引言:从"手工作坊"到"工业革命"
在人工智能的技术演进史上,有一场常被忽视却至关重要的革命------它不发生在算法的数学推导中,也不发生在硬件的算力飞跃里,而是发生在数据如何处理、特征如何提取的根本方法论上。
在传统的机器学习时代,数据科学家常被戏称为"特征工程民工"。他们的工作日常充斥着数据清洗、缺失值填充、特征变换和复杂的特征组合。这个过程高度依赖领域专家的经验,不仅耗时耗力,且充满了试错的偶然性。曾有业界共识:特征工程决定了模型效果的上限,而算法只是在无限逼近这个上限。
然而,深度学习的崛起彻底颠覆了这一范式。它宣布:让算法自己去学习特征,人类不再需要手把手教机器什么是"耳朵尖"、"尾巴长" 。这不仅仅是效率的提升,更是一场思维方式的革命------从"特征工程"到"特征学习"的跃迁。
本文将深入剖析这场革命的前世今生,带你理解机器学习为何依赖人工特征,深度学习如何实现自动特征提取,以及在未来,这两者将走向怎样的融合。
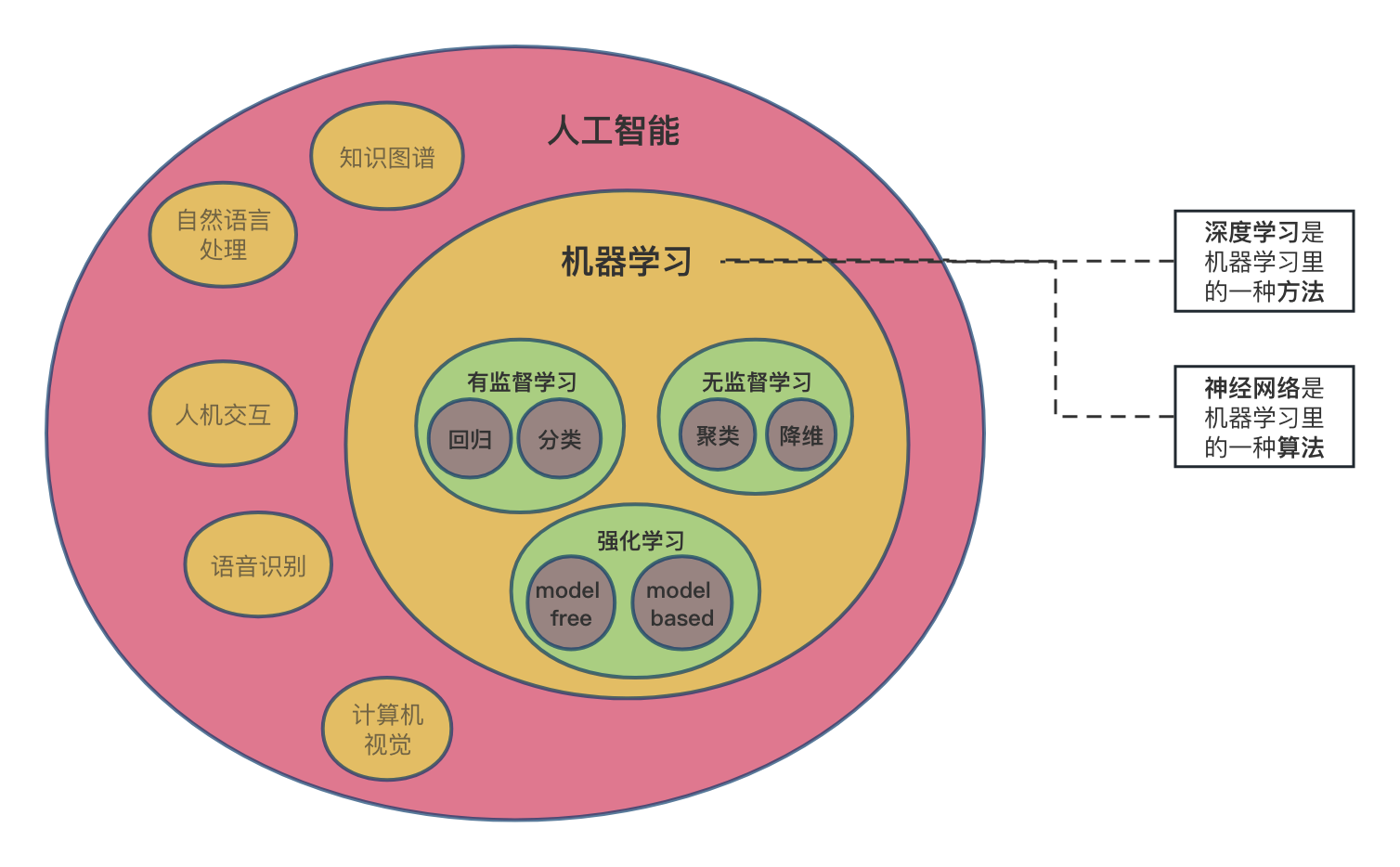
一:前深度学习时代------机器学习的"手工作坊"
1.1 什么是机器学习?
要理解这场革命,首先得明白什么是机器学习。与传统的"规则驱动"编程不同,机器学习是"数据驱动"的。传统编程是程序员写下 if-else 逻辑,告诉计算机在各种情况下该做什么;而机器学习则是将大量数据(包括输入和输出)喂给算法,让算法自己总结出规律,生成一个模型。当有新的数据输入时,这个模型负责输出预测结果。
例如,要识别一封邮件是否为垃圾邮件,传统编程可能需要写100条规则:包含"中奖"关键词、发件人不在通讯录、含有可疑链接等。而机器学习只需要提供10万封已标记好的邮件(是垃圾邮件或不是),算法便能自动归纳出垃圾邮件的"模样"。
1.2 特征工程:机器学习的"支柱"
然而,早期的机器学习算法非常"笨拙"。它们无法直接处理原始数据,比如像素点、文本字符串或音频波形。它们只能理解数字,而且最好是结构化的、分布良好的数字。
这就催生了特征工程。特征工程是将原始数据转化为能更好表示潜在问题特征的过程,目的是提高模型的预测准确性。这就好比为一位侦探(算法)准备案件材料。你不能直接把一堆杂乱无章的现场照片扔给他,而是需要整理出清晰的时间线、嫌疑人的通话记录、现场的指纹编号等关键线索。
在实际应用中,这意味着:
-
图像识别:我们需要定义图像的边缘、纹理、颜色直方图、SIFT(尺度不变特征变换)特征等。
-
文本处理:需要将文本转换为词袋模型、TF-IDF(词频-逆文档频率)值,或者进行词性标注。
-
结构化数据:需要对年龄进行分箱(binning),对类别变量进行独热编码(One-Hot Encoding),或者组合两个特征(如"房屋面积"乘以"每平米单价"得到"总价")。
1.3 人工特征的困境
这种依赖专家经验的范式,存在着几大致命伤:
-
维度诅咒与复杂性:特征组合的可能性是爆炸性的。假设你有100个特征,两两组合就能产生近5000个新特征。人工穷举不仅不现实,而且容易引入噪声。
-
领域壁垒高:要做好金融风控的特征工程,你得懂金融;要做好医疗影像的特征工程,你得懂医学。这导致了极高的技术应用门槛。
-
鲁棒性差:手工设计的特征往往过于具体。例如,针对某一特定光照条件下设计的图像特征,换一种光照可能就完全失效了。模型的泛化能力受限。
-
耗时且不可复用:数据科学家80%的时间花在数据准备和特征工程上,且针对A项目设计的特征,几乎无法直接用在B项目上。
这就是前深度学习时代的缩影------人工智能的本质,是"人工"堆出来的智能。
二:深度学习的崛起------自动化特征的"工业革命"
2.1 什么是深度学习?
深度学习是机器学习的一个子集,它基于一种受大脑神经元结构启发的算法------人工神经网络。当这种网络的层数非常深时(例如几十层、上百层甚至上千层),就被称为"深度"学习。
如果说传统机器学习是"让机器从特征中学习规律",那么深度学习就是"让机器直接从原始数据中学习如何提取特征"。
2.2 自动特征提取:深度学习的核心魔法
深度学习的革命性在于其表示学习能力。它的多层结构天然地形成了一个特征金字塔:
-
底层网络:学习一些非常基础的特征。在处理图像时,底层神经元可能只识别边缘(横线、竖线)、颜色斑点;在处理语音时,底层可能只识别音素的频率。
-
中层网络:将底层的基础特征组合成有意义的部件。图像的中层网络可能识别出眼睛、鼻子、轮子;语音的中层可能识别出音节。
-
高层网络:将中层特征进一步抽象成完整的物体或概念。图像的高层可能识别出人脸、汽车;语音的高层可能识别出单词或语义。
这一过程完全是端到端的。我们不再需要告诉模型"先提取边缘,再组合成眼睛,最后识别出人脸"。我们只需要给模型海量的猫的图片,模型通过反向传播算法,自己就会调整内部神经元(也就是特征提取器)的参数,最终形成一个能准确识别猫的模型。
2.3 案例分析:识别一张猫的图片
-
机器学习流程:
-
定义特征:耳朵的夹角(是否尖)、胡须的长度、毛发的纹理、眼睛的颜色直方图。
-
编写代码提取这些特征,将一张图片转换为几百个数值组成的向量。
-
将向量输入支持向量机或随机森林分类器。
-
模型输出结果:是猫(概率90%)。
-
-
深度学习流程:
-
直接将原始像素矩阵(例如256x256x3的数值)输入卷积神经网络。
-
网络经过卷积、池化等一系列操作,自动计算。
-
模型输出结果:是猫(概率95%)。
-
在这个过程中,深度学习模型的中间层自发地学会了识别边缘、纹理、猫的轮廓、甚至猫的脸部结构。这一切都无需人工干预。
三:针锋相对------六大维度的深度对比
为了更清晰地展现这场革命的全貌,我们将两者在六个核心维度上进行深度对比。
3.1 特征工程 vs. 特征学习
这是最核心、最本质的区别。
-
机器学习 :高度依赖人工。特征的质量直接决定了模型效果的天花板。这是一个经验驱动、试错成本极高的过程。
-
深度学习 :自动化端到端学习。模型在训练过程中同步学习特征表示。这不仅是体力劳动的解放,更是模型能力的释放------深度学习能发现人类经验无法触及的、更深层次的非线性特征组合。
3.2 数据需求:石油 vs. 核燃料
-
机器学习 :食量小,效率高。由于特征已经被人工提炼过,模型结构相对简单(参数少),机器学习在几千到几万条中小规模数据集上往往就能表现良好。例如,用逻辑回归做信贷评分,几千条样本通常足够。
-
深度学习 :数据饥渴,力大飞砖。深度神经网络参数量巨大(可达亿级),需要海量数据来驱动训练,才能避免过拟合,找到最优解。没有百万级甚至亿级的图像数据,无法训练出一个鲁棒的图像分类器。这也是为什么深度学习在互联网时代才爆发------因为只有互联网才能提供海量的"燃料"。
3.3 硬件依赖:CPU vs. GPU
-
机器学习 :平民化。大多数传统机器学习算法(决策树、线性模型、甚至一些集成模型)在普通的中央处理器上即可高效运行。这使得它们非常容易部署在低功耗、低成本的设备上。
-
深度学习 :贵族化。深度学习本质上是大量的矩阵乘法运算,这种计算模式恰好是图形处理器的强项。训练大型模型(如GPT系列、ResNet)需要数千块GPU/TPU集群耗费数周时间,耗电量惊人,成本极高。
3.4 可解释性:白盒 vs. 黑箱
-
机器学习 :透明的白盒。模型决策过程相对清晰。决策树可以可视化展示"如果年龄>30且收入>1万,则批准贷款";逻辑回归可以直接给出每个特征的权重系数,告诉我们"收入"比"年龄"重要3倍。这在医疗、金融、司法等需要强监管和可解释性的领域至关重要。
-
深度学习 :神秘的黑箱。一个上百层的神经网络,经过千万次非线性变换,最终的输出结果几乎无法追溯具体是哪些特征起了决定性作用。虽然近年来出现了如Grad-CAM(梯度加权类激活映射)等试图解释模型的技术,但深度学习本质上仍难以解释。试想,一个无法解释的AI拒绝了你的贷款申请,你是无法接受的。
3.5 模型复杂度与训练时间
-
机器学习 :短平快。训练时间从几秒到几十分钟不等。适合快速迭代验证、对实时性要求极高的场景。
-
深度学习 :重慢长。训练时间以小时、天甚至周为单位。但这通常换来的是更高的精度上限。
3.6 适用场景:结构化 vs. 非结构化
-
机器学习 :结构化数据的王者。表格数据(如Excel表格、数据库记录)是机器学习的传统优势区。金融风控、电商销量预测、客户流失分析等领域,XGBoost、LightGBM等梯度提升树模型依然是首选。
-
深度学习 :非结构化数据的霸主。图像、视频、音频、自然语言文本------这些人类直接感知的原始数据,是深度学习的统治区。无论是自动驾驶、人脸识别、语音助手还是ChatGPT,底层核心技术都是深度学习。
四:殊途同归------未来的融合与进化
尽管深度学习掀起了一场革命,但这并不意味着传统机器学习会被淘汰。相反,我们正在进入一个融合共生的时代。
4.1 自动机器学习:颠覆者也在被颠覆
有趣的是,虽然深度学习革命了特征工程,但自动化也在反过来革命机器学习。自动机器学习(AutoML) 和自动特征工程(AutoFE) 正在将传统机器学习从"手工作坊"中解放出来。
现代自动特征工程工具(如阿里巴巴的AutoFE,或基于遗传算法的Feature-gen)可以通过程序化的方式,自动探索特征空间。它们可以:
-
自动变换:对数值特征自动尝试平方、开方、对数、Sigmoid等非线性变换,寻找最优的数据分布。
-
自动组合:像深度学习一样,通过梯度提升决策树等算法自动寻找特征之间的交互作用,生成高阶组合特征。
-
自动选择:使用遗传算法或多目标优化,在保证模型精度的前提下,最小化特征数量,提升模型可解释性和运行效率。
例如,一篇2025年的学术研究提出了一种双层遗传算法进行特征工程,能够在提升模型性能(F1分数平均提高1.5%)的同时,大幅减少特征数量(平均减少54.5%)。这证明,即便在不使用深度学习的情况下,通过先进的自动化手段,传统机器学习依然在不断进化。
4.2 混合范式:最好的技术是"用好"技术
在实际工业应用中,纯粹的"二选一"并不明智。越来越多的架构师采用混合范式:
-
深度学习作为特征提取器 + 机器学习作为分类器/回归器 :
这是目前非常流行的做法。例如,我们可以用一个预训练好的卷积神经网络(如ResNet)提取图像的高层特征向量(例如2048维),然后将这个向量输入到传统的支持向量机或XGBoost中进行分类。这种方式结合了深度学习的自动特征提取能力和传统机器学习的小样本、强解释性优势。
-
机器学习处理结构化数据 + 深度学习处理非结构化数据 :
在一个多模态任务中(如视频内容审核),我们可能用深度学习处理视频帧(图像)和音频(语音),用传统机器学习处理用户元数据(结构化表格,如粉丝数、发布时间等),最后融合所有结果做出判断。
4.3 选择的艺术:何时用什么?
作为从业者,面对这场革命,我们该如何选择?以下是一些实操指南:
优先选择传统机器学习的情况:
-
数据量较小(例如少于1万条样本)。
-
数据是结构化的表格数据(如CSV文件)。
-
需要强可解释性(如医疗诊断、银行风控报告)。
-
计算资源有限(仅有普通CPU,无GPU)。
-
需要快速开发和部署(快速基线模型)。
优先选择深度学习的情况:
-
数据是非结构化的(图像、音频、文本、视频)。
-
拥有海量数据(百万级以上)。
-
问题极其复杂(如自动驾驶感知、大语言模型)。
-
对精度要求极高,且不介意"黑箱"。
-
有充足的GPU计算资源。
五:结论------拥抱工具,更要理解本质
回顾这场由深度学习引发的特征工程革命,我们看到了一个清晰的脉络:从人工定义,到自动发现;从局部优化,到全局端到端。
深度学习的伟大之处,不仅仅在于它刷新了ImageNet(大规模视觉识别挑战赛)的榜单,也不仅仅在于它催生了ChatGPT,而在于它改变了我们看待数据和解决问题的角度。它告诉我们,机器不仅可以学习如何解决问题,还可以学习如何更好地"理解"问题。
然而,我们也要清醒地认识到,工具越强大,使用者的责任越大 。深度学习并非万能钥匙,传统机器学习也远未过时。那些从业界的顶尖高手,往往不是只会调PyTorch(深度学习框架)或只会用Scikit-learn(机器学习库)的人,而是那些深刻理解数据本质、理解算法优劣,并能在正确的地方使用正确的工具的人。
特征工程的革命,不是要消灭工程师,而是要倒逼工程师们从繁琐的手工特征劳动中解放出来,去思考更具创造性的问题:如何定义问题?如何获取数据?如何构建更高效的混合系统?如何理解和解释模型的决策?
下一次当你面对一个复杂的数据问题时,不妨问问自己:这个问题,是需要我手把手教机器找特征,还是我只需要提供数据,让机器自己去发现规律?这个问题的答案,将指引你走向通往未来的那条正确的路。
参考资料:
-
带你了解机器学习与深度学习主要区别
-
AI辅助数据开发:基于深度学习的自动化数据清洗与特征工程实现
-
人工智能、机器学习和深度学习,其实不是一回事
-
深度学习与机器学习的区别
-
深度学习与机器学习的区别
-
一文读懂深度学习与机器学习的差异