在云产品智能诊断场景里,ReAct 很强,但也很容易"想太多、做太久、停不下"。
尤其当诊断对象是 K8s、ECS、负载均衡、数据库、配置中心这类强依赖外部状态的系统时,模型经常会在同一个观察---推理---行动闭环里反复绕圈:查了同一个日志、读了同一段事件、得到了几乎没变化的结果,然后继续得出相似结论,最终进入死循环。
这时候,单纯依赖 prompt 里的一句"请避免重复"通常不够。
更稳妥的方式,是在 ReAct 外围加一层 Harness:它负责统计近期执行轨迹、识别循环模式、触发干预策略,并在必要时中止或切换执行路径。
ReAct 负责推理,Harness 负责监控和打断,Verifier 负责验收。
同时还要补充一点:如果某些场景本身是固定流程,且步骤明确、依赖稳定,那就不一定适合交给 ReAct 动态编排,应该由工程系统自己按固定流程编排执行。
也就是说,能流程化的就流程化,能确定性的就不要让模型自由发挥。
一、云产品智能诊断里,ReAct 为什么容易死循环
云诊断和普通问答不一样,它不是"答对就行",而是要在大量噪声信息中持续收敛根因。
这类任务有几个典型特征:
- 输入不完整,往往只有一条告警或一段报错
- 信息分散在日志、指标、事件、配置、发布记录里
- 证据之间可能互相矛盾
- 最终结论必须能被验证
- 中途状态还会变化,比如实例重启、Pod 重建、流量切换
在这种情况下,ReAct 很容易出现以下问题:
1)一直在同一条假设上打转
比如看到 ImagePullBackOff,模型不断检查镜像、仓库、secret、deployment diff,但结果其实已经证明镜像 tag 写错了,却没有明确终止条件,继续查下去就会重复。
2)工具调用没有新信息
模型会反复调用同一个检查工具,参数也几乎一致,但观察值没有变化。
3)上下文越来越长
历史日志、事件和推理都堆在上下文里,模型开始依赖旧判断,导致错误被放大。
4)模型自己不知道已经循环了
ReAct 的循环本身是"合理的",因为它每一轮都在根据观察继续推理;但如果缺少外部约束,它就可能永远不结束。
二、Harness 在哪里介入
Harness 不是简单"再加一个提示词",而是一个外部控制层。
它把"模型是否在循环里"这件事做成一个工程问题,而不是让模型自我判断。
Harness 的核心职责包括:
- 统计近期执行轨迹
- 识别重复工具调用
- 识别重复观察结果
- 识别重复结论文本
- 判断是否进入死循环
- 注入干预 prompt
- 限制工具
- 压缩上下文
- 中止执行
- 切换策略
- 交给 Verifier 验收
三、架构&时序
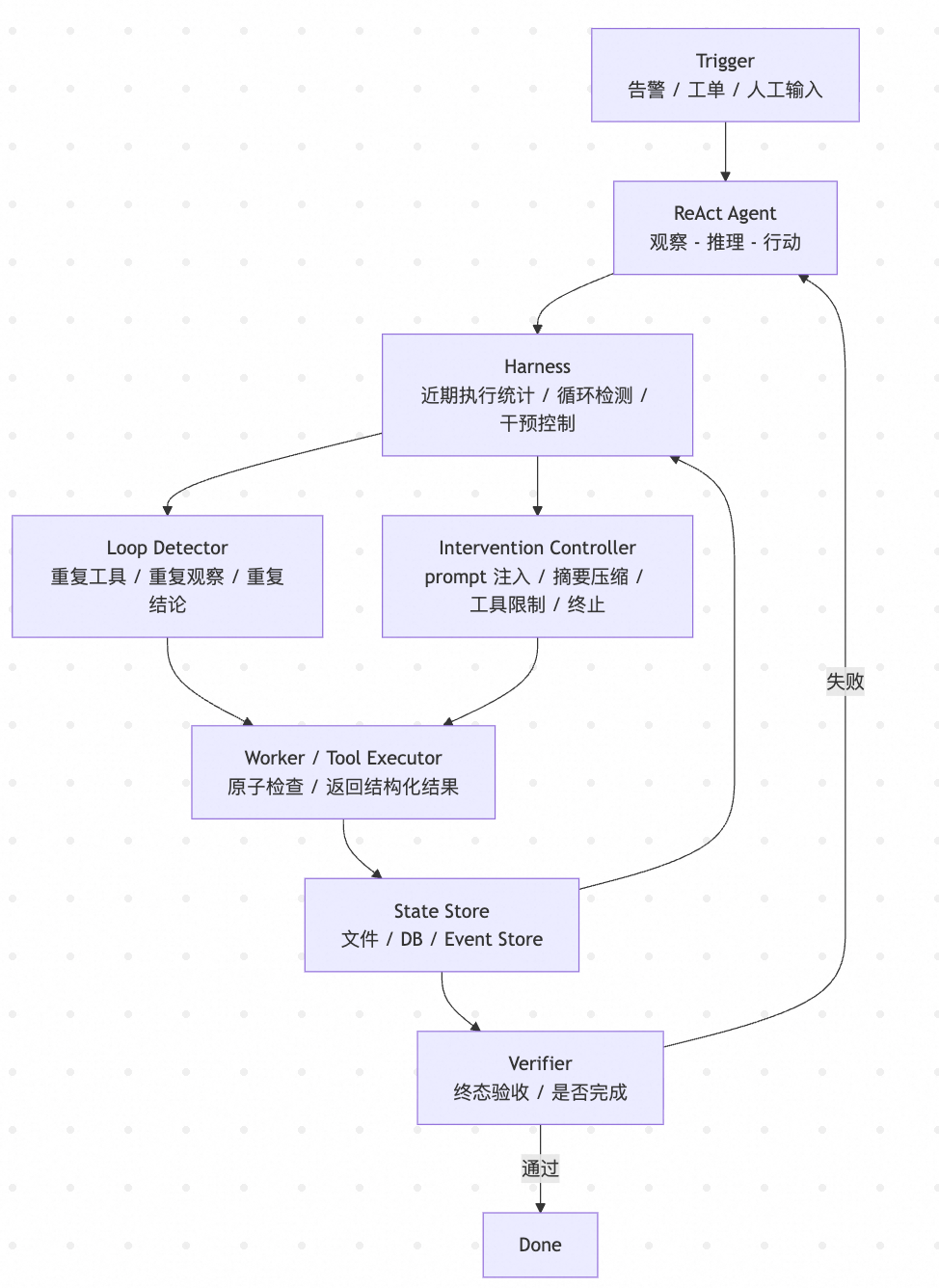
这张架构图展示了 ReAct 死循环的工程化解决方案:ReAct 负责推理和工具调用,Harness 负责统计近期执行并判断是否进入循环,必要时通过 prompt 干预、工具限制或终止执行来打断回路,Verifier 则负责最终验收。
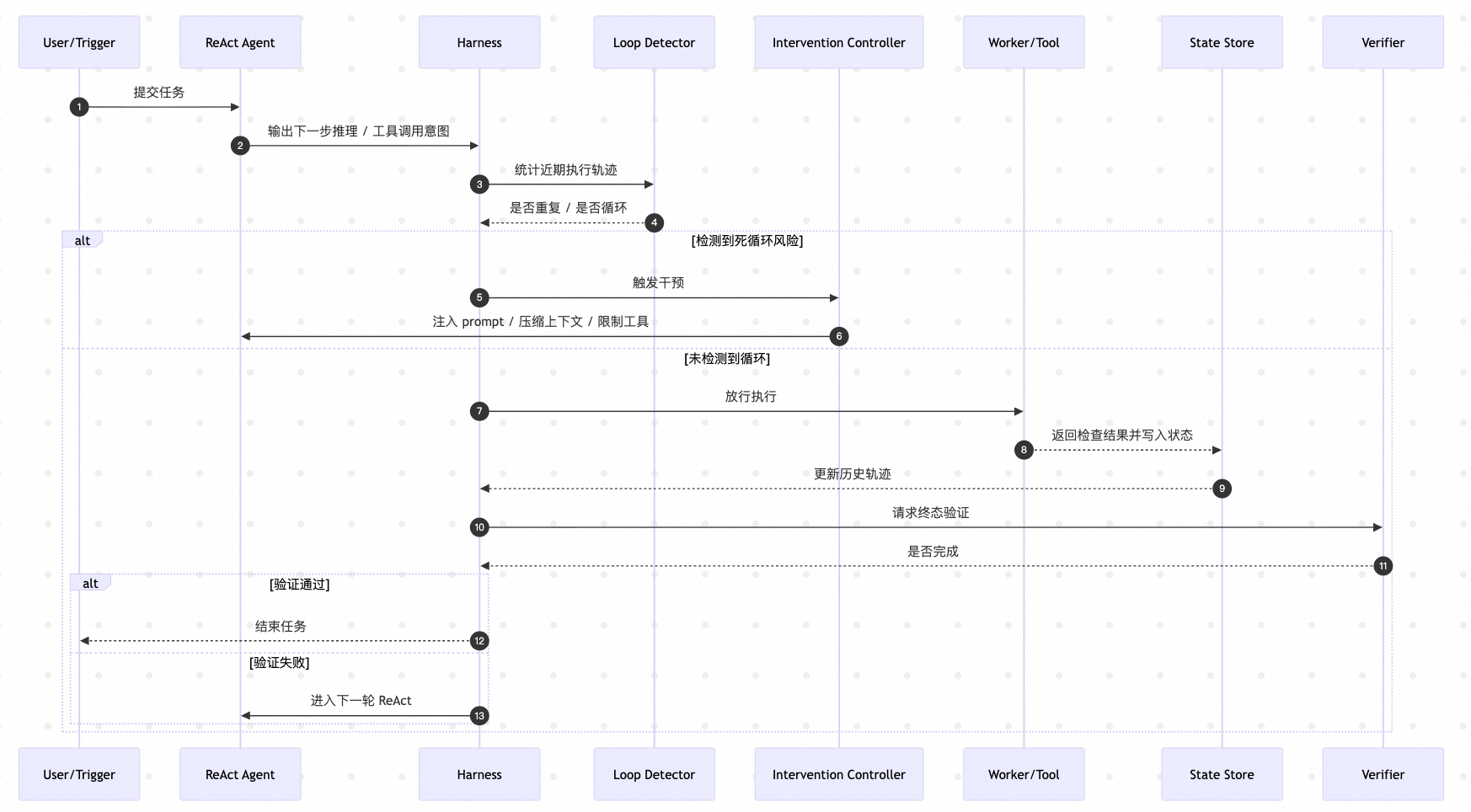
这张时序图说明了 Harness 如何在每轮执行前后介入:先统计近期轨迹,判断是否出现重复模式;若命中循环风险,则注入干预;若未命中,则允许继续执行,并在状态外化后进入终态验证。
四、云产品智能诊断案例:Pod 启动失败导致 ReAct 反复打转
下面用一个最常见的 K8s 场景来说明。
场景现象
某个 Deployment 更新后,Pod 一直处于:
ImagePullBackOff执行:
kubectl get pods看到:
my-app-5d7d978fb9-2fj5m 0/1 ImagePullBackOff 0 2m这说明 Pod 在拉镜像阶段就失败了。
如果没有 Harness,ReAct 可能怎么循环
第 1 轮
- 观察:Pod
ImagePullBackOff - 推理:可能是镜像不存在
- 行动:查镜像 tag
第 2 轮
- 观察:镜像 tag 不匹配
- 推理:可能是仓库认证失败
- 行动:查
imagePullSecret
第 3 轮
- 观察:secret 正常
- 推理:可能是仓库网络问题
- 行动:查仓库连通性
第 4 轮
- 观察:连通性正常
- 推理:可能是 deployment 配置错了
- 行动:查部署 diff
第 5 轮
- 观察:diff 显示镜像 tag 的确写错了
- 推理:问题已定位,但模型仍继续想确认更多证据
- 行动:重复查镜像、重复查事件......
这时,如果没有外部约束,ReAct 很容易继续绕圈,明明已经足够收敛,却迟迟不退出。
有 Harness 介入后,流程会怎样变化
第 1 轮:规划
ReAct 先生成诊断路径:
- 查镜像引用
- 查 Pod 事件
- 查
imagePullSecret - 查部署 diff
第 2 轮:执行与统计
Harness 记录每次工具调用和观察结果,发现:
check_image_reference已调用过query_pod_events已调用过inspect_image_pull_secret已调用过get_deployment_diff已调用过
第 3 轮:循环检测
Loop Detector 判断:
- 连续 3 轮观察变化很小
- 同一个工具调用重复出现
- 结论和上一轮高度相似
于是 Harness 触发干预。
第 4 轮:干预
Intervention Controller 可以做这些事:
- 注入 prompt:
"你已经检查过镜像、事件和 secret,请切换到终态判断,不要重复相同工具。" - 压缩上下文:
只保留关键证据,例如image_tag = v2.0、image_exists = false - 限制工具:
临时禁用已经重复调用的工具 - 直接终止:
如果已经达到阈值,升级人工
第 5 轮:Verifier 验收
如果修复后 Pod 变为 Running,readiness probe 通过,任务结束。
如果没有通过,进入下一轮诊断,但不会再无限重复同一路径。
五、固定流程场景:不要强行交给 ReAct 动态编排
还有一种情况要特别说明:
如果某些场景本身是固定流程、步骤明确、依赖稳定,那就不应该让 ReAct 动态编排,应该由工程系统自己按固定流程执行。
比如:
- 固定的巡检流程
- 固定的上线前校验流程
- 固定的告警分级流程
- 固定的修复脚本执行流程
这类场景的特点是:
- 步骤已知
- 顺序明确
- 条件稳定
- 不需要模型自由判断太多
这种情况下,最好的做法不是让 ReAct 自己决定下一步,而是直接由编排引擎、工作流引擎或脚本流程来控制执行顺序 。
ReAct 更适合处理不确定、信息不完整、需要动态判断的情况;固定流程交给固定编排,效率更高,风险更小,也更容易审计。
六、ReAct 死循环排查清单
下面这部分可以直接作为公众号正文里的实操清单。
1)先确认是不是真的进入死循环
观察是否存在以下特征:
- 同一个工具反复调用
- 同一组观察结果重复出现
- 模型输出高度相似
- token 消耗持续上升,但状态没有变化
- 一直没有进入完成或失败退出
2)检查终止条件是否清晰
最常见的问题是:没有明确的结束标准。
排查点
- 是否只靠模型自己判断完成?
- 是否有外部验收条件?
- 是否有明确的成功标志?
- 是否有失败退出条件?
修复建议
- 增加
max_iterations - 增加
completion_promise - 增加外部验证,例如测试通过、状态变更、目标文件生成
3)检查是否存在状态更新触发自身再次更新
很多死循环,本质上是:
当前步骤更新了某个状态,这个状态又反过来触发了同一个步骤。
修复建议
- 用
ref保存不应触发重渲染的状态 - 对对象/数组做稳定化处理
- 避免在 effect 内直接修改触发源状态
- 把"计算下一步"和"写回状态"分离
4)检查工具调用是否缺少去重和幂等
修复建议
- 对工具调用做 request hash 去重
- 相同输入在短时间内直接复用结果
- 给工具调用加幂等键
- 对重复调用直接返回上次结果
5)检查观察结果是否真的有变化
修复建议
- 提升工具输出质量
- 让工具返回更结构化的信息
- 加入更多上下文维度
- 必要时做降级,直接转人工
6)检查模型是否在"自我确认"
修复建议
- 要求每一轮必须产出"新证据"或"新动作"
- 如果没有新信息,禁止继续同一路径
- 对重复结论做拦截
7)检查上下文是否过长导致失焦
修复建议
- 做上下文摘要
- 只保留关键证据
- 把状态外化到文件或数据库
- 让下一轮只读摘要,不读全量历史
8)检查是否缺少最大迭代次数
修复建议
- 必须设置
max_iterations - 超限后自动退出并升级人工
- 记录失败原因,而不是继续空转
9)检查是否该切换到别的模式
如果任务具备以下特点:
- 结果可验证
- 需要长期执行
- 有明确终态
- 需要强制推进
那就不要只靠 ReAct,应该切到:
- Claude Code 式 Agent Loop
- Harness 驱动的执行循环
- 状态外化 + 验证机制
七、Harness 在工程上如何打断循环
1)执行前:统计近期轨迹
Harness 会观察最近 N 轮的:
- 工具调用
- 返回结果
- 观察摘要
- 结论文本
如果发现:
- 同一工具重复调用
- 同一参数 hash 反复出现
- 同一观察重复 2~3 轮
- 结论没有新增证据
就判定为循环风险。
2)执行中:注入干预
当 Harness 判断进入循环时,可以做几种干预:
- 注入新的 prompt,要求切换诊断路径
- 压缩上下文,只保留关键证据
- 禁止继续调用同一个工具
- 切换到更保守的策略
- 直接中止并升级人工
3)执行后:验收是否真的收敛
即便 ReAct 产生了"看起来合理"的结论,也不能直接结束。
Harness 会把结果送到 Verifier,检查目标状态是否真的改变。
没有通过验收,就继续下一轮,而不是让模型自己宣布结束。
八、工程落地建议
1)ReAct 层只负责规划
不要让它承担终态判定。
2)Harness 层负责循环监控
这是防死循环的关键。
3)状态一定要外化
把调用历史、观察结果、去重键、失败原因全部写到文件或数据库里。
4)Verifier 必须独立
不要把"是否完成"交给模型主观判断。
5)对重复调用做硬约束
对已经命中过的工具、参数、观察结果,做强制去重和限流。
6)固定流程交给编排系统
如果是已知步骤、已知顺序、已知条件的固定流程,不要强行交给 ReAct 动态编排,直接由工作流或脚本执行更稳。
九、总结
ReAct 死循环,本质上是推理闭环没有被外部约束切断 。
在云产品智能诊断里,这个问题尤其常见,因为任务本身就依赖外部系统状态,天然容易反复验证、反复推理、反复确认。
真正有效的解决方案,不是让模型"更聪明一点",而是把系统做成一个工程闭环:
- ReAct 负责找方向
- Harness 负责监控和打断循环
- State Store 负责记录与恢复
- Verifier 负责终态验收
- 固定流程 则交给工程编排系统