一、简介
在自然语言处理的世界里,如何让计算机 "读懂" 人类语言一直是核心难题,而词向量转换正是破解这一难题的关键钥匙。词向量转换的本质,是将文本中离散的词语转化为连续的数值向量。这一步看似简单,却实现了从 "机器无法理解的文字" 到 "可计算的数字" 的跨越,为后续的文本分类、情感分析、机器翻译等任务铺平了道路。
二、词向量转换相关概念
1、词向量转换存在的意义
计算机擅长处理数值数据,原始文本无法直接被计算机理解和分析。**词向量转换通过将单词转换为数值向量,**把语言信息编码成计算机能处理的形式。这样,计算机可以利用这些向量进行计算,从而挖掘文本中的有用信息,实现对文本的理解和处理。
2、词向量转换的分类
特征提取库中导入向量转化模块,自然语言转换成数据的形式,才能保证模型进行训练。
1、基于统计的方法 统计每个单词在这句话中出现的次数
2、基于神经网络模型训练的方法
接下来介绍是基于统计的方法进行词向量转换
三、算法介绍
python
from sklearn.feature_extraction.text import CountVectorizer
texts=["dog cat fish","dog cat cat","fish bird", 'bird']
cv = CountVectorizer(ngram_range=(1,3))
cv_fit = cv.fit_transform(texts)
print(cv_fit)
print(cv.get_feature_names_out())
print(cv_fit.toarray())代码解析:
python
cv = CountVectorizer(ngram_range=(1,3))创建了CountVectorizer实例,并设置了两个参数:
ngram_range=(1,3):考虑 1 元词(单个词)、2 元词(两个词的组合)和 3 元词(三个词的组合)
常用参数还有:
max_features=n:n为整数,只保留出现频率最高的 n个特征(词语或词组),如max_features=6:只保留出现频率最高的 6 个特征(词语或词组)
python
cv_fit = cv.fit_transform(texts)cv.fit_transform(texts)对文本进行拟合和转换:
fit:分析文本,构建词汇表
transform:将文本转换为词频矩阵
注意:cv.fit_transform(texts)与cv.fit(text)的区别:
cv.fit(text):
只分析文本,构建词汇表
cv.fit_transform(texts):
** 第一步:**分析文本,构建词汇表
** 第二步:**根据 Fit 生成的词汇表,把文本转换成词频矩阵
python
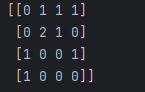
print(cv_fit)print(cv_fit)输出的是一个稀疏矩阵表示,格式为(文档索引, 特征索引) 词频

python
print(cv.get_feature_names_out())会返回 CountVectorizer 拟合(fit/fit_transform)后生成的特征名称数组(词汇表),每个元素对应词频矩阵的一列,顺序和矩阵列索引完全一致。

python
print(cv_fit.toarray())CountVectorizer 生成的稀疏词频矩阵 转换为密集的 NumPy 数组
四、项目分析
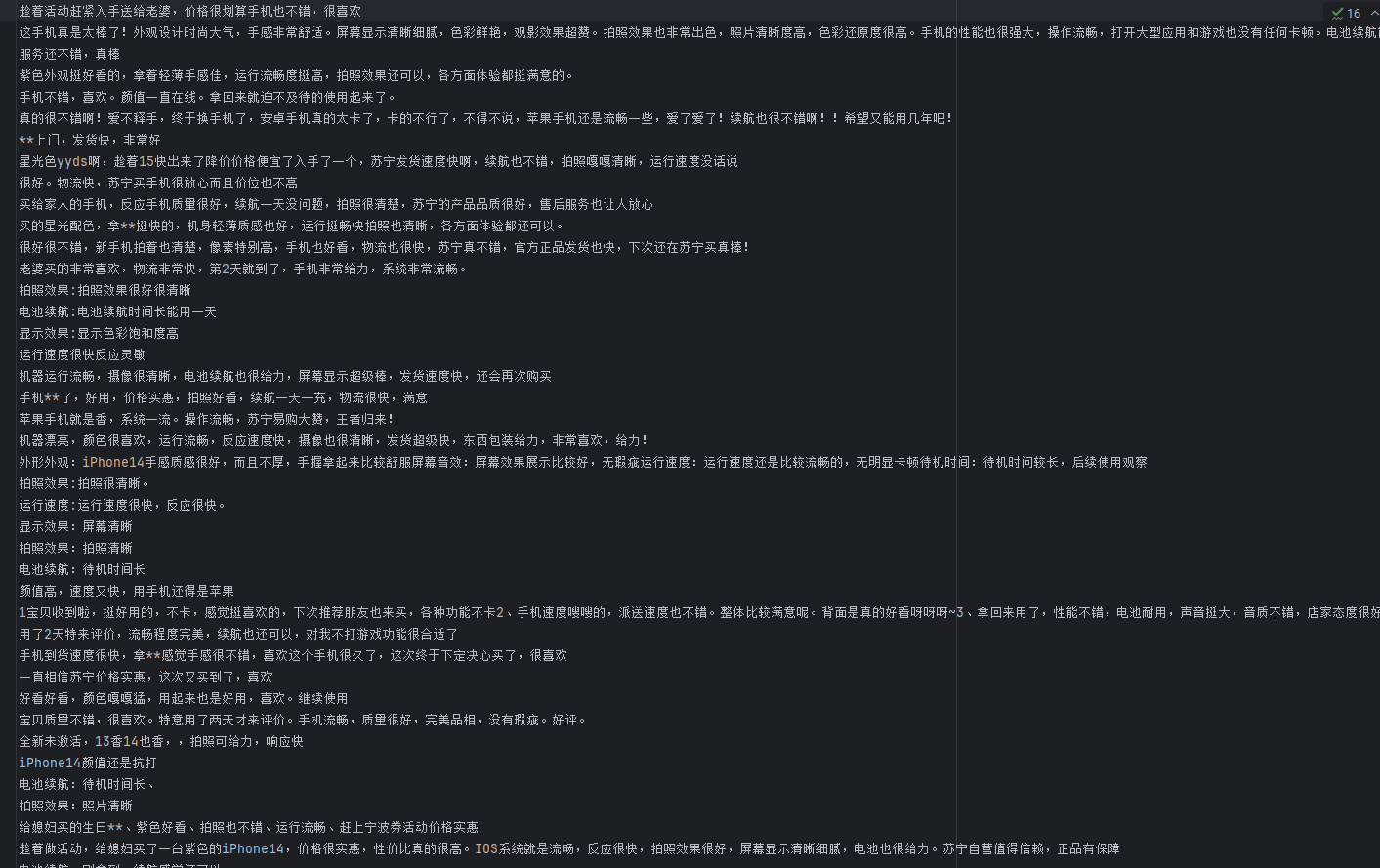
有个苏宁上爬取的关于某品牌手机的评论,一个好评与一个差评文件
数据集:
好评:
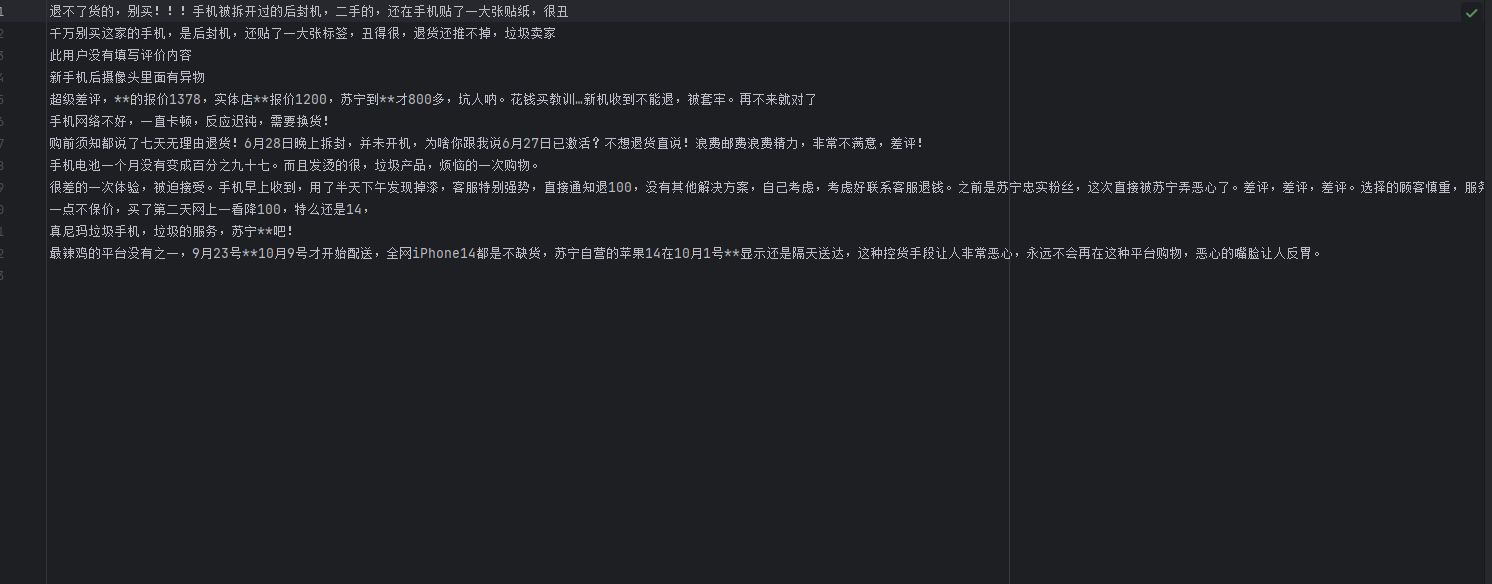
差评:
任务:
训练一个只能判断评论的模型
1.将文字转换为词向量,自己加入y标签,jieba分词,筛选停用词
2.构造模型(朴素贝叶斯)
具体流程思路:
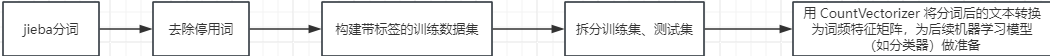
导入数据、库
python
import pandas as pd
cp_content = pd.read_table(r".\差评.txt", encoding='UTF-8')
yzpj_content = pd.read_table(r".\好评.txt", encoding='UTF-8') hp_content、yzpj_content 是 DataFrame 类型,存储 "好评""差评" 文本数据,默认有一列 content 存文本内容。
中文分词(差评 + 好评)
python
# A:对差评分词
import jieba
cp_segments = []
contents = cp_content.content.values.tolist() # 将content列数据取出并转化为list格式,目的是分别 jieba.lcut分词
for content in contents:
results = jieba.lcut(content)
if len(results) > 1: # 当分词之后,这条评论如果只有1个内容
cp_segments.append(results) # 将分词后的内容添加到列表segments中
cp_fc_results = pd.DataFrame({'content': cp_segments})
cp_fc_results.to_excel('cp_fc_results.xlsx', index=False)
# B:对好评分词
yzpj_segments = []
contents = yzpj_content.content.values.tolist() # 将content列数据取出并转化为list格式,目的是分别 jieba.lcut分词
for content in contents:
results = jieba.lcut(content)
if len(results) > 1:
yzpj_segments.append(results) # 将分词后的内容添加到列表segments中
# 分词结果储存在新的数据框中
yzpj_fc_results = pd.DataFrame({'content': yzpj_segments})
yzpj_fc_results.to_excel('yzpj_fc_results.xlsx', index=False)先提取 cp_content 中 content 列的文本,转成列表遍历;
jieba.lcut(content) 对单条文本分词,结果是 list(如 "这个产品好" → ["这个", "产品", "好"] );
注意此时分词结果不满足标准格式即CountVectorizer 要求输入是 "用空格连接的字符串",(如 ["这个","产品"] → "这个 产品" )。
读取停用词,定义及调用去除停用词函数
python
stopwords = pd.read_csv(r"../data/StopwordsCN.txt", encoding='utf8', engine='python', index_col=False)
# 定义去除停用词函数
def drop_stopwords(contents, stopwords):
segments_clean = []
for content in contents:
line_clean = []
for word in content:
if word in stopwords:
continue
line_clean.append(word)
segments_clean.append(line_clean)
return segments_clean
# 调用去除停用词函数
contents = cp_fc_results.content.values.tolist() # DataFrame格式转为list格式
stopwords = stopwords.stopword.values.tolist() # 停用词转为list格式
cp_fc_contents_clean_s = drop_stopwords(contents, stopwords)
contents = yzpj_fc_results.content.values.tolist() # DataFrame格式转为list格式
yzpj_fc_contents_clean_s = drop_stopwords(contents, stopwords)构建带标签的训练数据集
python
cp_train = pd.DataFrame({'segments_clean': cp_fc_contents_clean_s,'label':1}) #差评标签设为1
yzpj_train = pd.DataFrame({'segments_clean': yzpj_fc_contents_clean_s, 'label':0}) #好评设为0
pj_train = pd.concat([cp_train, yzpj_train]) #差评数据集和好评数据集结合拆分训练集、测试集
python
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(pj_train['segements_clean'].values.pj_train['label'].values,random_state=0)词向量转换
python
''' 所有词的词向量转换 '''
words = []
for line_index in range(len(x_train)):
words.append(' '.join(x_train[line_index]))
print(words)
''' 导入词向量转化库 '''
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(max_features=4000,lowercase=False,ngram_range=(1,3))
vec.fit(words)
x_train_vec = vec.transform(words)由于jieba分词后的结果不符合需求格式,所以在训练模型前需要转换为标准格式:
CountVectorizer 要求输入是 "用空格连接的字符串",所以用 ' '.join(...) 把分词列表转成字符串(如 ["这个","产品"] → "这个 产品" )
导入朴素贝叶斯分类器并训练数据
python
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB(alpha=0.1)
classifier.fit(x_train_vec,y_train)
train_pr = classifier.predict(x_train_vec)
#训练集数据预测得分
from sklearn import metrics
print(metrics.classification_report(y_train,train_pr))
#测试集数据分析
test_words = []
for line_index in range(len(x_test)):
test_words.append(' '.join(x_test[line_index]))
test_pr = classifier.predict(vec.transform(test_words)) #测试集的词库转换得到的词向量
print(metrics.classification_report(y_test,train_pr))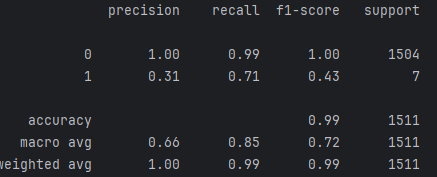
检测
python
s = '这个手机很不错'
s_seg = jieba.lcut(s)
s_clean = [] # 初始化空列表
for word in s_seg: # 遍历分词结果
if word not in stopwords: # 筛选非停用词
s_clean.append(word) # 保留符合条件的词
s_words = " ".join(s_clean)
s_vec = vec.transform([s_words])
prediction = classifier.predict(s_vec)
if prediction[0] == 0:
print(f"句子『{s}』的预测结果:好评")
else:
print(f"句子『{s}』的预测结果:差评")