目录
- 前言
- 一、贪心算法
-
- [1.1 简单贪心](#1.1 简单贪心)
-
- [1.1.1 货舱选址](#1.1.1 货舱选址)
- [1.1.2 最大子段和](#1.1.2 最大子段和)
- [1.1.3 纪念品分组](#1.1.3 纪念品分组)
- [1.1.4 排座椅](#1.1.4 排座椅)
- [1.1.5 矩阵消除游戏](#1.1.5 矩阵消除游戏)
- 结语


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、贪心算法
贪心算法是两极分化很严重的算法 。简单的问题会让你觉得理所应当,难一点的问题会让你怀疑人生。
1.什么是贪心算法?
贪心算法,或者说是贪心策略:企图用局部最优找出全局最优。
- 把解决问题的过程分成若干步;
- 解决每一步时,都选择"当前看起来最优的"解法;
- "希望"得到全局的最优解。
2.贪心算法的特点
- 对于大多数题目,贪心策略的提出并不是很难,难的是证明它是正确的。因为贪心算法相较于暴力枚举,每一步并不是把所有情况都考虑进去,而是只考虑当前看起来最优的情况。但是,局部最优并不等于全局最优,所以我们必须要能严谨的证明我们的贪心策略是正确的。
一般证明策略有:反证法,数学归纳法,交换论证法等等。 - 当问题的场景不同时,贪心的策略也会不同。因此,贪心策略的提出是没有固定的套路和模板的。我后面讲的题目虽然分类,但是大家会发现具体的策略还是相差很大。
因此,不要妄想做几道贪心题目就能遇到一个会一个。有可能做完50道贪心题目之后,第51道还是没有任何思路。
3. 如何学习贪心?
先有一个认知:做了几十道贪心的题目,遇到一个新的又没有思路,这时很正常的现象,把心态放平。
- 前期学习的时候,重点放在各种各样的策略上,把各种策略当成经验来吸收;
- 在平常学习的时候,尽可能的证明一下这个贪心策略是否正确,这样有利于培养严谨的思维。但是在比赛中,能想出来一个策略就已经不错了,如果再花费大量的时间去证明,有点得不偿失。这个时候,如果根据贪心策略想出来的若干个边界情况都能过的话,就可以尝试去写代码了。
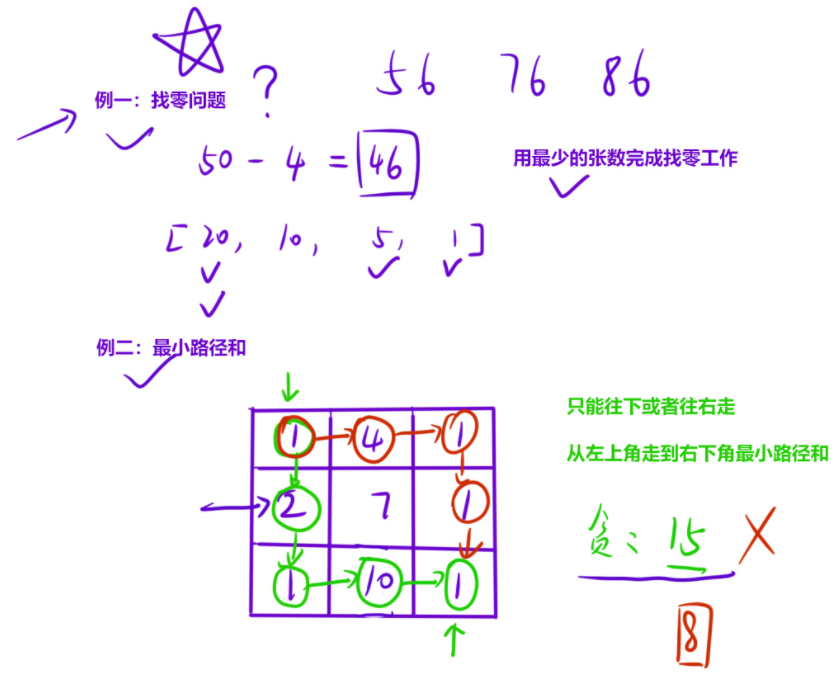
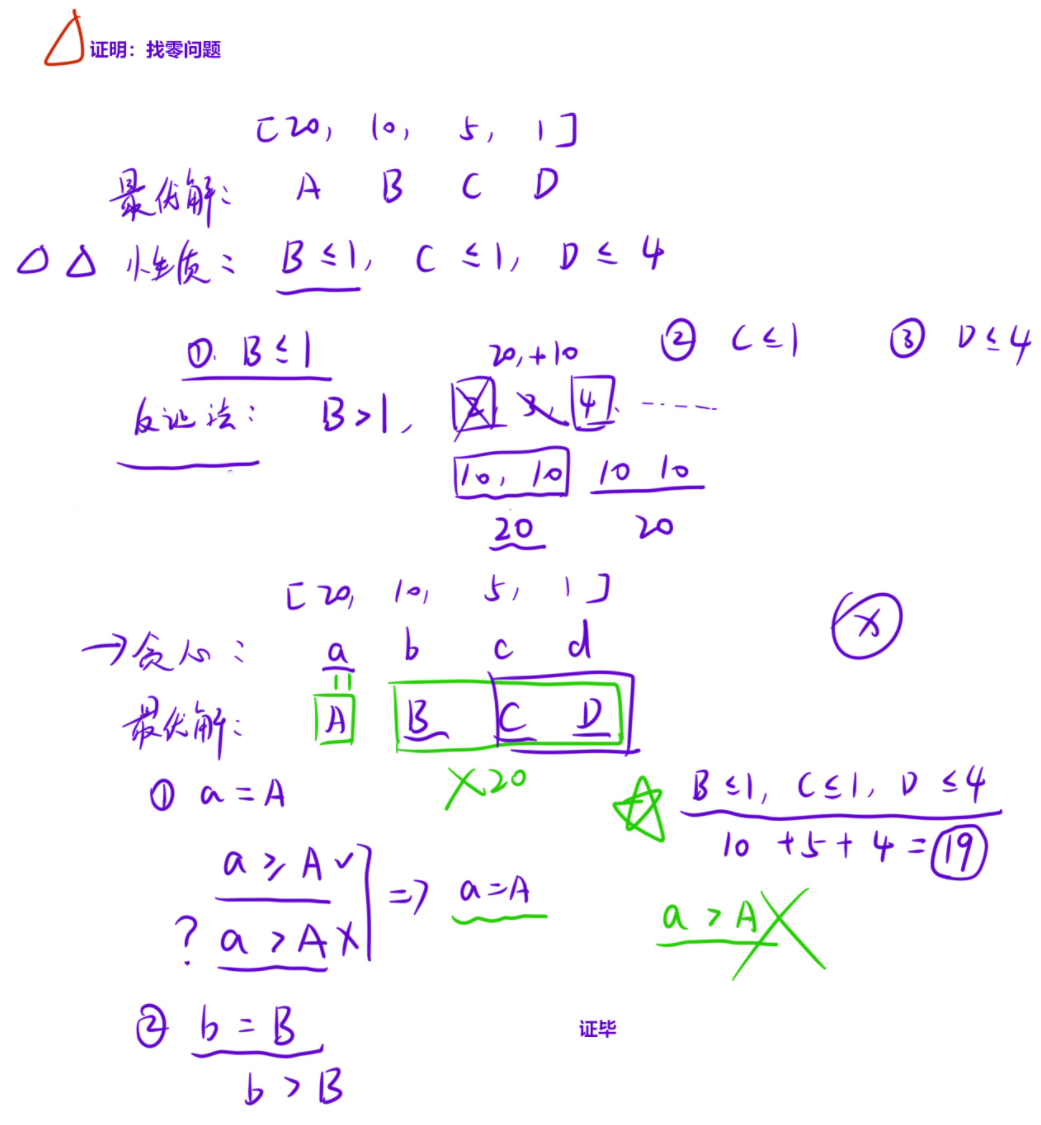
1.1 简单贪心
1.1.1 货舱选址
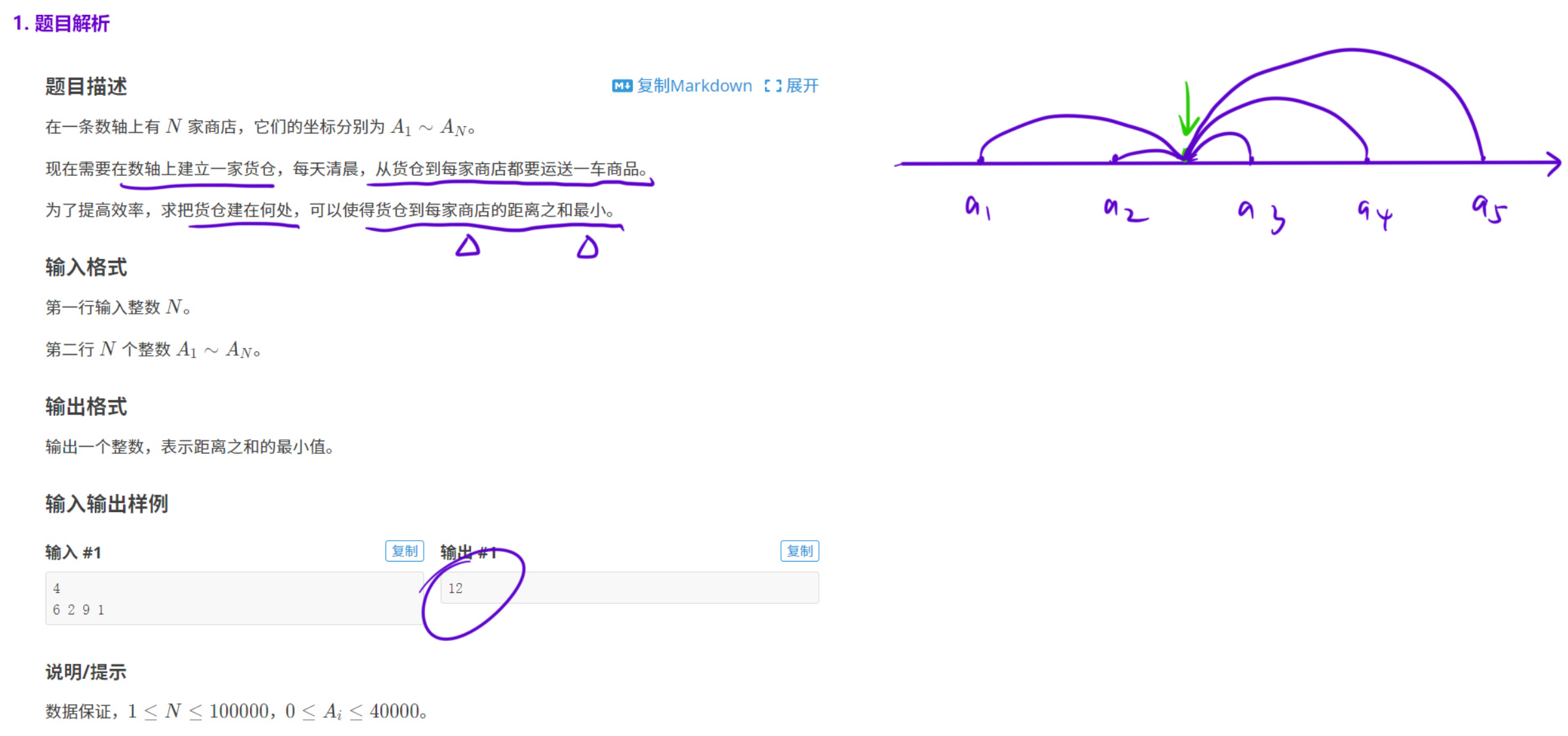
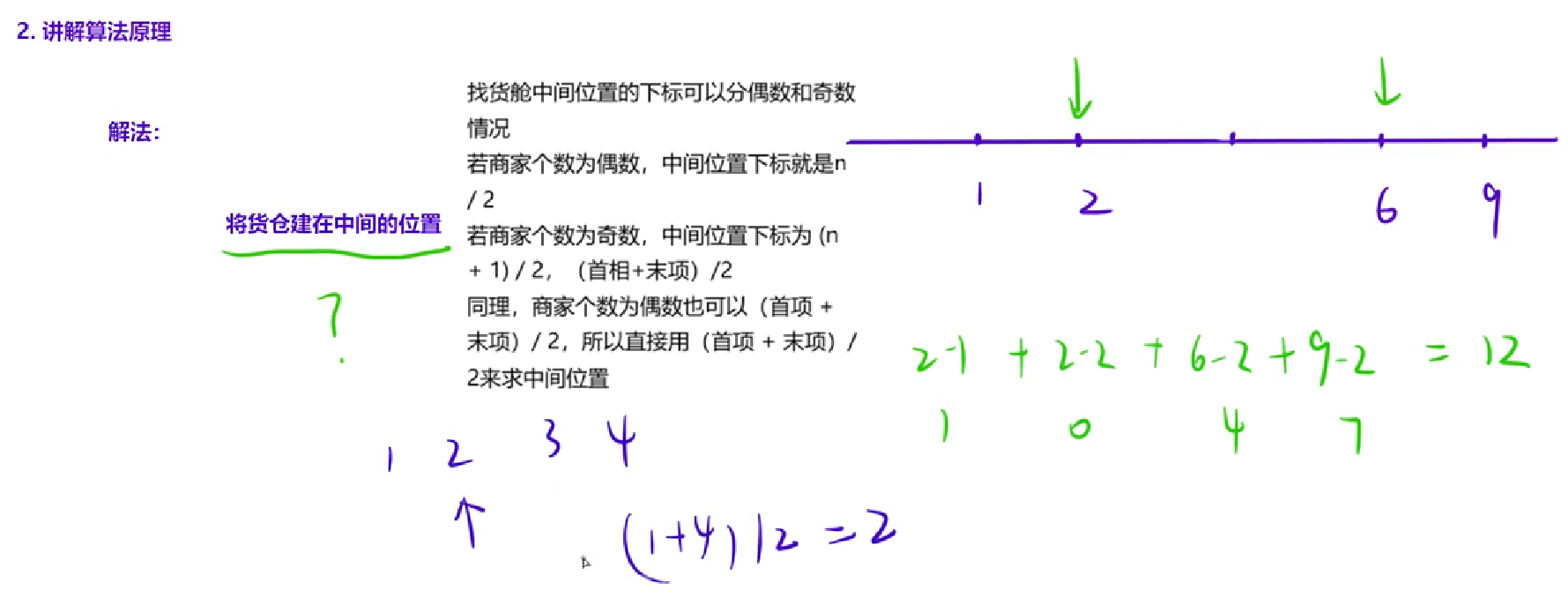
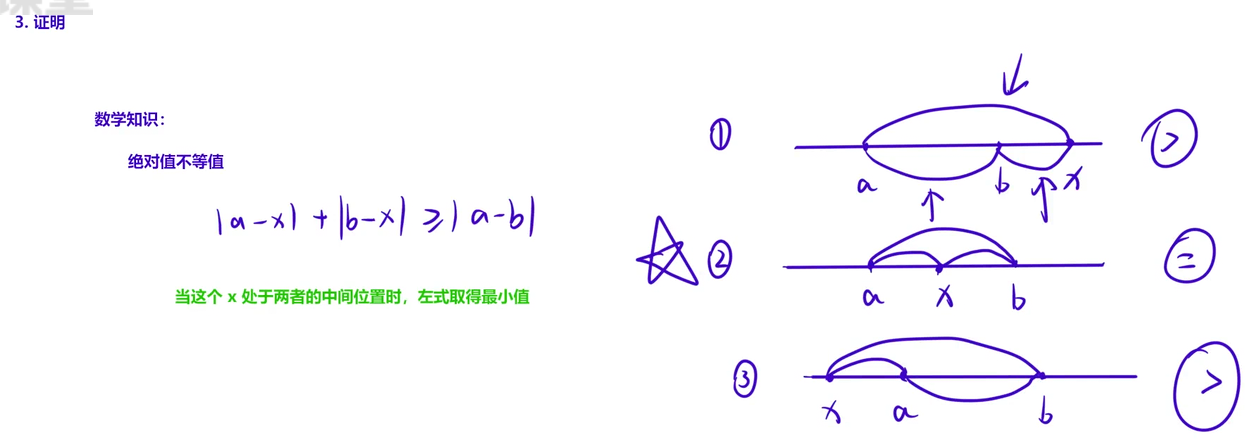
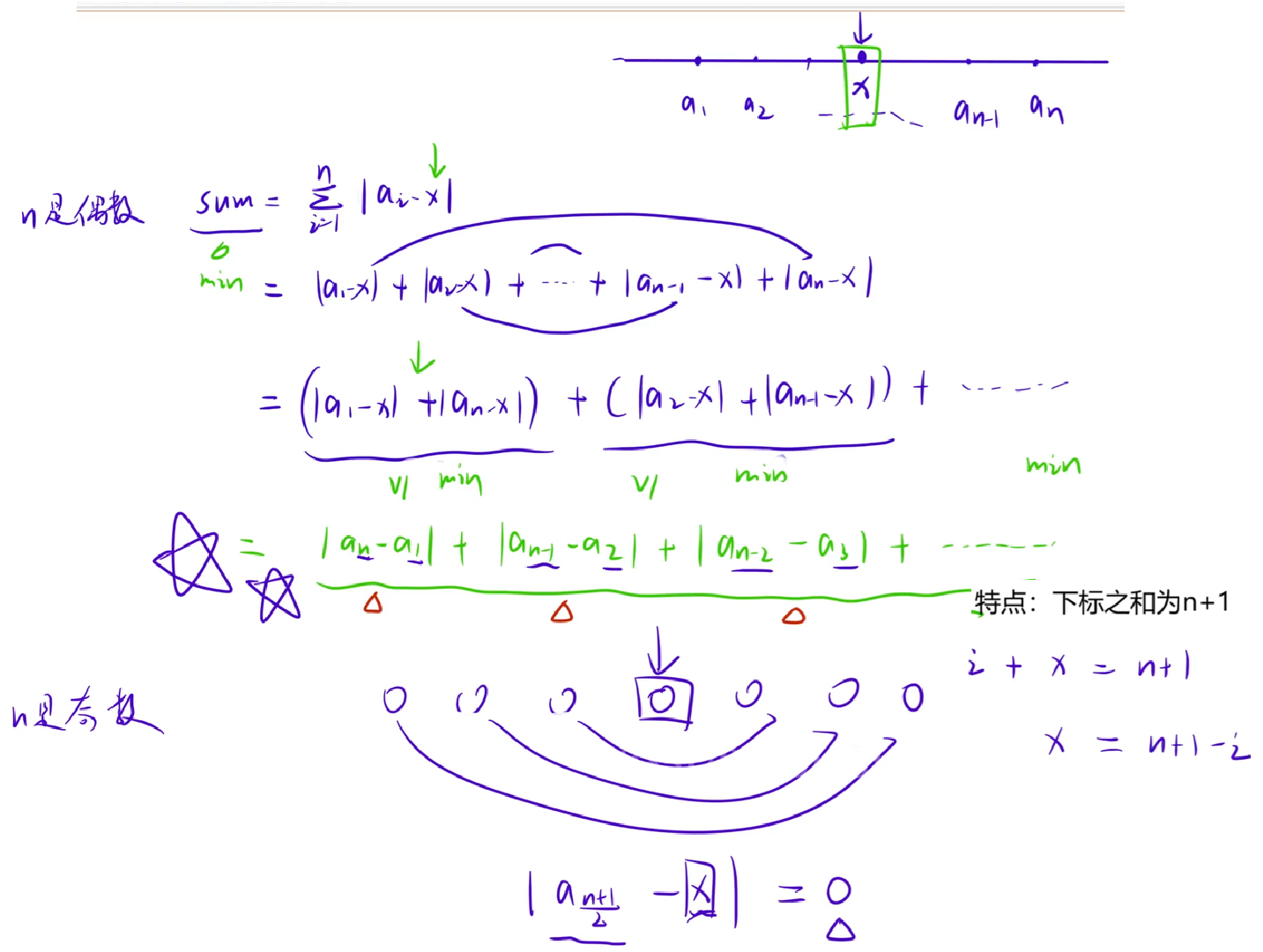
这里提供两种写法:
直接法:排序后取中位数,计算所有点到中位数的绝对距离之和。
cpp
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 1e5 + 10;
int n;
LL a[N];
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
sort(a + 1, a + 1 + n);
LL ret = 0;
// 利用中间值来计算
// for(int i = 1; i <= n; i++)
// {
// ret += abs(a[i] - a[(n + 1) / 2]);
// }
// 用结论计算
for(int i = 1; i <= n / 2; i++)
{
ret += a[n - i + 1] - a[i];
}
cout << ret << endl;
return 0;
}配对法:排序后首尾配对(第i个和第n-i+1个),累加每对的差值,结果与直接法完全一致(每对差值等于它们到中位数的距离之和)。
cpp
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 1e5 + 10;
typedef long long LL;
LL a[N];
LL n;
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
sort(a + 1, a + n + 1);
//利用结论配对法
LL ret = 0;
for(int i = 1; i <= (n / 2); i++)
{
ret += abs(a[n + 1 - i] - a[i]);
}
cout << ret << endl;
return 0;
}题目中数据范围为什么定义为long long
分两种极端情况:
① 直接法(算所有点到中位数的距离和)
最坏情况:所有商店都分布在数轴两端(比如一半在 0,一半在 40000),中位数在中间。那每个点到中位数的距离,最大约等于 40000。总距离和 ≈ 105×40000=4×109这个数 远大于 int 的最大值 2.1×109,int 根本存不下,会直接溢出。
② 配对法(首尾配对算差值和)
排序后,把第 i 个和第 n-i+1 个配对,每对差值是 大坐标 - 小坐标。最坏情况:最小坐标是 0,最大是 40000,每对差值都是40000。配对数 ≈ N/2=5×104总距离和 ≈ 5×104×40000=2×109这个数虽然比 2.1×109 小一点,但非常接近上限 ,如果 N 是奇数(比如 105+1),配对数会更多,总和就会超过 int 上限,依然有溢出风险。
在蓝桥杯比赛中很多数据范围溢出的情况都是隐性的,新手建议直接全部的定义为long long更为稳妥。
1.1.2 最大子段和
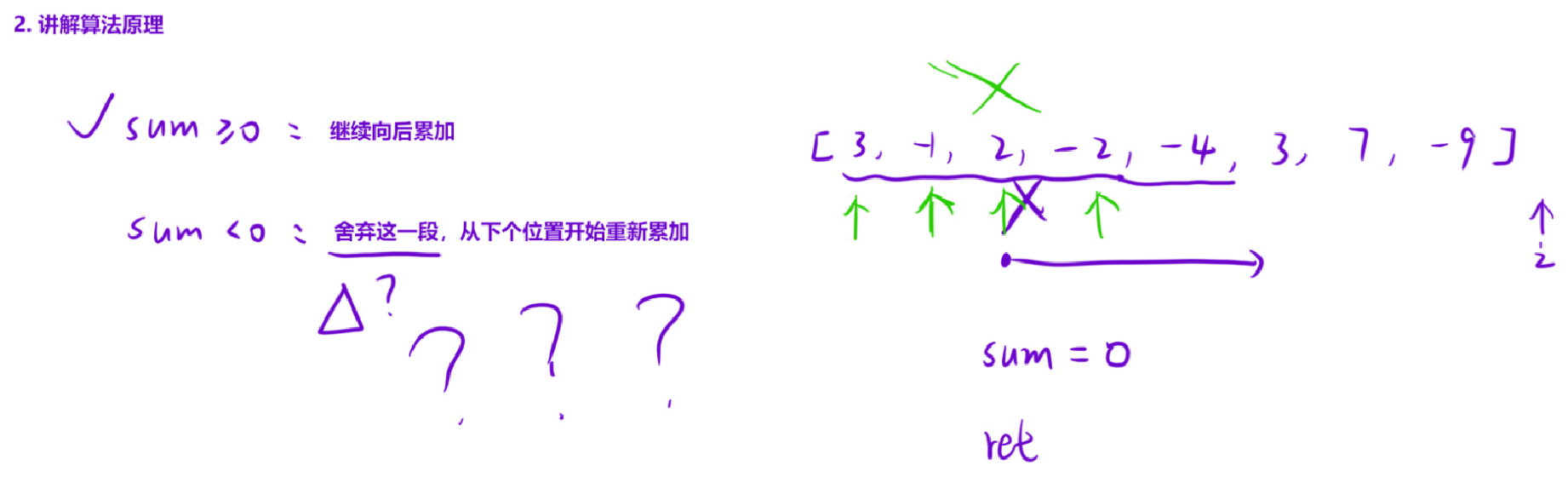
解法:有没有似曾相识的感觉?这是我们第二次遇见它了,但还不是最后一次~
贪心算法:从前往后累加,我们会遇到下面两种情况:
- 目前的累加和≥0:那么当前累加和还会对后续的累加和做出贡献,那我们就继续向后累加,然后更新结果;
- 目前的累加和<0:对后续的累加和做不了一点贡献,直接大胆舍弃计算过的这一段,把累加和重置为0,然后继续向后累加。
这样我们在扫描整个数组一遍之后,就能更新出最大子段和。
聪明的你此时就会有「些」大大的疑惑了,why?why?why?为什么可以得到「最优解」?怎么感觉这个策略是「错」的啊?感觉「好多情况」都没考虑进去,为什么就得到一个正确的结果?为什么可以「大胆舍去」这一段累加和?
如果你有大大的疑惑,这就对了。我刚开始做这道题,看到别人的题解是这样写的时候,也有如此疑惑。(我觉得这就是贪心算法的魅力吧,看似很简单,很玄学,其实有很多值的我们思考的地方)别着急,我们接下来证明一下这个贪心策略是正确的。
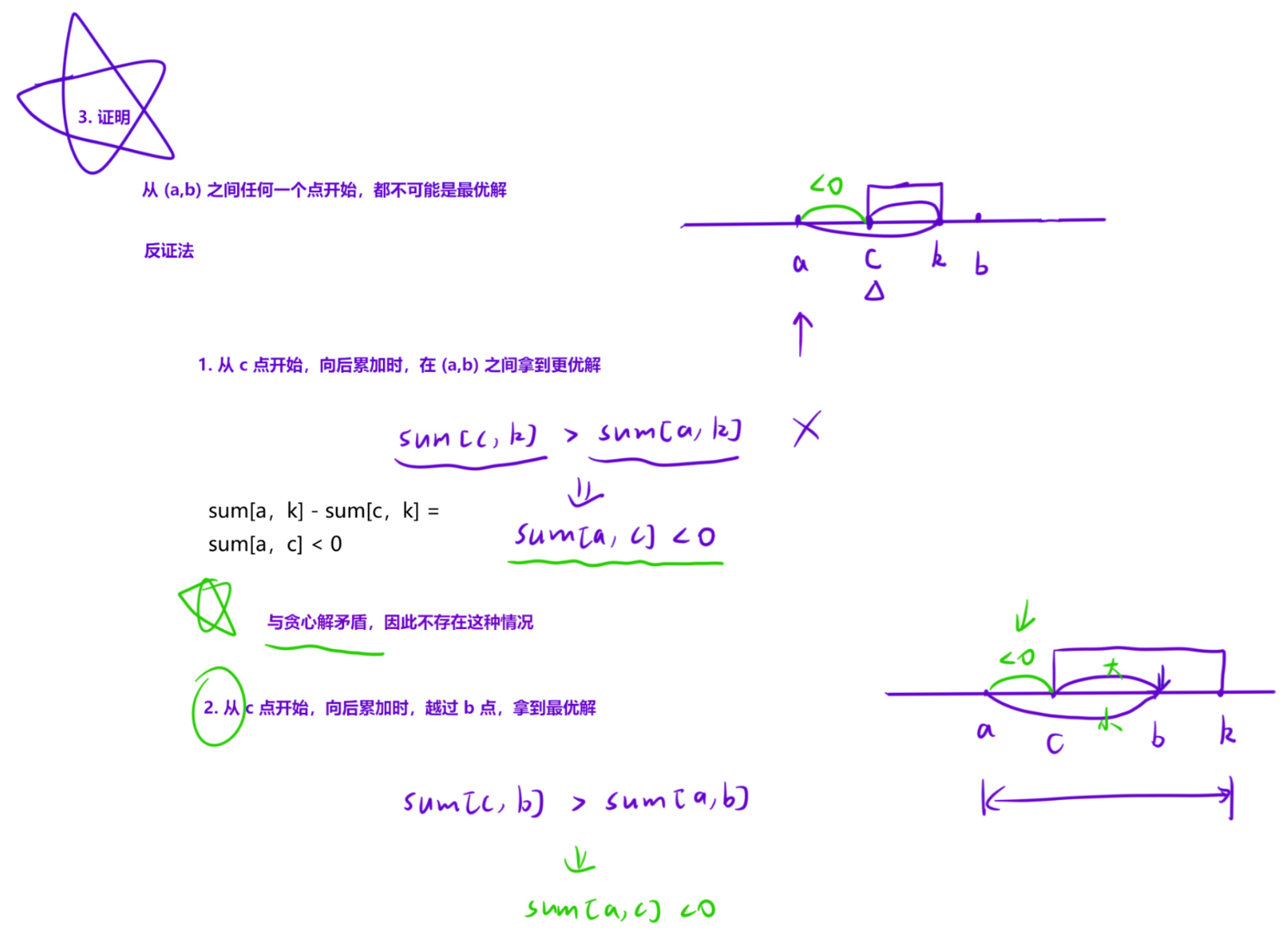
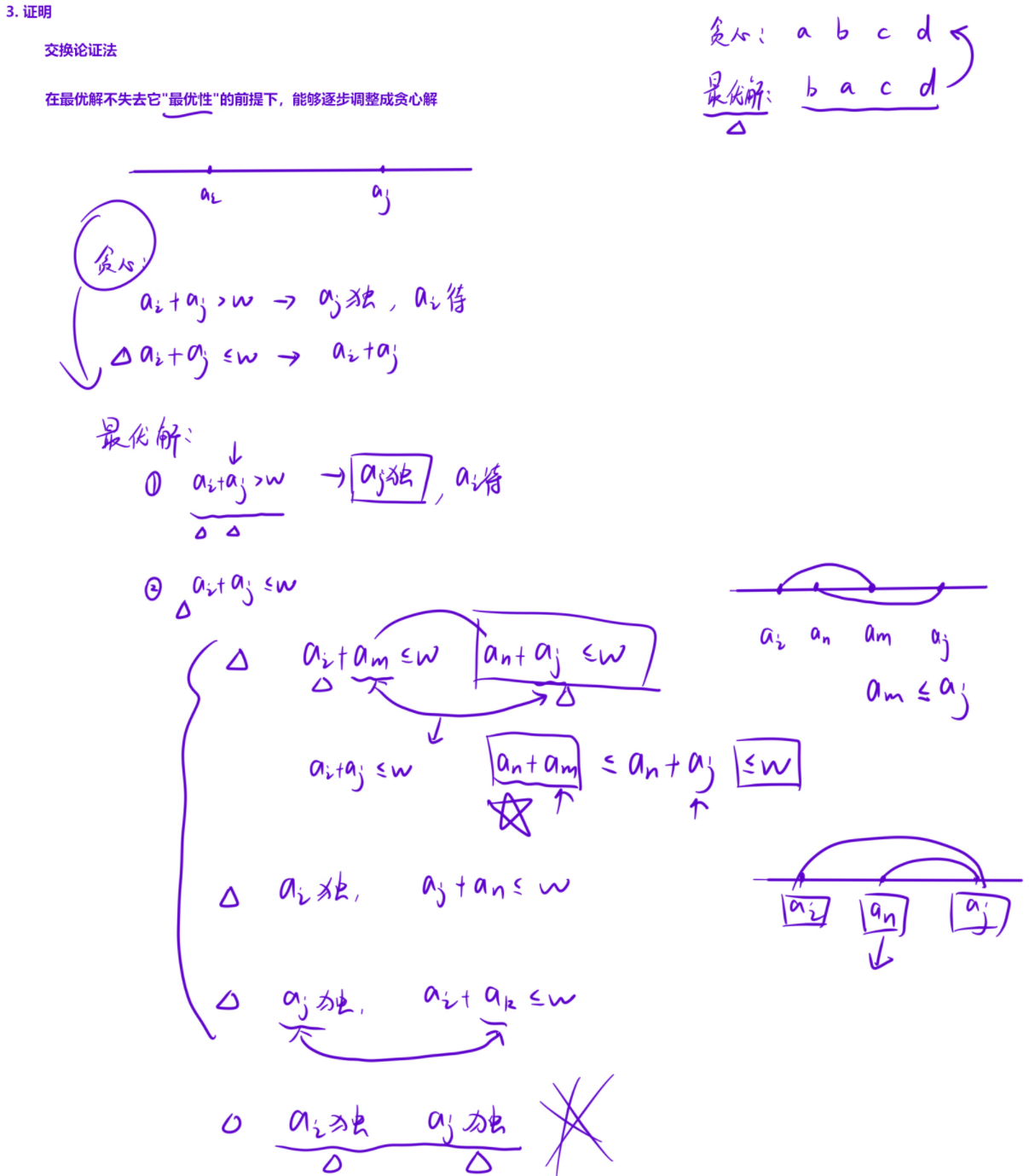
其实只需要证明我们在累加的过程中,出现负数时,为什么可以大胆的舍去这一段区间,然后重新开始。证明以下三点,就可以「大胆舍弃」了:

在累加的过程中算出一段区间和suma,b<0,如果不舍弃这一段,那么a,b段之间就会存在一点,「以某个位置为起点」就会「更优」,分为下面两种情况:
1.在ab段存在一个点c,从这个位置开始,「越过b」的累加和比从a开始的累加和更优:
用「反证法」证明这种情况不存在。
如果存在这一点,那么:sumc,b > suma,b,这样才能保证向后加的时候更优。
但这是「不可能」的。如果sumc,b > suma,b,那么suma,c一1 < 0,这与我们的贪心策略矛盾。
因为我们贪心策略向后加的时候,只要不小于0,就会一直加下去。如果a,c一1段小于0,就会在c点之前停止,不会累加到b。
因此区间内不存在一点,在计算子数组和时,在越过的情况下,能比从a开始更优。
2.在ab段存在一个点c,从这个位置开始,「不越过b」的累加和比从a开始的累加和更优:
也可以用「反证法」证明这种情况不存在。
如果存在这一点,那么:sumc,k > suma,k。
但这是不可能的。如果sumc,k > suma,k,那么suma,c一1 < 0,这与我们的贪心策略矛盾。
因此区间内不存在一点,在计算子数组和时,在「不越过b」的情况下,能比从a开始更优。
综上所述,我们可以大胆舍弃这一段,重新开始。
cpp
#include <iostream>
using namespace std;
typedef long long LL;
const int N = 2e5 + 10;
int n;
LL a[N];
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
LL sum = 0, ret = -1e6;
for(int i = 1; i <= n; i++)
{
sum += a[i];
ret = max(ret, sum);
if(sum < 0) sum = 0;
}
cout << ret << endl;
return 0;
}要点补充:ret用来统计最终结果,但是有可能整个数组全是负数,最后结果应该是当中最大的那个值,所以ret不能初始化为0,要初始化为一个特别小的数
1.1.3 纪念品分组
纪念品分组
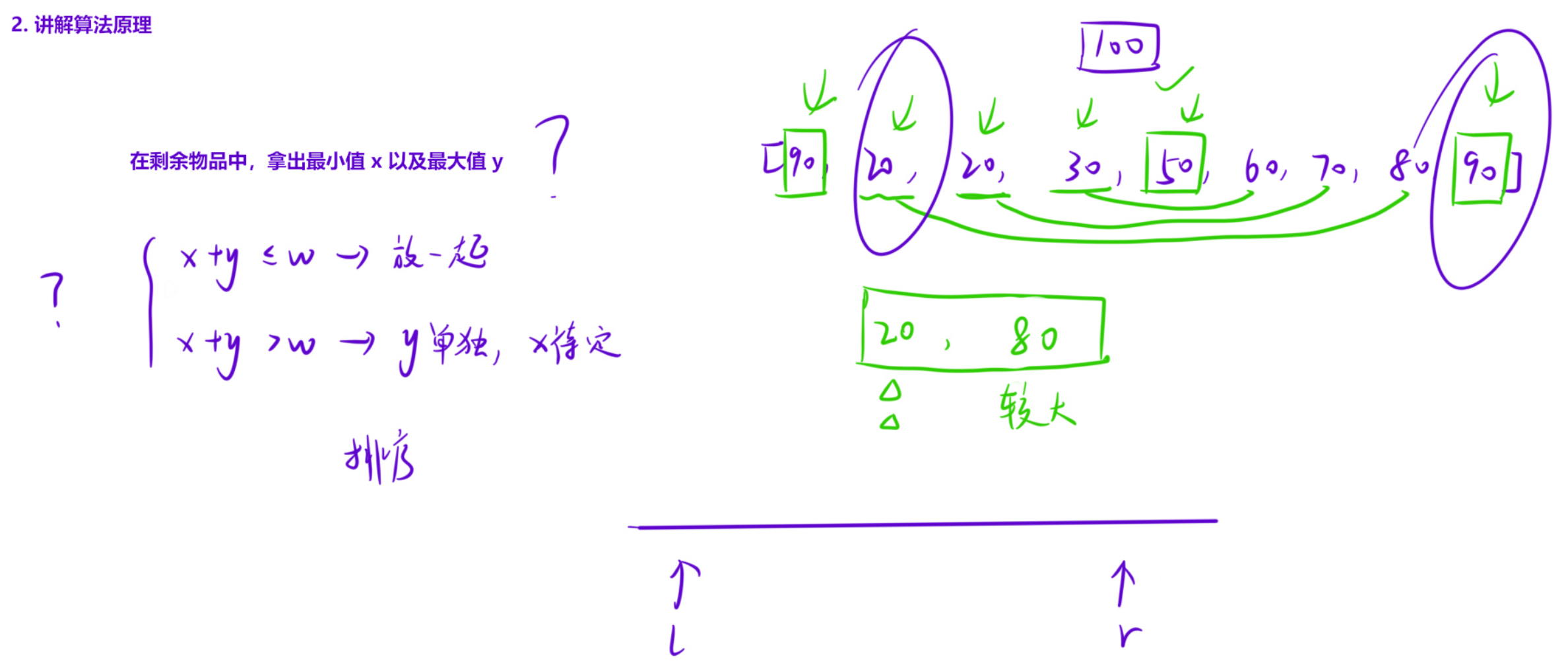
【解法】
先将所有的纪念品排序,每次拿出当前的最小值与最大值y:
- 如果 x + y ≤ w:就把这两个放在一起;
- 如果 x + y > w:说明此时最大的和谁都凑不到一起,y 单独分组,x 继续留下在进行下一次判断。
直到所有的物品都按照上述规则分配之后,得到的组数就是最优解。


cpp
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 3e4 + 10;
typedef long long LL;
LL a[N];
LL w, n;
int main()
{
cin >> w >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
sort(a + 1, a + n + 1);
LL l = 1, r = n, ret = 0;
//两个指针相遇时,当前的物品也需要分组
while(l <= r)
{
//如果if else中需要执行两个语句,两个语句之间一定要用逗号隔开
if(a[l] + a[r] <= w) l++, r--;
//r单独放
else r--;
ret++;
}
cout << ret << endl;
return 0;
}1.1.4 排座椅
排座椅
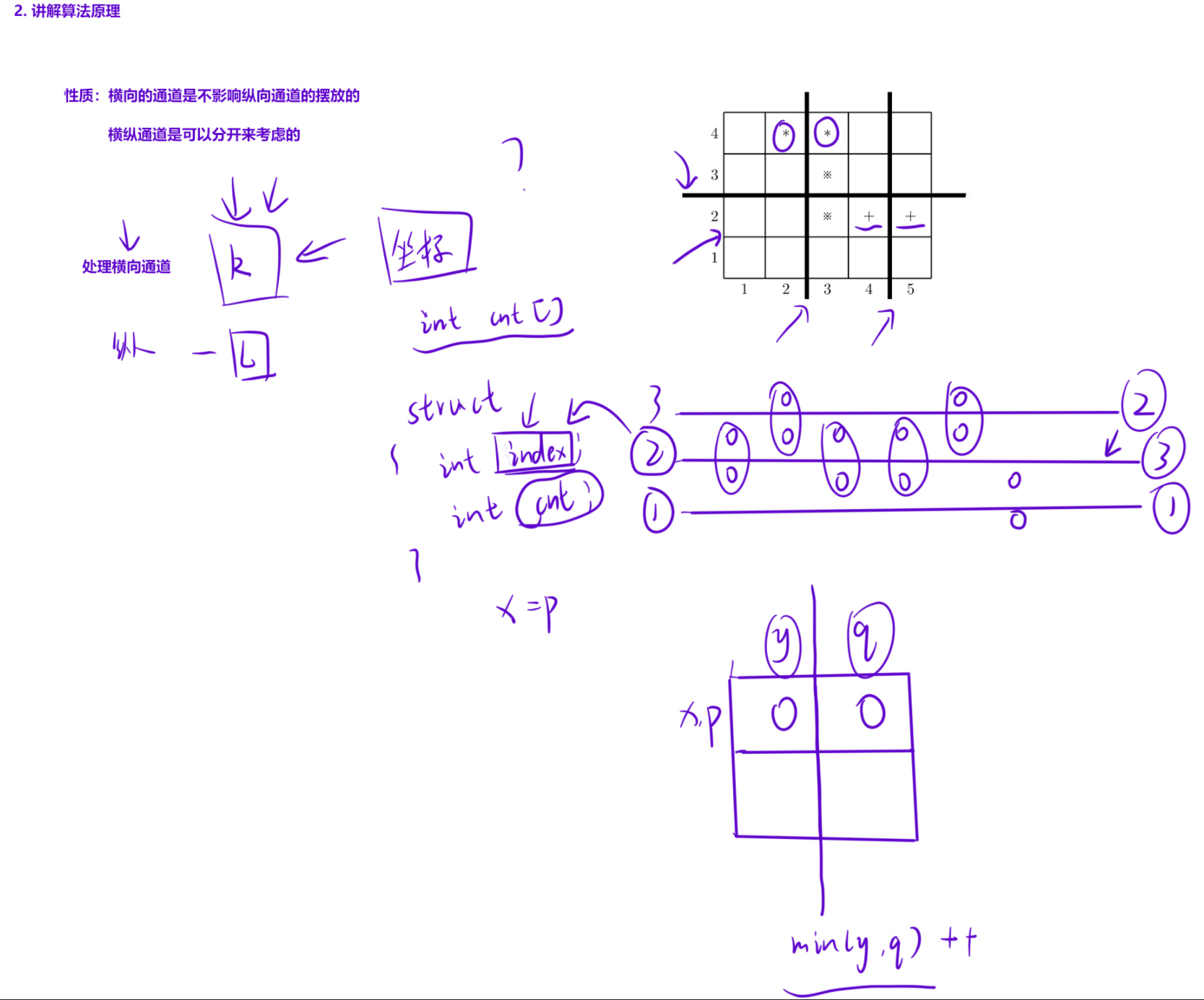
核心目标是:在 M 行 N 列的教室中,选择 K 个横向通道(行与行之间)和 L 个纵向通道(列与列之间),使得被通道隔开的交头接耳同学对数最多(即剩余交头接耳对数最少)。
贪心策略:每个候选通道位置(行 i 与 i+1 之间、列 j 与 j+1 之间)的「价值」= 在此处开通道能隔开的交头接耳对数。我们只需选择价值最高的 K 个横向通道和价值最高的 L 个纵向通道,即可得到最优解。
cpp
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 1010;
struct node
{
int index; // 通道位置编号(行/列)
int cnt; // 此位置作为通道能隔开的交头接耳对数
}row[N], col[N]; // row: 横向通道数组,col: 纵向通道数组
int m, n, k, l, d; // 输入参数:行数、列数、横向通道数、纵向通道数、交头接耳对数
// 按 cnt 从大到小排序(用于筛选价值最高的通道)
bool cmp1(node& x, node& y)
{
return x.cnt > y.cnt;
}
// 按 index 从小到大排序(用于输出时保证顺序递增)
bool cmp2(node& x, node& y)
{
return x.index < y.index;
}
int main()
{
cin >> m >> n >> k >> l >> d;
// 初始化:给每个通道位置赋予对应的编号
for(int i = 1; i <= m; i++) row[i].index = i;
for(int i = 1; i <= n; i++) col[i].index = i;
// 统计每个通道的价值(cnt)
while(d--)
{
int x, y, p, q; cin >> x >> y >> p >> q;
if(x == p) // 左右相邻(同一行)→ 对应纵向通道
col[min(y, q)].cnt++;
else // 前后相邻(同一列)→ 对应横向通道
row[min(x, p)].cnt++;
}
// 第一步:按价值降序排序,筛选出价值最高的K/L个通道
sort(row + 1, row + 1 + m, cmp1);
sort(col + 1, col + 1 + n, cmp1);
// 第二步:将筛选出的通道按位置升序排序,保证输出顺序
sort(row + 1, row + 1 + k, cmp2);
sort(col + 1, col + 1 + l, cmp2);
// 输出结果
for(int i = 1; i <= k; i++)
cout << row[i].index << " ";
cout << endl;
for(int i = 1; i <= l; i++)
cout << col[i].index << " ";
cout << endl;
return 0;
}尤其要注意:这里 sort 需要的是告诉它 "用哪个函数做比较"(把函数本身传过去,由 sort 内部自己去调用),所以只需要写 cmp1(函数名)即可,不用加括号和参数。
1.1.5 矩阵消除游戏
矩阵消除游戏
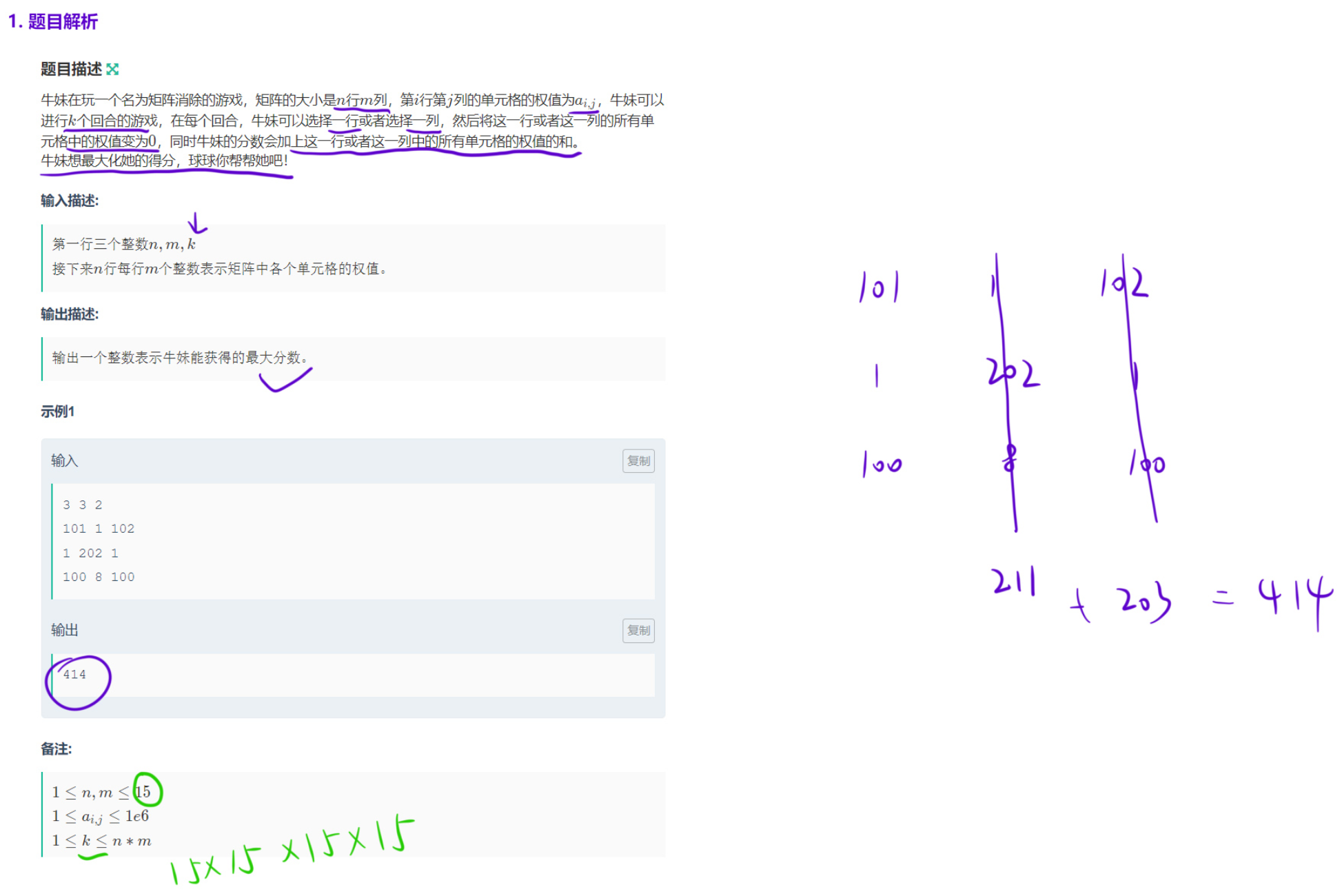
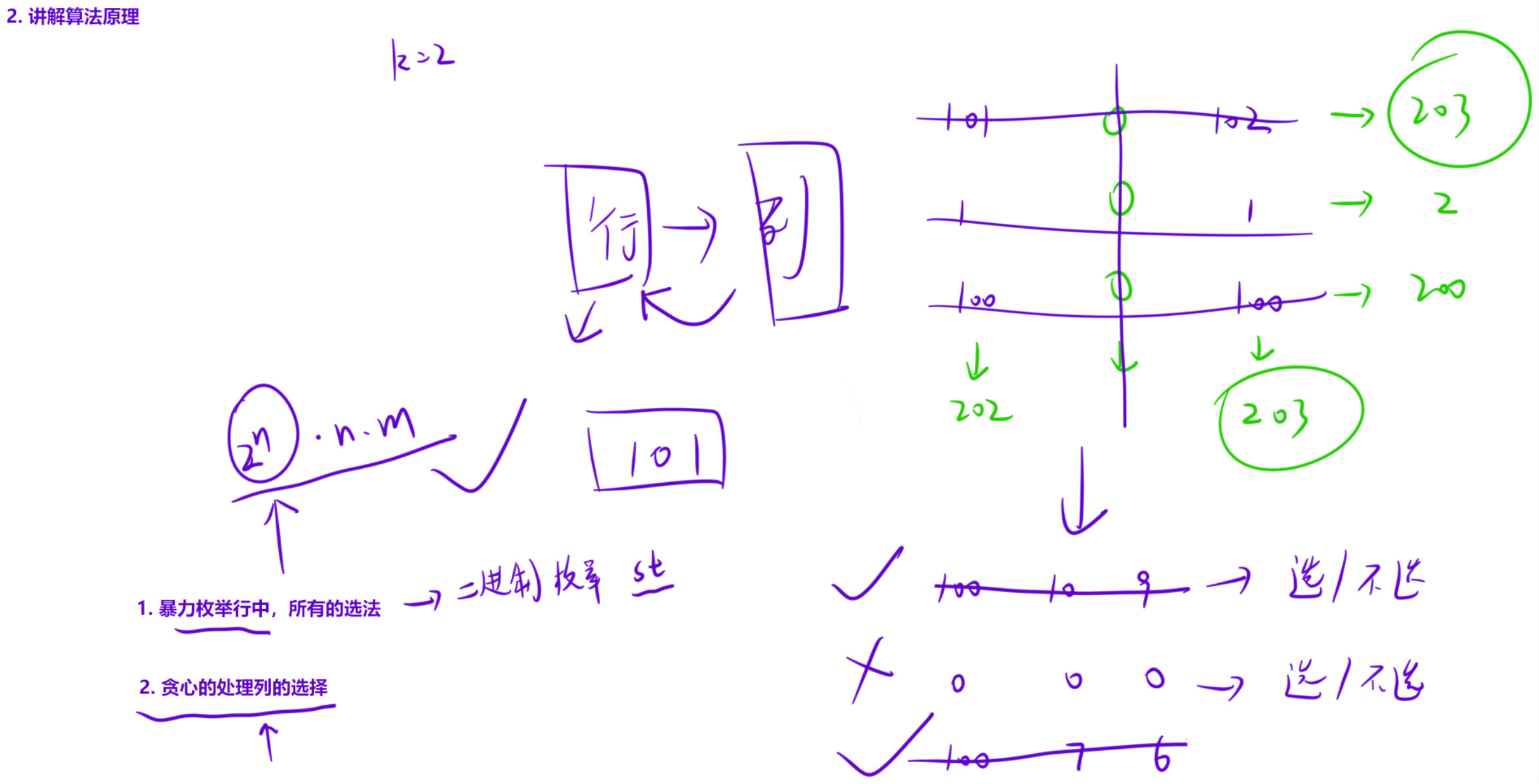
题目核心思路 :
我们有一个 n×m 的矩阵,最多进行 k 次操作:每次选择一行或一列,将其全部置 0,并获得该行 / 列所有元素的和作为分数。目标是最大化总得分。
由于 n, m ≤ 15,直接暴力枚举所有行 + 列的选择组合会超时(2^(n+m) 量级),因此代码采用枚举行的选择 + 贪心选列的优化思路:
- 先枚举所有可能的行选择方案(用二进制掩码表示),确定要消除哪些行。
- 对于剩下未被消除的行,计算每一列的和,然后贪心选择前
k - 选中行数个最大的列和,补全 k 次操作。 - 遍历所有行选择方案,取总分最大值。
cpp
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 20;
int n, m, k;
int a[N][N];
int col[N]; // 统计列和
// 统计 x 的二进制表示中 1 的个数
int calc(int x)
{
int ret = 0;
while (x)
{
ret++;
x -= x & -x;
}
return ret;
}
// 按照值从大到小排序
bool cmp(int a, int b)
{
return a > b;
}
int main()
{
cin >> n >> m >> k;
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
cin >> a[i][j];
int ret = 0;
// 暴力枚举出行的所有选法
for (int st = 0; st < (1 << n); st++)
{
int cnt = calc(st);
if (cnt > k) continue; // 不合法的状态
memset(col, 0, sizeof col);
int sum = 0; // 记录当前选法中的和
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
if ((st >> i) & 1) sum += a[i][j];
else col[j] += a[i][j];
}
}
// 处理列
sort(col, col + m, cmp);
// 选 k - cnt 列
for (int j = 0; j < k - cnt; j++) sum += col[j];
ret = max(ret, sum);
}
cout << ret << endl;
return 0;
}1. 常量与变量定义
cpp
const int N = 20; // 数组最大维度,题目n/m≤15,20足够
int n, m, k; // n行、m列、最多k次操作
int a[N][N]; // 存储矩阵的原始数值
int col[N]; // 核心辅助数组:记录「未被选中的行」中,每一列的元素和- 变量作用:
aij:第 i 行第 j 列的原始值(i/j 从 0 开始,代码用 0 索引);
colj:所有没被选中消除的行中,第 j 列的元素总和(后续用来选列得分)。
2. calc 函数:统计二进制中 1 的个数(核心工具函数)
cpp
// 统计 x 的二进制表示中 1 的个数
int calc(int x)
{
int ret = 0; // 计数:1的个数
while(x) // x>0时循环
{
ret++; // 每找到一个1,计数+1
x -= x & -x; // 核心操作:消去x最右侧的1
}
return ret;
}- 核心原理:x & -x 是计算机中快速找「最右侧 1」的位运算技巧(补码特性)。
例:x=6(二进制 110)→ x&-x=2(二进制 010)→ x -= 2 后变为 4(二进制 100);
再循环:x=4 → x&-x=4 → x -=4 后变为 0,循环结束,ret=2(6 的二进制有 2 个 1)。 - 函数作用:输入一个二进制数(行选择掩码),返回「选中的行数」(因为掩码中 1 的位置对应选中的行)。
3. cmp 函数:排序比较器
cpp
// 按照值从大到小排序
bool cmp(int a, int b)
{
return a > b;
}- 作用:给 sort 函数用,让数组降序排列(默认 sort 是升序)。
- 例:col = 10,5,20 → 调用 sort(col, col+3, cmp) 后变为 20,10,5。
- 主函数:核心逻辑(分 8 步拆解)
cpp
int main()
{
// 步骤1:输入矩阵维度、操作次数、矩阵元素
cin >> n >> m >> k;
for(int i = 0; i < n; i++)
for(int j = 0; j < m; j++)
cin >> a[i][j];
// 步骤2:初始化全局最大得分
int ret = 0;
// 步骤3:枚举所有行的选择方案(二进制掩码)
// 1<<n 等价于 2^n,st的取值范围:0 ~ 2^n -1
for(int st = 0; st < (1 << n); st++)
{
// 步骤4:计算当前方案选中的行数,跳过不合法方案
int cnt = calc(st); // cnt = 选中的行数
if(cnt > k) continue; // 选中行数超过k,无法再选列,直接跳过
// 步骤5:重置col数组为0,计算行得分+未选行的列和
memset(col, 0, sizeof col); // 每次枚举新方案,col要清零
int sum = 0; // 记录当前方案的总得分
for(int i = 0; i < n; i++) // 遍历每一行
{
for(int j = 0; j < m; j++) // 遍历每一列
{
// 判断第i行是否被选中(st的第i位是否为1)
if((st >> i) & 1)
{
// 情况1:第i行被选中 → 累加该行第j列的值到sum(行得分)
sum += a[i][j];
}
else
{
// 情况2:第i行未被选中 → 累加该值到col[j](后续列得分用)
col[j] += a[i][j];
}
}
}
// 步骤6:贪心选列(补全k次操作)
sort(col, col + m, cmp); // 列和降序排列
// 选 k - cnt 个最大的列和(剩余操作次数)
for(int j = 0; j < k - cnt; j++)
{
sum += col[j];
}
// 步骤7:更新全局最大得分
ret = max(ret, sum);
}
// 步骤8:输出最终结果
cout << ret << endl;
return 0;
}关键步骤的「具象化例子」
假设:n=2行,m=2列,k=2,矩阵为:
cpp
a[0][0]=1, a[0][1]=2 (第0行:和为3)
a[1][0]=3, a[1][1]=4 (第1行:和为7)枚举 st=1(二进制 01):
- st=1 → 二进制 01 → 第 0 行被选中(i=0 时,(1>>0)&1=1),第 1 行未被选中(i=1 时,(1>>1)&1=0);
- cnt=calc(1)=1(≤k=2,合法);
- 计算 sum 和 col:
i=0(选中行):j=0 → sum +=1;j=1 → sum +=2 → sum=3;
i=1(未选中行):j=0 → col 0 +=3;j=1 → col 1 +=4 → col=3,4; - 排序 col:降序后 4,3;
- 剩余操作次数:k-cnt=1 → 选 col 0=4 → sum=3+4=7;
- ret 更新为 7(初始 ret=0)。
枚举 st=2(二进制 10):
- st=2 → 第 1 行被选中,第 0 行未被选中;
- cnt=1,sum=7(第 1 行和),col=1,2;
- 排序后 col=2,1,选 1 个 → sum=7+2=9;
- ret 更新为 9。
枚举 st=3(二进制 11):
- st=3 → 两行都被选中;
- cnt=2,sum=3+7=10;
- 剩余操作次数 = 0 → 不选列;
- ret 更新为 10(最终结果)。
最后的最后,还没有结束,该题目还存在一个隐性的bug,我也是刚刚不经意间测了出来
若全局变量 colN 定义在 aNN 之前提交代码就不能通过示例了,按照常理来说,全局变量的定义顺序不应该影响最终结果才是
原因出在// 选 k - cnt 个最大的列和(剩余操作次数)for (int i = 0; i < k - cnt; i++) sum += col[i];i < k - cnt会发生越界访问的情况,k的数据范围是很大的,k <= n * m,k最大可以把整个矩阵所有的数选到,就是如果cnt很小(为0/1),k很大(n×m),在这一列选的时候就会超过这一列的极限(这一列的极限为m个),发生越界访问
为了避免发生这种风险,就可以使用下面的写法
cpp
// 选 k - cnt 个最大的列和(剩余操作次数)
for (int j = 0; j < min(k - cnt, m); j++) sum += col[j];若k - cnt过于大的时候,就强制把范围限制在所有的列m
先定义a数组,再定义col数组没有出错的原因是:后定义的col数组即使越界访问也是访问那些没有定义的格子,全局变量后面没有定义的格子值是0,所以后面sum累加的时候也不会出错,但是若先定义col数组,再定义a数组,两个数组在内存中存储的时候就是挨着存的,此时col数组越界的时候就会访问到a数组,a数组中的值就不是0了,所以后续累加会出错
结语
