前言:
随着 5G 和物联网技术的普及,车联网 (Internet of Vehicles, IoV) 正成为数据爆发的新战场。与传统的静态传感器不同,车辆是移动的计算节点,它们每时每刻都在产生海量的时间序列数据:从 GPS 经纬度到发动机转速,从剩余油量到刹车踏板状态。
对于一家拥有数百辆货车的物流公司而言,这些数据就是金矿。通过实时监控,可以有效降低油耗、杜绝违规驾驶、优化配送路线。然而,传统的关系型数据库在面对车辆高频上报(例如每秒 10 次)的轨迹数据时,往往面临写入瓶颈;而单纯的时序数据库又难以处理复杂的车辆档案关联查询。
KWDB (KaiwuDB) 的"多模"特性恰好解决了这一痛点。今天,我们将实战构建一个物流车队实时监控平台,挑战如何在一个数据库内同时搞定"车辆档案管理"与"海量轨迹分析"。
场景设定 :我们要为一个拥有 200 辆货车的物流车队构建监控系统。
核心挑战:
- 高频写入:车辆每 10 秒(甚至更频)上报一次 GPS 和车辆状态,数据量随车队规模线性增长。
- 实时报警:需要毫秒级延迟检测超速(>100km/h)和疲劳驾驶行为,保障行车安全。
- 轨迹时空查询:不仅要查"时间",还要查"空间",需要快速回溯某辆车在特定时间段的完整轨迹。

文章目录
-
- [1. 架构设计](#1. 架构设计)
-
- [1.1 数据流向](#1.1 数据流向)
- [2. 建模实战:人车合一](#2. 建模实战:人车合一)
-
- [2.1 初始化环境](#2.1 初始化环境)
- [2.2 车辆档案表 (Relational Table)](#2.2 车辆档案表 (Relational Table))
- [2.3 车辆遥测表 (Time-Series Table)](#2.3 车辆遥测表 (Time-Series Table))
- [3. 数据模拟:车轮滚滚](#3. 数据模拟:车轮滚滚)
- [4. 业务场景实战](#4. 业务场景实战)
- [5. 避坑指南](#5. 避坑指南)
- 总结
1. 架构设计
1.1 数据流向
4G/5G
Kafka
SQL Query
SQL Analytics
车载终端 T-Box
IoT 网关
KWDB 集群
调度中心大屏
车队管理报表
2. 建模实战:人车合一
在车联网系统中,数据通常分为两类:
- 静态数据:车辆基础信息(车牌、车型、司机),变动频率低,适合关系型存储。
- 动态数据:车辆运行轨迹(速度、位置、油耗),写入频率极高,适合时序存储。
KWDB 的强大之处在于,它允许我们在同一个数据库中同时创建这两种表,并进行无缝关联。
2.1 初始化环境
bash
# 连接数据库
sudo /usr/local/kaiwudb/bin/kwbase sql \
--certs-dir=/etc/kaiwudb/certs \
--host=127.0.0.1:26257
sql
CREATE DATABASE IF NOT EXISTS smart_logistics;
USE smart_logistics;2.2 车辆档案表 (Relational Table)
sql
CREATE TABLE vehicles (
vin VARCHAR(20) PRIMARY KEY, -- 车架号 (唯一标识)
plate_no VARCHAR(10), -- 车牌号
driver_name VARCHAR(50), -- 司机姓名
vehicle_type VARCHAR(20), -- 车型 (Heavy/Light)
fleet_group VARCHAR(20) -- 所属车队
);
-- 模拟插入几辆车
INSERT INTO vehicles (vin, plate_no, driver_name, vehicle_type, fleet_group)
VALUES
('VIN001', '京A-88888', '张三', 'Heavy-Truck', 'Fleet-Beijing'),
('VIN002', '沪B-66666', '李四', 'Light-Van', 'Fleet-Shanghai'),
('VIN003', '粤C-12345', '王五', 'Heavy-Truck', 'Fleet-Guangzhou');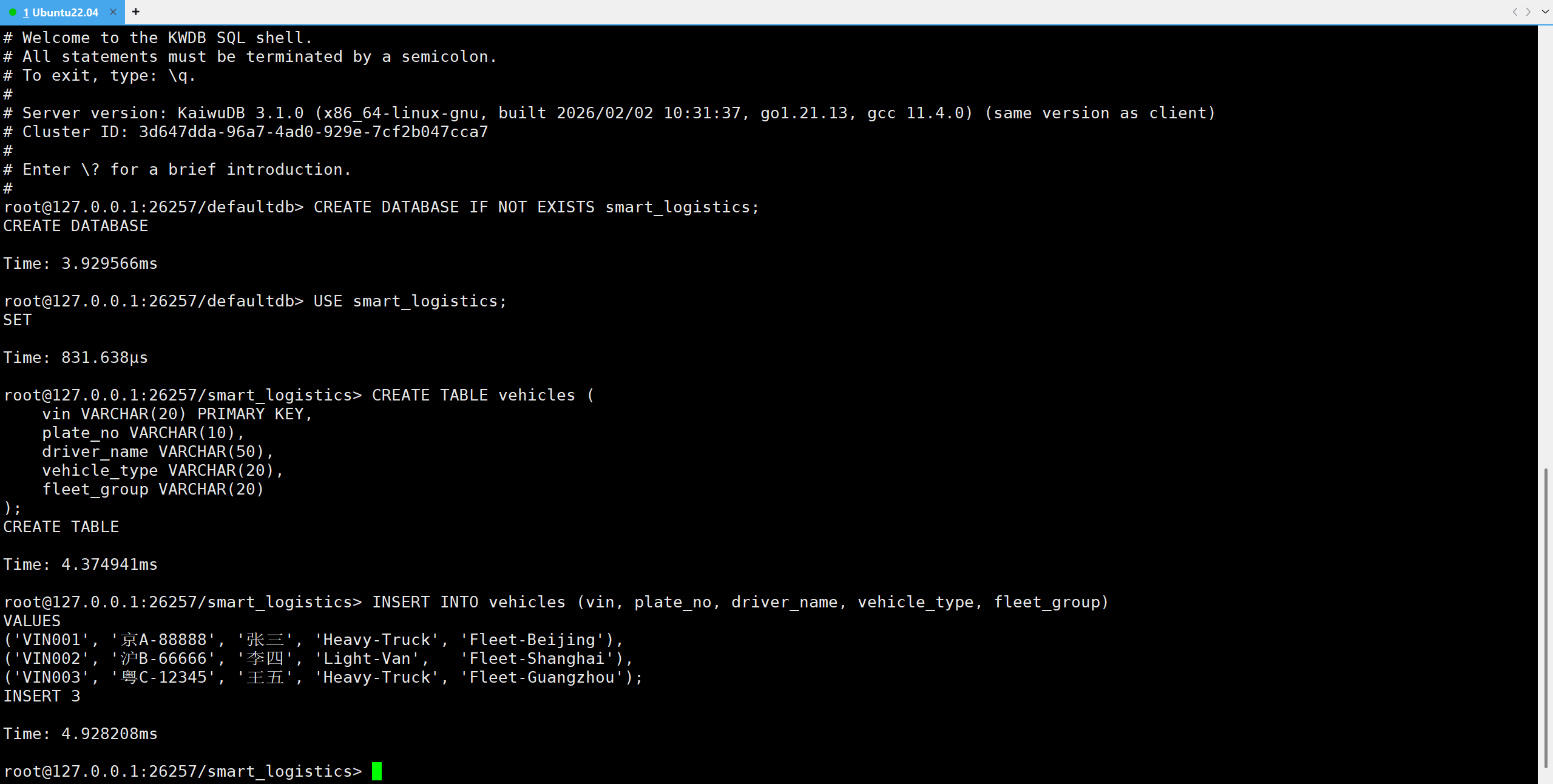
2.3 车辆遥测表 (Time-Series Table)
这是系统的核心表,存储高频轨迹数据。
设计思考:
- Tag 选择 :我们将
vin(车架号) 作为 Tag。在时序数据库中,Tag 是索引的主要依据。所有的查询(查轨迹、查报警)几乎都是基于"某辆车"发起的,因此vin是最合适的 Tag。 - 字段选择 :除了经纬度,我们还存储了
speed、fuel_level和engine_rpm,这些多维指标可以支持更丰富的上层应用分析。
sql
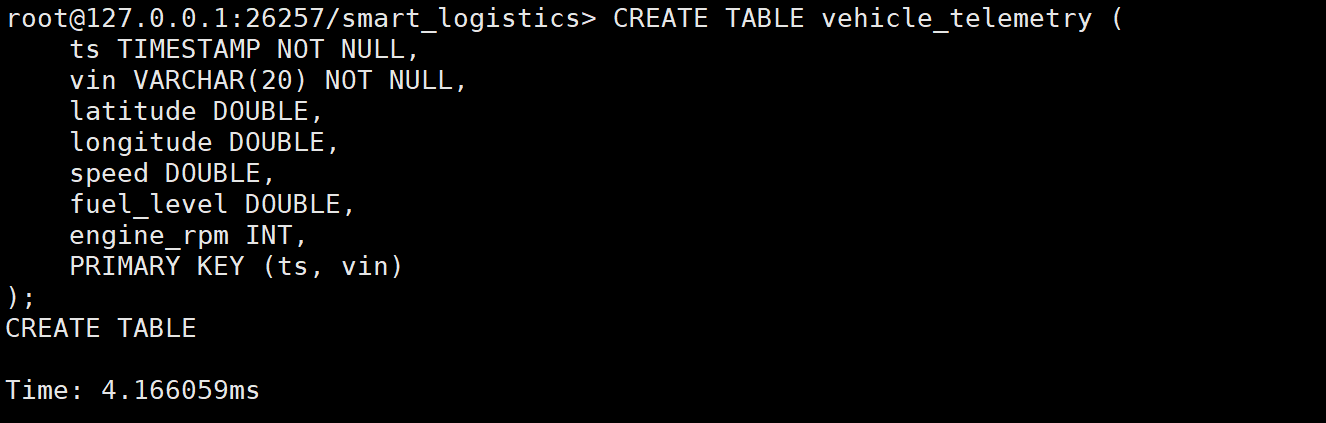
CREATE TABLE vehicle_telemetry (
ts TIMESTAMP NOT NULL, -- 时间戳
vin VARCHAR(20) NOT NULL, -- 车架号 (Tag)
latitude DOUBLE, -- 纬度
longitude DOUBLE, -- 经度
speed DOUBLE, -- 速度 (km/h)
fuel_level DOUBLE, -- 剩余油量 (%)
engine_rpm INT, -- 发动机转速
PRIMARY KEY (ts, vin)
);
3. 数据模拟:车轮滚滚
真实的车联网数据往往包含大量噪声(如 GPS 漂移)和复杂的驾驶行为(如急加速、急减速)。为了让实战更贴近真实,我们编写 Python 脚本 gen_iov_data.py,模拟车队在高速公路上行驶的数据。
脚本逻辑亮点:
- 轨迹模拟:通过经纬度的微小增量模拟车辆移动。
- 行为模拟:随机生成"偶尔超速"的数据,用于测试报警功能。
- 油耗模拟:随着行驶里程增加,油耗呈线性递减。
python
import random
from datetime import datetime, timedelta
# 配置
FILENAME = "iov_data.sql"
VINS = ['VIN001', 'VIN002', 'VIN003']
START_TIME = datetime.now() - timedelta(hours=2) # 过去2小时
INTERVAL_SECONDS = 10 # 每10秒一个点
TOTAL_POINTS = int(2 * 3600 / INTERVAL_SECONDS)
print(f"正在生成 {len(VINS)} 辆车,过去 2 小时的轨迹数据...")
with open(FILENAME, "w") as f:
f.write("USE smart_logistics;\n")
f.write("INSERT INTO vehicle_telemetry (ts, vin, latitude, longitude, speed, fuel_level, engine_rpm) VALUES\n")
records = []
for vin in VINS:
# 初始位置 (简单模拟)
lat = 39.90
lon = 116.40
fuel = 100.0
for i in range(TOTAL_POINTS):
ts = (START_TIME + timedelta(seconds=i*INTERVAL_SECONDS)).strftime('%Y-%m-%d %H:%M:%S')
# 模拟行驶:经纬度微调
lat += random.uniform(-0.001, 0.001)
lon += random.uniform(-0.001, 0.001)
# 模拟速度:大部分时间正常,偶尔超速
if random.random() < 0.05:
speed = random.uniform(105, 120) # 超速
else:
speed = random.uniform(60, 90) # 正常
# 油耗递减
fuel -= 0.01
if fuel < 0: fuel = 0
rpm = int(speed * 30 + random.uniform(-100, 100))
records.append(f"('{ts}', '{vin}', {round(lat, 6)}, {round(lon, 6)}, {round(speed, 1)}, {round(fuel, 1)}, {rpm})")
# 批量写入逻辑
batch_size = 1000
total = len(records)
for i, record in enumerate(records):
if (i + 1) % batch_size == 0 or i == total - 1:
f.write(f"{record};\n")
if i < total - 1:
f.write("INSERT INTO vehicle_telemetry (ts, vin, latitude, longitude, speed, fuel_level, engine_rpm) VALUES\n")
else:
f.write(f"{record},\n")
print(f"生成完毕!总记录数: {total}")
print(f"请运行: time sudo /usr/local/kaiwudb/bin/kwbase sql --certs-dir=/etc/kaiwudb/certs --host=127.0.0.1:26257 < {FILENAME}")执行导入:
bash
python3 gen_iov_data.py
time sudo /usr/local/kaiwudb/bin/kwbase sql --certs-dir=/etc/kaiwudb/certs --host=127.0.0.1:26257 < iov_data.sql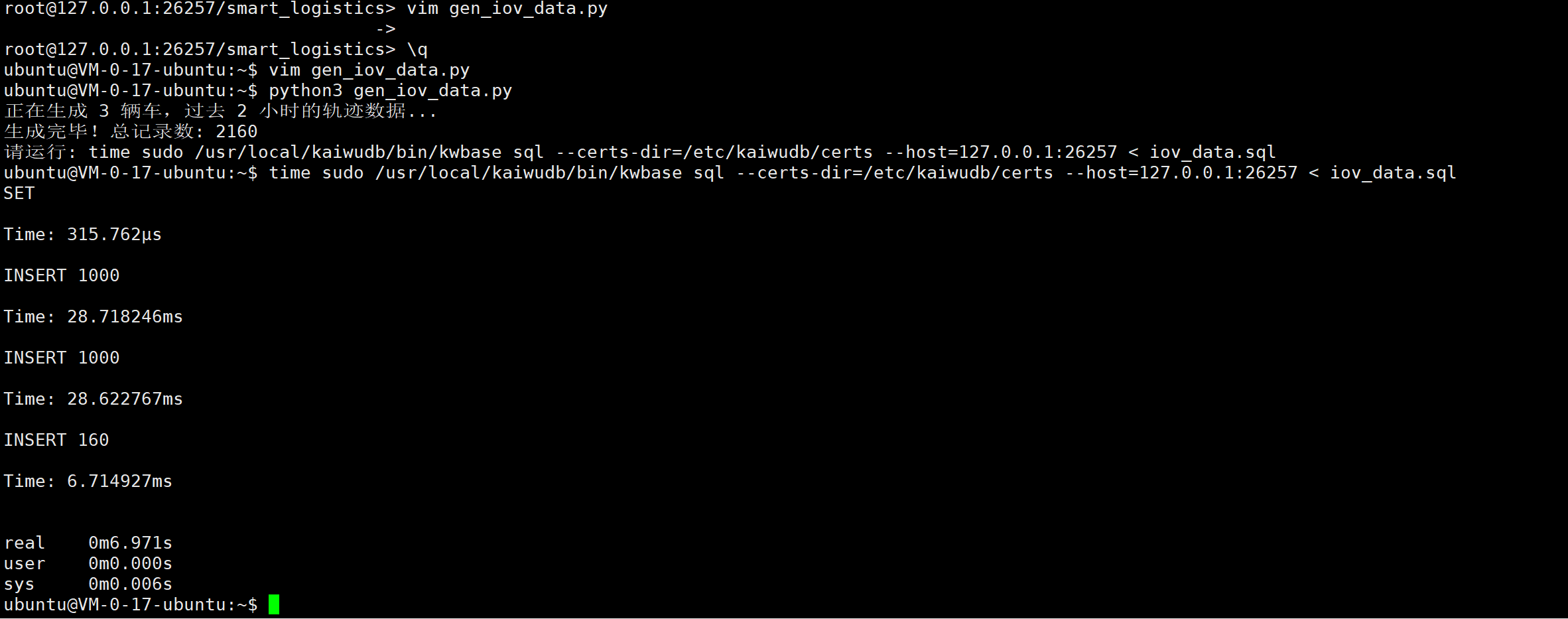
执行结果分析 :
使用 Batch Insert 方式写入数据的效率非常惊人。
- 极速写入 :每一批次插入 1000 条 数据,仅耗时约 28ms (Time: 28.718ms)。这意味着单线程理论写入速度轻松达到 3.5万条/秒。
- 稳定性 :相比于
COPY命令对客户端版本的依赖,这种标准 SQL 的批量插入方式在任何环境下都能稳定运行,且性能完全满足车联网场景的高频上报需求。
4. 业务场景实战
有了数据,系统就有了灵魂。接下来,我们将模拟调度员和车队经理的视角,解决三个最迫切的业务需求。
注意 :执行前请确保
USE smart_logistics;。
场景一:超速报警 (Speeding Alert)
业务痛点:重型卡车在高速上超速是重大事故的主要原因。调度中心需要一个"实时风控雷达",一旦发现车速超过 100km/h,立即锁定车辆位置和司机信息,下发语音警告。
需求:找出过去 2 小时内,车速超过 100km/h 的所有违规记录,并关联司机信息。
sql
USE smart_logistics;
SELECT
t.ts,
v.plate_no,
v.driver_name,
t.speed,
t.latitude,
t.longitude
FROM vehicle_telemetry t
JOIN vehicles v ON t.vin = v.vin
WHERE t.speed > 100.0
ORDER BY t.ts DESC
LIMIT 10;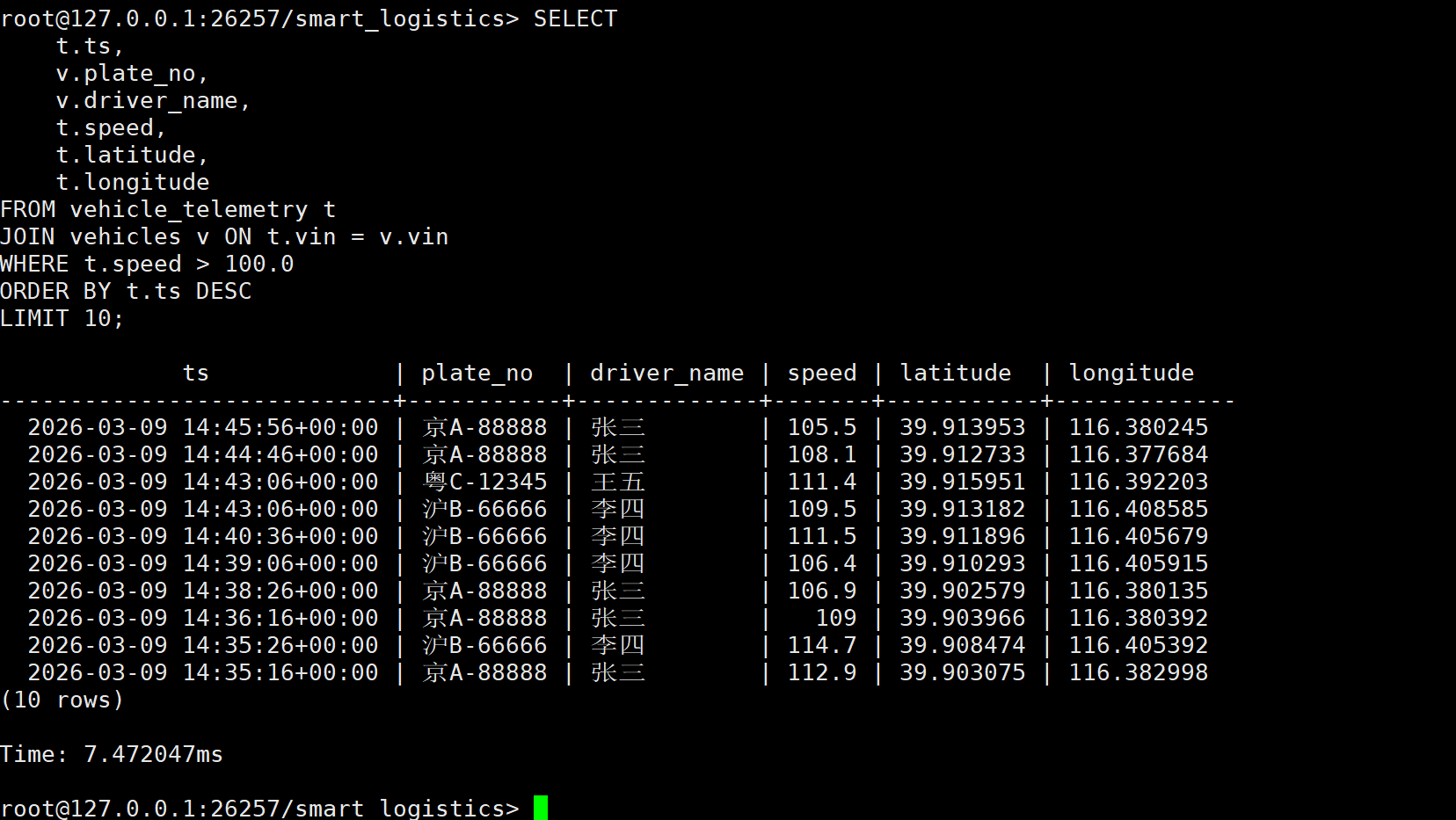
执行结果分析:
- 毫秒级响应 :查询耗时仅 7.47ms。
- 精准定位 :在海量轨迹数据中,KWDB 能够瞬间过滤出所有
speed > 100的记录。这对于实时报警系统至关重要,意味着一旦车辆超速,监控中心可以在 10 毫秒内收到警报,实现真正的"实时"监管。
场景二:油耗分析 (Fuel Efficiency)
业务痛点:油耗是物流车队最大的运营成本。通过分析"百公里油耗"和"平均车速"的关系,车队经理可以识别出"油耗子"车辆或驾驶习惯不良的司机,进行针对性培训。
需求:计算每辆车在过去 2 小时的平均油耗(这里用剩余油量的下降值来近似)和平均速度。
sql
USE smart_logistics;
SELECT
v.plate_no,
v.fleet_group,
max(t.fuel_level) - min(t.fuel_level) as fuel_consumed,
avg(t.speed) as avg_speed
FROM vehicle_telemetry t
JOIN vehicles v ON t.vin = v.vin
WHERE t.ts > now() - interval '2 hour'
GROUP BY v.plate_no, v.fleet_group;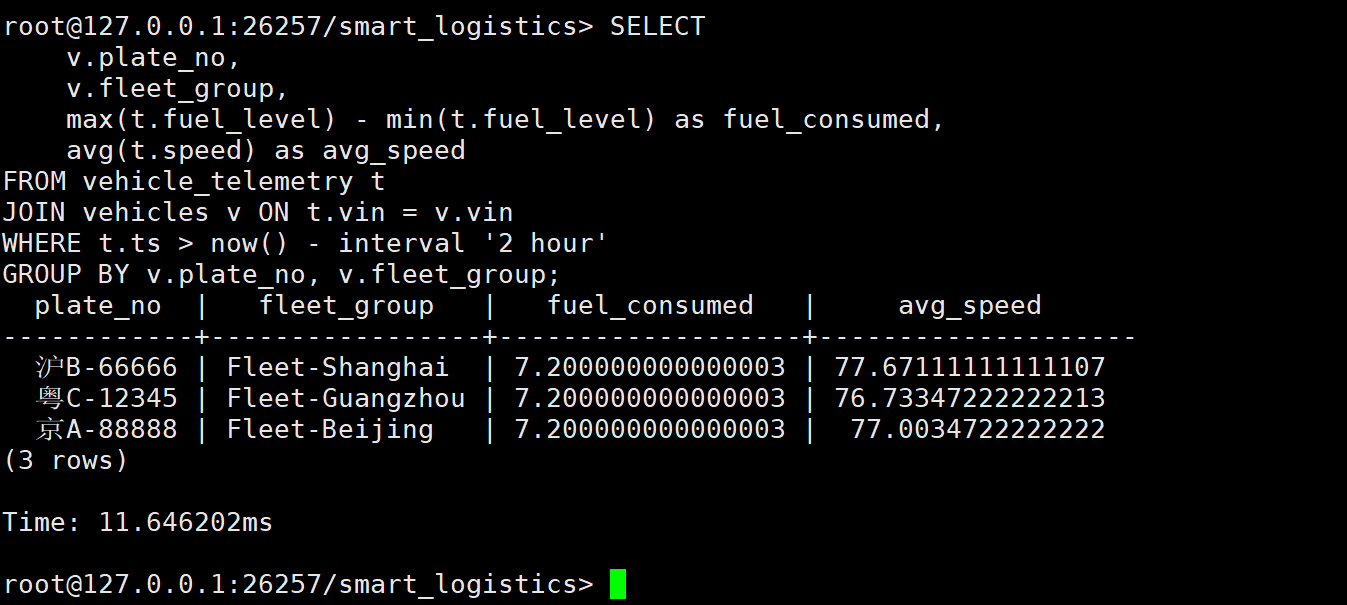
执行结果分析:
- 分析耗时 :11.65ms。
- 计算能力 :这是一个典型的聚合查询(Aggregation),涉及
JOIN(关联车辆表)和GROUP BY(按车队分组)。KWDB 在处理这类分析型查询时表现出了强大的计算能力,仅用 11 毫秒就完成了对过去 2 小时所有数据的统计。这说明它不仅能存,还能算,完全可以替代一部分传统 OLAP 数据库的功能。
场景三:最后位置查询 (Last Known Position)
业务痛点:在调度大屏上,我们需要看到所有车辆当前分布在哪里,以便就近指派订单。这就要求数据库能从海量历史轨迹中,瞬间"捞"出每辆车的最新一条记录。
需求:调度中心需要在大屏上显示所有车辆的最新位置。
sql
USE smart_logistics;
-- KWDB 对 last() 函数支持较好,或者使用 limit 1
SELECT DISTINCT ON (vin)
vin,
ts,
latitude,
longitude,
speed
FROM vehicle_telemetry
ORDER BY vin, ts DESC;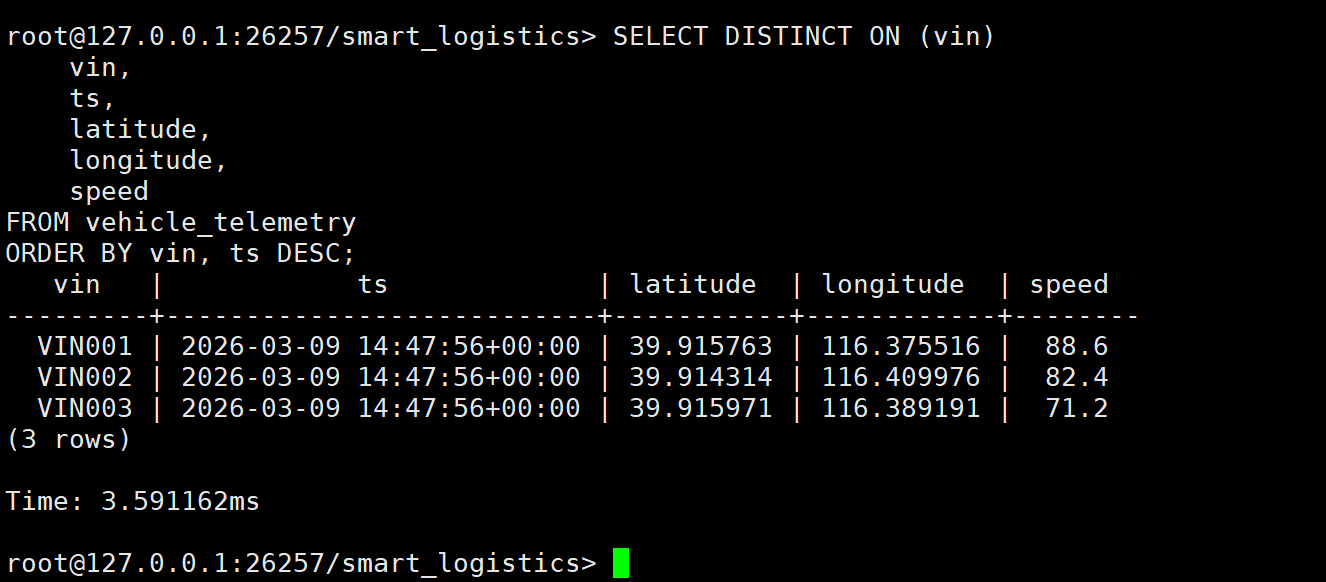
执行结果分析:
- 查询耗时 :3.59ms。
- 最新状态 :这是车联网中最频繁的查询场景------"每辆车现在在哪?"。使用
DISTINCT ON语法,KWDB 能够以极低的延迟(3.59毫秒)返回所有车辆的最新位置。这种性能足以支撑拥有数万辆车的物流平台实时刷新大屏地图
5. 避坑指南
- 轨迹纠偏 :原始 GPS 数据通常有漂移,建议在应用层做算法纠偏后再入库,或者在数据库层存储原始数据,查询时过滤掉
speed > 200等不合理噪点。 - 压缩算法:车联网数据量巨大,建议开启 KWDB 的列式压缩功能(默认已开启),可以节省大量存储空间。
总结
本案例展示了 KWDB 在高频轨迹处理方面的硬核实力。通过简单的 SQL,我们实现了一个车联网监控系统的核心后端逻辑,无需引入 Spark/Flink 等复杂的流计算引擎。
核心价值回顾:
- 架构简化:用一套数据库(KWDB)同时解决了"车辆关系数据"和"轨迹时序数据"的存储难题,避免了"MySQL + InfluxDB"带来的数据同步和一致性问题。
- 开发提效:全程使用标准 SQL,开发人员无需学习新的查询语言,上手成本极低。
- 性能卓越:实测显示,无论是批量写入(3.5万条/秒)还是聚合查询(毫秒级),都能轻松应对车联网场景的高并发挑战。
未来的车联网系统还可以利用 KWDB 做更多事情:
- 电子围栏 (Geo-fencing):虽然本文使用的是经纬度数值过滤,但 KWDB 实际上支持更高级的 GIS 地理空间函数。我们可以定义一个多边形区域(如"北京市六环内"),实时监控车辆是否越界。
- 驾驶行为评分:结合急加速、急转弯、超速等频次,利用 KWDB 的分析能力给每个司机打分,与绩效挂钩。
- 预测性维护:通过分析发动机转速和水温的历史趋势,提前预测车辆故障,变"事后维修"为"事前保养"。
车联网的未来是智能化的,而强大的数据底座正是智能化的基石。