深度优先搜索(BFS)
深度优先搜索可以类比为树形结构的遍历过程:从根节点出发,沿着一条路径尽可能深入探索,直到到达叶子节点;然后回溯到最近的未探索分支,重复上述过程,直至遍历完整棵树并最终回到根节点。该算法实现需要用到栈(后进先出,方便搜索到最深处时返回上个位置再继续往深度搜索),需要的空间为树高,不具备最短路搜索功能。该算法运行和递归函数内核差不多,最终遍历所有可能节点。
下面以实现给定输入整数n,求n位数字全排列的代码实现为例:
cpp
#include <iostream>
using namespace std;
const int N = 10;
int n;
int path[N];
bool st[N];
void dfs(int u)
{
if(u == n)
{
for(int i=0; i<n; i++) cout << path[i] << " ";
cout << endl;
return;
}
for(int i=1; i<=n; i++) // 修正:生成1~n的排列
{
if(!st[i])
{
path[u] = i;
st[i] = true; // 修正:标记i而非u
dfs(u+1); // 修正:直接传递u+1
st[i] = false;
}
}
}
int main()
{
cin >> n;
dfs(0);
return 0;
}
以下是n-皇后问题的代码实现。该算法采用DFS搜索策略,并在搜索过程中进行剪枝优化:当发现当前节点不满足条件时,立即回溯到上层节点,终止对该分支的继续搜索。这种优化在树形结构中表现为直接剪除无效的分支路径。
第一种搜索顺序:
cpp
#include <iostream>
using namespace std;
const int N = 20;
int n; // 逐行检查遍历
char g[N][N]; // 记录棋盘中每步放置什么棋子
bool col[N], dg[N], udg[N]; // 这三个数组分别标识是否棋盘摆放列冲突、正对角线冲突以及反对角线冲突
// u表示当前行处理
void dfs(int u)
{
// 处理完所有阵列打印结果后返回
if(u == n)
{
for(int i=0; i<n; i++) puts(g[i]);
puts("");
return;
}
// 逐行处理棋盘,满足条件插入皇后后马上跳转下一行,否则,继续该行往前探索,默认满足行约束
for(int i=0; i<n; i++)
if(!col[i] && !dg[u + i] && !udg[n - u + i])
{
g[u][i] = 'Q';
col[i] = dg[u+i] = udg[n-u+i] = true;
dfs(u+1);
col[i] = dg[u+i] = udg[n-u+i] = false;
g[u][i] = '.';
}
}
int main()
{
cin >> n;
// 初始化棋盘所有为.
for(int i=0; i<n; i++)
for(int j=0; j<n; j++)
{
g[i][j] = '.';
}
dfs(0);
return 0;
}第二种搜索顺序:
cpp
#include <iostream>
using namespace std;
const int N = 20;
int n; // 逐行检查遍历
char g[N][N]; // 记录棋盘中每步放置什么棋子
bool row[N], col[N], dg[N], udg[N]; // 这四个数组分别标识是否棋盘摆放行列冲突、正对角线冲突以及反对角线冲突
void dfs(int x, int y, int s)
{
// 触碰到边界返回
if(y == n) y = 0, x ++;
if(x == n)
{
// 已经放了n个皇后且触碰边界
if(s == n)
{
for(int i=0; i<n; i++) puts(g[i]);
puts("");
}
return;
}
// 不放皇后
dfs(x, y + 1, s);
// 放皇后
if(!row[x] && !col[y] && !dg[x + y] && !udg[x - y + n])
{
g[x][y] = 'Q';
row[x] = col[y] = dg[x + y] = udg[x + y + n] = true;
dfs(x, y+1, s+1);
row[x] = col[y] = dg[x + y] = udg[x + y + n] = false;
g[x][y] = '.';
}
}
int main()
{
cin >> n;
// 初始化棋盘所有为.
for(int i=0; i<n; i++)
for(int j=0; j<n; j++)
{
g[i][j] = '.';
}
dfs(0, 0, 0);
return 0;
}广度优先搜索(DFS)
广度优先搜素也可以类比为树形结构的遍历工程:从根节点出发,一圈一圈往外搜索,直到叶子节点。该算法实现需要用到队列(先进先出,先访问根节点周边节点再不断扩散出去搜索),需要的空间为2^h(h为树高),在各边权重相等情况下可以作为最短路算法使用。大致实现思路是初始化一个队列,之后只要队列不为空每次从队列中弹出首元素处理,之后根据该元素再判断是否将新元素加入队列中。
例如比较经典的走迷宫的题目,给定输入n和m表示迷宫的长和宽,迷宫中每个点取值0或1(0表示该点可通过,1表示该点不可走),可用BFS实现求起点到某点的最短路径,代码实现如下:
cpp
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef pai<int, int> PII;
const int N = 110;
int n, m; // 迷宫的长和宽
int g[N][N]; // 迷宫每点是否可以通行
int d[N][N]; // 记录起始点到达各点最短距离
PII q[N*N]; // 辅助队列实现BFS
int bfs()
{
int hh=0, tt=0; // 顺序存储实现队列
q[0] = {0,0}; // 初始化队列
memset(d, -1, sizeof d);
d[0][0] = 0; // 初始化距离数组
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1}; // dx和dy朝x和y方向相互配合,共同形成元素移动四个方位
// 算法主循环
while(hh <= tt)
{
auto t = q[hh ++];
for(int i = 0; i < 4; i++)
{
// 向周边移动
int x = t.first + dx[i], y = t.second + dy[i];
// 在有效范围内才会更新队列以及距离数组
if(x >= 0 && x < n && y >= 0 && y < m && g[x][y] == 0 && d[x][y] == -1)
{
d[x][y] = d[t.first][t.second] + 1;
q[++ tt] = {x, y};
}
}
}
return d[n-1][m-1];
}
int main()
{
cin >> n >> m;
for(int i=0; i<n; i++)
for(int j=0; j<m; j++)
cin >> g[i][j];
cout << bfs() << endl;
return 0;
}树和图的存储
树可以看成是一种特殊的图,无向图又可以看成是一种特殊的有向图,因此,只要学会有向图存储和使用即可。图存储要么采用邻接矩阵存储(适合稠密图)要么就是邻接表存储(适合稀疏图)。
以下举例树的重心的算法题代码实现:
cpp
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 10010, M = N * 2;
int n; // 图中有几个节点
int h[N], e[M], ne[M], idx; // 用来实现顺式存储邻接表所需
bool st[N]; // 标识某节点是否已被访问处理
int ans = N; // 存储全局连通分量节点数量最低值
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
// 以u为根节点的树的子树中点的数量
int dfs(int u)
{
st[u] = true; // 标记一下,已经被搜索过了
// res记录子树中最大连通分量节点数
int sum = 1, res = 0;
for(int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if(!st[j])
{
int s = dfs(j);
res = max(res, s);
sum += s;
}
}
res = max(res, n - sum);
ans = min(ans, res);
return sum;
}
int main()
{
cin >> n;
memset(h, -1, sizeof h);
// 采用顺序存储实现的邻接表存储节点
for(int i = 0; i < n-1; i++)
{
int a, b;
cin >> a >> b;
add(a, b), add(b, a);
}
dfs(1);
cout << ans << endl;
}有向图的拓扑序列
只有有向无环图才存在拓扑序列,算法大致流程为先扫一遍将所有度为0的节点加入队列,之后只要队列不空,就将首个元素弹出队列,将这个节点所指所有节点的度都减1,之后这些节点如果度变为0后则将这些节点再次加入队列中,循环这个过程,最终判断是否所有节点都加入过队列即可,算法代码实现如下:
cpp
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 10010;
int n, m; // 图中有几个节点
int h[N], e[M], ne[M], idx; // 用来实现顺式存储邻接表所需
int d[N], q[N]; // d存储节点的度,q是辅助队列
bool topsort()
{
int hh = 0, tt = -1;
// 所有度为0的节点都放入队列
for(int i = 1; i <= n; i++)
if(!d[i])
q[++ tt] = i;
while(hh <= tt)
{
int t = q[hh ++];
for(int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
d[j] --;
if(d[j] == 0) q[++ tt] = j;
}
}
return tt == n - 1;
}
int main()
{
// n个节点m条边
cin >> n >> m;
memset(h, -1, sizeof h);
// 采用顺序存储实现的邻接表存储节点
for(int i = 0; i < m; i++)
{
int a, b;
cin >> a >> b;
add(a, b);
d[b] ++;
}
if(topsort())
{
for(int i = 0; i < n; i ++) printf("%d", q[i]);
puts("");
}
else puts("-1");
return 0;
}最短路径算法
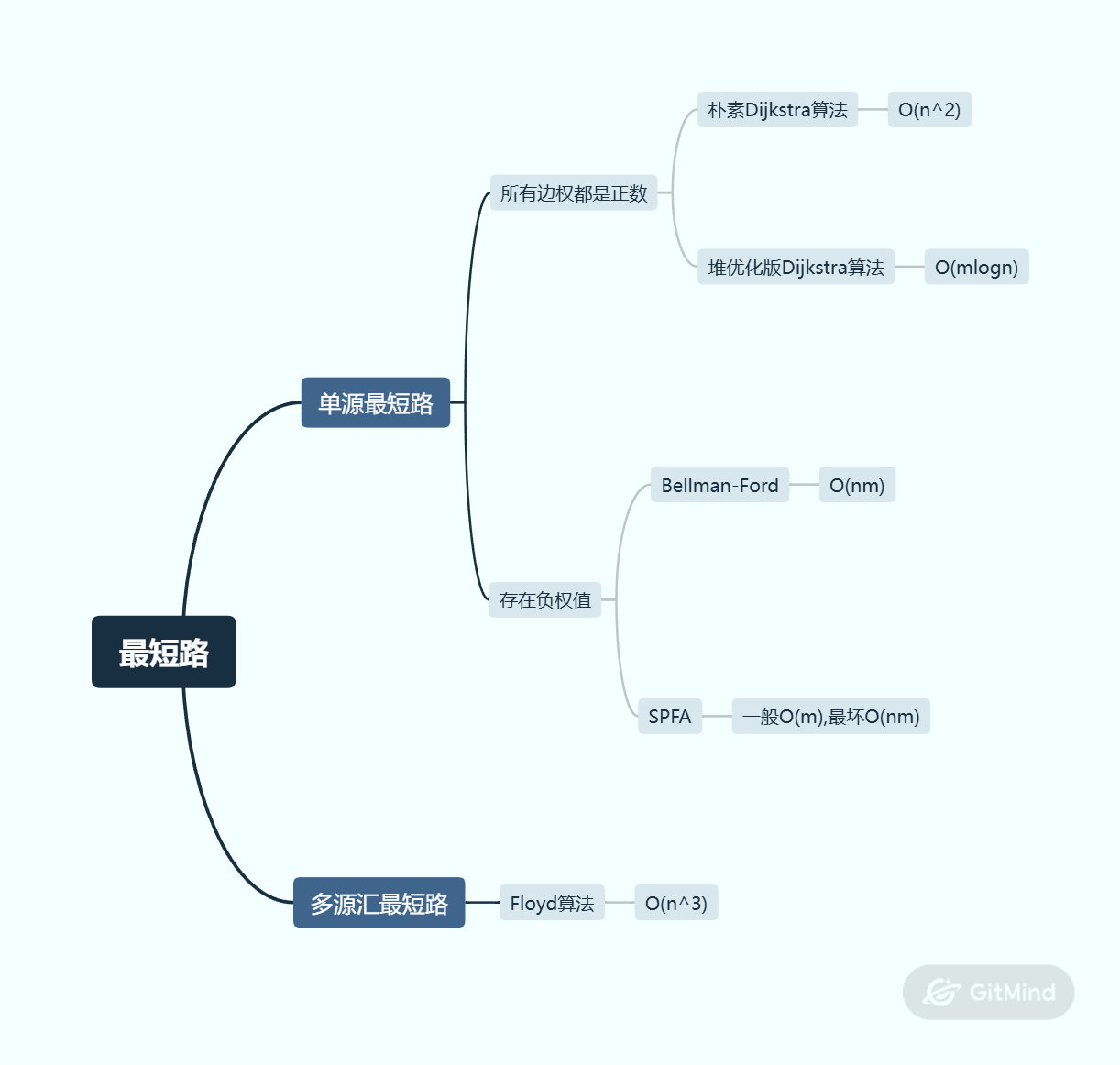
朴素Dijkstra算法
算法流程如下:
- 初始化距离数组(起始点设为0,其余点设为正无穷表示不可达)
- 依次遍历所有节点,每轮执行以下操作:
- 从距离数组中选择当前距离最小的点
- 以该点作为中转点,更新其他节点的距离(若通过该中转点可缩短距离)
- 重复上述过程,直至所有节点都被处理完毕
算法代码模板如下:
cpp
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 510;
int n, m;
int g[N][N]; // 邻接矩阵存储节点信息
int dist[N]; // 距离数组存储节点到其余节点距离
bool st[N]; // 标记当前节点是否已被访问
int dijkstra()
{
// 距离数组初始化
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
// 寻找dist数组中距离最小值
for(int i = 0; i < n; i++)
{
int t = -1;
for(int j = 1; j <= n; j++)
{
if(!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
}
st[t] = true;
// 找到最小值后更新距离数组
for(int i = 0; i < n; i++)
dist[j] = min(dist[j], dist[t] + g[t][i]);
}
if(dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
int main()
{
scanf("%d%d", &n, &m); // n表示节点m表示边
memset(g, 0x3f, sizeof g);
// 邻接矩阵存储图
while(m --)
{
int a, b, c;
cin >> a >> b >> c;
g[a][b] = min(g[a][b], c); // 防止出现多重边特殊处理
}
int t = dijkstra();
printf("%d\n", t);
return 0;
}堆优化版Dijkstra算法
该算法基于朴素版基础上将算法主流程循环中寻找dist数组中最小值的这个过程用堆来查找,可以优化到O(1),那么算法主要时间开销就是维护堆(O(mlogn)),算法原本流程时间复杂度优化为O(n),算法代码模版如下:
cpp
#include <cstring>
#include <iostream>
#include <queue>
#include <algorithm>
using namespace std;
typedef pair<int, int> PII;
const int N = 10010;
int n, m;
int h[N], e[N], ne[N], w[N], idx; // 用顺序存储实现邻接表存储图
int dist[N]; // 距离数组存储节点到其余节点距离
bool st[N]; // 标记当前节点是否已被访问
// 邻接表添加节点信息
void add(int a, int b, int c)
{
e[idx] = b, ne[idx] = ne[h[a]], h[a] = idx, w[idx] = c, idx ++;
}
int dijkstra()
{
// 距离数组初始化
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
// 小根堆初始化
priority_queue<PII, vector<PII>, greater<PII> heap;
heap.push({0, 1});
// 算法主循环流程
while(heap.size())
{
auto t = heap.top();
heap.pop();
int ver = t.second, distance = t.first;
if(!st[ver]) continue;
for(int i = h[ver]; i != -1; i = ne[i])
{
int j = e[i];
if(dist[j] > distance + w[i])
{
dist[j] = distance + w[i];
heap.push({dist[j], j});
}
}
}
if(dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
int main()
{
scanf("%d%d", &n, &m); // n表示节点m表示边
memset(g, 0x3f, sizeof g);
// 邻接矩阵存储图
while(m --)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
int t = dijkstra();
printf("%d\n", t);
return 0;
}Bellman-Ford算法
该算法包含两层循环,外层循环n次,内层循环遍历所有边,对每一条边做距离数组的松弛操作。可以利用该算法来检测是否存在负环(存在经过边数为n的最短路径),该算法可以允许处理负环是因为该算法返回的路径要求小于等于k条边,算法代码模版如下:
cpp
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
typedef pair<int, int> PII;
const int N = 1010, M = 1010;
int n, m, k;
int dist[N], backup[N];
struct Edge{
int a, b, w;
}edges[M];
int bellman_ford()
{
for (int i = 0; i < n; i++)
{
memcpy(backup, dist, sizeof dist); // 防止出现"串联",满足题目不超过k条边的最短路径的条件
for(int j = 0; j < m; j++)
{
int a = edges[j].a, b = edges[j].b, w = edges[j].w;
dist[b] = min(dist[b], dist[a] + w);
}
}
if(dist[n] > 0x3f3f3f3f / 2) return -1;
return dist[n];
}
int main()
{
scanf("%d%d%d", &n, &m, &k);
for(int i = 0; i < m; i++)
{
int a, b, w;
cin >> a >> b >> w;
edges[i] = {a, b, w};
}
int t = bellman_ford();
if(t == -1) puts("impossible");
else cout << t;
return 0;
}SPFA
该算法无法处理含负环的图结构,其核心思想是对Bellman-Ford算法的松弛过程进行优化。根据松弛操作的数学特性可知,只有当某节点的距离值dist减小时,才可能对其相邻节点进行有效松弛。因此,该算法采用广度优先遍历策略,通过队列机制避免无效节点访问:首先将起始点入队初始化,在每轮迭代中依次取出队首节点尝试松弛其邻接节点,若松弛成功则将被松弛节点加入队列。算法实现模板如下:
cpp
#include <queue>
#include <iostream>
#include <algorithm>
using namespace std;
typedef pair<int, int> PII;
const int N = 1010;
int n, m;
int h[N], w[N], e[N], ne[N], idx;
int dist[N];
bool st[N];
void add(int a, int b, int c)
{
e[idx] = b, ne[idx] = ne[h[a]], h[a] = idx, w[idx] = c, idx ++;
}
int spfa()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
queue<int> q;
q.push(1);
st[1] = true; // 标记哪些节点已加入节点,不重复加入
while(q.size())
{
int t = q.front();
q.pop();
st[t] = false;
for(int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if(dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
if(!st[j])
{
q.push(j);
st[j] = true;
}
}
}
}
if(dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
int main()
{
scanf("%d%d", &n, &m);
memset(h, -1, sizeof h);
while(m --)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
int t = spfa();
if(t == -1) puts("impossible");
else cout << t << endl;
return 0;
}Floyd算法
先初始化邻接矩阵存储节点距离关系,算法思想每轮次中依次选择一个节点作为中转点是否能松弛其他节点,能松弛则更新dist邻接矩阵。
cpp
void floyd()
{
for(int k = 1; k <= n; k++)
for(int i = 1; i <= n; i++)
for(int j = 1; j <= n; j++)
{
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}
}最小生成树
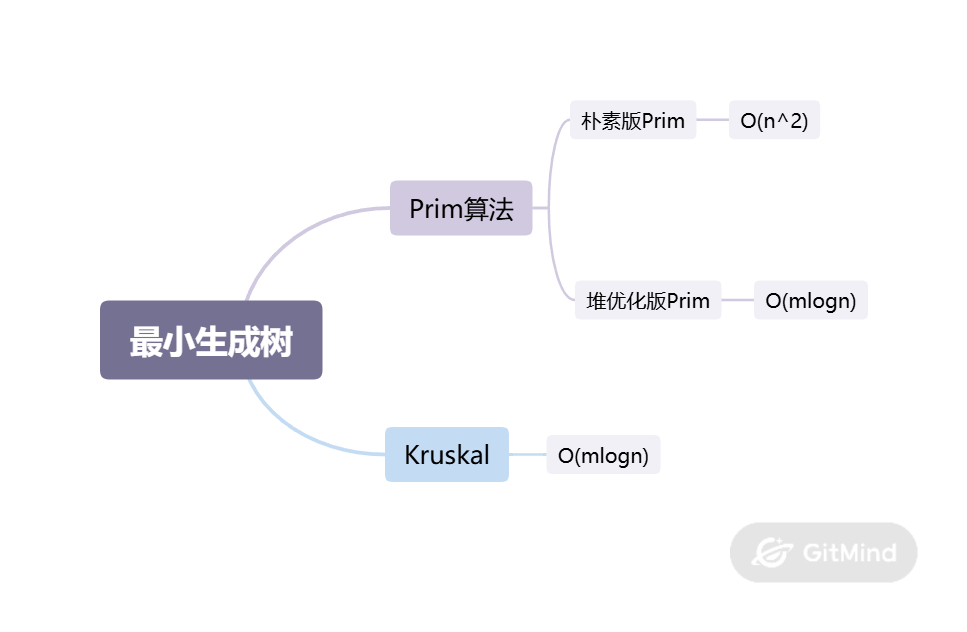
Prim算法
该算法是一种用于在加权连通图中寻找最小生成树(MST) 的贪心算法。它的核心思想是"从一点出发,不断生长",通过不断寻找连接"已选顶点"和"未选顶点"之间权值最小的边,逐步将整棵树构建出来。算法的代码模版如下:
cpp
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, INF = 0x3f3f3f3f;
int n, m;
int g[N][N]; // 邻接矩阵存储图
int dist[N]; // 距离数组存储的是集合外点到集合中所有点最近距离
bool st[N]; // 标记节点是否在集合中
int prim()
{
memset(dist, 0x3f, sizeof dist); // 初始化dist
int res = 0; // 记录最小生成树中所有选中边权之和
for(int i = 0; i < n; i ++) // 依据算法每次选中一个节点加入集合中
{
int t = -1;
for(int j = 0; j < n; j ++) // 选出选中集合外dist中最小值也就是距离集合距离最小的点
if(!st[j] && (t == -1 || dist[j] > dist[j]))
t = j;
if(i && dist[t] == INF) return INF;
if(i) res += dist[t];
for(int j = 0; j < n; j++) dist[j] = min(disj[j], g[t][j]); // 更新dist
st[t] = true;
}
}
int main()
{
cin >> n >> m;
memset(g, 0x3f, sizeof g);
while(m --)
{
int a, b, c;
cin >> a >> b >> c;
g[a][b] = g[b][a] = min(g[a][b], c); // 防止出现多重边处理,只记录其中最小的那个边
}
int t = prim();
if(t == INF) puts("impossible");
else cout << t;
return 0;
}Kruskal算法
将所有边按照权重从小到大排序,从小到大枚举每条边,如果这个边对应两个节点不在选定集合内,那就加入,否则略过。算法模版如下:
cpp
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 10010;
int n, m;
int p[N]; // 并查集的数组
struct Edge
{
int a, b, w;
bool operator< (const Edge &w)const
{
return w < W.W;
}
}edges[N];
int find(int x)
{
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
int main()
{
cin >> n >> m;
for(int i = 0; i < n; i ++)
{
int a, b, w;
cin >> a >> b >> w;
edges[i] = {a, b, w};
}
sort(edges, edges + m); // 排序,最大时间开销
for(int i = 1; i <= n; i ++) p[i] = i; // 并查集数组初始化
int res = 0, cnt = 0;
for(int i = 0; i < m; i++)
{
int a = edges[i].a, b = edges[i].b, w = edges[i].w;
a = find(a), b = find(b);
if(a != b)
{
p[a] = b;
res += w;
cnt ++;
}
}
if(cnt < n-1) puts("impossible");
else cout << t;
return 0;
}二分图
二分图定义是可以把所有的点划成两边两部分,每部分内节点之间没有边连接。这个限制条件也可以是当且仅当图中不存在奇数环。
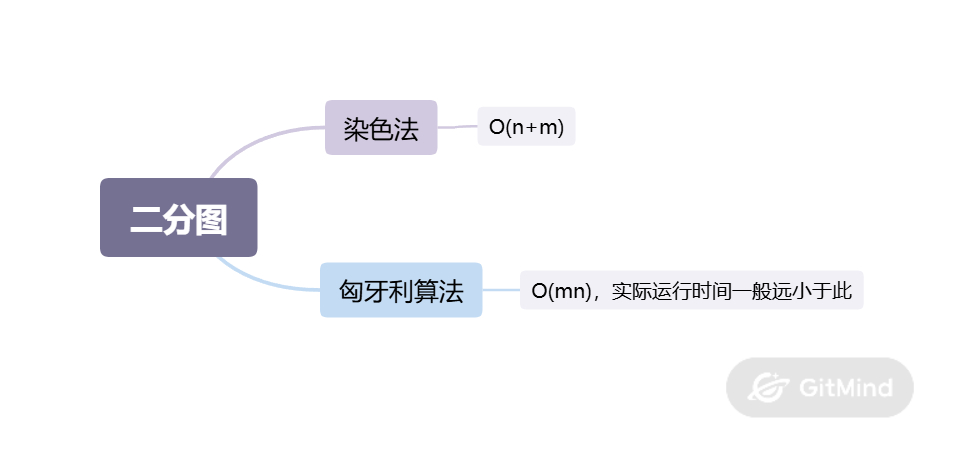
染色法
采用深度优先搜索从当前节点开始逐个进行染色处理。根据二分图的定义可知,若某个节点被染成一种颜色,则其所有相邻节点都必须染成相反颜色,否则该图就不是二分图。算法实现模板如下:
cpp
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 10010, M = 20010;
int n, m;
int h[N], e[M], ne[M], idx;
int color[N];
void add(int a, int b)
{
e[idx] = b, ne[idx] = ne[h[a]], h[a] = idx, idx ++;
}
bool dfs(int u, int c)
{
color[u] = c;
for(int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if(!color[j])
{
if(!dfs(j, 3-c)) return false;
}
else if (color[j] == c) return false;
}
return true;
}
int main()
{
cin >> n >> m;
memset(h, -1, sizeof h);
while(m --)
{
int a, b;
cin >> a >> b;
add(a, b), add(b, a);
}
bool flag = true;
// 防止有多个连通分支,遍历所有节点
for(int i = 1; i <= n; i ++)
{
if(!color[i])
{
if(!dfs(i, 1))
{
flag = false;
break;
}
}
}
if(flag) puts("yes");
else puts("no");
return 0;
}匈牙利算法
该算法可以告诉我们在一个二分图中成功匹配边的数量最大值。代码实现如下:
cpp
#include <iostream>
#include <algorithm>
using namespace std;
const int N =510, M = 10010;
int n1, n2, m;
int h[N], e[N], ne[N], idx;
int match[N];
bool st[N];
void add(int a, int b)
{
e[idx] = b, ne[idx] = ne[h[a]], h[a] = idx, idx ++;
}
bool find()
{
for(int i = h[x]; i != -1; i ++)
{
int j = e[i];
if(!st[j])
{
st[j] = true;
if(match[j] == 0 || find(match[j]))
{
match[j] = x
return true;
}
}
}
return false;
}
int main()
{
cin >> n1 >> n2 >> m;
memset(h, -1, sizeof h);
while(m --)
{
int a, b;
cin >> a >> b;
add(a, b);
}
int res = 0;
for(int i = 1; i <= n1; i ++)
{
memset(st, false, sizeof st);
if(find(i)) res ++; // 运行算法看是否该节点可找到点匹配
}
cout << res;
return 0;
}