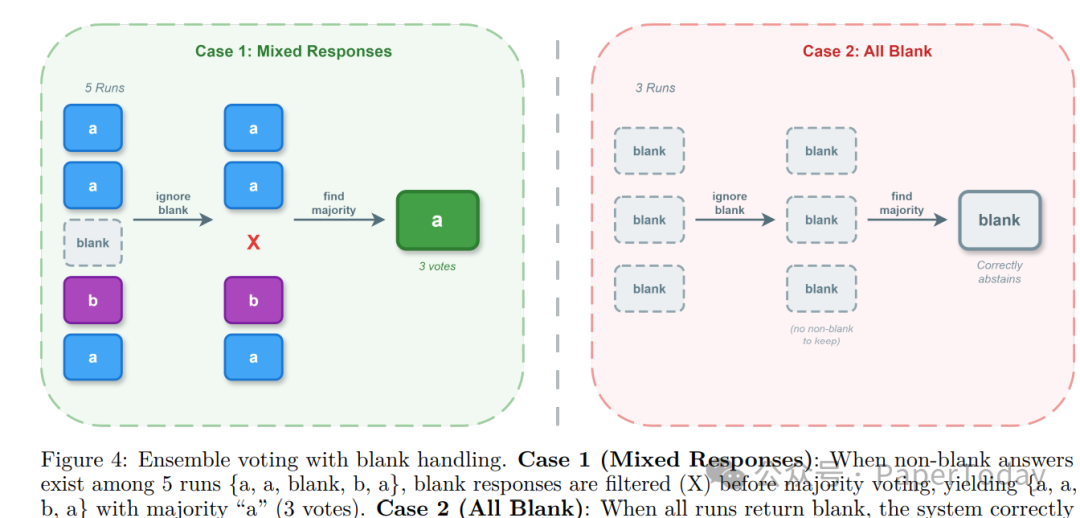
执行m次独立推理,通过弃权感知投票聚合:
-
ignore_blank=true:过滤弃权响应后再投票(防止保守运行主导)
-
AnswerPriority:先投票选答案,再从匹配答案的运行中收集引用
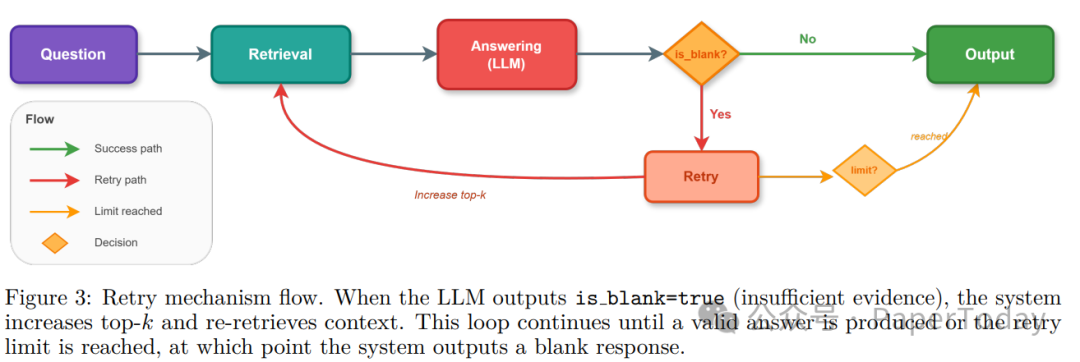
重试机制:当模型因证据不足弃权时,自动扩大Top-K重新检索,解决26.8%的"不必要弃权"错误。
三、结论:关键发现与数据验证
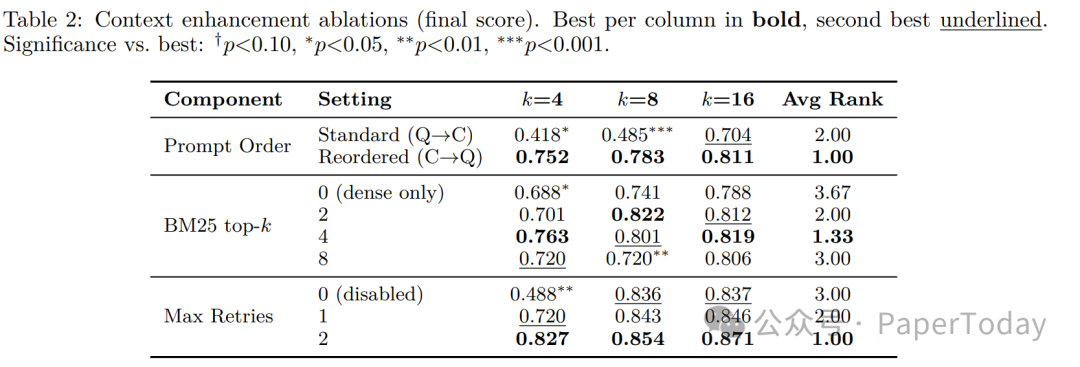
3.1 消融实验亮点
| 组件 | 关键发现 | 提升幅度 |
|---|---|---|
| Prompt重排序 | 上下文放问题前(C→Q)vs 标准顺序(Q→C) | **+80%**(k=4时0.418→0.752) |
| 重试机制 | 解决不必要弃权 | **+69%**(k=4时0.488→0.827) |
| 集成投票 | ignore_blank过滤 | +1.2pp (n=9时0.882→0.894) |
| BM25混合 | 层次化稠密检索已足够强 | 仅+3.1pp |
📊 Table 2 完整数据:Prompt重排序在k=4/8/16均显著优于标准顺序(p<0.05)
3.2 榜单表现
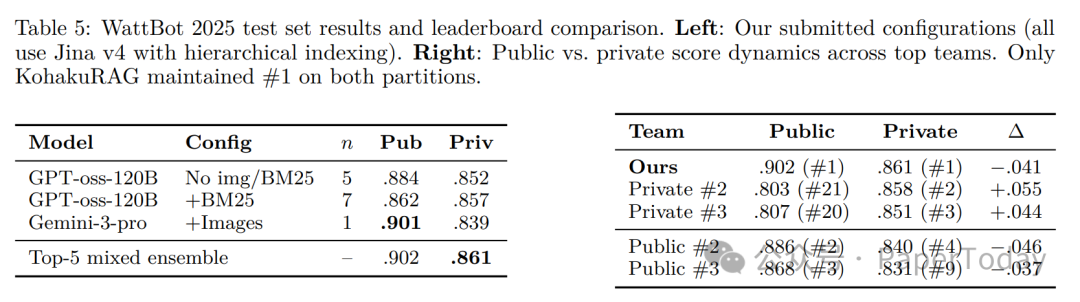
Table 5 - Leaderboard
| 配置 | 公榜 | 私榜 | 特点 |
|---|---|---|---|
| GPT-oss-120B 7-ensemble + BM25 | 0.862 | 0.857 | 最稳定(分差仅0.5%) |
| Gemini-3-pro + 图片 | 0.901 | 0.839 | 单轮最高但波动大(-6.2%) |
| Top-5混合集成 | 0.902 | 0.861 | 双榜第一 |
核心洞察:集成方法显著提升跨分布稳定性。单模型Gemini虽公榜最高,私榜暴跌6.2%;而KohakuRAG的跨模型集成融合Gemini视觉能力与GPT-oss文本理解,实现鲁棒泛化。
3.3 错误分析启示
对2,583次预测的错误分解:
-
不必要弃权(26.8%)→ 重试机制直接针对
-
引用不匹配(23.6%)→ 未来方向:引用约束解码
-
数值选择错误(22.2%)→ 需更精细的查询分解
总结
KohakuRAG证明:结构感知索引 + 多查询覆盖 + 集成稳定性是高精度RAG的三驾马车。其开源实现为技术文档问答提供了即插即用的解决方案,尤其在需要精确引用和数值准确性的场景中表现卓越。