如果你做过工业故障诊断、医疗信号分析、网络流量检测,甚至雷达目标识别,一定绕不开一个核心任务 ------时间序列分类(Time Series Classification, TSC)。作为时序数据分析的核心任务,TSC 早已从实验室的算法研究,渗透到智慧医疗、工业 4.0、国防军工、网络安全等关键领域。但面对爆炸式增长的技术方案,很多从业者和研究者都会陷入困惑:
- 传统方法和深度学习方法到底该怎么选?
- 面对标注数据稀缺的工业场景,小样本 TSC 有哪些成熟的落地方案?
- Transformer、Mamba、KAN 这些新兴模型,在 TSC 领域到底表现如何?
- 从算法到落地,还要跨过哪些核心门槛?
2026 年刚刚发表在顶刊《Computer Science Review》上的《A comprehensive review of time series classification: Traditional, deep learning, and few-shot learning Methods》一文,给了我们一套完整、系统的答案。这篇综述开创性地提出了 **「三横三纵」多维研究框架 **,完整梳理了 TSC 领域从理论到应用的全链路发展。今天这篇博客,就带大家吃透这篇重磅综述,看懂 TSC 的过去、现在与未来。
一、核心框架:三横三纵,打通 TSC 的任督二脉
这篇综述最核心的价值,就是打破了以往综述「只罗列算法、不构建体系」的局限,提出了一套 **「三横三纵」的多维研究框架 **,把零散的 TSC 技术点,整合成了一个完整的知识体系。
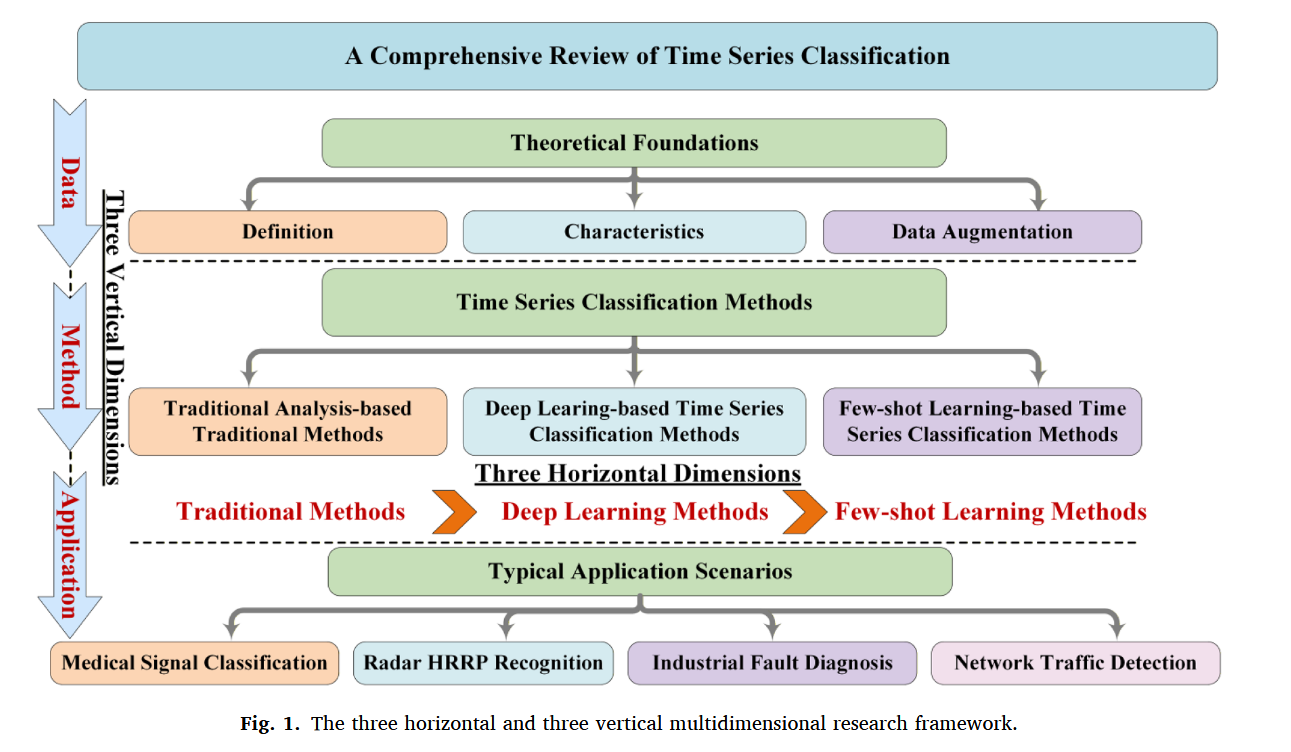
「三横」:技术演进的三大阶段
横向维度,按照 TSC 技术的发展脉络,划分了三大方法论体系,清晰展现了从「人工特征工程」到「数据驱动」再到「数据高效学习」的范式演进:
- 传统分析类方法:以人工设计特征为核心,是 TSC 领域的奠基性方案;
- 深度学习类方法:端到端自动特征提取,是当前 TSC 的主流技术底座;
- 小样本学习类方法:针对标注数据稀缺的真实场景,是当前 TSC 的研究热点。
「三纵」:研究落地的三大维度
纵向维度,覆盖了 TSC 从数据到落地的全流程,解决了以往综述「重模型、轻场景」的问题:
- 数据维度:涵盖时序数据特性、数据增强、公开数据集等基础内容;
- 方法维度:对应横向的三大方法论,拆解每类方法的核心原理、优势与局限;
- 应用维度:聚焦医疗、雷达、工业、网络安全四大典型场景,分析技术落地的痛点与方案。
这套框架就像一张 TSC 领域的「全景地图」,不管你是刚入门的新手,还是深耕多年的研究者,都能快速找到自己的位置,看清领域的研究空白与发展方向。
二、方法论全景:从传统到前沿,TSC 的技术演进之路
基于「三横」的框架,我们来完整梳理 TSC 技术的演进历程,搞懂每类方法的核心逻辑、适用场景与天花板。
2.1 传统方法:手工特征时代的奠基与局限
在深度学习普及之前,传统 TSC 方法完全依赖领域知识和人工特征设计,核心可以分为四大类,至今在小样本、短序列场景中仍有不可替代的价值:
| 方法类别 | 核心思想 | 典型代表 | 核心优势 | 核心局限 |
| 统计建模类 | 基于统计理论捕捉时序的分布、周期、趋势特征 | ARIMA 模型、高斯过程、小波相干分析 | 理论严谨、可解释性强、小样本下表现稳定 | 对数据分布有严格假设、难以建模非线性长依赖、高维数据适配性差 |
| 相似度匹配类 | 以序列间的形态相似度为分类核心,结合距离度量与近邻规则 | DTW 动态时间规整、Shapelets 子序列、KNN 分类器 | 无需复杂特征工程、对非线性非平稳序列适配性好、原理直观易落地 | 长序列下计算复杂度高、对噪声敏感、高维多变量场景性能骤降 |
| 特征工程类 | 人工提取时域、频域、时频域特征,结合传统机器学习分类器 | TSFresh 特征库、SVM、随机森林 | 特征物理意义明确、中小数据集训练效率高、可解释性强 | 极度依赖领域专家经验、难以自动捕捉复杂非线性模式、对未知模式漂移适配性差 |
| 集成学习类 | 构建多个基分类器,通过投票 / 加权融合提升泛化能力 | TS-CHIEF、HIVE-COTE v2 | 抗过拟合能力强、对噪声和模式多样性适配性好、多分类场景鲁棒性高 | 模型结构复杂、训练推理成本高、集成结果可解释性差 |
|---|
传统方法的核心痛点,在于「人工特征设计的天花板」。面对如今 IoT 时代爆发的高维、长序列、非平稳时序数据,人工特征已经很难覆盖所有的有效模式,深度学习的登场也就成了必然。
2.2 深度学习:端到端学习的爆发式革新
深度学习彻底解决了传统方法「人工特征工程」的瓶颈,通过端到端的学习,自动从原始时序数据中提取判别性特征,也是这篇综述的核心重点。论文将深度学习 TSC 方法,按照特征提取的目标,分为了四大类,完整覆盖了当前主流的技术方案:
(1)局部模式挖掘类:抓细节,找局部判别性特征
这类方法把时序数据当作「静态对象」,通过卷积、小波变换等方式,提取时序中局部连续的形态特征(比如峰值、突变、局部趋势),是工业界最常用的 TSC 方案。
-
核心代表:1D-CNN、FCN 全卷积网络、InceptionTime、Rocket/MiniRocket/MultiRocket 系列、TCN 时序卷积网络;
-
核心优势:对局部细微模式敏感、计算效率高、易并行化、有一定的噪声抑制能力,非常适合故障诊断、ECG 信号分类等依赖局部波形特征的场景;
-
核心局限:难以建模长距离时序依赖,对依赖长期趋势的分类任务表现不佳。
(2)时序依赖建模类:看全局,捕捉长程演化规律
这类方法把时序数据当作「动态序列流」,通过循环结构或注意力机制,捕捉序列的全局演化动态和长程依赖,解决了 CNN 类方法的长序列短板。
-
核心代表:LSTM/GRU 及其变体、Transformer/TST、Hformer 等 Transformer 变体;
-
核心优势:能有效捕捉长程时序依赖,擅长识别序列的整体趋势和周期规律,在多变量长序列场景中优势显著;
-
核心局限:RNN 类模型存在梯度消失 / 爆炸问题、训练无法并行;原生 Transformer 自注意力的二次复杂度,在超长序列下会出现内存和计算瓶颈。
(3)混合模型架构类:强强联合,多尺度特征融合
这类方法融合了「局部卷积」和「全局注意力 / 循环」模块,同时捕捉多尺度的时序表征,克服了单一范式模型的短板,也是当前 SOTA 方案的主流设计思路。
- 核心代表:CNN-Transformer 混合模型、CNN-LSTM 级联架构、TSCMamba(Mamba + 多视图学习)、SCNet(频谱卷积 + 多尺度模块);
- 核心优势:同时兼顾局部细节和全局依赖,分类精度普遍优于单一模型,对复杂时序数据的适配性更强;
- 核心局限:模型结构更复杂、超参数调参难度大、特征融合策略不当会导致信息冗余或关键特征稀释。
这里特别提一下论文里重点关注的新兴模型:
- Mamba:通过选择性状态空间模型,实现了线性时间复杂度的全局上下文建模,完美结合了 Transformer 的全局感受野和 RNN 的线性复杂度,是超长时序分类的最优解之一;
- KAN:用边的可学习激活函数替代了 MLP 节点的固定激活函数,函数拟合能力和可解释性更强,在复杂非线性时序分类中表现突出,但目前硬件优化还不够成熟。
(4)时空融合建模类:解耦关联,适配多变量时序
这类方法专门针对多变量时序数据,在建模时序动态的同时,显式建模变量间的空间关联,解决了多变量时序中「通道间耦合」的问题。
- 核心代表:GCN/GNN 图神经网络、ConvTran、TodyNet 动态图网络、SAGoG 相似性感知图网络;
- 核心优势:能同时捕捉时序动态和变量间的空间关联,完美适配多传感器、多通道的工业 / 医疗时序数据;
- 核心局限:重度依赖空间结构先验知识、纯时序数据场景会引入冗余计算、小数据集下易过拟合。
2.3 小样本学习:破解标注稀缺的行业痛点
真实工业场景中,90% 以上的 TSC 任务都面临「标注数据稀缺」的问题:故障样本难获取、医疗数据标注成本极高、雷达目标数据采集受限...... 小样本学习,就是为了解决这个核心痛点而生的。论文将小样本 TSC 方法分为四大类,完整覆盖了当前的主流技术路线:
- 迁移学习类:核心是「知识复用」,把大规模源域数据上预训练的时序特征提取能力,迁移到小样本目标域,典型方案包括预训练模型微调、域对抗训练。优势是实现简单、落地性强,缺点是源域和目标域差异过大时会出现「负迁移」。
- 自监督学习类:核心是「无监督预训练」,通过设计掩码重构、时序对比学习等前置任务,从海量无标注时序数据中学习通用特征表示,再用少量标注数据微调分类器。典型方案包括 TS-TCC、CA-TCC,是当前工业界最有潜力的落地方向。
- 元学习类:核心是「学会学习」,通过跨任务的元训练,让模型获得「快速适配新任务」的能力,在新的小样本分类任务中,仅需少量样本就能快速收敛。典型方案包括 MAML、时序原型网络,优势是新类别适配速度快,缺点是元训练需要大量异构任务,计算成本高。
- 多模态学习类:核心是「互补信息增强」,把时序数据和文本、图像等其他模态数据融合,通过跨模态的知识补充,提升小样本下的特征判别性。典型方案包括时序 - 语言大模型融合、时序成像 + 预训练 CV 模型,适合有辅助模态信息的场景。
三、落地指南:从实验室到工业界,TSC 的四大核心场景
这篇综述最难得的一点,就是没有停留在算法层面,而是深入拆解了 TSC 在四大高价值行业的落地现状、核心挑战与技术选型,这对从业者来说是最有价值的部分。
3.1 医疗信号分类:生命信号的精准解读
核心场景 :ECG 心电信号分类、EEG 脑电信号分类、EMG 肌电信号分类、呼吸信号分析;核心挑战 :个体间差异大、标注需要专业医师成本极高、信号信噪比低、跨设备数据分布偏移、隐私合规要求严格;主流技术方案:轻量级 CNN+LSTM 混合模型、小样本迁移学习、联邦学习解决数据孤岛问题、可解释 AI 满足临床信任要求。
3.2 雷达 HRRP 目标识别:国防场景的核心感知
核心场景 :雷达高分辨距离像(HRRP)的目标分类、非合作目标识别、隐身目标检测;核心挑战 :目标姿态敏感性强、信噪比波动大、仿真数据与实测数据存在域差、非合作目标标注样本稀缺、开放集识别要求高;主流技术方案:CNN-Transformer 混合架构、小样本元学习、对比学习解决仿真 - 实测域适配、动态图网络建模散射点关联。
3.3 工业故障诊断:智能制造的安全底座
核心场景 :轴承 / 齿轮箱故障诊断、航空发动机状态监测、风电设备故障预警、工业传感器异常检测;核心挑战 :健康数据与故障数据极端不平衡、工况多变导致分布漂移、复合故障耦合难分离、早期故障特征微弱、边缘设备部署的轻量化要求;主流技术方案:Rocket 系列轻量级模型、Mamba 超长序列建模、数字孪生 + 生成式数据增强解决样本稀缺、迁移学习解决多工况适配问题。
3.4 网络流量检测:网络安全的第一道防线
核心场景 :IoT 入侵检测、加密流量分类、网络攻击识别、异常流量检测;核心挑战 :攻击模式快速迭代导致概念漂移、加密流量 payload 不可见、零日攻击样本稀缺、高吞吐场景下的实时性要求、对抗性规避攻击;主流技术方案:时序成像 + Transformer 模型、自监督学习检测零日攻击、轻量化模型适配边缘网关、对抗训练提升模型鲁棒性。
四、行业痛点与未来:TSC 的下一个十年在哪里?
论文的最后,系统总结了当前 TSC 领域面临的三大通用核心挑战,并提出了四大未来研究方向,给所有研究者和从业者指明了赛道。
4.1 当前 TSC 领域的三大核心挑战
- 数据层面:高质量标注样本稀缺、真实数据非独立同分布、跨源数据异构性强、信噪比低;
- 模型层面:跨域泛化能力不足、概念漂移下性能快速衰减、黑箱模型可解释性差,难以满足安全关键场景的要求;
- 部署层面:SOTA 模型的计算复杂度与边缘设备的实时性、功耗约束存在矛盾、数据隐私合规要求高、对抗环境下的鲁棒性不足。
4.2 未来四大核心研究方向
(1)生成式增强与域自适应
针对样本稀缺和跨域漂移问题,未来的核心是物理引导的生成式建模:结合数字孪生、物理先验知识,生成符合真实物理规律的合成样本,而非纯数据驱动的生成;同时通过元学习、子域自适应技术,实现模型在不同设备、不同工况、不同个体间的鲁棒迁移。
(2)物理信息融合与因果可解释性
安全关键场景中,「高精度」远不如「可解释、可信任」重要。未来的 TSC 模型,将从纯数据驱动,走向物理信息融合的神经网络(PINNs):把行业的物理机理、先验知识嵌入到模型的损失函数和结构中,让模型学习到的特征具备明确的物理语义;同时通过因果推理,替代传统的关联建模,让模型的决策过程可追溯、可解释。
(3)轻量化架构与隐私计算
针对边缘部署的需求,未来的 TSC 模型将朝着硬件感知的轻量化设计发展:深度可分离卷积、线性注意力、Mamba 等高效架构,结合剪枝、量化、知识蒸馏的压缩流水线,实现精度和效率的平衡;同时通过联邦学习、差分隐私技术,打破医疗、工业等领域的数据孤岛,在不泄露原始数据的前提下,实现多源数据的联合建模。
(4)时间序列基础模型
大语言模型在 NLP/CV 领域的成功,也给 TSC 领域指明了方向。未来的核心突破点,是构建通用的时序基础模型:通过在海量多域时序数据上进行自监督预训练,让模型学习到通用的时序动态规律,再通过 Prompt Tuning、LoRA 等轻量化适配方式,快速迁移到不同的下游 TSC 任务中,解决小样本、冷启动的行业痛点。同时结合思维链(CoT)推理,缓解大模型的「幻觉」问题,提升复杂诊断任务的可靠性。