

**前引:**复合查询的逻辑整合与多表查询的关联技巧,正是突破这一瓶颈的关键,也是从"会用MySQL"到"用好MySQL"的重要分水岭。本文将聚焦这两大核心知识点,结合实际场景拆解逻辑、梳理方法,帮助你夯实查询基础,在复杂数据需求中精准高效地提取信息。复合查询的逻辑整合与多表查询的关联技巧,正是突破这一瓶颈的关键,也是从"会用MySQL"到"用好MySQL"的重要分水岭。本文将聚焦这两大核心知识点,结合实际场景拆解逻辑、梳理方法,帮助你夯实查询基础,在复杂数据需求中精准高效地提取信息!
目录
[(4)group by](#(4)group by)
[(6)order by](#(6)order by)
[(3)页目录 与 B+树](#(3)页目录 与 B+树)
语句顺序(必掌握)
牢记下面关键字的书写顺序(非执行顺序):
select→from→where→group by→having→order by→limit
(1)select
作用:指定 "要显示哪些字段"
(2)from
作用:告诉 MySQL,你要查的数据来自哪个 / 哪些表
(3)where
作用:筛选 "满足条件的内容",一般搭配条件,如下
| 条件类型 | 符号 | 需求例子 | SQL 写法 |
|---|---|---|---|
| 等于(精确匹配) | = | 查姓名是 "张三" 的学生 | SELECT * FROM student WHERE name = '张三'; |
| 大于 / 小于 | > / < | 查分数>80 的成绩 | SELECT * FROM score WHERE score > 80; |
| 不等于 | != 或 <> | 查不是 "数学" 科目的成绩 | SELECT * FROM score WHERE subject != '数学'; |
| 包含在列表里 | IN | 查 "语文" 或 "数学" 的成绩 | SELECT * FROM score WHERE subject IN ('语文', '数学'); |
| 是空值(无数据) | IS NULL | 查缺考的成绩(分数为 null) | SELECT * FROM score WHERE score IS NULL; |
| 不是空值 | IS NOT NULL | 查有分数的成绩 | SELECT * FROM score WHERE score IS NOT NULL; |
(4)group by
作用:按 "某个字段分组",比如:成绩有三种,那么就有三组
注意:select中的非聚合字段必须全部出现在 group by 后面,比如:
cpp
-- select后非聚合字段:user_id、order_status(都在group by里)
-- 聚合字段:sum(amount)(无需在group by里)
select
user_id, -- 非聚合字段,在group by里
order_status, -- 非聚合字段,在group by里
sum(amount) as total_amount -- 聚合字段
from orders
group by user_id, order_status; -- group by参数:两个非聚合字段
(5)having
作用: 过滤 "分组后的结果",where是分组前过滤,having是分组后过滤(比如数学低于30分)
(6)order by
作用:对数据进行排序(升序 / 降序)
(7)limit
作用:返回的行数控制,比如 limit 3:只显示3行
(8)替换where:on...and
好处:一行搞定 "连表 + 过滤";
- ON :负责 "两张表怎么连"(必须写,比如学生表和成绩表靠
student.id = score.stu_id) - AND:在连表的基础上,额外 "筛掉不需要的数据"(比如只看语文成绩、分数≥80)
【一】复合查询实战
我们采用下面这样的表来做练习:可以直接CV进数据库
表结构:
cpp
CREATE TABLE EMP (
deptno INT,
ename VARCHAR(20),
job VARCHAR(20),
sal INT,
comm INT NULL
);表数据:
cpp
INSERT INTO EMP (deptno, ename, job, sal, comm) VALUES
(10, 'King', 'MANAGER', 5000, 1000),
(20, 'Smith', 'CLERK', 800, NULL),
(20, 'Jones', 'MANAGER', 2975, 500),
(30, 'Blake', 'MANAGER', 2850, 800),
(30, 'Clark', 'CLERK', 2450, NULL),
(10, 'Scott', 'ANALYST', 3000, 600),
(20, 'Adams', 'CLERK', 1100, 200),
(30, 'Turner', 'SALESMAN', 1500, 300),
(10, 'Miller', 'CLERK', 1300, NULL),
(20, 'Ford', 'ANALYST', 3000, 700);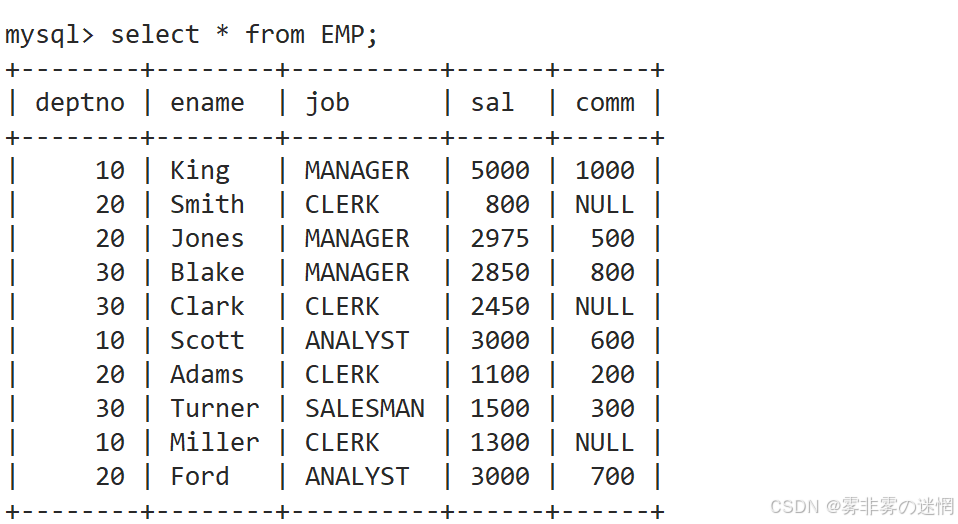
(1)实例1
查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J
先找到工资、岗位字段:
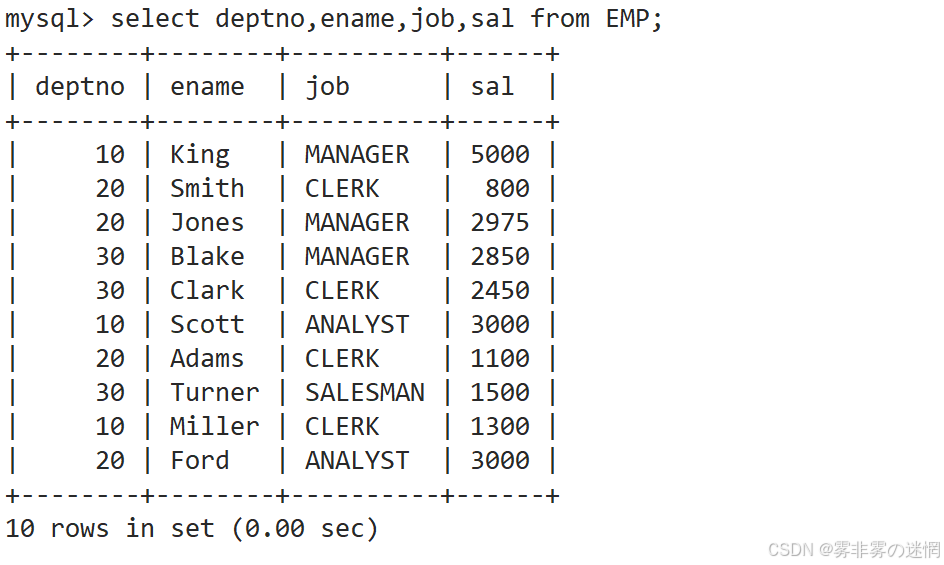
现在找高于500的、或者岗位为指定的信息:

再并列条件:姓名首字母为大写的J,即 % 模糊匹配

(2)实例2
按照部门号升序而雇员的工资降序排序
先找:部门号、工资、雇员名称字段
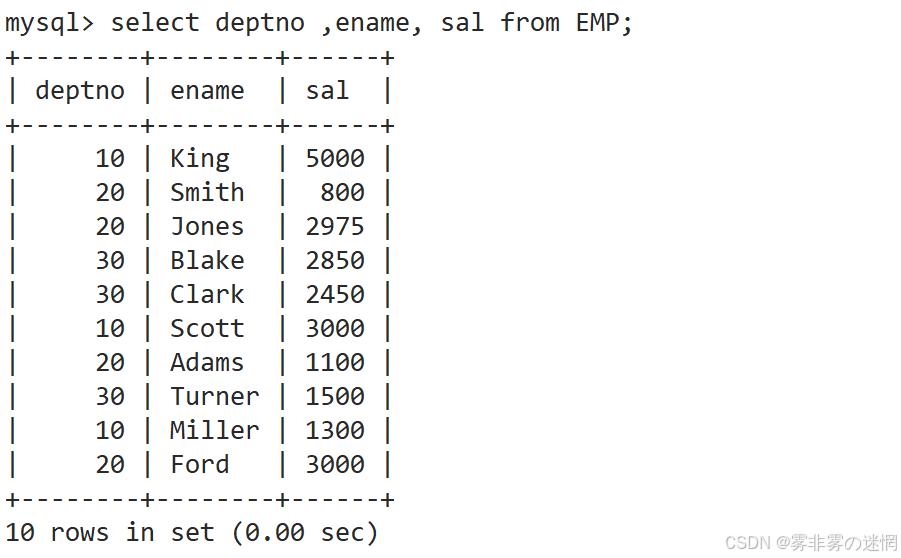
再进行指定内容的排序:部门号升序、工资降序
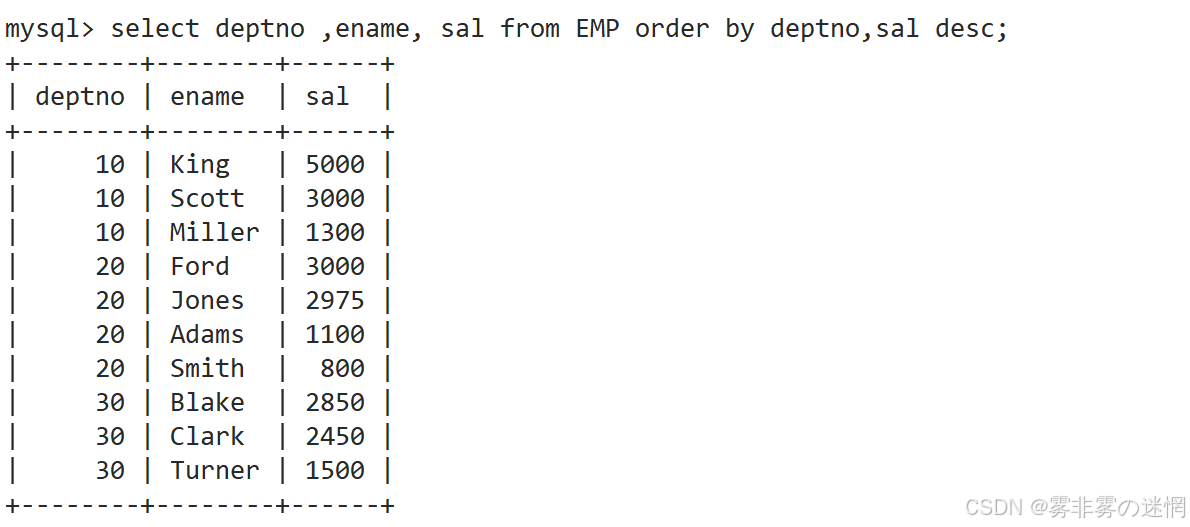
(3)实例3
使用年薪进行降序排序
先找到年薪字段:这里就是月薪*12
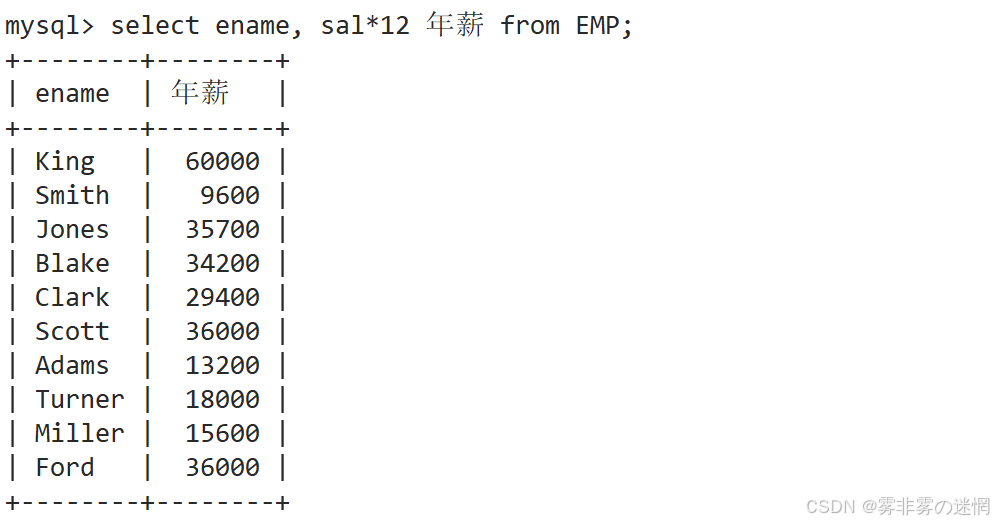
完成降序:

(4)实例4
显示工资最高的员工的名字和工作岗位
先找员工、工资、岗位字段:
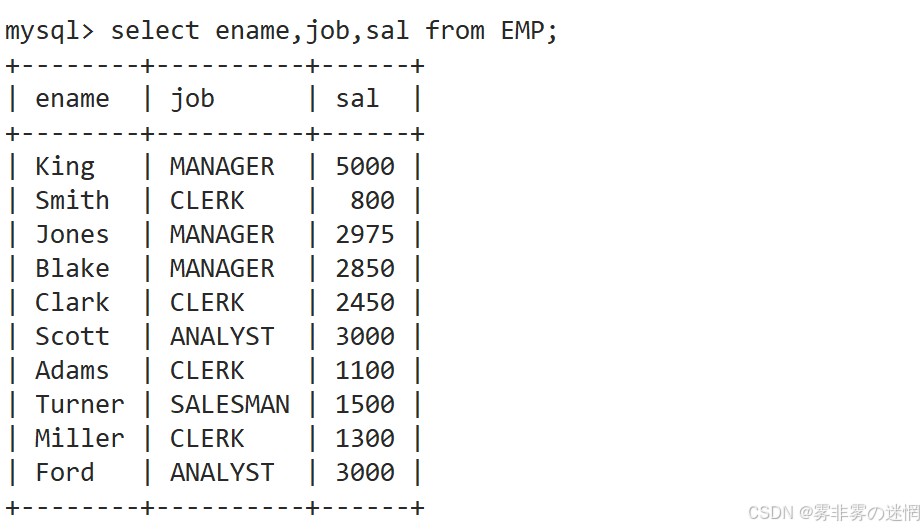
找工资最高的员工:
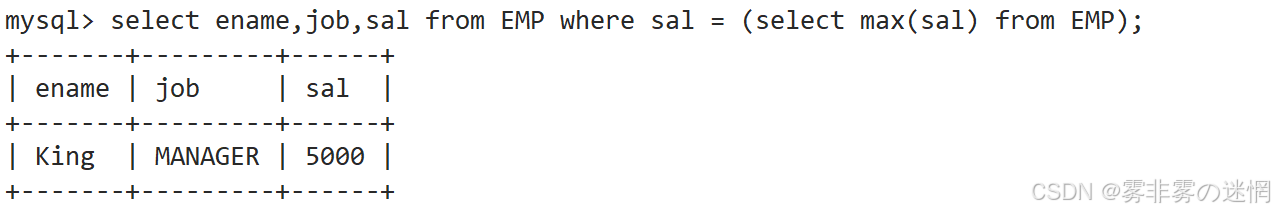
(5)实例5
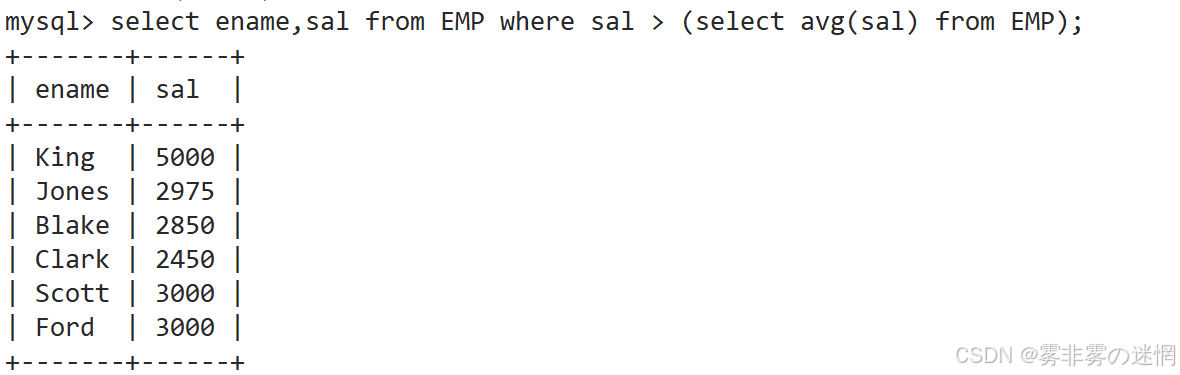
显示工资高于平均工资的员工信息
先找:工资字段(这里就不演示了!),然后计算平均工资,中间用 > 进行判断:
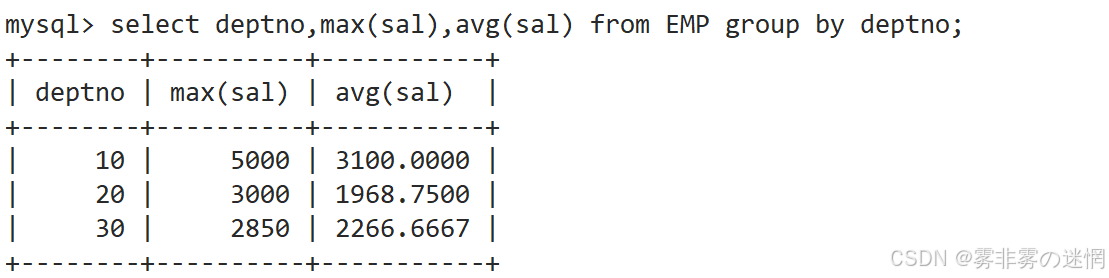
(6)实例6
显示每个部门的平均工资和最高工资
先找工资字段(不演示),然后 avg 计算平均工资,和 max 计算最高工资:
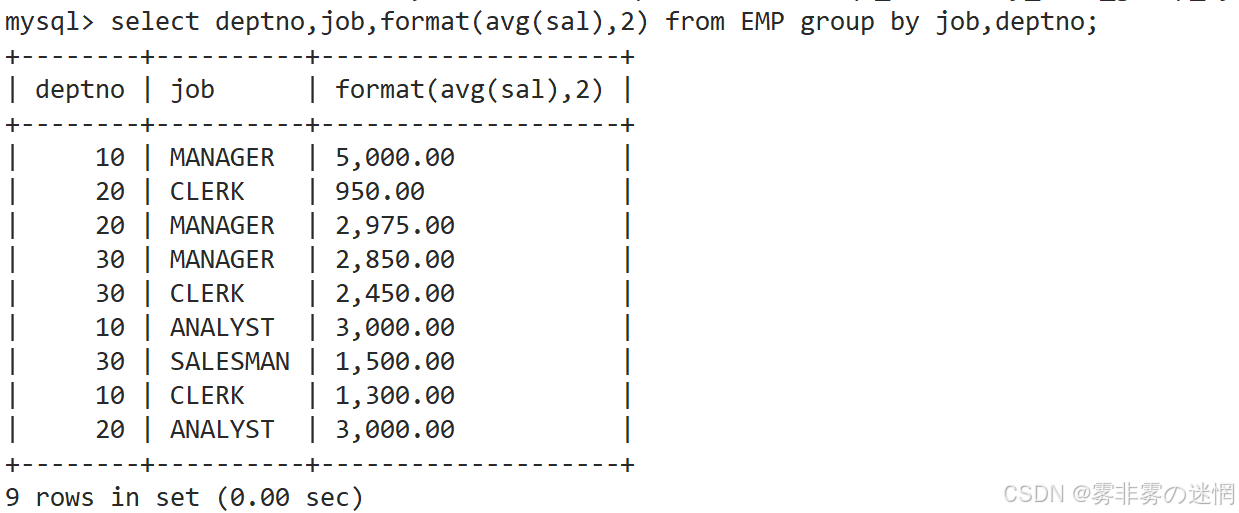
(7)实例7
显示每种岗位的雇员总数,平均工资,
需要用 group by按对应字段分组(select中的非聚合字段必须全部出现在 group by中)
先拿到每种岗位的雇员总数:
【二】多表查询
实际开发中往往数据来自不同的表,所以需要多表查询
现在存在如下的两张表:

from 后面可以跟多张表,它们的数据会进行逐个组合,称为笛卡儿积,例如:
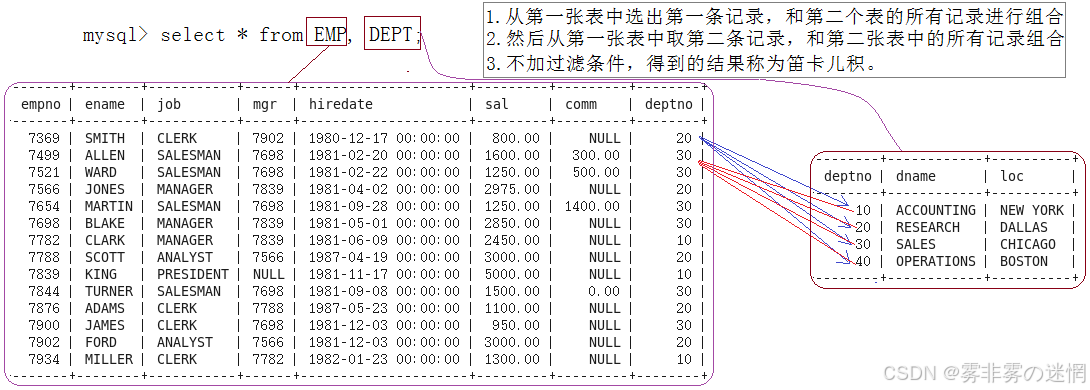
笛卡尔积之后两张表变为一张表,逻辑不变,当做一张表来进行查询
现在我们对两张表进行笛卡尔积:可以看到数据非常的乱,现在进行筛选
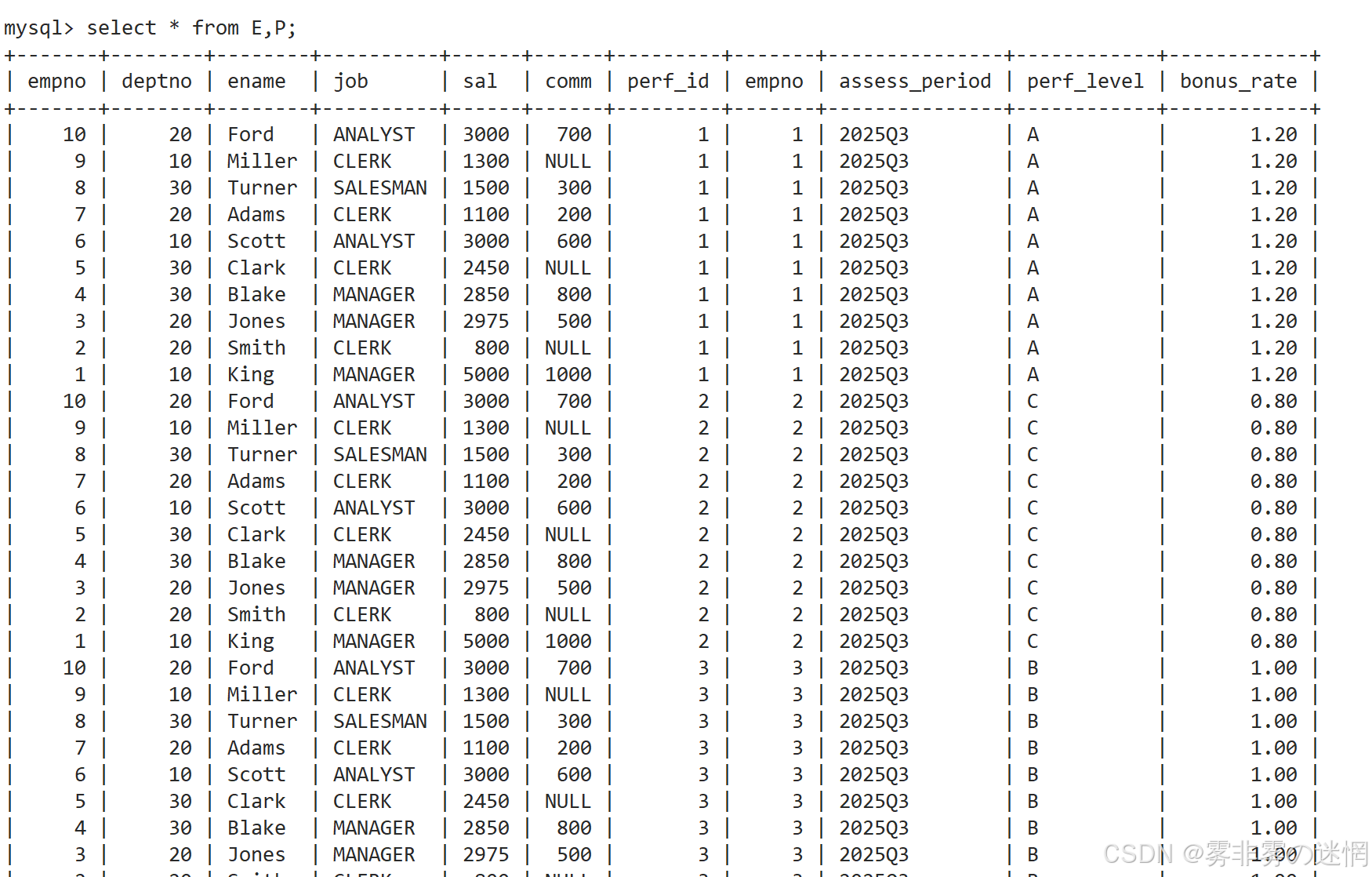
如果 E 表的 empno 在 P 中也有,我们就输出出来:
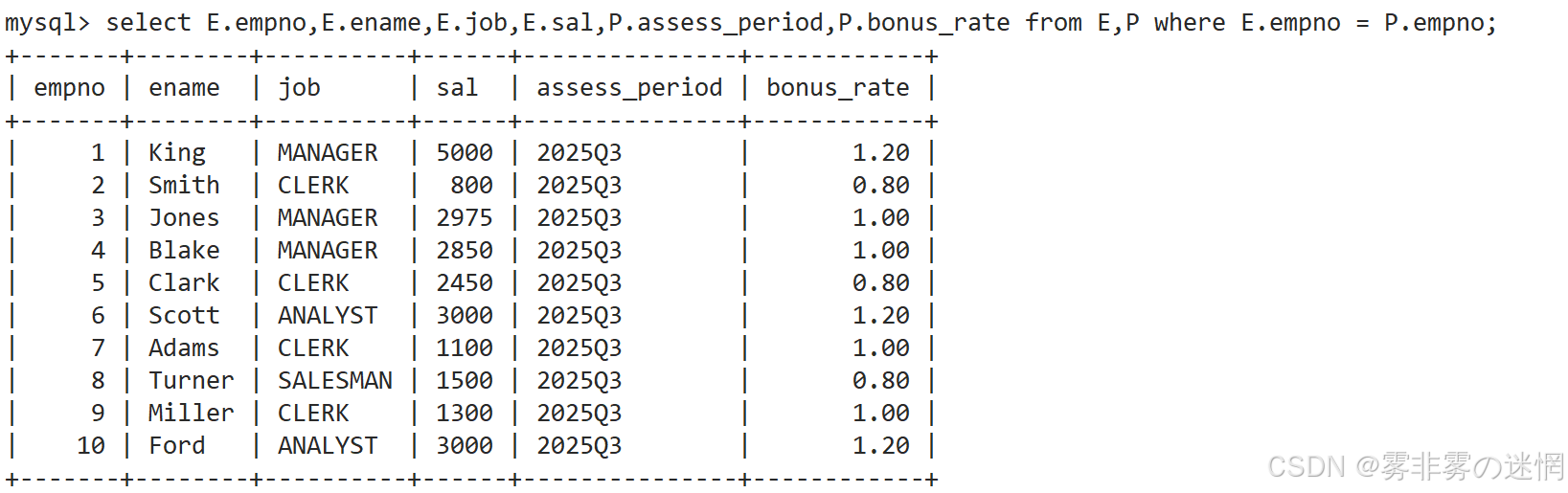
需要注意:如果两张表有同样的字段,需要指定查询,否则 select 无法查找
比如:查找奖金系数大于1的员工(distinct 可以去重)
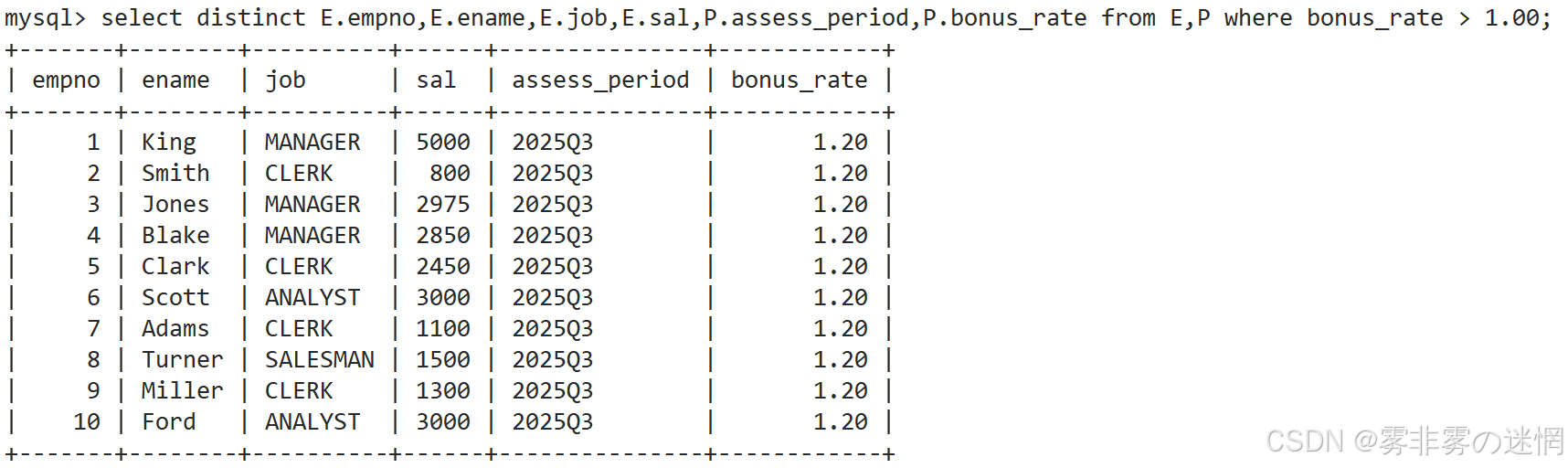
现在我们准备如下两张表进行练习:
-- 创建学生表 CREATE TABLE student ( id INT PRIMARY KEY, name VARCHAR(20) NOT NULL ); -- 创建成绩表(科目限定3类,方便筛选) CREATE TABLE score ( id INT PRIMARY KEY, stu_id INT, subject VARCHAR(10) CHECK (subject IN ('语文', '数学', '英语')), score INT ); -- 插入学生数据(4名学生,覆盖不同成绩情况) INSERT INTO student VALUES (1, '张三'), -- 语文+数学(2科有成绩) (2, '李四'), -- 语文(有分)+英语(缺考,分数null) (3, '王五'), -- 数学(有分)+语文/英语(无成绩) (4, '赵六'); -- 三科均无成绩 -- 插入成绩数据(含缺考、无对应学生的成绩) INSERT INTO score VALUES (1, 1, '语文', 88), (2, 1, '数学', 95), (3, 2, '语文', 76), (4, 2, '英语', null), -- 缺考,分数null (5, 3, '数学', 69), (6, 5, '英语', 82); -- 无对应学生的成绩
(1)表的内连接
含义:内连接实际上就是利用where子句,对两种表形成的笛卡儿积进行筛选
(2)表的外连接
含义:表的外连接分为左外连接和内外连接
(1)左外连接
含义:左侧的表完全显示我们就说是左外连接
语法:
select 字段名 from 表名1 left join 表名2 on 连接条件(2)右外连接
含义:左侧的表完全显示我们就说是左外连接
语法:
select 字段 from 表名1 right join 表名2 on 连接条件【三】索引
我们直接上原理讲解,拒绝废话!索引3是什么需要一步步循序渐进:
索引的作用:
提高数据的检索速度,数据插入、更新、删除的速度(即非IO的效率)
(1)MySQL与磁盘
首先磁盘的工作方式我们是知道的:每个盘面被分为多个扇区,每个磁面的摆臂+磁头告诉摆动来寻找目标位置,读取时以"块"作为单位读取,"块"由许多个扇区组成,如下图:
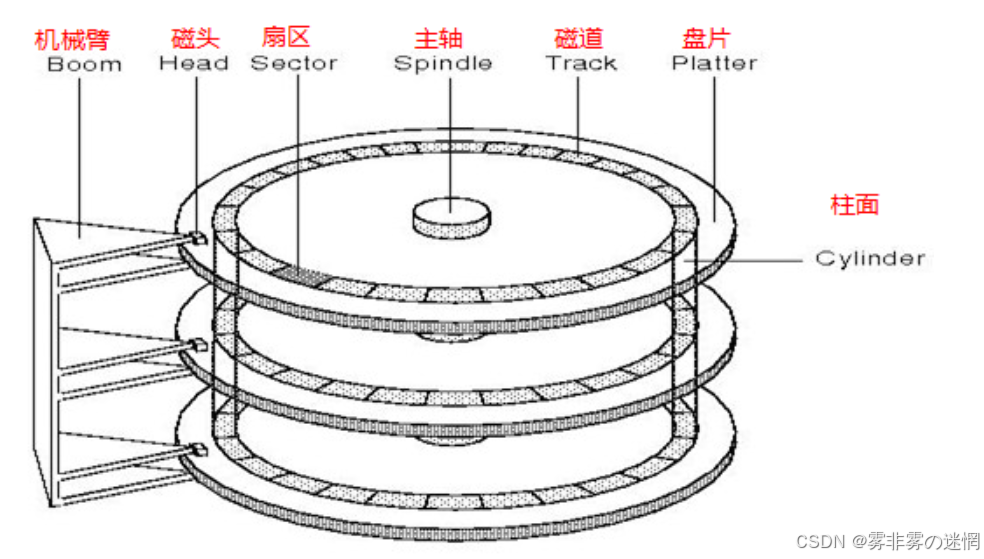
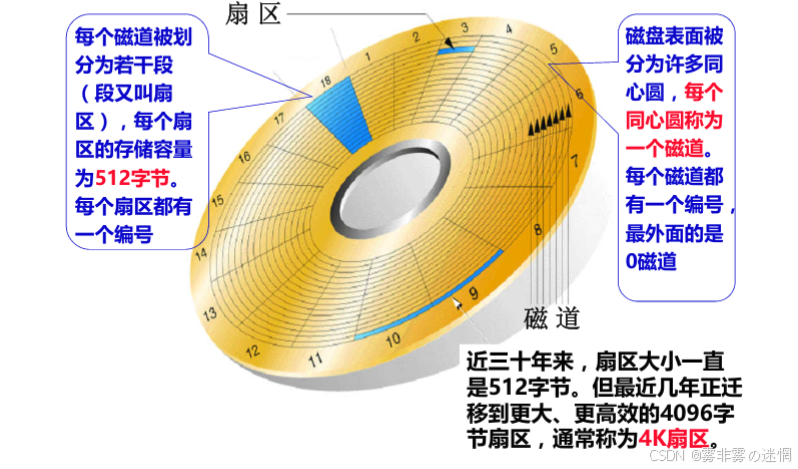
假设现在有8亿条数据,一定会在磁盘占据许多个扇区,寻找一个文件即找到对应的扇区
随机访问:本次IO所给出的扇区地址和上次IO给出扇区地址不连续,这样的话磁头在两次IO操作 之间需要作比较大的移动动作才能重新开始读/写数据
连续访问:如果当次IO给出的扇区地址与上次IO结束的扇区地址是连续的,那磁头就能很快的开 始这次 IO操作,这样的多个IO操作称为连续访问
MySQL为了提高数据的IO效率,和磁盘进行数据交互的基本单位是 16KB(4*4)
该数据单元,被称为 page(解决多次与磁盘IO问题)
(2)三条共识
(1)MySQL中的数据文件以page为单位保存在磁盘中的
(2)为了更好的进行上面的操作, MySQL 服务器在内存中运行的时候,在服务器内部,就申请 了被称为 Buffer Pool 的的大内存空间,来进行各种缓存
其实就是很大的内存空间,来和磁盘数据进行IO交互
(3)数据库文件肯定不止有一个page大小,那么管理多个page就需要组织起来:
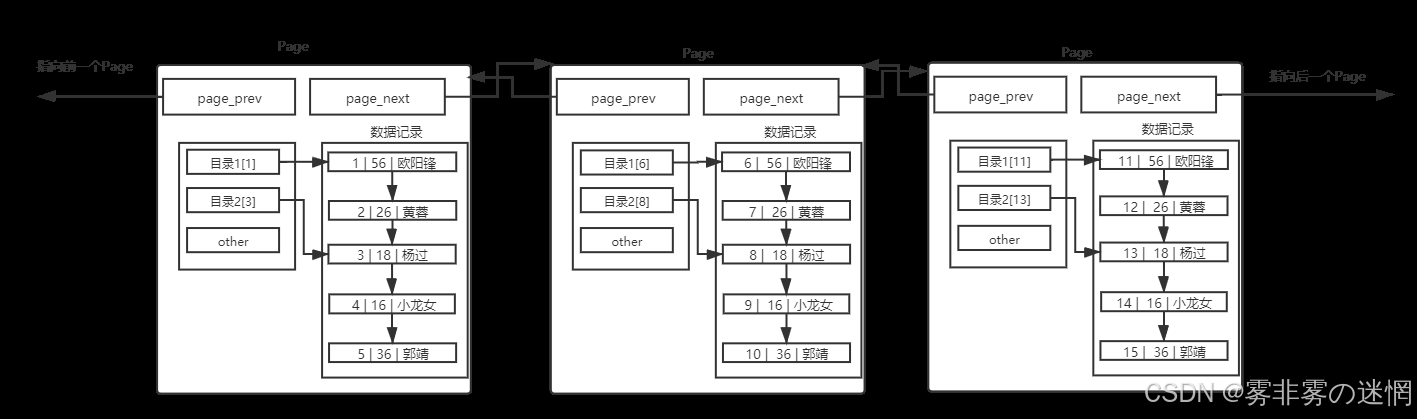
Buffer Pool 空间大就可以随便放page吗?如何定位某个数据在哪个page?线性查找?
(3)页目录 与 B+树
页目录即根据目标唯一的主键进行区域划分:快速定位某个章节、页
例如:书的目录
页目录的查找效率提升:
如果找id为5的数据,从原来的线性查找5次,变成查找3次左右,数据越多,指数降低的越明显
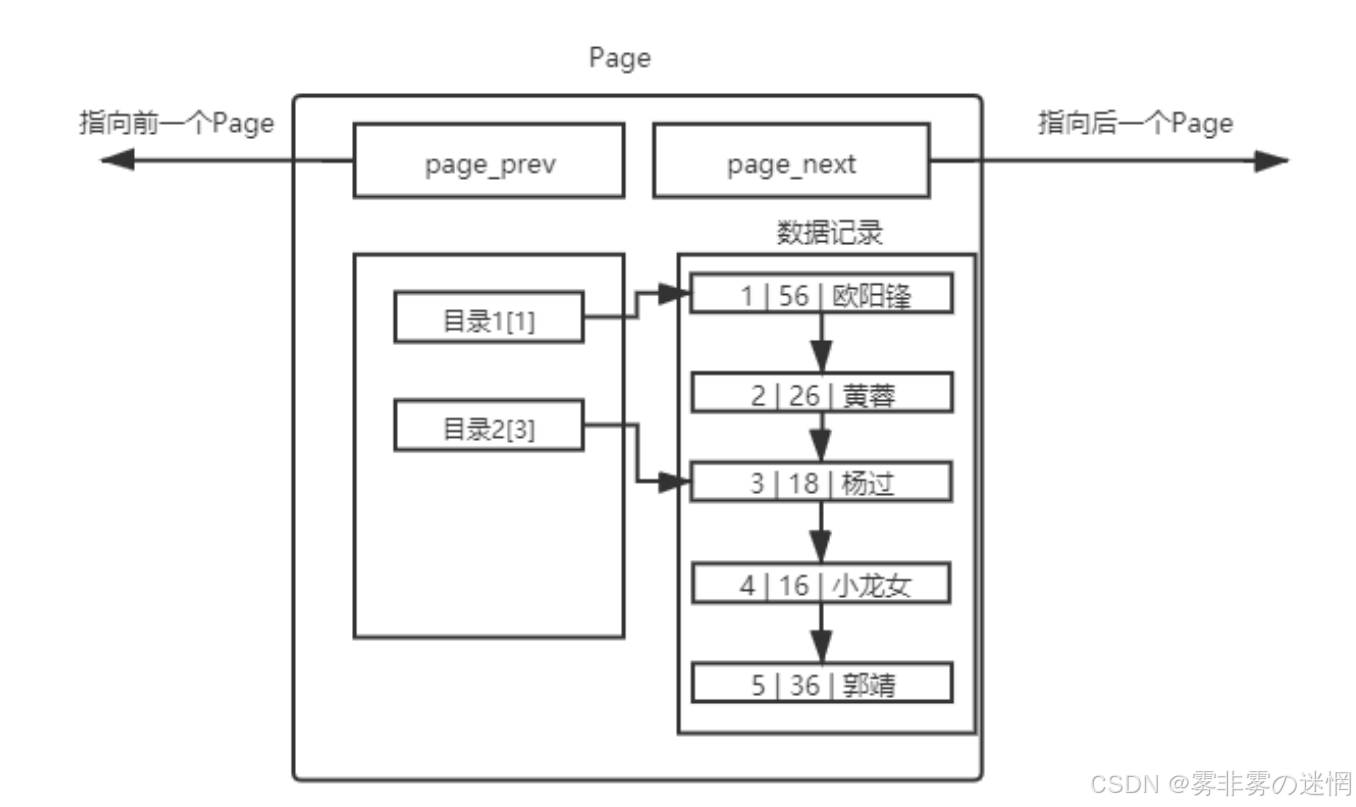
那么如果数据足够多?所建立的目录也越多,趋近线性查找?
解决方法:我们也可以给目录再建立目录,例如:
目录页的本质也是页,普通页中存的数据是用户数据,而目录页中存的数据是普通页的地址
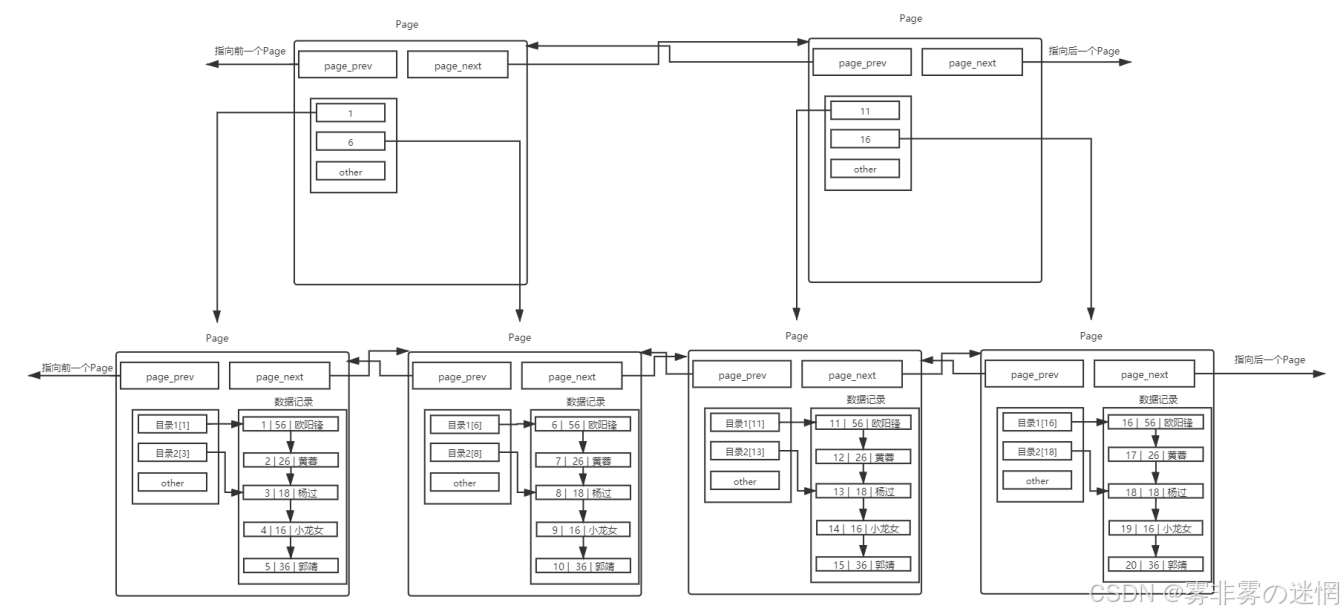
为何不是红黑树、哈希结构?红黑属于二叉树,比B+树更高,哈希也只能从上往下查找
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html(可点击前往数据结构演示)
为什么不是B树?而是B+树?B+树的底部是相连的,意味临近数据可以直接左右查找
B树:
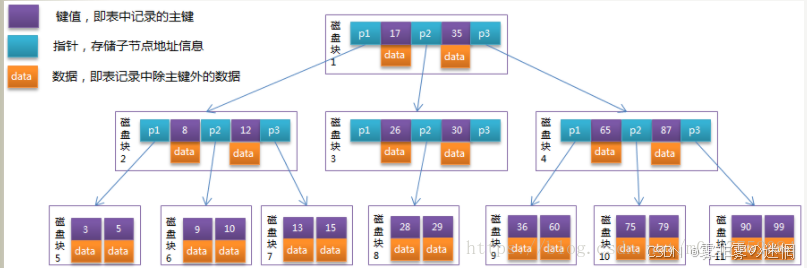
B+树:
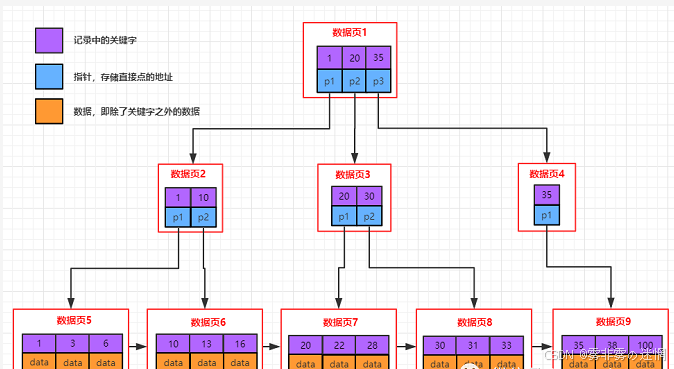
**索引定义:**数据库实现快速查询而采用的数据结构(B+树)
(4)非/聚簇索引
聚簇索引:将用户数据与索引数据放在一起索引方案,例如:
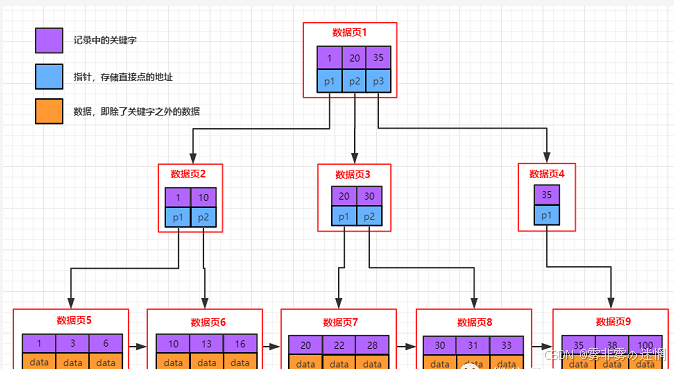
非聚簇索引:将用户数据与索引数据不放在一起索引方案,例如:
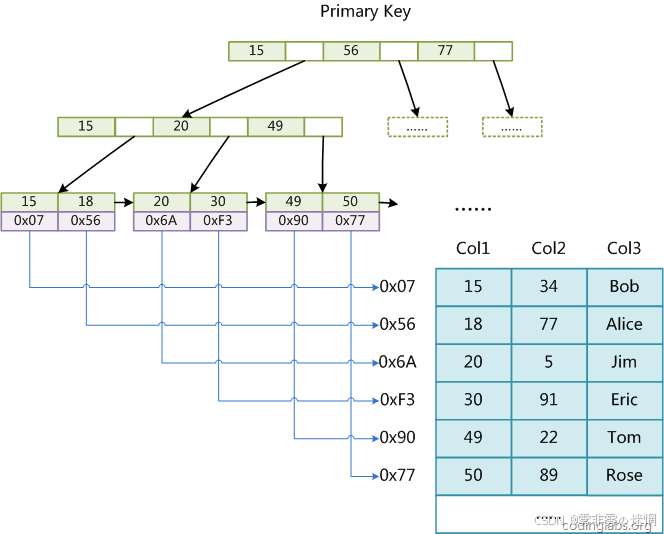
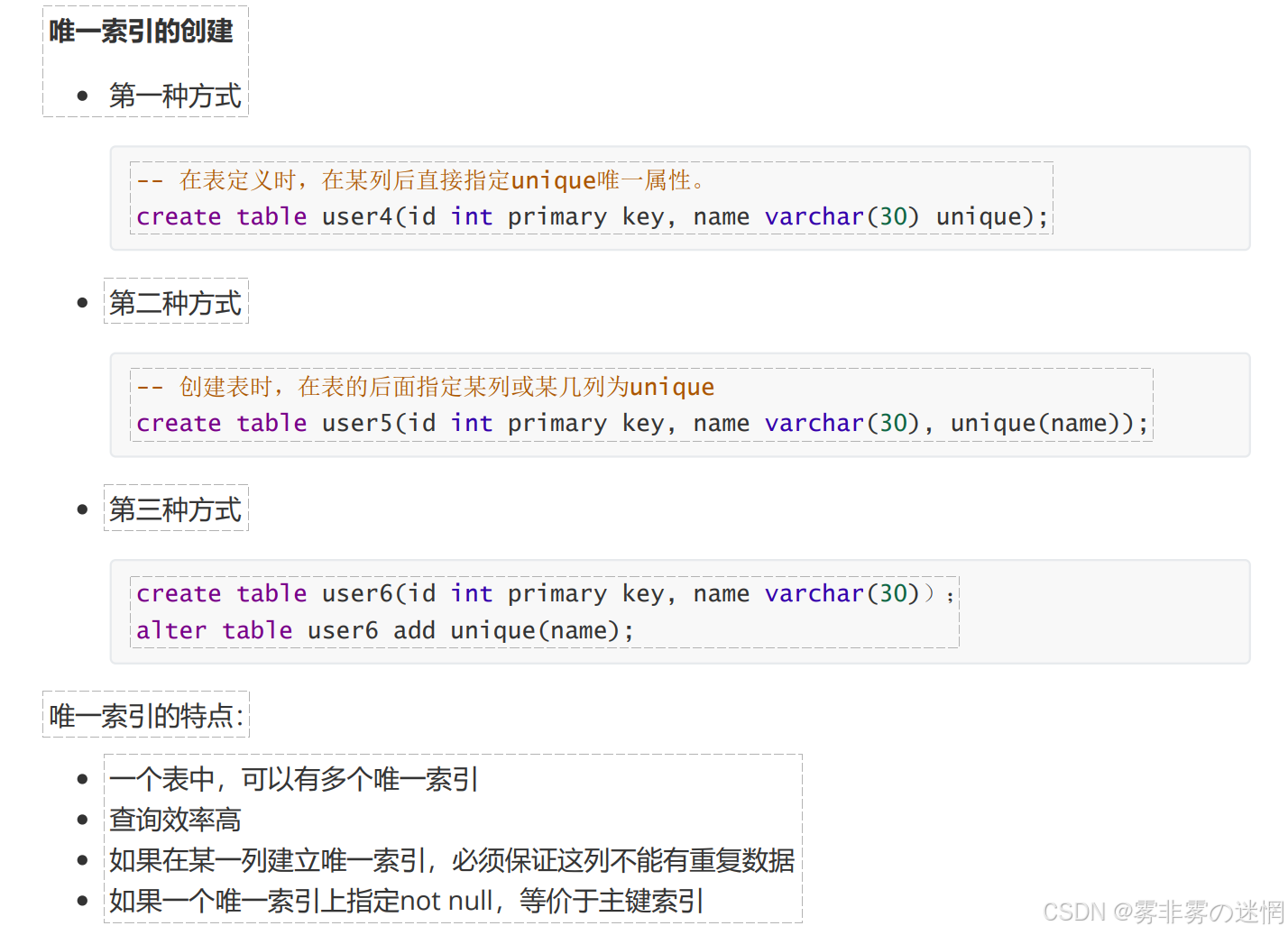
(5)创建索引
主键索引:
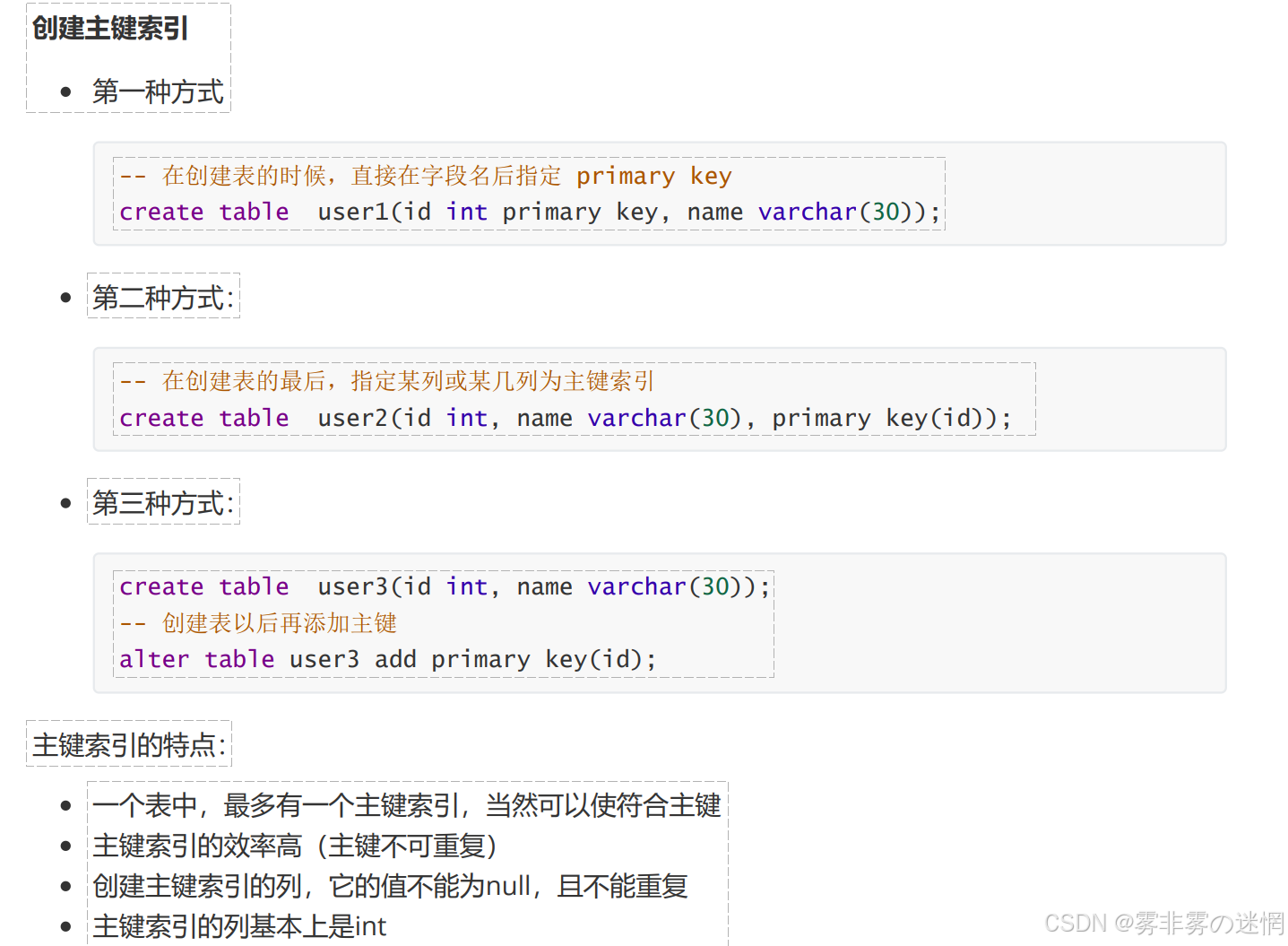
唯一键索引:
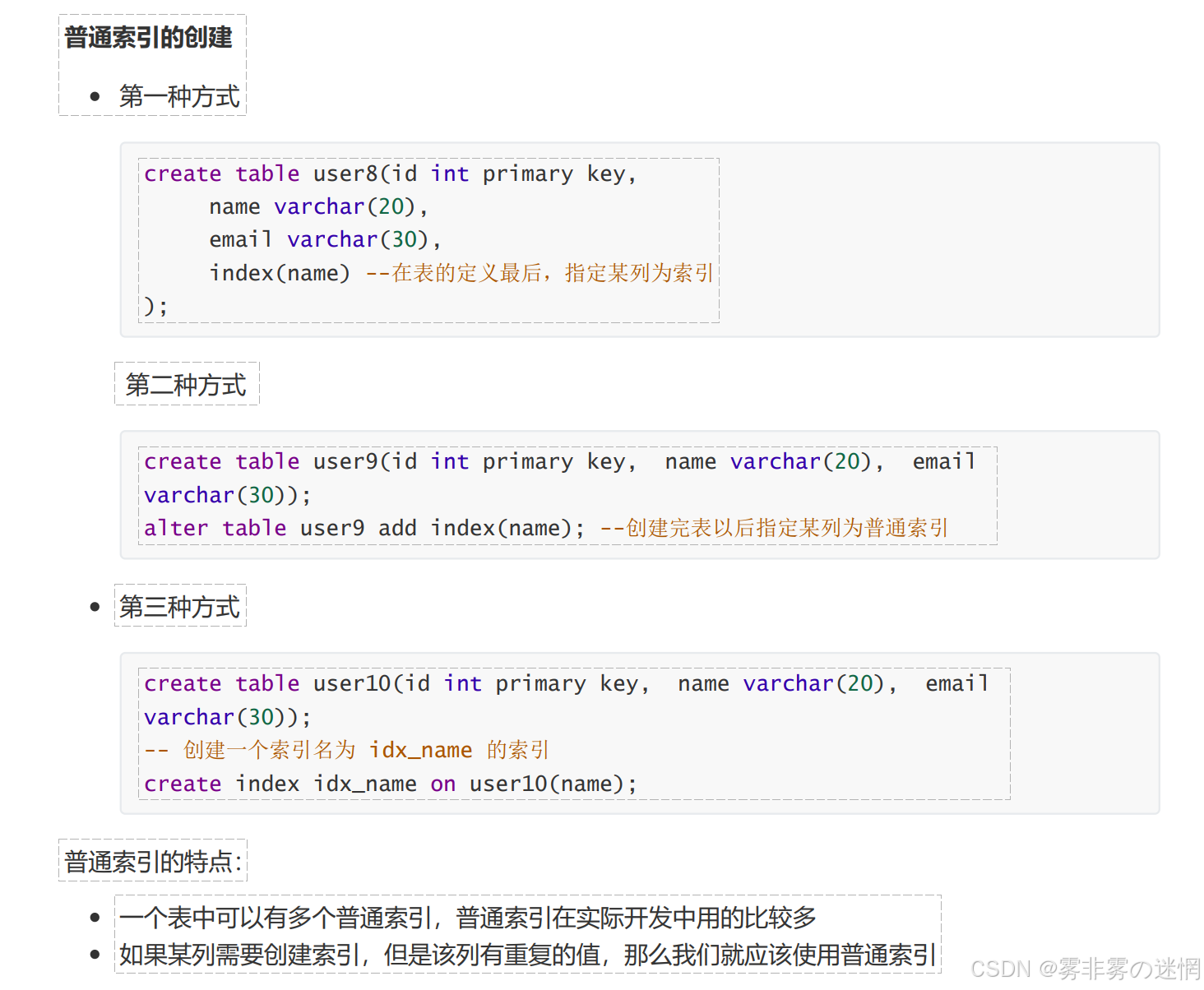
普通索引创建:
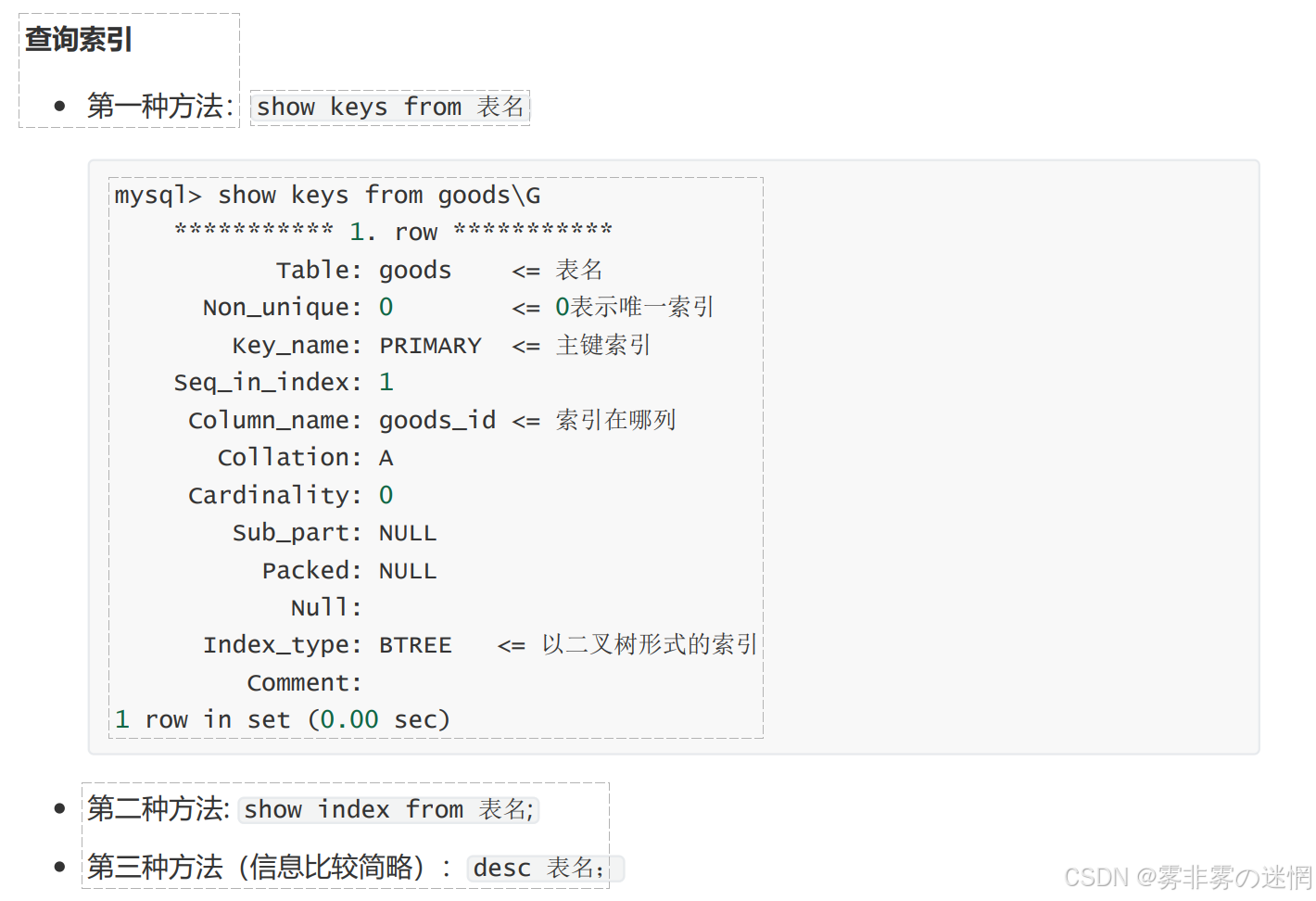
(6)查询索引
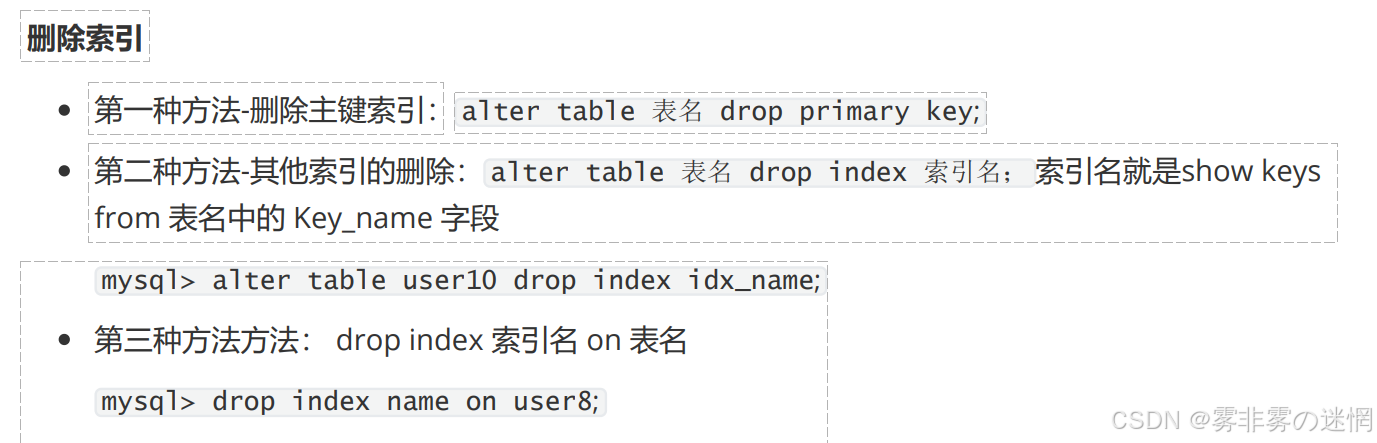
(7)删除索引
(8)索引的创建原则
