MCU中部署TinyMaix
本笔记主要涉及的是MCU中进行部署轻量级神经网络推理模型TinyMaix
---------wosz
TinyMaix介绍
TinyMaix 是为在资源有限的 MCU 上运行 AI 神经网络 Mdoel 而设计的,TinyMaix 旨在成为一个简单的 TinyML 推理库,它放弃了许多新功能,也不使用 CMSIS-NN 这类库。
设计原则
易用性 > 移植性 > 速度 > 空间
核心特性
- 核心代码少于 400行 (
tm_layers.c+tm_model.c+arch_cpu.h) - 代码段(.text)少于 3KB
- 低内存消耗,甚至 Arduino ATmega328(32KB Flash, 2KB RAM)都能运行 MNIST
- 支持 INT8/FP32/FP16 模型,实验性支持 FP8 模型
- 支持多种芯片架构的专用指令优化:ARM SIMD/NEON/MVEI,RV32P, RV64V
- 支持全静态的内存配置(无需 malloc)
核心技术架构
三层架构设计
TinyMaix 采用清晰的三层架构,实现了代码的高度模块化和可移植性:
┌─────────────────────────────────────────────────┐
│ 模型管理层 (tm_model.c) │
│ - tm_load() : 加载模型到内存 │
│ - tm_run() : 执行推理 │
│ - tm_unload() : 卸载模型 │
│ - tm_preprocess(): 输入数据预处理 │
├─────────────────────────────────────────────────┤
│ 算子实现层 (tm_layers.c) │
│ - tml_conv2d_dwconv2d() : 卷积/深度卷积 │
│ - tml_fc() : 全连接层 │
│ - tml_gap() : 全局平均池化 │
│ - tml_softmax() : Softmax激活 │
│ - tml_reshape() : 形状变换 │
│ - tml_add() : 残差连接 │
├─────────────────────────────────────────────────┤
│ 架构优化层 (arch_xxx.h) │
│ - tm_dot_prod() : 点积运算 │
│ - tm_dot_prod_pack2() : 双通道并行点积 │
│ - tm_postprocess_sum() : 后处理(激活+量化) │
│ - tm_dot_prod_3x3x1() : 3x3卷积优化 │
└─────────────────────────────────────────────────┘架构优势:
- 模型管理层:提供统一的 API 接口,用户只需调用 load/run 即可
- 算子实现层:实现神经网络的各种层运算,与具体硬件无关
- 架构优化层:针对不同 CPU 架构提供 SIMD 加速实现,通过宏切换
支持的架构:
arch_cpu.h:纯 C 实现,适用于所有平台arch_arm_simd.h:ARM Cortex-M4/M7 的 SIMD 指令arch_arm_neon.h:ARM Cortex-A 系列的 NEON 指令arch_arm_mvei.h:ARMv8.1-M 的 MVE 指令arch_rv32p.h:RISC-V 32位 P 扩展arch_rv64v.h:RISC-V 64位向量扩展arch_x86_sse2.h:x86 SSE2 指令集
INT8 量化技术
量化是 TinyMaix 实现极低内存占用的核心技术,将 FP32 模型压缩为 INT8,内存和计算量减少 4倍。
量化原理
量化公式:
real_value = scale × (quantized_value - zeropoint)scale:缩放因子,将整数映射回浮点数范围zeropoint:零点偏移,处理非对称分布quantized_value:INT8 量化值(-128 ~ 127)
示例:
c
// 量化:FP32 -> INT8
int8_t quant = (int8_t)(fp32_value / scale + zeropoint);
// 反量化:INT8 -> FP32
float dequant = (quant - zeropoint) * scale;Per-Channel 量化
TinyMaix 采用 Per-Channel 量化策略,每个输出通道有独立的 scale:
c
// 每个输出通道独立的权重scale
for(int c = 0; c < out->c; c++) {
sumscale[c] = ws[c] * in_s; // ws[c]是该通道的权重scale
}优势:
- 精度更高:不同通道的权重分布可能差异很大
- 灵活性强:可以针对每个通道优化量化参数
Bias 预融合优化
在模型转换时,将 zeropoint 的影响预先融合到 bias 中:
c
// 预融合公式(转换时计算)
bias_fused[c] = bias[c] + (-out_zp) × sum(weights[c])
// 运行时直接使用融合后的bias
sum += bias_fused[c];好处:减少运行时计算开销,无需每次都计算 zeropoint 的影响。
FASTSCALE 定点优化
针对无 FPU 的 MCU,TinyMaix 提供定点数优化:
c
#if TM_FASTSCALE
// 用移位代替浮点除法
int32_t outscale = (1 << TM_FASTSCALE_SHIFT) / out_s;
sumtype_t sumf = (sum << TM_FASTSCALE_SHIFT) / scales[i];
outp[i] = (mtype_t)(((sumf * out_s) >> (SHIFT + SHIFT)) + out_zp);
#else
// 标准浮点运算
float sumf = sum * scales[i];
outp[i] = (mtype_t)(sumf / out_s + out_zp);
#endif性能提升 :在无 FPU 的芯片上可提速约 1/3,但会略微降低精度。
Ping-Pong Buffer 内存管理
Ping-Pong Buffer 是 TinyMaix 实现极低内存占用的关键技术,通过复用内存空间,最小化运行时 RAM 需求。
基本原理
神经网络的层间数据流是单向的,当前层的输出成为下一层的输入,因此可以复用内存:
Layer 0: Conv2D
输入: buf[0:784] (28×28×1 = 784 bytes)
输出: buf[784:1464] (13×13×4 = 680 bytes)
Layer 1: Conv2D
输入: buf[784:1464] ← 复用 Layer 0 的输出
输出: buf[0:288] ← 复用 Layer 0 的输入空间
Layer 2: Conv2D
输入: buf[0:288] ← 复用 Layer 1 的输出
输出: buf[1400:1464] ← 使用新的空间内存布局示意:
时刻 T0 (Layer 0 执行):
[========Input========][======Output======][........]
0 784 1464 buf_size
时刻 T1 (Layer 1 执行):
[======Output======]...[========Input========]
0 288 784 1464
时刻 T2 (Layer 2 执行):
[====Input====]..................[==Output==]
0 288 1400 1464模型转换时的内存规划
TinyMaix 的模型转换工具会自动计算最优的内存布局:
python
# tflite2tmdl.py 转换输出示例
================ pack model head ================
buf_size = 1464 # 运行时需要的总缓冲区大小
================ pack layers ================
CONV_2D
in_oft:0, size:784; out_oft:784, size:680
CONV_2D
in_oft:784, size:680; out_oft:0, size:288
CONV_2D
in_oft:0, size:288; out_oft:1400, size:64内存分配策略
c
// 模型加载时一次性分配
tm_err_t tm_load(tm_mdl_t* mdl, const uint8_t* bin, uint8_t* buf, ...) {
if(buf == NULL) {
// 动态分配
mdl->buf = (uint8_t*)tm_malloc(mdl->b->buf_size);
} else {
// 使用用户提供的静态缓冲区
mdl->buf = buf;
}
}优势:
- 内存最小化:MNIST 模型仅需 1.4KB RAM
- 预计算偏移:运行时无需动态分配,零开销
- 支持静态内存:适合无 malloc 的裸机环境
- 缓存友好:数据局部性好,减少 cache miss
实际案例
MNIST 模型(手写数字识别):
- 模型大小:2.4KB(Flash)
- 运行缓冲:1.4KB(RAM)
- 可在 ATmega328(2KB RAM)上运行
移植
移植首先要保证最小的核心文件:
tinymaix.h- 主头文件(数据结构和API定义)tm_port.h- 移植配置文件(需要根据MCU修改)tm_model.c- 模型管理层tm_layers.c或tm_layers_O1.c- 算子实现层(选一个)arch_xxx.h- 架构优化层(根据MCU选择):- arch_cpu.h - 通用CPU(无SIMD)
- arch_arm_simd.h - ARM Cortex-M4/M7
- arch_arm_neon.h - ARM Cortex-A
以上就是最核心的必要文件,此外还需要我们通过Tsenflow训练生成的模型文件用于推理。
Tsenflow训练模型
我们MCU主要是处理传感器数据偏多,因此此处我们就以传感器数据为例子进行传感器数据训练模型的一个方法:
- 首先就是我们训练数据的载体采用CSV格式,方便我们对我们的数据打上标签
- 传感器数据来源主要是在我们的目标硬件上进行实时采样,对每一段数据都打上标签进行分类事件
传感器数据主要路线大致有:
- 分类:比如IMU的姿态检测
- 异常检测:比如检测电压电流的正常情况
对于分类的数据吗,我们系统正常运行采集即可获得数据进行具体的分配标定,但是对于异常检测,异常运行的情况毕竟是少数这个时候就需要采用合适的手段进行处理了。
- 正常/异常二分类
- 训练集要有 normal 和 abnormal 标签
- 异常数据来源:真实故障、故障注入(手动添加异常)
- 训练后直接输出异常概率,评估更直观
- 只用正常数据建模
- 训练集只放"确认正常"的数据;模型学习正常模式
- 推理时算异常分数(重构误差/预测误差),超过阈值就报警。
- 阈值一般用正常验证集分数的 P99~P99.9,再加"连续 K 窗超阈值"防抖
下面以一部分数据进行IMU姿态检测为例子训练模型**(imu_pose_dataset_ax_ay_az.csv)下面只贴部分数据**
| sample_id | ax | ay | az | label |
|---|---|---|---|---|
| 1 | 0.009 | -0.0086 | 0.9662 | flat_up |
| 179 | 0.0483 | 0.036 | -0.9721 | flat_down |
| 321 | 0.0024 | 1.0086 | -0.0027 | left_side |
| 452 | 0.0104 | -1.0545 | 0.03 | right_side |
| 612 | 0.9573 | 0.0079 | -0.0126 | nose_up |
| 759 | -1.0396 | 0.0043 | -0.05 | nose_down |
| 913 | 0.7547 | -0.0343 | 0.7425 | tilt_front_45 |
| 1053 | -0.6635 | -0.029 | 0.6394 | tilt_back_45 |
1)数据预处理
- 丢掉 sample_id,只用 ax, ay, az
- 把 label 映射成数字 id(保存映射表,部署要用)
2)python脚本运行TensorFlow训练模型,生成.h5文件
3)运行官方提供的h5_to_tflite.py脚本转换.h以及.tml
最后只需要以下文件即可(其中arch_cpu.h可以进行替换对应的进行加速操作)

之后我们可以先在PC端先进行模型测试一下正确性再进行移植
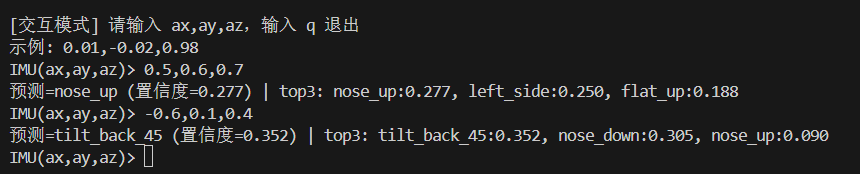
置信度越高,则模型认为越自信,可信度就越高,但是也不一定正确,因此可以采用再实际运行中采用多帧确认或者修改数据样本进行或者添加更多的数据样本以增加模型的识别精度。
MCU移植
将上述的核心文件移植到对应的MCU中去对接一下接口,即可进行使用,下面简单进行一下演示。
首先需要修改一下tm_port.h中关于时钟的获取,原本的版本是Linux端下的,我们MCU直接提供滴答定时器或者使用DWT给一个获取微秒的时间戳也可以。
c
#include <sys/time.h>
#include <time.h>
#define TM_GET_US() ((uint32_t)((uint64_t)clock()*1000000/CLOCKS_PER_SEC))然后还有一个问题就是语法兼容问题可能存在,我们的TinyMaix使用的是GNU模式,因此我们这边需要开启相关的GNU扩展(在Keil中可以 Options for Target -> C/C++ -> GNU Extensions (--gnu)进行打开。
运行模型
-
配置TinyMaix运行参数,保持一致性
-
在
tm_Port.h中保持模型量化一致性c#define TM_MDL_TYPE TM_MDL_INT8
-
-
初始化模型
-
调用
tm_load加载模型c/* &mdl:模型运行句柄(上下文),后续 tm_run 要用它。 mdl_data:模型二进制数据(就是你头文件里的模型数组)。 mdl_buf:推理中间缓冲区(工作内存),大小要满足 MDL_BUF_LEN。 NULL:层回调函数(可选);传 NULL 表示不做逐层调试回调。 &in:返回模型输入张量描述(形状+输入缓冲指针),后续预处理会写到这里。 */ tm_mdl_t mdl; tm_mat_t in, outs[1]; uint8_t mdl_buf[MDL_BUF_LEN] __attribute__((aligned(8))); tm_load(&mdl, mdl_data, mdl_buf, NULL, &in);
-
-
准备输入数据
-
将我们的传感器数据转化成为模型的输入
c//dims=1, h=1, w=1, c=3,也就是一个 1x1x3 的向量,由生成的模型定义 tm_mat_t in_fp = {1,1,1,3,{0}}; //或者tm_mat_t in_fp = {in.dims, in.h, in.w, in.c, {0}}; in_fp.dataf = x_raw;
-
-
模型运行和预处理
-
预处理
ctm_preprocess(&mdl, TMPP_FP2INT, &in_fp, &in); -
运行模型
ctm_run(&mdl, &in, outs); //将模型的输出到outs -
获取模型输出
cfloat *p = outs[0].dataf; //或者模型的输出概率结果输出的结果就是模型认为当前输入更像哪个类别,以及"像到什么程度"。此时我们就可以利用这个概率进行一个概率排序以及阈值判定进行一个结果判断。
-
IMU示例:
c
#include "bno085x_app.h"
#include "tinymaix.h"
#include "imu_pose_int8.h"
#include "myusart.h"
extern I2C_HandleTypeDef hi2c1;
extern UART_HandleTypeDef huart1;
float ax,ay,az;
static tm_mdl_t mdl;
static tm_mat_t in, outs[1];
static uint8_t mdl_buf[MDL_BUF_LEN] __attribute__((aligned(8)));
static float x_raw[3];
void bno85x_app_init(void)
{
BNO080_Init(&hi2c1,0x4B);
softReset();
enableAccelerometer(100);
tm_load(&mdl, mdl_data, mdl_buf, NULL, &in);
}
void imu_data(void)
{
if(dataAvailable())
{
ax=getAccelX();
ay=getAccelY();
az=getAccelZ();
x_raw[0] = ax;
x_raw[1] = ay;
x_raw[2] = az;
tm_mat_t in_fp = {1,1,1,3,{0}};
in_fp.dataf = x_raw;
if (tm_preprocess(&mdl, TMPP_FP2INT, &in_fp, &in) != TM_OK) return;
if (tm_run(&mdl, &in, outs) != TM_OK) return;
float *p = outs[0].dataf; // 8类概率
uart_printf(&huart1, "flat_down:%f,flat_up:%f,left_side:%f,nose_down:%f\r\n", p[0], p[1], p[2], p[3]);
uart_printf(&huart1, "nose_up:%f,right_side:%f,tilt_back_45:%f,tilt_front_45:%f\r\n", p[4], p[5], p[6], p[7]);
}
}