🎵 Mimi音频神经网络编解码器:高保真声音处理的突破
在数字音频技术飞速发展的今天,音频压缩与处理领域迎来了一次重大突破。由Kyutai实验室开发的Mimi音频神经网络编解码器,以其创新的架构和卓越的性能,正在重新定义高保真音频处理的边界。本文将深入探讨这一革命性技术,从其核心原理到实际应用,带您全面了解Mimi如何将语义与声学信息巧妙融合,以极低的比特率实现惊人的音频质量。
音频编解码技术的演进与挑战
音频编解码技术自诞生以来,经历了从传统方法到现代神经网络的演变历程。传统的音频编解码器如MP3、AAC等,主要依靠信号处理技术,通过频域变换、量化编码等方式实现压缩。这些方法虽然在一定比特率下能够提供可接受的音频质量,但在极低比特率条件下往往会出现明显的失真和音质下降。
随着深度学习技术的崛起,神经网络开始被引入音频处理领域。早期的神经网络音频编解码器尝试使用深度神经网络来优化传统编码器的参数,或改进量化方法。然而,这些方法往往计算复杂度高,难以实现实时处理,且在极低比特率下仍难以保持高质量的音频还原。
Mimi的出现,标志着音频编解码技术进入了一个新的阶段。它不仅采用了先进的神经网络架构,还创新性地将语义信息和声学信息相结合,实现了在12.5Hz采样率和仅1.1kbps比特率下的高质量音频处理。
Mimi的核心架构与技术创新
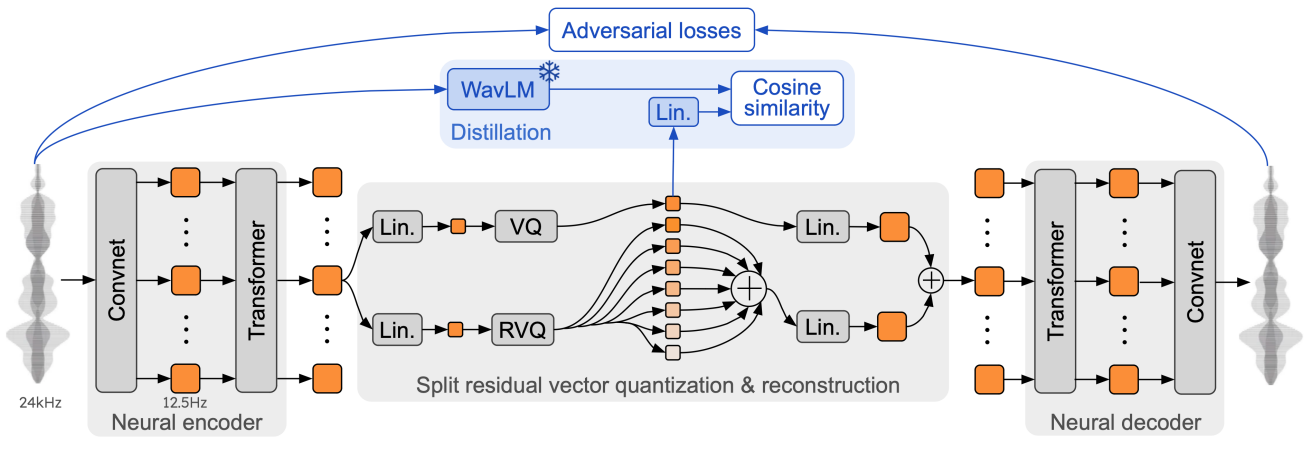
Mimi采用了一种流式编码器-解码器架构,其核心在于将复杂的音频信号转换为离散的音频令牌(audio tokens),并通过量化的潜在空间表示这些令牌。这种端到端训练的方法,使得Mimi能够学习到音频信号中的语义和声学特征,并在解码时精准还原。
关键技术特性
Mimi的架构设计体现了多项技术创新:
-
流式处理架构:与传统的块处理方式不同,Mimi采用流式处理,能够实时处理连续的音频流,这对于实时通信和交互式应用至关重要。
-
量化的潜在空间:通过将音频信号映射到离散的潜在空间,Mimi能够在保持高质量的同时实现高效压缩。
-
语义与声学信息的融合:Mimi不仅捕捉音频的声学特征,还理解其语义内容,这使得它在处理语音信号时特别有效。
-
端到端训练:整个编码-解码过程通过端到端方式训练,确保了模型各组件之间的最优协同工作。
Mimi的应用场景与优势
Mimi的高效性和高质量使其在多个领域展现出巨大潜力:
语音处理领域
Mimi特别适用于语音相关的应用,包括:
- 语音语言模型的训练
- 文本到语音(TTS)系统
- 语音通信应用
- 语音存储和传输
实时音频处理
由于其流式架构和低计算复杂度,Mimi能够实现实时音频处理,这对于以下场景尤为重要:
- 实时语音通信
- 语音助手和交互系统
- 在线会议和远程协作
- 游戏中的实时音频处理
资源受限环境
Mimi的低比特率特性使其非常适合资源受限的环境:
- 移动应用
- 物联网设备
- 低带宽网络环境
- 边缘计算设备
快速上手:使用Mimi进行音频处理
要开始使用Mimi,首先需要安装必要的Python包。以下是在Hugging Face Transformers库中使用Mimi的基本步骤:
python
# 安装必要的依赖
pip install --upgrade pip
pip install --upgrade datasets[audio]
pip install git+https://github.com/huggingface/transformers.git@main安装完成后,可以按照以下代码示例加载Mimi模型并进行音频处理:
python
from datasets import load_dataset, Audio
from transformers import MimiModel, AutoFeatureExtractor
# 加载演示数据集(来自LibriSpeech,约9MB)
librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
# 加载模型和特征提取器
model = MimiModel.from_pretrained("kyutai/mimi")
feature_extractor = AutoFeatureExtractor.from_pretrained("kyutai/mimi")
# 确保音频采样率与模型要求匹配
librispeech_dummy = librispeech_dummy.cast_column("audio", Audio(sampling_rate=feature_extractor.sampling_rate))
audio_sample = librispeech_dummy[0]["audio"]["array"]
# 预处理输入
inputs = feature_extractor(raw_audio=audio_sample, sampling_rate=feature_extractor.sampling_rate, return_tensors="pt")
# 显式编码然后解码音频输入
encoder_outputs = model.encode(inputs["input_values"])
audio_values = model.decode(encoder_outputs.audio_codes)[0]
# 或者直接使用前向传播
audio_values = model(inputs["input_values"]).audio_valuesMimi的技术细节与性能分析
Mimi的技术细节展现了其在音频处理领域的先进性。模型采用了一种创新的架构,结合了卷积神经网络和变换器的优势,能够有效地捕捉音频信号中的时序和频谱特征。
模型架构
Mimi的架构可以大致分为以下几个部分:
输入音频 → 预处理 → 编码器 → 量化 → 潜在表示 → 解码器 → 输出音频- 编码器:将原始音频信号转换为连续的表示,捕捉音频的语义和声学特征。
- 量化层:将连续的表示离散化为令牌,实现压缩。
- 解码器:从离散令牌重建高质量的音频信号。
训练数据与方法
Mimi是在大规模语音数据上训练的,这使其特别适合处理语音信号。训练过程采用了多阶段的训练策略,从简单的重建任务到更复杂的语义理解任务,逐步提升模型的能力。
性能指标
Mimi在多个音频质量评估指标上表现出色,尤其是在低比特率条件下。与传统编解码器相比,Mimi能够在相同比特率下提供显著更好的音频质量,或者在相同质量下实现更低的比特率。
实际应用案例与最佳实践
Mimi在实际应用中已经展现出其强大的能力。以下是一些典型的应用案例和最佳实践:
语音通信应用
在实时语音通信中,Mimi可以显著降低带宽需求,同时保持高质量的语音传输。以下是实现实时语音通信的基本框架:
[麦克风] → Mimi编码 → 网络传输 → Mimi解码 → [扬声器]关键点:
- 保持12.5Hz的编码速率以确保低延迟
- 使用流式处理以实现实时性
- 根据网络状况动态调整编码参数
语音合成系统
Mimi可以作为高质量语音合成系统的组件,特别是与大型语言模型结合时。以下是一个基本的语音合成流程:
python
# 伪代码:使用Mimi进行语音合成
def text_to_speech(text, model):
# 1. 使用语言模型将文本转换为语义表示
semantic_representation = language_model.encode(text)
# 2. 使用Mimi将语义表示转换为音频
audio_codes = mimi.encode(semantic_representation)
audio = mimi.decode(audio_codes)
return audio音频存储与传输
对于需要存储或传输大量音频数据的场景,Mimi可以显著减少存储空间和带宽需求。例如,一个小时的语音数据:
- 传统CD质量音频:约600MB
- 使用Mimi编码:约5MB(节省99%的空间)
未来发展与挑战
尽管Mimi已经取得了显著的成就,但音频编解码领域仍有广阔的发展空间。以下是未来可能的发展方向和面临的挑战:
技术发展方向
- 多模态扩展:将Mimi扩展到处理音频与其他模态(如视频、文本)的联合表示。
- 自适应编码:根据内容复杂度和网络状况动态调整编码参数。
- 个性化音频处理:针对特定用户或场景优化音频处理效果。
面临的挑战
- 计算效率:进一步提高模型的计算效率,使其在资源受限设备上也能高效运行。
- 通用性:扩展Mimi对非语音音频(如音乐、环境声音)的处理能力。
- 伦理考量:确保音频技术不被用于恶意目的,如声音伪造或隐私侵犯。
结论
Mimi音频神经网络编解码器代表了音频处理技术的一次重大飞跃。通过创新的架构和训练方法,Mimi在极低比特率条件下实现了高质量的音频处理,为语音通信、语音合成和音频存储等领域带来了新的可能性。
随着技术的不断发展和完善,Mimi有望在更多场景中发挥其优势,推动音频技术的边界。无论是对于研究人员、开发者还是最终用户,Mimi都展示了人工智能技术在音频领域的巨大潜力,预示着一个更加智能和高效的音频处理时代的到来。
飞跃。通过创新的架构和训练方法,Mimi在极低比特率条件下实现了高质量的音频处理,为语音通信、语音合成和音频存储等领域带来了新的可能性。
随着技术的不断发展和完善,Mimi有望在更多场景中发挥其优势,推动音频技术的边界。无论是对于研究人员、开发者还是最终用户,Mimi都展示了人工智能技术在音频领域的巨大潜力,预示着一个更加智能和高效的音频处理时代的到来。
要了解更多关于Mimi的信息,可以访问项目仓库获取源代码和详细文档,或者通过在线体验亲自感受Mimi的音频处理能力。对于希望下载模型或获取资源的用户,这里提供了丰富的资源和工具,帮助您快速开始使用Mimi进行音频处理。