一、论文基本信息
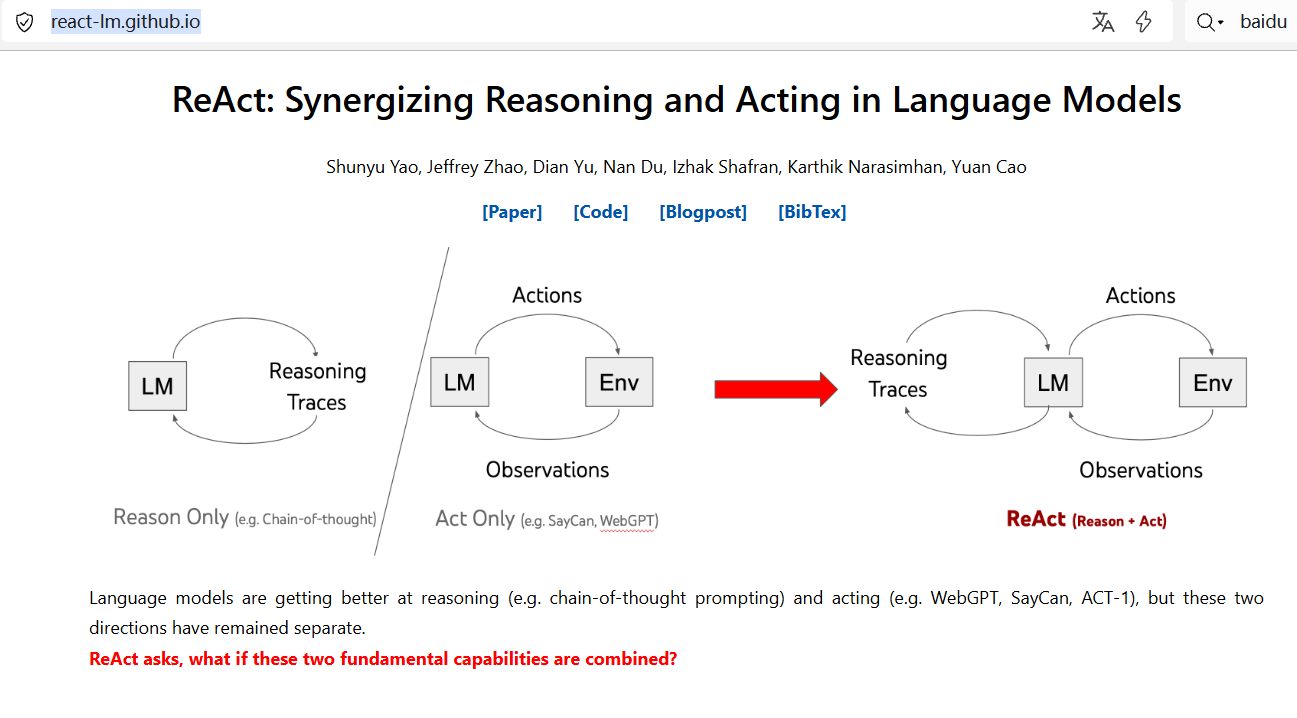
《ReAct: Synergizing Reasoning and Acting in Language Models》(以下简称"ReAct")是2023年ICLR会议的经典论文,由普林斯顿大学与谷歌大脑团队合作完成。论文针对大型语言模型(LLMs)"推理与行动分离"的局限,提出"推理-行动协同"的通用框架,推动LLMs从"文本生成器"向"通用问题解决器"演进。
原文:
https://arxiv.org/pdf/2210.03629

二、研究背景与问题
1. 现有方法的局限
论文指出,传统LLMs的应用范式存在两大割裂:
- 仅推理(如Chain-of-Thought, CoT) :依赖模型内部知识生成思维链,但无法与外部世界交互,易导致事实幻觉 (如生成虚假信息)和错误传播(前序推理错误导致后续结论偏差)。
- 仅行动(如WebGPT) :专注于生成与外部交互的动作(如搜索、点击),但缺乏高层规划 (如目标分解)和工作记忆(如跟踪任务进度),在复杂任务中易"迷失方向"(如重复无效动作)。
2. 研究问题
论文核心解决:如何让LLMs在解决复杂任务时,同时具备"逻辑推理能力"与"外部交互能力",实现"思考指导行动、行动反馈思考"的动态协同?
三、ReAct核心框架
ReAct的本质是**"推理轨迹(Thought)"与"任务动作(Action)"的交错生成**,通过"思考-行动-观察"(Thought-Action-Observation)循环,实现推理与行动的协同。
1. 核心概念
- 推理轨迹(Thought) :模型生成的自然语言思考过程,用于分解目标、制定计划、跟踪进度、处理异常(如"我需要先搜索苹果遥控器的初始用途")。
- 任务动作(Action) :模型生成的外部交互指令,用于获取信息或执行操作(如"搜索苹果遥控器")。
- 观察(Observation) :动作执行后的环境反馈(如"苹果遥控器最初用于控制Front Row媒体中心"),用于更新模型上下文。
2. 形式化定义
ReAct扩展了传统智能体的动作空间,将动作分为两类:
- 外部动作(A):直接影响环境的动作(如搜索、点击),会触发观察反馈。
- 内部动作(L) :不直接改变环境的推理轨迹(如思考、规划),仅更新模型内部上下文。
最终动作空间为:A^=A∪L\hat{A} = A \cup LA^=A∪L,其中LLL为语言空间(推理轨迹的集合)。
3. 实现机制
ReAct通过**少样本提示(Few-Shot Prompting)**引导模型生成"推理-行动"序列,无需微调模型。具体流程:
- 输入:用户问题(如"苹果遥控器最初设计用于控制什么设备?")。
- 提示:提供少量"推理-行动-观察"示例(如"搜索苹果遥控器→观察结果→思考下一步"),引导模型模仿。
- 循环生成:模型交替生成"Thought"(推理)→"Action"(行动)→"Observation"(观察),直至完成任务(如"搜索Front Row→观察结果→得出结论")。
4. 灵活性与通用性
ReAct支持稀疏/密集思考适配不同任务:
- 知识密集型任务(如HotpotQA多跳问答) :采用密集思考(每一步行动前均有推理),确保逻辑严谨。
- 交互式决策任务(如ALFWorld文本游戏) :采用稀疏思考(仅在关键节点生成推理),减少冗余。
四、实验验证与结果
论文在四大类任务上验证了ReAct的有效性,覆盖知识推理、事实验证、交互决策等场景:
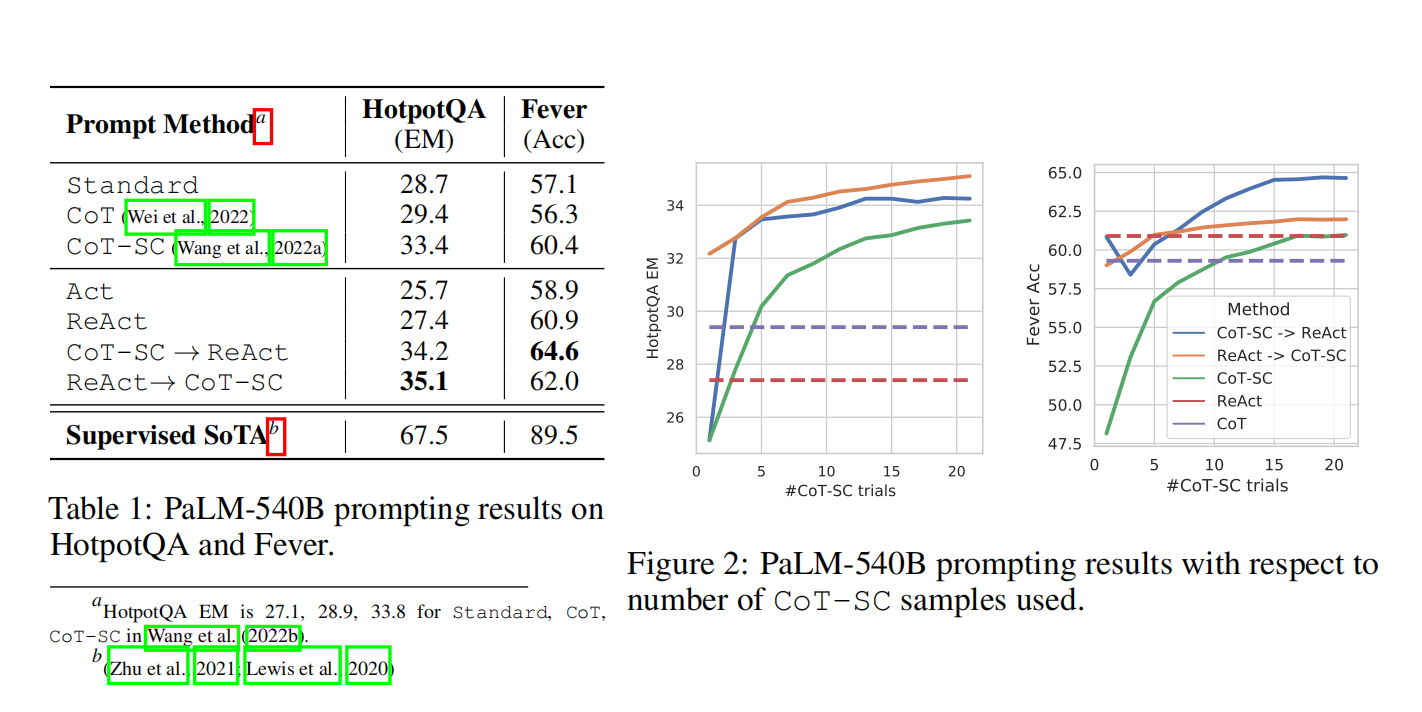
1. 知识密集型推理任务(HotpotQA、FEVER)
- 任务:多跳问答(HotpotQA)、事实验证(FEVER)。
- 动作空间 :模拟人类使用维基百科的方式,设计
search[entity](搜索实体)、lookup[string](查找字符串)、finish[answer](提交答案)三类动作。 - 结果 :
- ReAct在HotpotQA(EM得分27.4)、FEVER(准确率60.9)上显著优于仅行动基线 (Act-Only),且幻觉率远低于CoT(ReAct幻觉率0% vs CoT 56%)。
- 与CoT-SC(自洽CoT)结合的策略(ReAct→CoT-SC),在HotpotQA(35.1)、FEVER(64.6)上达到最优性能,证明"内部推理+外部知识"的互补性。
2. 交互式决策任务(ALFWorld、WebShop)
- 任务:文本游戏(ALFWorld,如"将胡椒瓶放入抽屉")、网页购物(WebShop,如"寻找符合要求的除臭剂")。
- 结果 :
- ReAct在ALFWorld上的成功率(71%)远超模仿学习(37%)、强化学习(45%),且仅需1-2个示例。
- ReAct在WebShop上的**成功率(40%)**比模仿学习(30%)、强化学习(30%)高10%,证明"常识推理+外部交互"的有效性。
3. 微调实验
论文用ReAct生成的3000条"正确轨迹"微调小模型(PaLM-8B/62B),结果显示:
- 微调后的ReAct模型性能超过所有大模型提示方法(如PaLM-8B微调ReAct优于PaLM-540B提示CoT)。
- 证明"推理轨迹"是小模型学习"有效行动"的关键。
五、ReAct的优势
1. 可解释性与可信度
通过显式推理轨迹,人类可清晰追踪模型的决策过程(如"为什么搜索这个实体?""这个结论基于什么观察?"),便于调试与纠错。
2. 事实性与抗幻觉
外部工具(如维基百科API)的引入,有效缓解CoT的幻觉问题(ReAct幻觉率0% vs CoT 56%)。
3. 动态适应性
"思考-行动-观察"循环允许模型根据外部反馈调整策略(如发现搜索结果为空时,自动更换关键词),提升复杂任务的鲁棒性。
4. 少样本泛化
仅需1-6个示例,ReAct即可泛化到新任务(如ALFWorld的新游戏场景),降低数据需求。
六、局限性与未来方向
1. 局限性
- 上下文窗口限制:复杂任务的"推理-行动"序列较长,易超出LLMs的上下文窗口(如HotpotQA的长轨迹)。
- 工具依赖:需预先定义外部工具(如维基百科API),对未见工具的泛化能力不足。
- 推理灵活性:密集思考可能导致冗余(如简单任务中的过度推理)。
2. 未来方向
- 多任务训练:结合强化学习(RL),提升模型对复杂任务的适应能力。
- 工具泛化:研究"零样本工具使用",减少对预定义工具的依赖。
- 上下文优化:通过摘要、剪枝等技术,减少"推理-行动"序列的长度。
七、总结
ReAct论文的核心贡献是提出"推理-行动协同"的通用框架 ,通过"思考-行动-观察"循环,实现LLMs的"逻辑推理"与"外部交互"的动态平衡。实验证明,ReAct在知识推理、交互决策等任务上显著优于传统方法,且具有可解释性强、抗幻觉、少样本泛化等优势,为后续LLM Agent的发展奠定了基础(如LangChain、AutoGen等框架均借鉴了ReAct的思想)。
论文的核心结论是:推理与行动的协同,是LLMs成为通用问题解决器的关键。未来的研究需进一步优化框架的效率与泛化能力,推动LLMs向更复杂、更实用的方向发展。