📋 深度学习连续剧------梯度下降法
适用对象 :深度学习初学者
难度 :入门 → 进阶
涵盖内容:数学推导 · 手算示例 · MLP · Python/NumPy 实现 · 局限性分析**
涵盖考点:
📋 教案目录
本教案共分六大章节,循序渐进地带领读者掌握梯度下降法的核心思想与实战技能:
| 章节 | 主题 | 核心要点 |
|---|---|---|
| 第一章 | 为什么需要梯度下降? | 最小二乘法引入 · 正规方程局限 · 可视化直觉 |
| 第二章 | 梯度下降法的数学推导 | 导数回顾 · 偏导 · 迭代更新规则 · 手算例子 |
| 第三章 | 多层感知机(MLP)简介 | 神经元模型 · 网络结构 · 前向传播 |
| 第四章 | 手算MLP的反向传播 | 链式法则 · 逐层求导 · 完整手算流程 |
| 第五章 | Python/NumPy 实战 | 手动梯度 · 完整训练循环 · 可视化 |
| 第六章 | 梯度下降法的局限与改进 | 局部最优 · 鞍点 · 消失梯度 · Adam等 |
第一章:为什么需要梯度下降?
1.1 从一个具体问题出发
在学习梯度下降法之前,我们先从一个真实世界的问题出发,看看机器学习最基本的任务是什么:拟合数据。
📊 数据来源说明
本章使用的数据来自经典的"波士顿房价数据集"(Harrison & Rubinfeld, 1978,发表于《环境经济与管理杂志》)的简化版本。原始数据集包含506条样本、13个特征,在机器学习教学中被广泛使用。此处我们仅取其中一个特征------房间数量(RM,平均每户房间数)------与房价中位数(MEDV,单位:千美元)之间的关系,简化为一元线性回归问题,以便手算推导。
我们的任务非常直观:
- 已知一批房子的"平均房间数" x 与"房价中位数" y
- 希望找到一条直线 y = w \\cdot x + b 来最好地描述这种关系
- 目标:求解参数 w(斜率)和 b(截距)
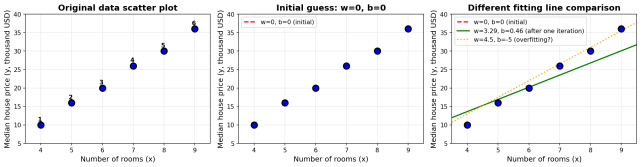
1.1.1 示例数据(简化版,便于手算)
我们从数据集中抽取以下6个数据点(x = 房间数,y = 房价/千美元):
| 样本编号 | 房间数 x | 房价 y(千美元) | 备注 |
|---|---|---|---|
| 1 | 4.0 | 10.0 | 小户型 |
| 2 | 5.0 | 16.0 | 中小户型 |
| 3 | 6.0 | 20.0 | 中等户型 |
| 4 | 7.0 | 26.0 | 中大户型 |
| 5 | 8.0 | 30.0 | 大户型 |
| 6 | 9.0 | 36.0 | 豪华户型 |
 |
1.2 损失函数:衡量拟合好坏的标准
要找到最好的直线,首先需要定义什么叫好。我们使用均方误差(Mean Squared Error,MSE)作为损失函数:
L(w,b)=1N∑i=1N(yi−y^i)2=1N∑i=1N(yi−w⋅xi−b)2 L(w, b) = \frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}i)^2 = \frac{1}{N} \sum{i=1}^{N} (y_i - w \cdot x_i - b)^2 L(w,b)=N1i=1∑N(yi−y^i)2=N1i=1∑N(yi−w⋅xi−b)2
其中:
- NNN = 样本数量(此例 N = 6)
- yiy_iyi = 第 i 个样本的真实房价
- hatyi=w⋅xi+bhat{y}_i = w \cdot x_i + bhatyi=w⋅xi+b = 模型对第 i 个样本的预测值
- (yi−y^i)2(y_i - \hat{y}_i)^2(yi−y^i)2 = 预测误差的平方(平方是为了保证非负,且放大大误差)
1.3 为什么不直接用方程组求解?
聪明的读者可能会问:能不能直接解方程?对于线性回归,确实存在一个叫做"正规方程"(Normal Equation)的解析解:
θ∗=(X⊤X)−1⋅X⊤y \theta^* = (X^\top X)^{-1} \cdot X^\top y θ∗=(X⊤X)−1⋅X⊤y
这个公式在理论上完美,但在实际工程中面临严重挑战:
⚠️ 正规方程的实际局限
- 计算复杂度高:矩阵求逆的时间复杂度为 O(n³),当特征数 n 达到数万时(如图像分类),计算量大到不可接受
- 存储瓶颈: X\^\\top X 是 n×n 矩阵,n=10000 时就需要存储 10⁸ 个数,超出大多数内存限制
- 不可逆情形:当特征之间存在多重共线性时, X\^\\top X 不可逆,公式失效
- 不适用于非线性模型:神经网络的损失函数是高度非线性的,不存在解析解
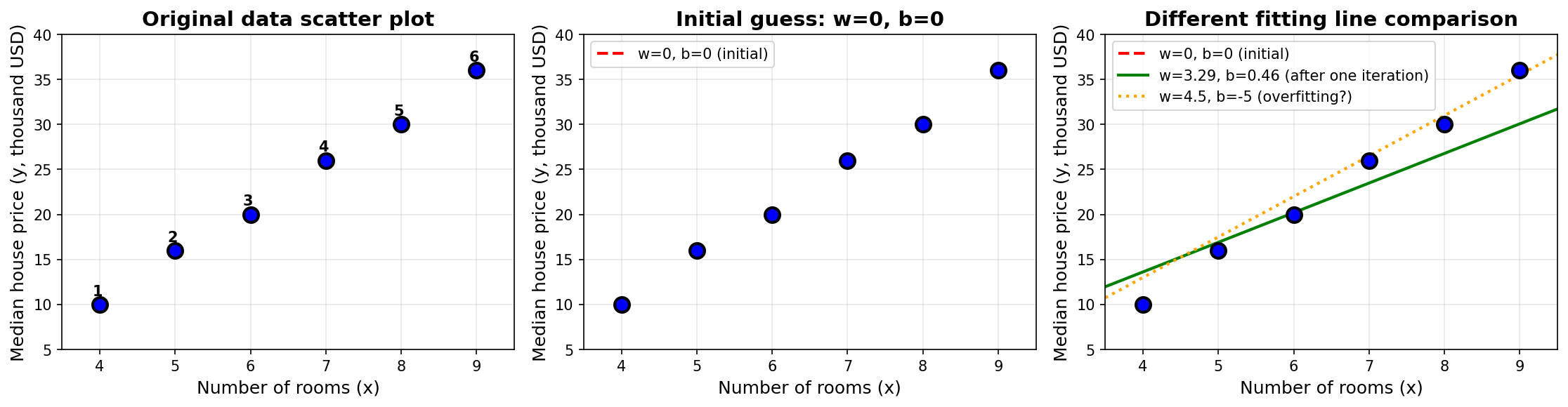
因此,梯度下降法作为一种通用的数值优化方法,成为了机器学习的核心算法。
图示:梯度下降 vs 正规方程收敛路径对比
第二章:梯度下降法的数学推导
2.1 核心直觉:山谷中的滚球
梯度下降的核心思想来自一个直观的比喻:想象你站在一座山上,目标是走到山谷最低点(损失最小)。你该怎么走?
- 环顾四周,找到当前位置最陡的下坡方向(这就是"梯度"的负方向)
- 沿着这个方向走一小步(步长由"学习率"控制)
- 重复上述过程,直到到达山谷
💡 关键 梯度是函数在某点上升最快的方向。沿梯度负方向移动,损失函数就会减小。
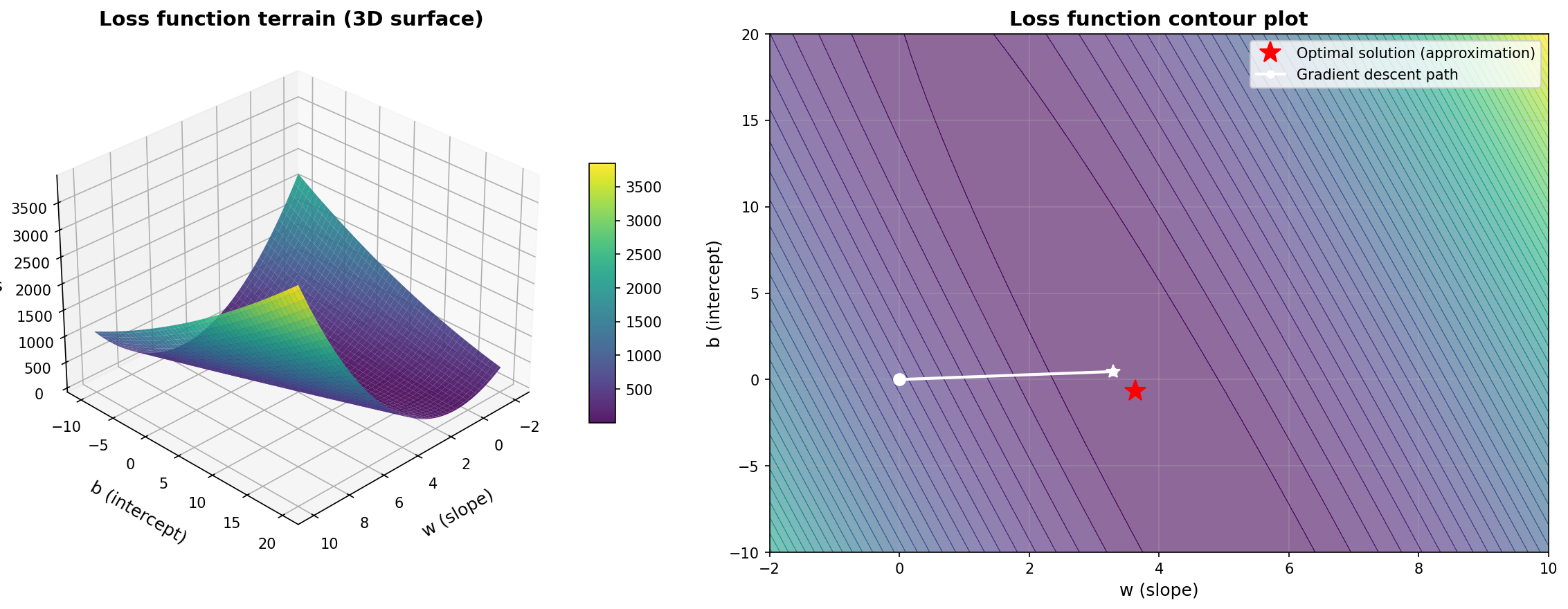
图示:三维损失曲面上的梯度下降轨迹
2.2 数学基础回顾:导数与偏导数
2.2.1 单变量导数
导数描述函数在某点的变化率,即"函数值随自变量的变化速度":
f′(x)=limh→0f(x+h)−f(x)h f'(x) = \lim_{h \to 0} \frac{f(x+h) - f(x)}{h} f′(x)=h→0limhf(x+h)−f(x)
几何意义:导数是曲线在该点的切线斜率。若 f'(x) \> 0 ,函数在 x 处递增;若 f'(x) \< 0 ,函数在 x 处递减。
2.2.2 偏导数(多变量时)
当函数有多个变量时(如 L(w, b) ),对某个变量求导时,将其他变量视为常数:
- \\frac{\\partial L}{\\partial w} 表示:b 固定,L 随 w 变化的速率
- \\frac{\\partial L}{\\partial b} 表示:w 固定,L 随 b 变化的速率
2.3 完整推导:一元线性回归的梯度
设损失函数为:
L(w,b)=1N∑i=1N(yi−w⋅xi−b)2 L(w, b) = \frac{1}{N} \sum_{i=1}^{N} (y_i - w \cdot x_i - b)^2 L(w,b)=N1i=1∑N(yi−w⋅xi−b)2
对 w 求偏导(使用链式法则,令 e_i = y_i - w \\cdot x_i - b 为残差):
对 w 的偏导推导过程
∂L∂w=1N∑i∂∂w(yi−w⋅xi−b)2=1N∑i2(yi−w⋅xi−b)⋅∂∂w(yi−w⋅xi−b)=1N∑i2(yi−w⋅xi−b)(−xi)=−2N∑ixi(yi−y^i) \begin{align*} \frac{\partial L}{\partial w} &= \frac{1}{N} \sum_i \frac{\partial}{\partial w} (y_i - w \\cdot x_i - b)\^2 \\ &= \frac{1}{N} \sum_i 2(y_i - w \cdot x_i - b) \cdot \frac{\partial}{\partial w}(y_i - w \cdot x_i - b) \\ &= \frac{1}{N} \sum_i 2(y_i - w \cdot x_i - b)(-x_i) \\ &= -\frac{2}{N} \sum_i x_i (y_i - \hat{y}_i) \end{align*} ∂w∂L=N1i∑∂w∂(yi−w⋅xi−b)2=N1i∑2(yi−w⋅xi−b)⋅∂w∂(yi−w⋅xi−b)=N1i∑2(yi−w⋅xi−b)(−xi)=−N2i∑xi(yi−y^i)
对 b 的偏导推导过程
∂L∂b=1N∑i2(yi−w⋅xi−b)(−1)=−2N∑i(yi−y^i) \begin{align*} \frac{\partial L}{\partial b} &= \frac{1}{N} \sum_i 2(y_i - w \cdot x_i - b)(-1) \\ &= -\frac{2}{N} \sum_i (y_i - \hat{y}_i) \end{align*} ∂b∂L=N1i∑2(yi−w⋅xi−b)(−1)=−N2i∑(yi−y^i)
2.4 参数更新规则
梯度下降的参数更新规则(同时更新所有参数):
w←w−α⋅∂L∂w=w+2αN∑ixi(yi−y^i)b←b−α⋅∂L∂b=b+2αN∑i(yi−y^i) \begin{aligned} w &\leftarrow w - \alpha \cdot \frac{\partial L}{\partial w} = w + \frac{2\alpha}{N} \sum_i x_i (y_i - \hat{y}_i) \\ b &\leftarrow b - \alpha \cdot \frac{\partial L}{\partial b} = b + \frac{2\alpha}{N} \sum_i (y_i - \hat{y}_i) \end{aligned} wb←w−α⋅∂w∂L=w+N2αi∑xi(yi−y^i)←b−α⋅∂b∂L=b+N2αi∑(yi−y^i)
其中 \\alpha (alpha)是学习率,控制每次更新的步长大小,通常取值范围:0.001 ~ 0.1
2.5 手算示例:一步一步走向最优
使用第一章的6个数据点,我们手动完成梯度下降的前两次迭代( \\alpha = 0.01 ):
初始化
设初始参数: w = 0 ,,, b = 0 ,学习率 \\alpha = 0.01
第0步:计算初始损失
当 w=0, b=0 时,所有预测值 \\hat{y}_i = 0 \\cdot x_i + 0 = 0
| x_i | y_i | \\hat{y}_i = 0 | 误差 (y_i - \\hat{y}_i) | 误差² |
|---|---|---|---|---|
| 4 | 10 | 0 | 10 | 100 |
| 5 | 16 | 0 | 16 | 256 |
| 6 | 20 | 0 | 20 | 400 |
| 7 | 26 | 0 | 26 | 676 |
| 8 | 30 | 0 | 30 | 900 |
| 9 | 36 | 0 | 36 | 1296 |
| 合计 | --- | --- | 138 | 3628 |
初始损失 L = 3628 / 6 \\approx 604.67
第1步:计算梯度(第一次迭代)
∂L∂w=−264×10+5×16+6×20+7×26+8×30+9×36=−1340+80+120+182+240+324=−13×986≈−328.67 \begin{align*} \frac{\partial L}{\partial w} &= -\frac{2}{6} 4 \\times 10 + 5 \\times 16 + 6 \\times 20 + 7 \\times 26 + 8 \\times 30 + 9 \\times 36 \\ &= -\frac{1}{3} 40 + 80 + 120 + 182 + 240 + 324 \\ &= -\frac{1}{3} \times 986 \approx -328.67 \end{align*} ∂w∂L=−624×10+5×16+6×20+7×26+8×30+9×36=−3140+80+120+182+240+324=−31×986≈−328.67
∂L∂b=−2610+16+20+26+30+36=−13×138=−46.0 \begin{align*} \frac{\partial L}{\partial b} &= -\frac{2}{6} 10 + 16 + 20 + 26 + 30 + 36 \\ &= -\frac{1}{3} \times 138 = -46.0 \end{align*} ∂b∂L=−6210+16+20+26+30+36=−31×138=−46.0
第1步:更新参数
w←0−0.01×(−328.67)≈3.29b←0−0.01×(−46.0)≈0.46 \begin{align*} w &\leftarrow 0 - 0.01 \times (-328.67) \approx 3.29 \\ b &\leftarrow 0 - 0.01 \times (-46.0) \approx 0.46 \end{align*} wb←0−0.01×(−328.67)≈3.29←0−0.01×(−46.0)≈0.46
第2步:用新参数预测 & 计算损失
使用 w=3.29, b=0.46 ,重新计算预测值和误差:
| x_i | y_i | \\hat{y}_i = 3.29x+0.46 | 误差 (y_i - \\hat{y}_i) |
|---|---|---|---|
| 4 | 10 | 13.62 | -3.62 |
| 5 | 16 | 16.91 | -0.91 |
| 6 | 20 | 20.20 | -0.20 |
| 7 | 26 | 23.49 | 2.51 |
| 8 | 30 | 26.78 | 3.22 |
| 9 | 36 | 30.07 | 5.93 |
第2步损失 L \\approx (13.11 + 0.83 + 0.04 + 6.30 + 10.37 + 35.16)/6 \\approx 10.97
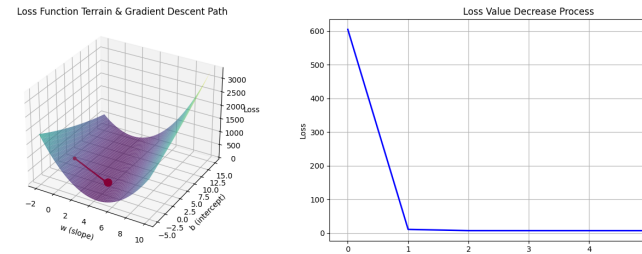
✅ 观察 损失从 604.67 大幅下降到 10.97,仅仅经过一次梯度下降迭代!这展示了梯度下降的强大收敛能力。继续迭代,损失将进一步减小,最终收敛到最优参数附近。
图示:损失函数随迭代次数下降曲线
第三章:多层感知机(MLP)简介
3.1 从单个神经元到网络
线性回归的模型太简单,无法学习复杂的非线性关系。多层感知机(Multi-Layer Perceptron,MLP)通过引入"隐藏层"和"激活函数",大幅提升了模型的表达能力。
3.1.1 单个神经元的计算
每个神经元执行两步操作:
- 线性变换: z = w_1x_1 + w_2x_2 + \\cdots + w_nx_n + b (加权求和)
- 激活函数: a = f(z) (引入非线性,例如 Sigmoid 或 ReLU)
3.1.2 常用激活函数
| 激活函数 | 公式 | 输出范围 | 主要用途 |
|---|---|---|---|
| Sigmoid | \\sigma(z) = \\frac{1}{1+e\^{-z}} | (0, 1) | 二分类输出层 |
| ReLU | \\text{ReLU}(z) = \\max(0, z) | [0, +∞) | 隐藏层(最常用) |
| Tanh | \\tanh(z) = \\frac{e\^z - e^{-z}}{e^z + e\^{-z}} | (-1, 1) | 隐藏层 |
| Softmax | \\text{softmax}(z_k) = \\frac{e\^{z_k}}{\\sum_j e\^{z_j}} | (0,1) 求和=1 | 多分类输出层 |
图示:不同激活函数图像对比
3.2 我们的教学用 MLP 架构
为了便于手算演示,我们设计一个极简的 MLP 网络,解决一个二分类问题:
🏗️ 网络结构定义
- 输入层:2个输入特征( x_1, x_2 )
- 隐藏层:1层,2个神经元,激活函数:Sigmoid \\sigma(z) = \\frac{1}{1+e\^{-z}}
- 输出层:1个神经元,激活函数:Sigmoid(输出概率,用于二分类)
- 损失函数:二元交叉熵 L = -\[y \\log(\\hat{y}) + (1-y)\\log(1-\\hat{y})\]
该网络共有参数:
- 隐藏层: W_1 = 2×2 矩阵(4个权重)+ b_1 = 2×1 向量(2个偏置)= 6个参数
- 输出层: W_2 = 1×2 矩阵(2个权重)+ b_2 = 1 个偏置 = 3个参数
- 总计:9个参数
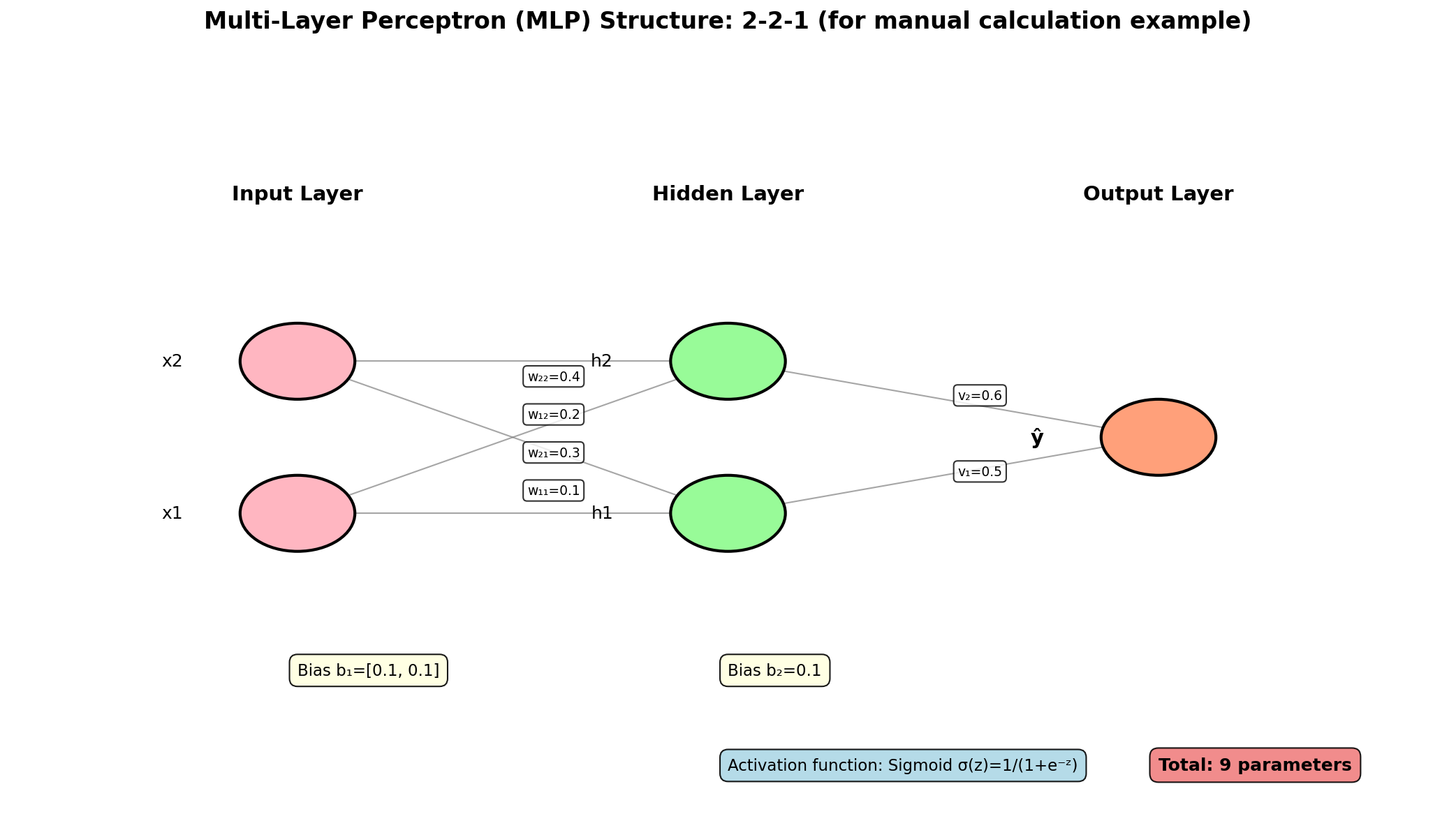
3.3 前向传播(Forward Pass)
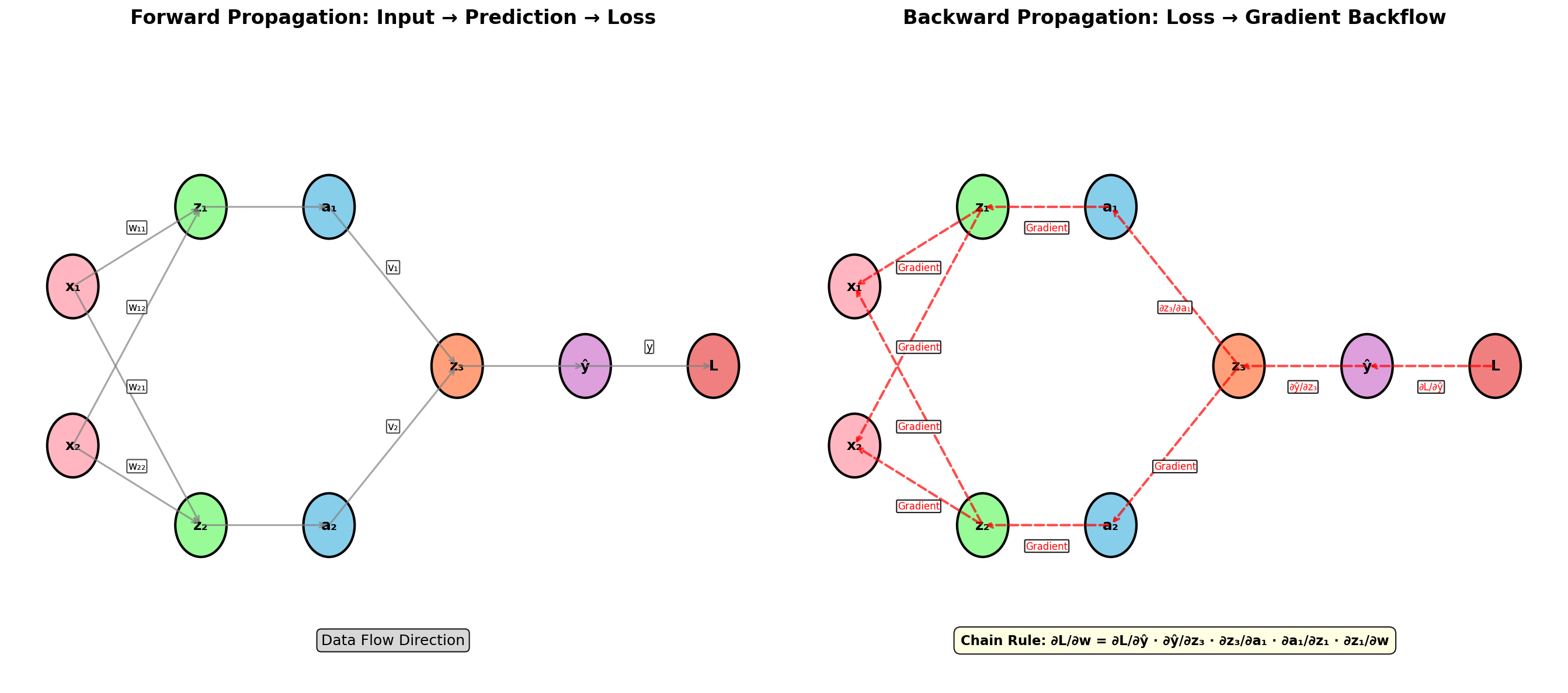
前向传播是神经网络的"预测"过程:输入数据从左(输入层)流向右(输出层),依次计算每一层的输出。
设一个输入样本 \\mathbf{x} = \[x_1, x_2\]\^\\top ,完整的前向传播步骤如下:
前向传播公式
第一步:输入层 → 隐藏层
\\mathbf{Z}_1 = W_1 \\cdot \\mathbf{x} + \\mathbf{b}_1
\\mathbf{A}_1 = \\sigma(\\mathbf{Z}_1) (对 \\mathbf{Z}_1 每个元素应用 Sigmoid)
第二步:隐藏层 → 输出层
Z_2 = W_2 \\cdot \\mathbf{A}_1 + b_2
A_2 = \\sigma(Z_2) (即最终预测值 \\hat{y} )
第三步:计算损失
L = -\[y \\log(A_2) + (1-y)\\log(1-A_2)\]
图示:MLP前向传播流程图
第四章:手算 MLP 的反向传播
4.1 反向传播的本质:链式法则
反向传播(Backpropagation)是计算神经网络所有参数梯度的高效算法,其数学本质是多元复合函数的链式法则:
dLdw=dLdA2⋅dA2dZ2⋅dZ2dw \frac{dL}{dw} = \frac{dL}{dA_2} \cdot \frac{dA_2}{dZ_2} \cdot \frac{dZ_2}{dw} dwdL=dA2dL⋅dZ2dA2⋅dwdZ2
损失 L 对权重 w 的梯度,等于沿着"损失 → 激活 → 加权和 → 权重"这条路径上所有偏导数的乘积。反向传播的"反"体现在:我们从输出层开始,逐层向前计算梯度。
4.2 具体数值初始化
以下是我们要手算的完整例子。使用如下初始参数(为简化计算,选取特殊数值):
| 参数 | 数值 | 说明 |
|---|---|---|
| 输入 x | 1.0, 2.0ᵀ | 一个训练样本,2个特征 |
| 真实标签 y | 1 | 正类(该样本属于类别1) |
| W₁ | \[0.1, 0.2, 0.3, 0.4] | 隐藏层权重,2×2 矩阵 |
| b₁ | 0.1, 0.1ᵀ | 隐藏层偏置 |
| W₂ | 0.5, 0.6 | 输出层权重,1×2 行向量 |
| b₂ | 0.1 | 输出层偏置 |
| 学习率 α | 0.1 | 梯度下降步长 |
4.3 前向传播(代入数值)
Step 1:隐藏层线性变换 Z₁
Z11=W100⋅x1+W101⋅x2+b11=0.1×1.0+0.2×2.0+0.1=0.1+0.4+0.1=0.6Z12=W110⋅x1+W111⋅x2+b12=0.3×1.0+0.4×2.0+0.1=0.3+0.8+0.1=1.2 \begin{align*} Z_11 &= W_100 \cdot x_1 + W_101 \cdot x_2 + b_11 \\ &= 0.1 \times 1.0 + 0.2 \times 2.0 + 0.1 = 0.1 + 0.4 + 0.1 = 0.6 \\ \\ Z_12 &= W_110 \cdot x_1 + W_111 \cdot x_2 + b_12 \\ &= 0.3 \times 1.0 + 0.4 \times 2.0 + 0.1 = 0.3 + 0.8 + 0.1 = 1.2 \end{align*} Z11Z12=W100⋅x1+W101⋅x2+b11=0.1×1.0+0.2×2.0+0.1=0.1+0.4+0.1=0.6=W110⋅x1+W111⋅x2+b12=0.3×1.0+0.4×2.0+0.1=0.3+0.8+0.1=1.2
Step 2:隐藏层激活 A₁(应用 Sigmoid)
Sigmoid 函数: \\sigma(z) = \\frac{1}{1 + e\^{-z}}
A11=σ(0.6)=11+e−0.6=11+0.5488≈0.6457A12=σ(1.2)=11+e−1.2=11+0.3012≈0.7685 \begin{align*} A_11 &= \sigma(0.6) = \frac{1}{1+e^{-0.6}} = \frac{1}{1+0.5488} \approx 0.6457 \\ A_12 &= \sigma(1.2) = \frac{1}{1+e^{-1.2}} = \frac{1}{1+0.3012} \approx 0.7685 \end{align*} A11A12=σ(0.6)=1+e−0.61=1+0.54881≈0.6457=σ(1.2)=1+e−1.21=1+0.30121≈0.7685
Step 3:输出层线性变换 Z₂
Z2=W21⋅A11+W22⋅A12+b2=0.5×0.6457+0.6×0.7685+0.1=0.3229+0.4611+0.1=0.8840 \begin{align*} Z_2 &= W_21 \cdot A_11 + W_22 \cdot A_12 + b_2 \\ &= 0.5 \times 0.6457 + 0.6 \times 0.7685 + 0.1 \\ &= 0.3229 + 0.4611 + 0.1 = 0.8840 \end{align*} Z2=W21⋅A11+W22⋅A12+b2=0.5×0.6457+0.6×0.7685+0.1=0.3229+0.4611+0.1=0.8840
Step 4:输出层激活 A₂(预测值 ŷ)
y^=A2=σ(0.8840)=11+e−0.884=11+0.4131≈0.7077 \hat{y} = A_2 = \sigma(0.8840) = \frac{1}{1+e^{-0.884}} = \frac{1}{1+0.4131} \approx 0.7077 y^=A2=σ(0.8840)=1+e−0.8841=1+0.41311≈0.7077
Step 5:计算损失
L=−ylog(y\^)+(1−y)log(1−y\^)=−1×log(0.7077)+0×log(0.2923)=−log(0.7077)≈0.3456 \begin{align*} L &= -y \\log(\\hat{y}) + (1-y)\\log(1-\\hat{y}) \\ &= -1 \\times \\log(0.7077) + 0 \\times \\log(0.2923) \\ &= -\log(0.7077) \approx 0.3456 \end{align*} L=−ylog(y\^)+(1−y)log(1−y\^)=−1×log(0.7077)+0×log(0.2923)=−log(0.7077)≈0.3456
4.4 反向传播(逐层求梯度)
Step 6:损失对 ŷ 的梯度
使用交叉熵对 Sigmoid 输出的联合导数(这两个组合后有非常简洁的形式):
∂L∂Z2=A2−y=0.7077−1=−0.2923 \frac{\partial L}{\partial Z_2} = A_2 - y = 0.7077 - 1 = -0.2923 ∂Z2∂L=A2−y=0.7077−1=−0.2923
💡 简化技巧 对于 Sigmoid + 交叉熵的组合, \\partial L / \\partial Z = A - y ,非常简洁,推导时无需展开两层链式法则。
Step 7:输出层权重 W₂ 的梯度
∂L∂W21=∂L∂Z2⋅A11=(−0.2923)×0.6457≈−0.1887∂L∂W22=∂L∂Z2⋅A12=(−0.2923)×0.7685≈−0.2246∂L∂b2=∂L∂Z2⋅1=−0.2923 \begin{align*} \frac{\partial L}{\partial W_21} &= \frac{\partial L}{\partial Z_2} \cdot A_11 = (-0.2923) \times 0.6457 \approx -0.1887 \\ \frac{\partial L}{\partial W_22} &= \frac{\partial L}{\partial Z_2} \cdot A_12 = (-0.2923) \times 0.7685 \approx -0.2246 \\ \frac{\partial L}{\partial b_2} &= \frac{\partial L}{\partial Z_2} \cdot 1 = -0.2923 \end{align*} ∂W21∂L∂W22∂L∂b2∂L=∂Z2∂L⋅A11=(−0.2923)×0.6457≈−0.1887=∂Z2∂L⋅A12=(−0.2923)×0.7685≈−0.2246=∂Z2∂L⋅1=−0.2923
Step 8:反向传播到隐藏层
首先计算 A₁ 的梯度(通过 W₂ 反传):
∂L∂A11=∂L∂Z2⋅W21=(−0.2923)×0.5=−0.1462∂L∂A12=∂L∂Z2⋅W22=(−0.2923)×0.6=−0.1754 \begin{align*} \frac{\partial L}{\partial A_11} &= \frac{\partial L}{\partial Z_2} \cdot W_21 = (-0.2923) \times 0.5 = -0.1462 \\ \frac{\partial L}{\partial A_12} &= \frac{\partial L}{\partial Z_2} \cdot W_22 = (-0.2923) \times 0.6 = -0.1754 \end{align*} ∂A11∂L∂A12∂L=∂Z2∂L⋅W21=(−0.2923)×0.5=−0.1462=∂Z2∂L⋅W22=(−0.2923)×0.6=−0.1754
然后通过 Sigmoid 的导数( \\sigma'(z) = \\sigma(z) \\cdot (1 - \\sigma(z)) )继续反传:
σ′(Z11)=A11⋅(1−A11)=0.6457×0.3543≈0.2287σ′(Z12)=A12⋅(1−A12)=0.7685×0.2315≈0.1779 \begin{align*} \sigma'(Z_11) &= A_11 \cdot (1 - A_11) = 0.6457 \times 0.3543 \approx 0.2287 \\ \sigma'(Z_12) &= A_12 \cdot (1 - A_12) = 0.7685 \times 0.2315 \approx 0.1779 \end{align*} σ′(Z11)σ′(Z12)=A11⋅(1−A11)=0.6457×0.3543≈0.2287=A12⋅(1−A12)=0.7685×0.2315≈0.1779
∂L∂Z11=∂L∂A11⋅σ′(Z11)=(−0.1462)×0.2287≈−0.0334∂L∂Z12=∂L∂A12⋅σ′(Z12)=(−0.1754)×0.1779≈−0.0312 \begin{align*} \frac{\partial L}{\partial Z_11} &= \frac{\partial L}{\partial A_11} \cdot \sigma'(Z_11) = (-0.1462) \times 0.2287 \approx -0.0334 \\ \frac{\partial L}{\partial Z_12} &= \frac{\partial L}{\partial A_12} \cdot \sigma'(Z_12) = (-0.1754) \times 0.1779 \approx -0.0312 \end{align*} ∂Z11∂L∂Z12∂L=∂A11∂L⋅σ′(Z11)=(−0.1462)×0.2287≈−0.0334=∂A12∂L⋅σ′(Z12)=(−0.1754)×0.1779≈−0.0312
Step 9:隐藏层权重 W₁ 的梯度
∂L∂W100=∂L∂Z11⋅x1=(−0.0334)×1.0=−0.0334∂L∂W101=∂L∂Z11⋅x2=(−0.0334)×2.0=−0.0669∂L∂W110=∂L∂Z12⋅x1=(−0.0312)×1.0=−0.0312∂L∂W111=∂L∂Z12⋅x2=(−0.0312)×2.0=−0.0624∂L∂b11=∂L∂Z11=−0.0334∂L∂b12=∂L∂Z12=−0.0312 \begin{align*} \frac{\partial L}{\partial W_100} &= \frac{\partial L}{\partial Z_11} \cdot x_1 = (-0.0334) \times 1.0 = -0.0334 \\ \frac{\partial L}{\partial W_101} &= \frac{\partial L}{\partial Z_11} \cdot x_2 = (-0.0334) \times 2.0 = -0.0669 \\ \frac{\partial L}{\partial W_110} &= \frac{\partial L}{\partial Z_12} \cdot x_1 = (-0.0312) \times 1.0 = -0.0312 \\ \frac{\partial L}{\partial W_111} &= \frac{\partial L}{\partial Z_12} \cdot x_2 = (-0.0312) \times 2.0 = -0.0624 \\ \frac{\partial L}{\partial b_11} &= \frac{\partial L}{\partial Z_11} = -0.0334 \\ \frac{\partial L}{\partial b_12} &= \frac{\partial L}{\partial Z_12} = -0.0312 \end{align*} ∂W100∂L∂W101∂L∂W110∂L∂W111∂L∂b11∂L∂b12∂L=∂Z11∂L⋅x1=(−0.0334)×1.0=−0.0334=∂Z11∂L⋅x2=(−0.0334)×2.0=−0.0669=∂Z12∂L⋅x1=(−0.0312)×1.0=−0.0312=∂Z12∂L⋅x2=(−0.0312)×2.0=−0.0624=∂Z11∂L=−0.0334=∂Z12∂L=−0.0312
4.5 参数更新(α = 0.1)
| 参数 | 旧值 | 梯度 | 新值 = 旧值 - 0.1×梯度 |
|---|---|---|---|
| W₂1 | 0.5000 | -0.1887 | 0.5000 - 0.1×(-0.1887) = 0.5189 |
| W₂2 | 0.6000 | -0.2246 | 0.6000 - 0.1×(-0.2246) = 0.6225 |
| b₂ | 0.1000 | -0.2923 | 0.1000 - 0.1×(-0.2923) = 0.1292 |
| W₁00 | 0.1000 | -0.0334 | 0.1000 - 0.1×(-0.0334) = 0.1033 |
| W₁01 | 0.2000 | -0.0669 | 0.2000 - 0.1×(-0.0669) = 0.2067 |
| W₁10 | 0.3000 | -0.0312 | 0.3000 - 0.1×(-0.0312) = 0.3031 |
| W₁11 | 0.4000 | -0.0624 | 0.4000 - 0.1×(-0.0624) = 0.4062 |
✅ 验证方向 所有梯度均为负值,参数更新后均变大。由于真实标签 y=1 而预测值 ŷ≈0.71(偏低),网络通过增大权重来提高预测概率,方向完全符合逻辑。
图示:反向传播梯度流动示意图
第五章:Python/NumPy 实现更复杂的 MLP
5.1 为什么转向 Python?
手算验证了梯度下降的原理,但面对实际问题时(数百个神经元、万级样本),手算完全不可行。Python + NumPy 可以用简洁的矩阵操作实现完整的神经网络,且不依赖任何自动微分框架------所有梯度均手动推导实现。
5.2 XOR 分类问题
我们用经典的 XOR(异或)问题来验证 MLP:XOR 是线性不可分的,单层感知机无法学习,但 MLP 可以。
| x₁ | x₂ | y(XOR输出) | 含义 |
|---|---|---|---|
| 0 | 0 | 0 | 两个输入相同 → 输出0 |
| 0 | 1 | 1 | 两个输入不同 → 输出1 |
| 1 | 0 | 1 | 两个输入不同 → 输出1 |
| 1 | 1 | 0 | 两个输入相同 → 输出0 |
5.3 完整 NumPy 实现代码
以下是不使用任何深度学习框架的完整 MLP 实现,所有梯度均手动计算:
python
import numpy as np
# ─── 1. 数据 ──────────────────────────────────────────────────
X = np.array([[0,0],[0,1],[1,0],[1,1]], dtype=float) # (4,2)
y = np.array([[0],[1],[1],[0]], dtype=float) # (4,1)
# ─── 2. 激活函数 ──────────────────────────────────────────────
def sigmoid(z): return 1 / (1 + np.exp(-z))
def sigmoid_d(a): return a * (1 - a) # σ'=σ(1-σ)
# ─── 3. 参数初始化(隐藏层4个神经元)──────────────────────────
np.random.seed(42)
W1 = np.random.randn(2, 4) * 0.5 # 输入层→隐藏层,形状(2,4)
b1 = np.zeros((1, 4)) # 隐藏层偏置,形状(1,4)
W2 = np.random.randn(4, 1) * 0.5 # 隐藏层→输出层,形状(4,1)
b2 = np.zeros((1, 1)) # 输出层偏置,形状(1,1)
# ─── 4. 训练循环 ──────────────────────────────────────────────
lr = 0.5 # 学习率
epochs = 10000 # 迭代次数
for epoch in range(epochs):
# ── 前向传播 ──
Z1 = X @ W1 + b1 # (4,2)@(2,4)=(4,4)
A1 = sigmoid(Z1) # (4,4)
Z2 = A1 @ W2 + b2 # (4,4)@(4,1)=(4,1)
A2 = sigmoid(Z2) # (4,1) 预测值
# ── 损失(二元交叉熵)──
loss = -np.mean(y*np.log(A2+1e-8) + (1-y)*np.log(1-A2+1e-8))
# ── 反向传播(手动梯度)──
N = X.shape[0] # 批次大小=4
dZ2 = (A2 - y) / N # 输出层δ:(4,1)
dW2 = A1.T @ dZ2 # (4,4).T@(4,1)=(4,1)
db2 = np.sum(dZ2, axis=0, keepdims=True)
dA1 = dZ2 @ W2.T # (4,1)@(1,4)=(4,4)
dZ1 = dA1 * sigmoid_d(A1) # 逐元素乘,(4,4)
dW1 = X.T @ dZ1 # (2,4)
db1 = np.sum(dZ1, axis=0, keepdims=True)
# ── 参数更新(梯度下降)──
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
if epoch % 1000 == 0:
print(f"Epoch {epoch:5d} | Loss: {loss:.4f}")
# ─── 5. 最终预测 ──────────────────────────────────────────────
print('\n最终预测(>0.5为1):')
print((A2 > 0.5).astype(int)) # 期望: [[0],[1],[1],[0]]5.4 预期输出与分析
运行上述代码,你将看到损失函数逐渐下降:
| 迭代次数 | 损失值(参考) | 说明 |
|---|---|---|
| Epoch 0 | ~0.69 | 接近随机猜测时的交叉熵 |
| Epoch 1000 | ~0.45 | 网络开始学习 |
| Epoch 3000 | ~0.12 | 收敛加速 |
| Epoch 7000 | ~0.02 | 接近完美拟合 |
| Epoch 9999 | ~0.008 | 最终预测全部正确 |
🚀 核心成就 我们用不到40行纯 NumPy 代码,完整实现了一个能学习 XOR 这种非线性规律的两层神经网络,且所有梯度均手动推导。这正是理解 PyTorch/TensorFlow 底层机制的最佳路径。
图示:XOR数据分布与决策边界演化过程
第六章:梯度下降法的局限性与改进
6.1 梯度下降的五大核心局限
局限一:陷入局部最优(Local Minima)
深度网络的损失面(Loss Landscape)极其复杂,存在无数个局部极小值。标准梯度下降一旦陷入局部最优,便无法逃脱。
想象:山谷中有许多小坑,滚球可能停在一个小坑里,而非最深的谷底
实际上,深度学习研究者发现:高维空间中的"局部最优"通常是鞍点(Saddle Points),而非真正的谷底。鞍点的危害更大------在某些方向梯度为零,使训练停滞。
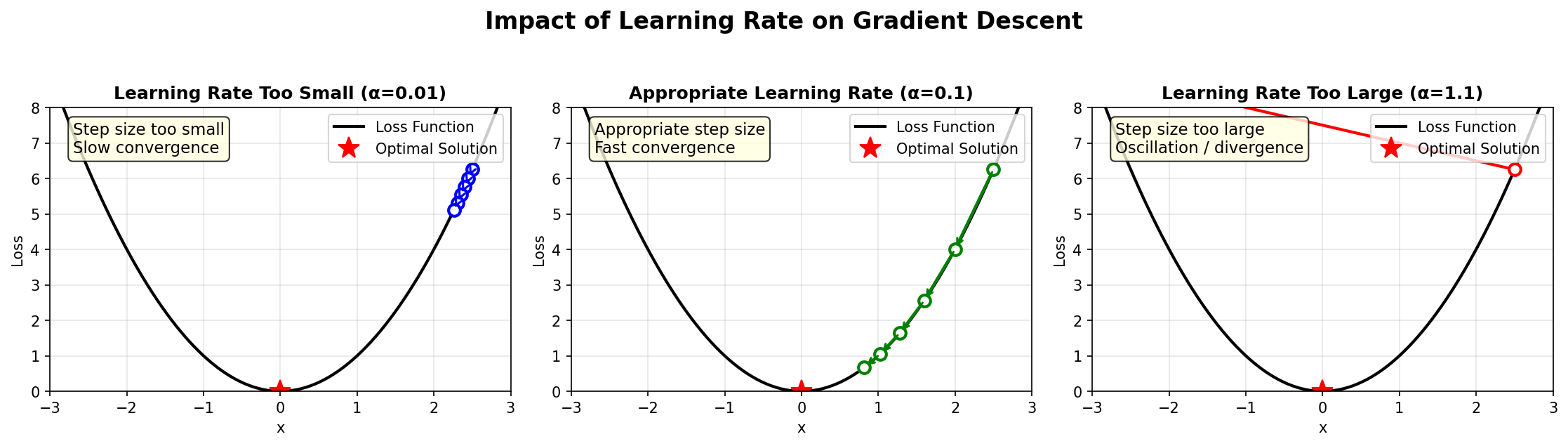
局限二:学习率难以设定
| 学习率状态 | 现象 | 后果 |
|---|---|---|
| 过大(α太高) | 更新步长过大,跳过最优解 | 损失震荡甚至发散 |
| 过小(α太低) | 更新极慢,需要大量迭代 | 训练时间过长,可能停滞 |
| 固定学习率 | 训练初期需大步,后期需小步 | 无法两全,效率低下 |
局限三:梯度消失(Vanishing Gradient)
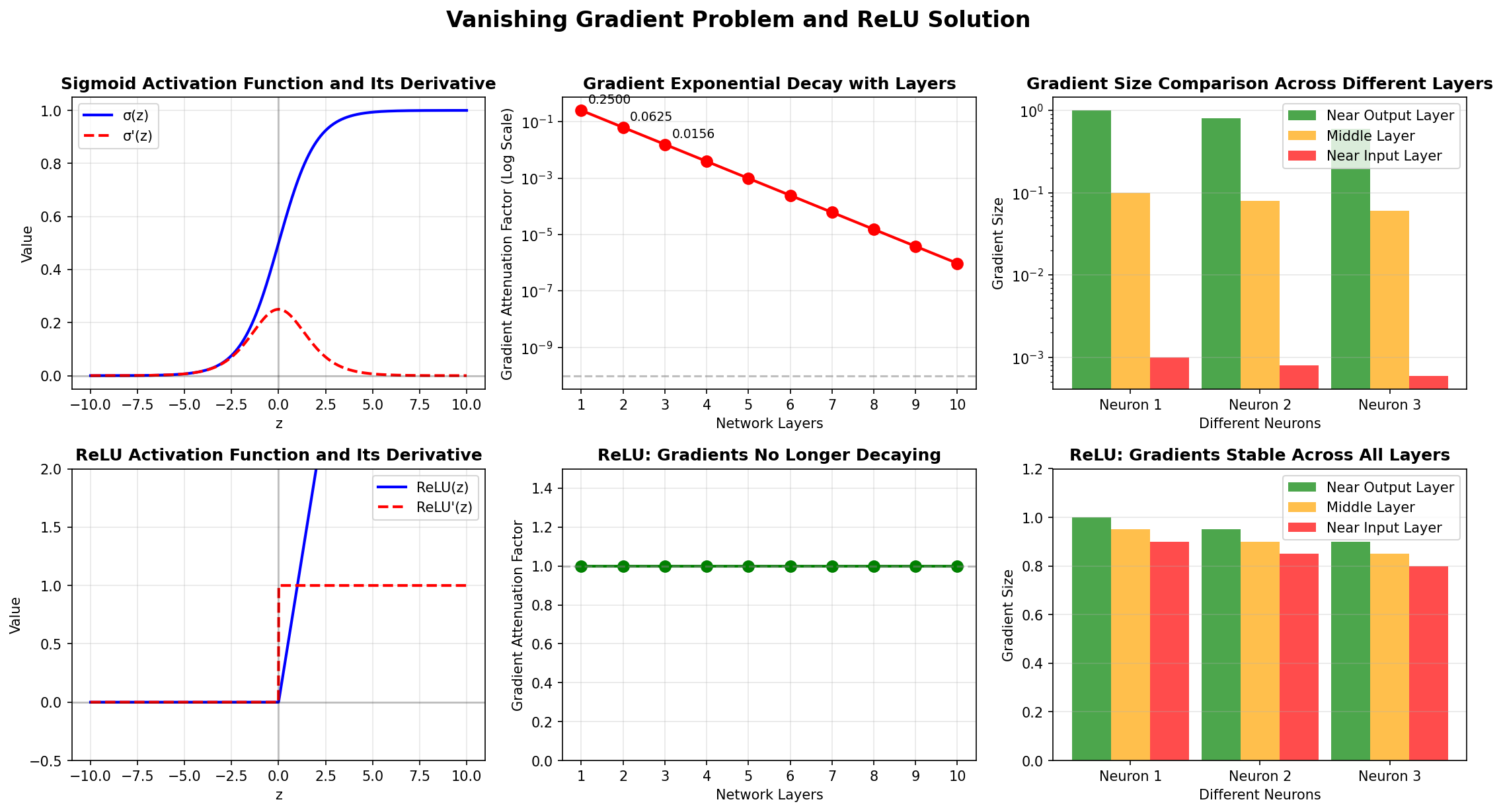
在深层网络中,梯度通过链式法则从输出层反向传播到输入层时,会被反复乘以小于1的值(如 Sigmoid 的导数最大只有0.25),导致靠近输入层的梯度趋向于零。
第 L 层的梯度≈σ′(zL)×σ′(zL−1)×⋯×σ′(z1) \text{第 } L \text{ 层的梯度} \approx \sigma'(z_L) \times \sigma'(z_{L-1}) \times \cdots \times \sigma'(z_1) 第 L 层的梯度≈σ′(zL)×σ′(zL−1)×⋯×σ′(z1)
若每个 \\sigma' \\approx 0.1 ,经过10层:,经过10层:,经过10层: 0.1\^{10} = 10\^{-10} \\to 接近于0
梯度消失导致深层网络的浅层参数几乎无法更新,是限制深度学习早期发展的关键障碍。
图示:梯度大小随层数衰减趋势
局限四:批量梯度下降(BGD)计算开销
标准梯度下降(Batch Gradient Descent)每次更新都要遍历全部训练数据,计算所有样本的梯度之和。当数据集有百万级样本时,每次参数更新的计算量巨大。
局限五:各维度学习步调不一致
不同参数的梯度大小可能相差悬殊(例如某个特征变化范围很大,另一个很小),导致损失面形状极不规则(拉伸的椭圆而非正圆),梯度下降路径曲折,收敛慢。
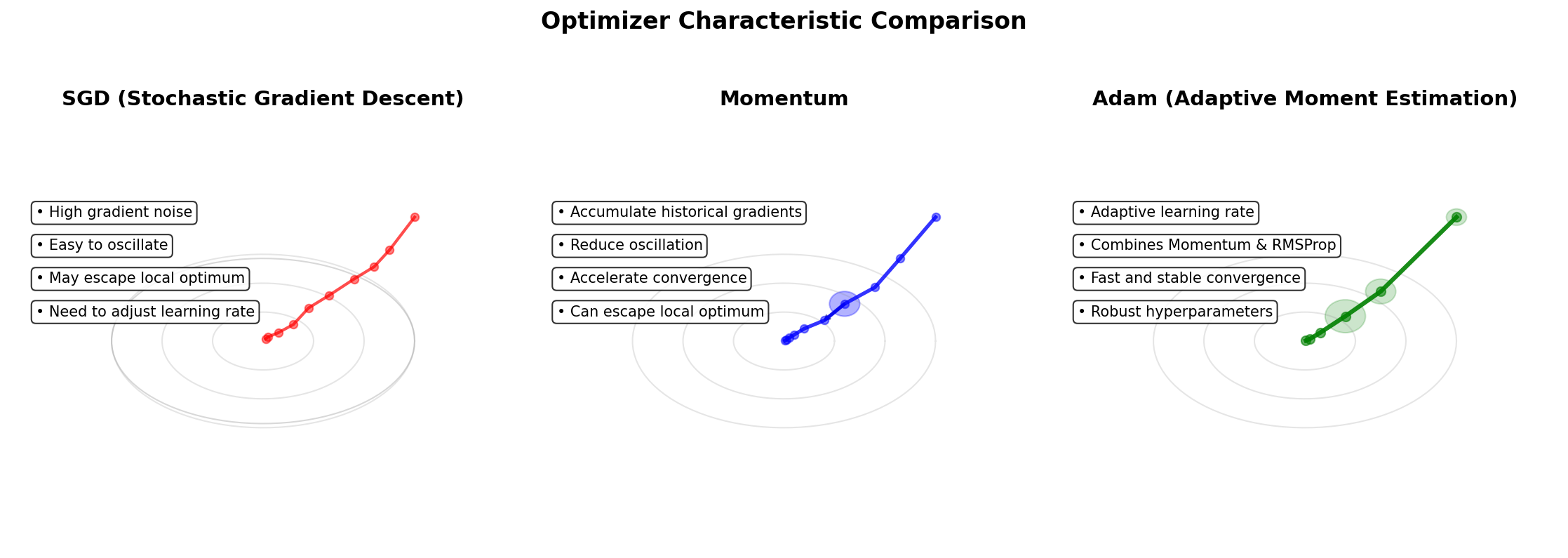
6.2 改进方案概览
| 局限问题 | 改进方法 | 核心思路 | 效果 |
|---|---|---|---|
| 鞍点 / 局部最优 | 随机梯度下降(SGD)+ 动量 | 随机噪声帮助逃出鞍点 | ★★★★ |
| 学习率难设定 | 学习率调度(LR Scheduler) | 随训练进程动态调整学习率 | ★★★ |
| 各维度不一致 | AdaGrad / RMSProp | 为每个参数自适应调整学习率 | ★★★★ |
| 梯度消失 | ReLU激活函数 + BatchNorm | 避免饱和区,稳定梯度范围 | ★★★★★ |
| 综合优化 | Adam优化器 | 结合动量+自适应学习率 | ★★★★★ |
6.3 现代优化器:Adam 简介
Adam(Adaptive Moment Estimation,2014年,Kingma & Ba)是目前最广泛使用的优化器,综合了动量法(Momentum)和 RMSProp 的优点:
Adam 更新规则
mt=β1⋅mt−1+(1−β1)⋅gt(一阶矩:梯度的指数移动平均)vt=β2⋅vt−1+(1−β2)⋅gt2(二阶矩:梯度平方的指数移动平均)m^t=mt1−β1t(偏差修正)v^t=vt1−β2t(偏差修正)θt=θt−1−α⋅m^tv^t+ε(参数更新) \begin{aligned} m_t &= \beta_1 \cdot m_{t-1} + (1-\beta_1) \cdot g_t & \text{(一阶矩:梯度的指数移动平均)} \\ v_t &= \beta_2 \cdot v_{t-1} + (1-\beta_2) \cdot g_t^2 & \text{(二阶矩:梯度平方的指数移动平均)} \\ \hat{m}_t &= \frac{m_t}{1-\beta_1^t} & \text{(偏差修正)} \\ \hat{v}t &= \frac{v_t}{1-\beta_2^t} & \text{(偏差修正)} \\ \theta_t &= \theta{t-1} - \alpha \cdot \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \varepsilon} & \text{(参数更新)} \end{aligned} mtvtm^tv^tθt=β1⋅mt−1+(1−β1)⋅gt=β2⋅vt−1+(1−β2)⋅gt2=1−β1tmt=1−β2tvt=θt−1−α⋅v^t +εm^t(一阶矩:梯度的指数移动平均)(二阶矩:梯度平方的指数移动平均)(偏差修正)(偏差修正)(参数更新)
典型超参数: \\beta_1=0.9, \\beta_2=0.999, \\varepsilon=1e-8 ,,, \\alpha=0.001 (默认学习率通常更鲁棒)
6.4 三种梯度下降变体对比
| 变体 | 每次更新用到的数据量 | 优点 | 缺点 |
|---|---|---|---|
| 批量梯度下降 (BGD) | 全部 N 个样本 | 梯度准确,收敛稳定 | 每步计算量大 |
| 随机梯度下降 (SGD) | 1 个样本 | 更新快,可逃出鞍点 | 梯度噪声大,震荡 |
| 小批量梯度下降 (Mini-batch GD) | B 个样本(通常16~256) | 兼顾速度和稳定性 | 需调整批大小 |
🎯 实践建议 在实际工程中,Mini-batch SGD + Adam 是最常见的组合。批大小 B 通常取32或128;学习率从 0.001 开始,配合学习率衰减策略(如余弦退火)。
6.5 学习路径建议
📚 推荐延伸阅读
- 《Deep Learning》(Goodfellow, Bengio, Courville)- 深度学习圣经,免费在线阅读
- CS231n: Convolutional Neural Networks for Visual Recognition(Stanford,免费课程)
- 《动手学深度学习》(李沐 et al.)- 中文,代码详尽,适合初学者
- 原始论文:Adam: A Method for Stochastic Optimization(Kingma & Ba, 2014)
- 原始论文:Learning representations by back-propagating errors(Rumelhart, 1986)