Java 性能优化
基础
-
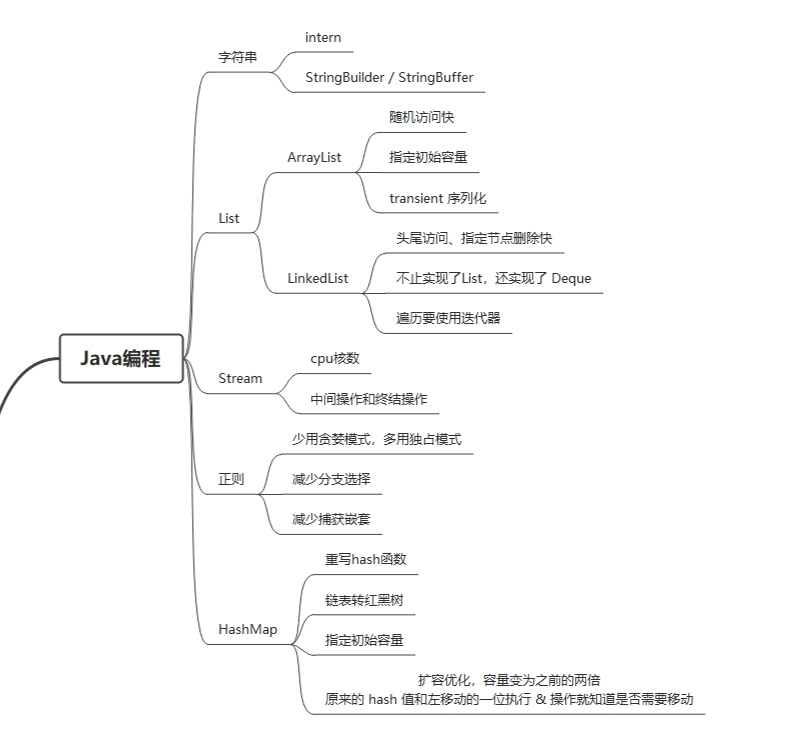
String 类在 jdk 的发展中发生过几次大变化,分别是 jdk7 和 jdk9,主要是改变了存储结构以节省内存空间,由于 String 中的值被 final 修饰(便于共享同一字符串,如 jvm 的字符串常量池),因此每次赋值都会产生新的 String 对象,所以在拼接字符串时可用 StringBuilder/StringBuffer 替换 str1 + str2 这样的操作。
String.intern() 方法可以显式的将字符串内容驻留在字符串常量池中,特定场景下能节省很多内存,如下代码:
java
String sql = "select ID, LOCATION, NAME, ... from INFO";
queryForList = jdbcTemplate.queryForList(sql);
List<InfoListVo> collect = new ArrayList<>(queryForList.stream().map(item -> {
InfoListVo temp = new InfoBmxxListVo();
Long infoId = MapUtils.getLong(item, "ID");
temp.setId(infoId)
.setLocation(MapUtils.getString(item, "LOCATION", ""))
.setName(MapUtils.getString(item, "NAME", ""));
return temp;
}).collect(Collectors.toList())); 第 7 行的 location 字段在一般场景下都是固定数量的,例如全省的地市数,另外像性别等这样的字段,使用 intern() 可以驻留在常量池中共享同一个对象。
java
.setLocation(MapUtils.getString(item, "LOCATION", "").intern())-
List 的诸多特性非常多的文章中已经提到了,这里只强调一点:LinkedList 只在头尾或给定节点操作效率高,多数情况下 ArrayList 由于 cpu 缓存等原因一般情况下还是更快。
-
stream 的效率在少量数据时未必比正常迭代高,只是提供了优雅的链式调用,并行流需要考虑 cpu 核数。
-
正则表达式的使用要慎重,复杂的正则表达式在匹配过程中经常会引起回溯问题。大量的回溯会长时间地占用 CPU,在使用过程中应减少分支选择与捕获嵌套。
-
HashMap 在 jdk8 也发生了一些变化,解决了多线程扩容可能死循环的问题,在链表过长时会转为红黑树结构。同时其中也有一些值得学习的地方,取模时如果 length 是 2^n,那么可以 & (2^n - 1),在扩容时也不需要重新计算哈希值。
对于容器类(List、Map)以及 StringBuilder 等需要考虑扩容的对象,在创建时都推荐指定一个初始容量以避免多次扩容。
多线程
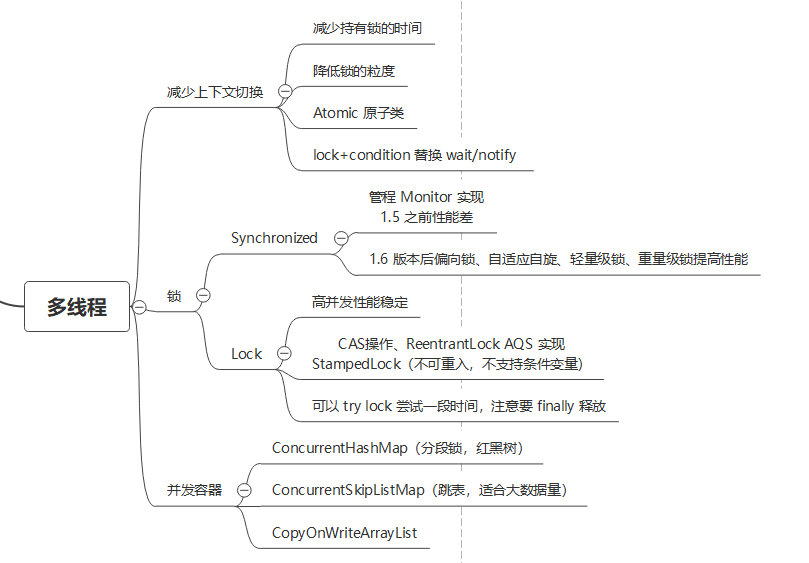
锁的底层其实只有两种,也体现了面对阻塞时的两种态度,是自旋还是阻塞。自旋锁出现的原因是有些行为非常短暂,阻塞的时间可能已经执行完成了,没有必要进行上下文切换,等一下就好。
Synchronized 由 Monitor 实现(自动生成字节码指令),涉及内核态操作,在 jdk6 之前没有进行过优化,性能差。后来随着性能优化以及锁升级等发展,性能目前并不比用户态的 Lock 差,通过自旋、自适应自旋及对象头的偏向锁、轻量级锁、重量级锁进行锁升级来实现。
Lock 是 Java 底层代码实现的,支持在获取时 try lock 尝试,也要注意在 finally 代码块中释放,高并发情况下性能会比容易升级为重量级锁的 Synchronized 稳定,同时有很多实现类,例如 ReentrantReadWriteLock(读写分离锁)。
在使用锁的时候要注意锁的粒度,可以锁代码块就不要锁方法,只锁必要的代码块,可以用 CAS、Atomic 等原子操作实现的代码就不用上升到锁。
ConcurrentHashMap 并发容器就是降低了锁的粒度,只锁对应的 segment 段,而不是锁整个对象,CoryOnWriteArratList 则是在有修改操作时复制一个新的执行修改操作,修改完成后原有对象的引用指向这个新的。
网络编程
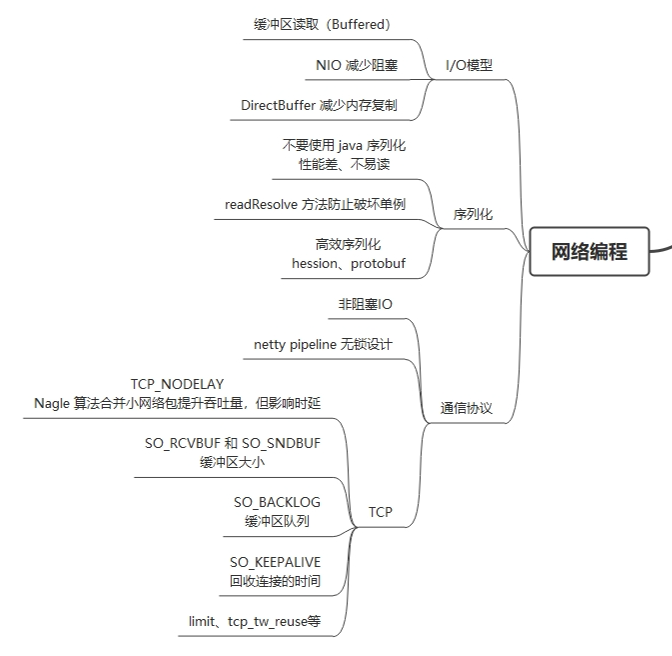
平时提到的 IO 既包括文件的IO,也指网络 IO。
在读取文件流时,使用 Bufferd 接收往往比直接 read 性能要好,因为减少了状态切换以及最大化利用缓冲区,如果是下载文件这样根本不需要业务层做改变的业务,可以利用零拷贝等技术减少文件内容的拷贝。
IO 模型中当前主流的 NIO 可以用少数线程维持数千个连接,是网络编程的基础。在网络通信(包括RPC)中,序列化机制也是值得深入考虑的部分,json、xml 易读性好但序列化后的体积大,hession、protobuf 则序列化的性能更好,相同的环境下,序列化的体积越小,自然发送给对方的速率也就更快。
除了应用层可以考虑的IO模型、序列化机制,操作系统本身的配置也会对性能产生影响,可调整的选项很多,包括但不限于syn、fin报文重试次数、半连接队列大小、拥塞控制算法等。
JVM
随着 jdk 版本的更新,JVM 也进行了诸多优化。
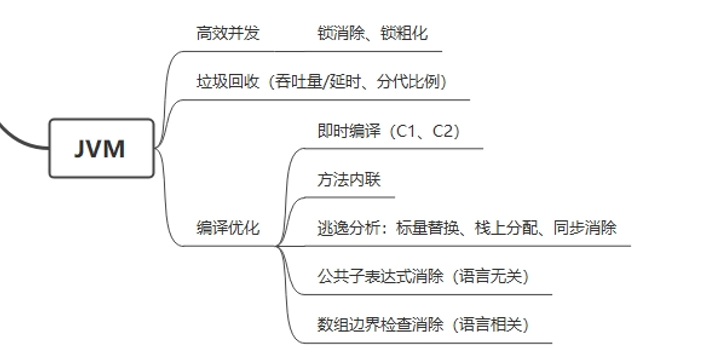
锁消除指的是在一段代码中如果不可能出现并发问题,那么即使加了锁也可能会被去除掉
java
public String concatString(String s1, String s2, String s3) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}由于字符串的作用域都在方法内,且 String 具有不可变性,StringBuffer 又通过锁实现了线程安全,那么这段代码中的 StringBuffer 就可能优化为 StringBuilder 实现。
锁粗化则是指,如果取锁、做A操作、释放锁;再取锁、做B操作、再释放锁,这样的操作可能被合并为先取锁,再做AB操作,最后释放锁。
垃圾回收从历代垃圾收集器的更新来看,几乎是在吞吐量和停用时延上做取舍,涉及到相当多的算法和概念,如标记整理(整理需要消耗时间,但整理后会内存分配等会省事)、标记清除(直接清除,停用时延小,多次清除后再整理一次)。
JVM 的编译优化也很复杂,即时编译通过分析热点代码缓存对应的机器码指令,方法内联减少了执行的方法数(减少虚拟机方法栈的操作),逃逸分析在分析出对象不会逸出后可能进行标量替换(对象的属性替换为直接的私有值,例如 user.age=3 变为 int age = 3),栈上分配(堆内存公用,分配可能加锁,同时栈内存方法执行完直接释放),同步消除(无需进行同步的代码块),公共子表达式消除(IDEA 其实会提示,例如在后面写了 list.size(), 在前面在定义 int size = list.size() 时会提示是否也替换掉下面的这个表达式)等等等等
设计模式
设计模式的初衷也许并不是为了性能,只是为了解耦和提升可拓展性,只是恰好某些设计模式也可以提高性能。
单例模式创建单一对象,诸如恶汉式、懒汉式、双重检测锁、静态内部类方式不再赘述,单例一般是单进程或者说单服务的单例,线程内单例可以借助 ThreadLocal 实现。
观察者模式可以在主流程执行完成并通知消费者后直接返回,由消费者异步执行其他步骤,减少响应时间。
原型模式提供了快速复制对象的手段,如 clone 接口。
享元模式则是共享对象,字符串常量池、Integer 的缓存。
数据库

数据库的物理优化即选择合适的索引,索引覆盖(查询的列就在索引上)、索引下推(过滤条件在索引上)、自增主键(减少页分裂)、最左匹配(索引匹配)均可不同程度的提高数据库性能。
在数据库的执行过程中,redolog、undolog 及用到的缓冲池 buffer_pool 等参数也会影响数据库的性能,但这些参数的修改最好经过测试环境验证后再正式上线。
在执行事务操作时,注意事务的顺序,某事务先操作表1再操作表2,另一事务先操作表2再操作表1则可能产生死锁,例如购物(先减自己再加商家)和退货事务(先减商家再增自己),原因是事务在执行时获取的锁结束时才释放。
分布式
分布式系统中的分布式锁、分布式事务、一致性等都是值得详细了解的东西。
常用的分布式锁诸如 Redis、Zookeeper 等都不是绝对安全的, Redis 中假如 5 个节点,A 服务获取了前三个节点的锁,开始执行事务,此时第三个节点主节点挂了,但数据还未同步到从节点,B 服务取得了后三个节点的锁,也开始执行事务,这就是一个典型的锁失效场景。同时使用 Redis 失效分布式锁,锁的时间也非常值得考量,使用时一定要注意命令的原子性。在多个业务同时取锁时还会发送冲突,可能多个业务都取不到,因为取到锁的前提是在一半以上的节点上成功加锁。
Zookeeper 的好处是不用担心业务挂了来不及释放锁,ZK 会通过维持会话来判断,但问题也出现在这,如果业务因为GC等原因会话过期,ZK 删除了业务节点,那么其他业务就可能取锁成功,此时两个业务都会认为自己拿到了分布式锁,进而一起操作共享资源。好处是比起 Redis 不担心锁超时,并减少了业务上锁时候的冲突。
这里引入一个业界大佬当时的结论:如果为了效率使用分布式锁,那么单节点 Redis 可能已足够,但如果是为了安全,请一定慎之又慎。
分布式事务涉及到的东西也很繁杂,我的看法是能不使用就不使用,2PC、3PC只能用于单服务执行分布式事务,阻塞等待 RM 响应时性能一般,TCC 对业务代码侵入性强,目前系统中使用 Seata 的比较多,对业务没有那么大的侵入性,通过 MQ 等实现最终一致性是大多数场景下都能接受的手段。
同时分布式系统中还有 AKF、CAP、BASE 理论及 一致性哈希、NWR 算法理论等,在合适的场景下使用也可以提高系统性能。