摘要 ------MU-MIMO 技术使基站 (BS) 能够通过同一频段同时向多个用户传输信号。它是 5G NR 增加数据速率的关键技术。在 5G 规范中,MU-MIMO 调度器需要为每个 TTI 确定每个用户的 RB 分配和 MCS 指派。在 MU-MIMO 下,多个用户可能会被共同调度在同一个 RB 上,且每个用户可能同时拥有多个数据流。此外,调度器在决策过程中必须满足严苛的实时性要求 (∼1\sim 1∼1 ms) 才能发挥作用。本文提出了 mCore ,一种新型的 5G 调度器(5G scheduler),它可以通过对 MU-MIMO 用户的 RB 分配和 MCS 指派进行联合优化,实现 ∼1\sim 1∼1 ms 的调度。
mCore 的核心思想是执行多阶段优化(a multi-phase optimization),并利用大规模并行计算。在每个阶段,mCore 要么将优化问题分解为若干个独立的子问题,要么将搜索空间缩小为一个更小但最有希望的子空间,或者两者兼而有之。我们在商用现货 GPU 上实现了 mCore 。实验结果表明,与现有的其他先进算法相比,当面对多达 100100100 个 RB 、100100100 个用户、292929 个 MCS 等级和 4×124 \times 124×12 根天线时,mCore 能够提供最佳的调度性能。它也是唯一能在 ∼1\sim 1∼1 ms 内找到调度方案的算法。
MCS (Modulation and Coding Scheme,调制与编码策略)
定义:MCS 是一个索引值,决定了基站给特定用户传输数据时所采用的调制阶数(例如 QPSK、16QAM、64QAM、256QAM 等)和信道编码率(即数据中包含多少用于纠错的冗余信息)。
核心作用(链路自适应):系统会根据用户的实时信道质量指标(CQI)来动态调整 MCS。
信道质量好时:分配高 MCS 等级(高阶调制、低冗余),单次可以传输更多数据,从而提高数据吞吐量。
信道质量差时:分配低 MCS 等级(低阶调制、高冗余),单次传输的数据少,但抗干扰能力强,保证通信的可靠性。
TTI (Transmission Time Interval,传输时间间隔)
定义:TTI 是无线通信系统(如 4G LTE 和 5G NR)中,MAC 层向物理层进行无线电资源调度的最小时间单位。每次数据的打包、编码、调制和发送,都是以一个 TTI 为周期来进行的。
5G NR 中的演进:
在传统的 4G LTE 中,TTI 通常固定为 1 ms(即一个子帧的长度)。
在 5G NR 中,为了适应不同的业务需求(如低延迟业务 URLLC),引入了灵活的子载波间隔(Numerology),因此 TTI 也是动态可变的。它通常对应一个时隙(Slot,包含 14 个 OFDM 符号),甚至可以是更短的微时隙(Mini-slot,可能只有 2 到 7 个符号)。
I. INTRODUCTION
多用户 MIMO (MU-MIMO) 被广泛认为是 5G NR 提高网络吞吐量的核心技术 1--3。MU-MIMO 允许基站 (BS) 在同一频段上同时向多个用户发送信号。根据 5G 标准 4,每个 RB 上最多可以同时调度 121212 个数据流(针对多达 121212 个不同用户),其中每个用户最多可获得 888 个数据流。相比之下,4G LTE 在基站和设备上配备的天线数量较少(例如,在 sub-6 GHz 频段),并且通常只采用 222 流 SU-MIMO 或 222 用户 MU-MIMO 6, 7。
尽管 MU-MIMO 在提高吞吐量方面具有巨大潜力,但它也给基站调度器的设计带来了极大的复杂性。为了使我们的讨论更加具体,让我们考虑一个 5G 基站的下行链路调度问题(见图 1)。
-
首先,调度器应该分配一定数量的 RB 给小区用户进行数据传输。在 MU-MIMO 下,一个 RB 可以分配给多个用户。这些用户可以通过应用波束赋形技术来解码他们所需的信号。请注意,用户获得的 SINR(以及数据速率)取决于与该用户在同一 RB 上共同调度的用户集合。
-
其次,调度器需要确定从基站传输给每个用户的数据流数量,以利用 MIMO 信道提供的分集和空间复用之间的最佳折衷。
-
第三,调度器需要为每个用户选择调制和编码方案 (modulation and coding scheme,MCS)。5G NR 中的一个实际约束是,分配给某个用户的所有 RB 上使用的数据流数量以及 MCS 等级必须相同 4。
因此,调度问题将 RB 分配(RB-allocation)、数据流数量确定(stream number determination)和 MCS 选择紧密耦合在一起。这使得 MU-MIMO 调度问题成为 NP-hard 问题 8--10,并且具有极其庞大的解空间。
此外,一个实用的 5G MU-MIMO 调度器必须能够满足实时性要求才能发挥作用。基于 5G NR 帧结构,传输时间间隔 (transmission time interval,TTI) 最多为 111 ms 5。在每个 TTI(即 111 ms)内,基站调度器必须为每个用户决定 RB 分配、MCS 等级和数据流数量,以实现某些性能目标(例如,比例公平 (proportional fair,PF) 11, 21)。
在现有文献中,关于蜂窝调度器设计的研究一直很活跃。然而,现有研究中没有一个能提供满足 5G 实时性要求的 MU-MIMO 调度器。一些具有代表性的工作包括 8, 9, 12--15。文献 8, 9, 12--14 中的设计有一个共同特征------它们的算法必须运行大量的迭代。由于这种迭代性质,这些设计都无法在实时(∼1\sim 1∼1 ms)内提供调度方案。此外,几乎没有研究能够针对 MU-MIMO 用户联合优化 RB 和 MCS 的调度。
- 例如,文献 15 的作者实现了一个实时的 5G 调度器,但他们的设计仅考虑了单天线部署。
- 文献 12, 14 的作者设计了为 SU-MIMO 用户分配 RB 的调度器。但并没有考虑 MU-MIMO 和 MCS。
- 在文献 9, 13 中,MCS 分配在其模型中得到了开发,但设计并未考虑 MU-MIMO 调度。
- 在文献 8 中,作者采用了一个简化的 MU-MIMO 模型,该模型没有考虑 MCS 选择。
在本文中,我们提出了 mCore1^11,这是第一个能够满足 111 ms 实时性要求的 5G MU-MIMO 调度器的设计与实现。mCore 的成功建立在近期使用基于 GPU 的通用平台解决复杂优化问题的进展之上(参见例如 15--20)。mCore 采用多阶段优化,在每个阶段都利用了 GPU 的并行计算能力。具体而言,在每个阶段,mCore
- 要么将每个问题分解为大量独立的子问题以利用大规模并行性,
- 要么利用信道条件和用户相关性选择最有希望的搜索空间,
- 或者同时执行这两种操作。
mCore 的主要贡献总结如下:
- mCore 是第一个能够在 ∼1\sim 1∼1 ms 内提供调度方案以及相应的波束赋形矩阵的 5G MU-MIMO 调度器的设计与实现。特别是,mCore 支持 MU-MIMO 调度,允许多个用户共享同一频段并同时拥有多个数据流。mCore 能够实时应用于 5G 蜂窝网络。
- mCore 通过基于 GPU 架构的专用多阶段优化设计实现了大规模并行计算。此外(In particular),mCore 利用信道条件的知识以及共同调度的 MU-MIMO 用户之间的相关性,将搜索空间限制在最有希望的子空间内,从而降低了复杂性。
- 我们在商用现货 (COTS) GPU 平台 NVIDIA DGX Station 上实现了 mCore。为了使我们的问题适配 GPU,我们进行了特殊的工程努力(Special engineering efforts),包括生成足够大数量的线程(generating a sufficiently large number of threads)、实践适当的索引方法(practicing a proper indexing method)以及明智地使用共享内存(using shared memory wisely)。mCore 能够利用众核技术大幅加快计算速度。
- 我们进行了大量的实验来评估 mCore 的性能。结果表明,对于多达 100100100 个 RB、100100100 个用户、4×124\times124×12 MIMO 的情况,mCore 可以在 ∼1\sim 1∼1 ms 内提供调度方案,而对于 303030 个 RB、303030 个用户、2×82\times82×8 MIMO 的情况,则可以在 250μs250\mu s250μs 内完成。此外,与现有的先进算法相比,mCore 能够实现更好的吞吐量性能。
II. SYSTEM MODEL
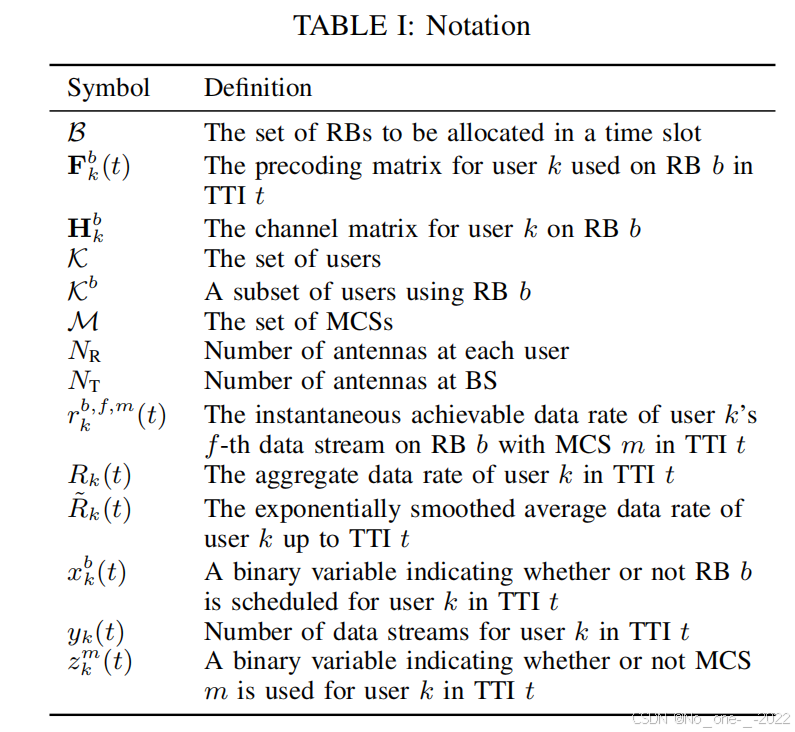
我们考虑 5G NR 蜂窝系统的下行链路 (DL) 调度问题。如图 1 所示,一个基站 (BS) 服务于一个用户集合 K\mathcal{K}K 。基站配备了 NTN_{\text{T}}NT 根天线,每个用户配备了 NRN_{\text{R}}NR 根天线( NT>NRN_{\text{T}} > N_{\text{R}}NT>NR )。表 I 给出了我们在本文中使用的主要符号。
我们考虑在宽带上的分时槽调度(time-slotted scheduling)。在每个时槽内,在下行链路带宽上存在一个 RB 集合 B\mathcal{B}B 。在每个 RB b∈Bb \in \mathcal{B}b∈B 上,选择用户子集 Kb⊂K\mathcal{K}^b \subset \mathcal{K}Kb⊂K 进行 MU-MIMO 传输2^22。用 xkb(t)∈{0,1}x_k^b(t) \in \{0, 1\}xkb(t)∈{0,1} 表示一个二元变量,指示在 TTI ttt 中基站是否为用户 k∈Kk \in \mathcal{K}k∈K 调度了 RB b∈Bb \in \mathcal{B}b∈B ,即,
xkb(t)={1,如果 RB b 在 TTI t 中被用于用户 k,0,其他.(1) x_k^b(t) = \begin{cases} 1, & \text{如果 RB } b \text{ 在 TTI } t \text{ 中被用于用户 } k, \\ 0, & \text{其他.} \end{cases} \tag{1} xkb(t)={1,0,如果 RB b 在 TTI t 中被用于用户 k,其他.(1)
对于 xkb(t)x_k^b(t)xkb(t) ,我们有以下约束。
约束 1 . 在一个 RB 中调度的最大用户数不能超过基站的天线数,即,
∑k∈Kxkb(t)≤NT.(b∈B)(2) \sum_{k \in \mathcal{K}} x_k^b(t) \le N_{\text{T}}. \quad (b \in \mathcal{B}) \tag{2} k∈K∑xkb(t)≤NT.(b∈B)(2)此外,每个用户 k∈Kk \in \mathcal{K}k∈K 可以同时拥有多个数据流(在规范 4 中也称为"层")。
然而,为了减少前馈控制信令开销和信号处理复杂度, 5G NR 施加了以下约束。
约束 2 . 如果一个用户被调度在多个 RB 上接收信号,那么该用户在所有分配给她的 RB 上必须拥有相同数量的数据流 4 。用 yk(t)y_k(t)yk(t) (非负整数)表示用户 kkk 在 TTI ttt 中的数据流数量(这在所有分配的 RB 上是相同的)。由于 yk(t)y_k(t)yk(t) 不能大于接收天线的数量,我们有
yk(t)≤NR.(k∈K)(3) y_k(t) \le N_{\text{R}}. \quad (k \in \mathcal{K}) \tag{3} yk(t)≤NR.(k∈K)(3)同时,用于 MU-MIMO 传输的每个 RB 上的数据流总数不能超过基站的天线数量。我们有
∑k∈Kxkb(t)yk(t)≤NT.(b∈B)(4) \sum_{k \in \mathcal{K}} x_k^b(t) y_k(t) \le N_{\text{T}}. \quad (b \in \mathcal{B}) \tag{4} k∈K∑xkb(t)yk(t)≤NT.(b∈B)(4)
在每个 TTI ttt 中,用户有一个可用于数据传输的 MCS 集合 M\mathcal{M}M 。对于 MCS 选择,我们有以下约束。
约束 3 . 如果一个用户被调度在多个 RB 上接收数据流,那么该用户必须在所有调度的 RB 上的所有数据流中使用相同的 MCS 4 。用 zkm(t)∈{0,1}z_k^m(t) \in \{0, 1\}zkm(t)∈{0,1} 表示一个二元变量,指示在 TTI ttt 中基站是否将 MCS m∈Mm \in \mathcal{M}m∈M 用于用户 k∈Kk \in \mathcal{K}k∈K ,即,
zkm(t)={1,如果 MCS m 在 TTI t 中被用于用户 k,0,其他.(5) z_k^m(t) = \begin{cases} 1, & \text{如果 MCS } m \text{ 在 TTI } t \text{ 中被用于用户 } k, \\ 0, & \text{其他.} \end{cases} \tag{5} zkm(t)={1,0,如果 MCS m 在 TTI t 中被用于用户 k,其他.(5)为了保证在分配给用户 kkk 的所有调度的 RB 上只使用一种 MCS ,我们有
∑m∈Mzkm=1.(k∈K)(6) \sum_{m \in \mathcal{M}} z_k^m = 1. \quad (k \in \mathcal{K}) \tag{6} m∈M∑zkm=1.(k∈K)(6)
基站应用预编码器来支持 MU-MIMO 和多个数据流。令 Fkb(t)\mathbf{F}k^b(t)Fkb(t) 为基站调度器在 RB bbb 上用于用户 kkk 的 NT×xkb(t)yk(t)N{\text{T}} \times x_k^b(t)y_k(t)NT×xkb(t)yk(t) 预编码矩阵。为了满足基站的功率约束,我们有 ∑k∈K∣∣Fkb(t)∣∣F2≤PT\sum_{k \in \mathcal{K}} ||\mathbf{F}k^b(t)||F^2 \le P{\text{T}}∑k∈K∣∣Fkb(t)∣∣F2≤PT ,其中 PTP{\text{T}}PT 是基站的总功率, ∣∣⋅∣∣F||\cdot||_F∣∣⋅∣∣F 表示 Frobenius 范数。那么用户 kkk 在 RB bbb 上的接收信号由下式给出
ckb=HkbFkbskb+Hkb∑i∈Ki≠kFibsib+nkb,(k∈Kb,b∈B) \mathbf{c}_k^b = \mathbf{H}_k^b \mathbf{F}_k^b \mathbf{s}_k^b + \mathbf{H}k^b \sum{i \in \mathcal{K}}^{i \neq k} \mathbf{F}_i^b \mathbf{s}_i^b + \mathbf{n}_k^b, \quad (k \in \mathcal{K}^b, b \in \mathcal{B}) ckb=HkbFkbskb+Hkbi∈K∑i=kFibsib+nkb,(k∈Kb,b∈B)
其中 Hkb∈CNR×NT\mathbf{H}k^b \in \mathbb{C}^{N{\text{R}} \times N_{\text{T}}}Hkb∈CNR×NT 是用户 k∈Kk \in \mathcal{K}k∈K 在 RB b∈Bb \in \mathcal{B}b∈B 上的信道矩阵, nkb\mathbf{n}k^bnkb 是独立同分布的 CN(0,n02)\mathcal{CN}(0, n_0^2)CN(0,n02) 加性复高斯噪声的 NR×1N{\text{R}} \times 1NR×1 向量, skb\mathbf{s}_k^bskb 是信号向量,为了简洁起见,我们省略了矩阵的 (t)(t)(t) 符号。
PTP_{\text{T}}PT:基站在单个 RB bbb 上发射的总功率
2^22 5G 中最小的调度分辨率可以是若干连续的 RB,称为资源块组 (RBG)。我们的设计可以很容易地扩展到基于 RBG 的调度。
每个用户 kkk 计算 Hkb=UkbΣkbVkb†\mathbf{H}_k^b = \mathbf{U}_k^b \mathbf{\Sigma}_k^b \mathbf{V}_k^{b\dagger}Hkb=UkbΣkbVkb† 的 SVD,其中 (⋅)†(\cdot)^\dagger(⋅)† 表示矩阵的共轭转置。 Σkb\mathbf{\Sigma}_k^bΣkb 和 Vkb\mathbf{V}_k^bVkb 被进一步压缩、量化并反馈给基站(以辅助预编码),并且 Ukb\mathbf{U}_k^bUkb 的最左侧 yky_kyk 列,记为 Ukb(yk)\mathbf{U}_k^{b(y_k)}Ukb(yk) ,被用作用户 kkk 处的合并器。在这个合并器之后,我们得到以下信号:
c~kb=Ukb(yk)†ckb=Γkb†Fkbskb+Γkb†∑i∈Kbi≠kFibsib+Ukb(yk)†nkb,(7) \tilde{\mathbf{c}}_k^b = \mathbf{U}_k^{b(y_k)\dagger} \mathbf{c}_k^b = \mathbf{\Gamma}_k^{b\dagger} \mathbf{F}_k^b \mathbf{s}_k^b + \mathbf{\Gamma}k^{b\dagger} \sum{i \in \mathcal{K}^b}^{i \neq k} \mathbf{F}_i^b \mathbf{s}_i^b + \mathbf{U}_k^{b(y_k)\dagger} \mathbf{n}_k^b, \tag{7} c~kb=Ukb(yk)†ckb=Γkb†Fkbskb+Γkb†i∈Kb∑i=kFibsib+Ukb(yk)†nkb,(7)
其中 Γkb=σk,1bvk,1b,⋯ ,σk,ykbvk,ykb\mathbf{\Gamma}k^b = \\sigma_{k,1}\^b \\mathbf{v}_{k,1}\^b, \\cdots, \\sigma_{k,y_k}\^b \\mathbf{v}_{k,y_k}\^bΓkb=σk,1bvk,1b,⋯,σk,ykbvk,ykb 是一个 NT×ykN{\text{T}} \times y_kNT×yk 矩阵, σk,ib\sigma_{k,i}^bσk,ib 是 Σkb\mathbf{\Sigma}k^bΣkb 的第 iii 个特征值,且 vk,ib\mathbf{v}{k,i}^bvk,ib 是 Vkb\mathbf{V}_k^bVkb 的第 iii 列。因此, Γkb\mathbf{\Gamma}_k^bΓkb 是在用户处应用合并器后的等效信道。可以基于 Γkb\mathbf{\Gamma}_k^bΓkb 使用不同的预编码方案。在本文中,我们应用对每个数据流具有等功率分配的 ZF 预编码方案。3^33
公式 (7) 推导过程
第一步:初始接收信号接收端用户 kkk 在 RB bbb 上的初始接收信号可以表示为期望信号、多用户干扰 (MUI) 和噪声的叠加:
ckb=HkbFkbskb+Hkb∑i∈Kbi≠kFibsib+nkb \mathbf{c}_k^b = \mathbf{H}_k^b \mathbf{F}_k^b \mathbf{s}_k^b + \mathbf{H}k^b \sum{i \in \mathcal{K}^b}^{i \neq k} \mathbf{F}_i^b \mathbf{s}_i^b + \mathbf{n}_k^b ckb=HkbFkbskb+Hkbi∈Kb∑i=kFibsib+nkb
第二步:应用合并器接收端使用合并器 Ukb(yk)†\mathbf{U}_k^{b(y_k)\dagger}Ukb(yk)† 对接收信号进行左乘处理:
c~kb=Ukb(yk)†ckb=Ukb(yk)†HkbFkbskb+Ukb(yk)†Hkb∑i∈Kbi≠kFibsib+Ukb(yk)†nkb \tilde{\mathbf{c}}_k^b = \mathbf{U}_k^{b(y_k)\dagger} \mathbf{c}_k^b = \mathbf{U}_k^{b(y_k)\dagger} \mathbf{H}_k^b \mathbf{F}_k^b \mathbf{s}_k^b + \mathbf{U}_k^{b(y_k)\dagger} \mathbf{H}k^b \sum{i \in \mathcal{K}^b}^{i \neq k} \mathbf{F}_i^b \mathbf{s}_i^b + \mathbf{U}_k^{b(y_k)\dagger} \mathbf{n}_k^b c~kb=Ukb(yk)†ckb=Ukb(yk)†HkbFkbskb+Ukb(yk)†Hkbi∈Kb∑i=kFibsib+Ukb(yk)†nkb为得到最终等式,核心在于证明 Ukb(yk)†Hkb=Γkb†\mathbf{U}_k^{b(y_k)\dagger} \mathbf{H}_k^b = \mathbf{\Gamma}_k^{b\dagger}Ukb(yk)†Hkb=Γkb† 。
第三步:信道矩阵的 SVD 分块展开对信道矩阵进行 SVD 分解 Hkb=UkbΣkbVkb†\mathbf{H}_k^b = \mathbf{U}_k^b \mathbf{\Sigma}_k^b \mathbf{V}_k^{b\dagger}Hkb=UkbΣkbVkb† 。截取前 yky_kyk 个数据流,利用分块矩阵可表示为:
Hkb=Ukb(yk)Σkb(yk)Vkb(yk)†+UrestΣrestVrest† \mathbf{H}_k^b = \mathbf{U}k^{b(y_k)} \mathbf{\Sigma}k^{b(y_k)} \mathbf{V}k^{b(y_k)\dagger} + \mathbf{U}{\text{rest}} \mathbf{\Sigma}{\text{rest}} \mathbf{V}{\text{rest}}^\dagger Hkb=Ukb(yk)Σkb(yk)Vkb(yk)†+UrestΣrestVrest†
第四步:证明等效信道等式计算 Ukb(yk)†Hkb\mathbf{U}_k^{b(y_k)\dagger} \mathbf{H}_k^bUkb(yk)†Hkb 。由于 Ukb\mathbf{U}_k^bUkb 是酉矩阵,其列向量相互正交且归一化,满足 Ukb(yk)†Ukb(yk)=I\mathbf{U}_k^{b(y_k)\dagger} \mathbf{U}_k^{b(y_k)} = \mathbf{I}Ukb(yk)†Ukb(yk)=I 且 Ukb(yk)†Urest=0\mathbf{U}k^{b(y_k)\dagger} \mathbf{U}{\text{rest}} = \mathbf{0}Ukb(yk)†Urest=0 ,因此代入展开式可得:
Ukb(yk)†Hkb=Σkb(yk)Vkb(yk)† \mathbf{U}_k^{b(y_k)\dagger} \mathbf{H}_k^b = \mathbf{\Sigma}_k^{b(y_k)} \mathbf{V}_k^{b(y_k)\dagger} Ukb(yk)†Hkb=Σkb(yk)Vkb(yk)†另一方面,根据文中定义,等效信道 Γkb\mathbf{\Gamma}_k^bΓkb 为矩阵 Vkb(yk)\mathbf{V}_k^{b(y_k)}Vkb(yk) 对列进行 Σkb(yk)\mathbf{\Sigma}_k^{b(y_k)}Σkb(yk) 缩放的结果:
Γkb=Vkb(yk)Σkb(yk) \mathbf{\Gamma}_k^b = \mathbf{V}_k^{b(y_k)} \mathbf{\Sigma}_k^{b(y_k)} Γkb=Vkb(yk)Σkb(yk)对其求共轭转置,由于奇异值对角阵满足 Σ†=Σ\mathbf{\Sigma}^\dagger = \mathbf{\Sigma}Σ†=Σ ,可得:
Γkb†=Σkb(yk)Vkb(yk)† \mathbf{\Gamma}_k^{b\dagger} = \mathbf{\Sigma}_k^{b(y_k)} \mathbf{V}_k^{b(y_k)\dagger} Γkb†=Σkb(yk)Vkb(yk)†由此证明 Ukb(yk)†Hkb=Γkb†\mathbf{U}_k^{b(y_k)\dagger} \mathbf{H}_k^b = \mathbf{\Gamma}_k^{b\dagger}Ukb(yk)†Hkb=Γkb† 成立。
第五步:得出最终结果将证明的等式代回第二步的信号表达式中,即得到最终的推导结果:
c~kb=Γkb†Fkbskb+Γkb†∑i∈Kbi≠kFibsib+Ukb(yk)†nkb(7) \tilde{\mathbf{c}}_k^b = \mathbf{\Gamma}_k^{b\dagger} \mathbf{F}_k^b \mathbf{s}_k^b + \mathbf{\Gamma}k^{b\dagger} \sum{i \in \mathcal{K}^b}^{i \neq k} \mathbf{F}_i^b \mathbf{s}_i^b + \mathbf{U}_k^{b(y_k)\dagger} \mathbf{n}_k^b \tag{7} c~kb=Γkb†Fkbskb+Γkb†i∈Kb∑i=kFibsib+Ukb(yk)†nkb(7)
对于 k∈Kk \in \mathcal{K}k∈K ,在 RB bbb 上第 fff 个数据流的信号干扰噪声比 (SINR) 由下式给出
SINRkb,f=γkb,fQkb,f−γkb,f,(8) \text{SINR}_k^{b,f} = \frac{\gamma_k^{b,f}}{\mathbf{Q}_k^{b,f} - \gamma_k^{b,f}}, \tag{8} SINRkb,f=Qkb,f−γkb,fγkb,f,(8)其中γkb,f=Γkb,f†Fkb,fFkb,f†Γkb,f \gamma_k^{b,f} = \mathbf{\Gamma}_k^{b,f\dagger} \mathbf{F}_k^{b,f} \mathbf{F}_k^{b,f\dagger} \mathbf{\Gamma}_k^{b,f} γkb,f=Γkb,f†Fkb,fFkb,f†Γkb,fQkb,f=n02+∑i∈KΓkb,f†FibFib†Γkb,f, \mathbf{Q}k^{b,f} = n_0^2 + \sum{i \in \mathcal{K}} \mathbf{\Gamma}_k^{b,f\dagger} \mathbf{F}_i^b \mathbf{F}_i^{b\dagger} \mathbf{\Gamma}_k^{b,f}, Qkb,f=n02+i∈K∑Γkb,f†FibFib†Γkb,f,并且 (⋅)kb,f(\cdot)_k^{b,f}(⋅)kb,f 是 (⋅)kb(\cdot)_k^b(⋅)kb 的第 fff 列。
瞬时可达数据速率取决于每个数据流的 SINR 和所选的 MCS 等级。具体而言,对于每个用户 k∈Kk \in \mathcal{K}k∈K ,较高的 MCS 等级 mmm 对应于传输中较高的数据速率 rmr^mrm 。然而,为了成功解码数据,用户 kkk 的每个数据流需要一定等级的 SINR。用 θm\theta^mθm 表示每个数据流使用 MCS mmm 成功解码数据的 SINR 阈值。那么我们有以下约束。
约束 4. 如果用户 kkk 在 RB bbb 上的第 fff 个数据流的 SINR 大于或等于 θm\theta^mθm ,那么该数据流的瞬时可达数据速率为 rmr^mrm ;否则可达数据速率降为零。用 rkb,f,m(t)r_k^{b,f,m}(t)rkb,f,m(t) 表示在 TTI ttt 中,用户 kkk 在 RB bbb 上使用 MCS mmm 的第 fff 个数据流的瞬时可达数据速率。那么
rkb,f,m(t)={rm,如果 SINRkb,f≥θm,0,其他.(f=1,⋯ ,yk(t),k∈K,b∈B,m∈M)(9) r_k^{b,f,m}(t) = \begin{cases} r^m, & \text{如果 } \text{SINR}k^{b,f} \ge \theta^m, \\ 0, & \text{其他.} \end{cases} \quad (f = 1, \cdots, y_k(t), k \in \mathcal{K}, b \in \mathcal{B}, m \in \mathcal{M}) \tag{9} rkb,f,m(t)={rm,0,如果 SINRkb,f≥θm,其他.(f=1,⋯,yk(t),k∈K,b∈B,m∈M)(9)用户 kkk 在 TTI ttt 中的总可达数据速率可以由下式给出Rk(t)=∑b∈Bxkb(t)∑f=1yk(t)∑m∈Mzkm(t)rkb,f,m(t),(10) R_k(t) = \sum{b \in \mathcal{B}} x_k^b(t) \sum_{f=1}^{y_k(t)} \sum_{m \in \mathcal{M}} z_k^m(t) r_k^{b,f,m}(t), \tag{10} Rk(t)=b∈B∑xkb(t)f=1∑yk(t)m∈M∑zkm(t)rkb,f,m(t),(10)其中如果 yk(t)=0y_k(t) = 0yk(t)=0 ,我们定义 ∑f=1yk(t)(⋅)=0\sum_{f=1}^{y_k(t)}(\cdot) = 0∑f=1yk(t)(⋅)=0 。
目标函数。 为了在考虑公平性的情况下优化吞吐量性能,我们应用广泛使用的 PF 数据速率作为我们的性能目标。用 R~k\tilde{R}_kR~k 表示用户 kkk 的长期平均数据速率。PF 目标函数由下式给出
∑k∈KlogR~k.(11) \sum_{k \in \mathcal{K}} \log \tilde{R}_k. \tag{11} k∈K∑logR~k.(11)
我们的实时调度器旨在通过在每个 TTI ttt 中做出调度决策来最大化 (11) 。一种常见的方法是最大化每个用户的瞬时速率与其在过去 TcT_cTc 个 TTI 内经过指数平滑的平均数据速率的归一化之和 21, 22 ,即,∑k∈KRk(t)R~k(t−1),(12) \sum_{k \in \mathcal{K}} \frac{R_k(t)}{\tilde{R}_k(t-1)}, \tag{12} k∈K∑R~k(t−1)Rk(t),(12)
其中R~k(t−1)=Tc−1TcR~k(t−2)+1TcRk(t−1). \tilde{R}_k(t-1) = \frac{T_c - 1}{T_c} \tilde{R}_k(t-2) + \frac{1}{T_c} R_k(t-1). R~k(t−1)=TcTc−1R~k(t−2)+Tc1Rk(t−1).
研究表明,当 Tc→∞T_c \to \inftyTc→∞ 时,在每个 TTI 中最大化 (12) 会渐近于 PF 目标 (11) 。
问题陈述。 我们的目标是在每个 TTI 中为所有用户分配 RB 、 MCS 、指派数据流的数量,以及计算预编码矩阵,以使 PF 目标函数 (12) 最大化。这个 5G MU-MIMO 调度问题可以写成如下形式。
OPT
max∑b∈B∑k∈K∑m∈M∑f=1yk(t)rkb,f,m(t)R~k(t−1)xkb(t)zkm(t)s.t.RB 分配约束: (2);数据流分配约束: (3), (4);MCS 指派约束: (6);SINR 和瞬时数据速率: (8), (9);xkb(t)∈{0,1}, yk(t)∈{0,1,⋯ }, zkm(t)∈{0,1}. \begin{aligned} \max \quad & \sum_{b \in \mathcal{B}} \sum_{k \in \mathcal{K}} \sum_{m \in \mathcal{M}} \sum_{f=1}^{y_k(t)} \frac{r_k^{b,f,m}(t)}{\tilde{R}_k(t-1)} x_k^b(t) z_k^m(t) \\ \text{s.t.} \quad & \text{RB 分配约束: (2);} \\ & \text{数据流分配约束: (3), (4);} \\ & \text{MCS 指派约束: (6);} \\ & \text{SINR 和瞬时数据速率: (8), (9);} \\ & x_k^b(t) \in \{0, 1\}, \ y_k(t) \in \{0, 1, \cdots\}, \ z_k^m(t) \in \{0, 1\}. \end{aligned} maxs.t.b∈B∑k∈K∑m∈M∑f=1∑yk(t)R~k(t−1)rkb,f,m(t)xkb(t)zkm(t)RB 分配约束: (2);数据流分配约束: (3), (4);MCS 指派约束: (6);SINR 和瞬时数据速率: (8), (9);xkb(t)∈{0,1}, yk(t)∈{0,1,⋯}, zkm(t)∈{0,1}.
在问题 OPT 中, xkb(t)x_k^b(t)xkb(t) 、 yk(t)y_k(t)yk(t) 和 zkm(t)z_k^m(t)zkm(t) 是决策变量, Fb(t)\mathbf{F}^b(t)Fb(t) 、 rkb,f,m(t)r_k^{b,f,m}(t)rkb,f,m(t) 和 R~k(t−1)\tilde{R}_k(t-1)R~k(t−1) 是中间变量,其他的则是给定常数。
实时挑战 问题 OPT 是 NP-hard 的 8, 9 ,并且解空间极其庞大。可能的 MCS 指派数量为 ∣M∣∣K∣|\mathcal{M}|^{|\mathcal{K}|}∣M∣∣K∣ 。在 MU-MIMO 设置下,可能的 RB 分配数量为 ∣B∣(∣K∣1)+⋯+(∣K∣NT)|\mathcal{B}| \left \\binom{\|\\mathcal{K}\|}{1} + \\cdots + \\binom{\|\\mathcal{K}\|}{N_{\\text{T}}} \\right∣B∣(1∣K∣)+⋯+(NT∣K∣) 。此外,可能的数据流分配数量为 NR∣K∣N_{\text{R}}^{|\mathcal{K}|}NR∣K∣ 。这些给了我们解空间中总共 (∣M∣NR)∣K∣∣B∣(∣K∣1)+⋯+(∣K∣NT)(|\mathcal{M}|N_{\text{R}})^{|\mathcal{K}|} |\mathcal{B}| \left \\binom{\|\\mathcal{K}\|}{1} + \\cdots + \\binom{\|\\mathcal{K}\|}{N_{\\text{T}}} \\right(∣M∣NR)∣K∣∣B∣(1∣K∣)+⋯+(NT∣K∣) 种可能性。在一个典型的 5G 蜂窝系统中,这个数字可能大到 ∼10189\sim 10^{189}∼10189 (当 ∣M∣=29|\mathcal{M}| = 29∣M∣=29 , ∣K∣=100|\mathcal{K}| = 100∣K∣=100 , ∣B∣=100|\mathcal{B}| = 100∣B∣=100 , NT=8N_{\text{T}} = 8NT=8 且 NR=2N_{\text{R}} = 2NR=2 时)。
另一方面,我们有着严苛的时序要求。在 5G NR 中,一个 TTI 的最长间隔时间为 111 ms(参数集 0) 5 。因此,有必要执行亚毫秒级调度,以实现 5G 下最大的 PF 性能。在本文中,我们将实时要求设定为
Treq=1 ms(13) T_{\text{req}} = 1 \text{ ms} \tag{13} Treq=1 ms(13)
对于一个 5G 调度器而言,虽然如果在轻量级设置下(例如,较少的用户数量),我们可能支持更多的参数集。面对高复杂度的问题和严苛的时序要求,现有的研究中没有一个能提供满足我们目标的解决方案。
5G MU-MIMO 调度解空间大小推导
1. 可能的 MCS 指派数量 zkm(t)z_k^m(t)zkm(t):∣M∣∣K∣|\mathcal{M}|^{|\mathcal{K}|}∣M∣∣K∣
- 约束条件:每个被调度的用户在所有分配的 RB 和数据流上必须使用完全相同的 MCS 等级。
- 推导过程 :系统共有 ∣K∣|\mathcal{K}|∣K∣ 个用户。每个用户独立从 ∣M∣|\mathcal{M}|∣M∣ 种可用的 MCS 等级中选择一种。根据排列组合的乘法原理,所有用户的总体选择方案数为 ∣M∣×∣M∣×⋯=∣M∣∣K∣|\mathcal{M}| \times |\mathcal{M}| \times \dots = |\mathcal{M}|^{|\mathcal{K}|}∣M∣×∣M∣×⋯=∣M∣∣K∣。
2. 可能的 RB 分配数量 xkb(t)x_k^b(t)xkb(t):∣B∣(∣K∣1)+⋯+(∣K∣NT)|\mathcal{B}| \left \\binom{\|\\mathcal{K}\|}{1} + \\cdots + \\binom{\|\\mathcal{K}\|}{N_{\\text{T}}} \\right∣B∣(1∣K∣)+⋯+(NT∣K∣)
- 约束条件 :在 MU-MIMO 中,同一个 RB 可分配给多个用户,但共同调度的用户总数不能超过基站天线数 NTN_{\text{T}}NT。
- 推导过程 :
- 单 RB 层面 :调度 111 个用户的组合数为 (∣K∣1)\binom{|\mathcal{K}|}{1}(1∣K∣),调度 222 个为 (∣K∣2)\binom{|\mathcal{K}|}{2}(2∣K∣),依此类推,最多调度 NTN_{\text{T}}NT 个用户。将这些情况求和,单 RB 的所有合法用户组合数为 (∣K∣1)+⋯+(∣K∣NT)\left \\binom{\|\\mathcal{K}\|}{1} + \\cdots + \\binom{\|\\mathcal{K}\|}{N_{\\text{T}}} \\right(1∣K∣)+⋯+(NT∣K∣)。
- 全局层面 :系统共有 ∣B∣|\mathcal{B}|∣B∣ 个独立 RB。算法在评估搜索空间时,将单 RB 的组合数与总 RB 数 ∣B∣|\mathcal{B}|∣B∣ 相乘,得到整体的 RB 分配可能数。
3. 可能的数据流分配数量 yk(t)y_k(t)yk(t) :NR∣K∣N_{\text{R}}^{|\mathcal{K}|}NR∣K∣
- 约束条件 :分配给特定用户的流数在所有 RB 上必须相同,且不能超过该终端的接收天线数 NRN_{\text{R}}NR。
- 推导过程 :系统共有 ∣K∣|\mathcal{K}|∣K∣ 个用户。每个用户的数据流层数有 NRN_{\text{R}}NR 种选择(假设从 111 到 NRN_{\text{R}}NR 层)。再次应用乘法原理,所有用户的数据流分配组合总数为 NR×NR×⋯=NR∣K∣N_{\text{R}} \times N_{\text{R}} \times \dots = N_{\text{R}}^{|\mathcal{K}|}NR×NR×⋯=NR∣K∣。
III. MCORE: A NOVEL DESIGN OF REAL-TIME MU-MIMO SCHEDULER
A. Main Ideas
主要思想包含两个方面。首先, mCore 将 OPT 分解为大量独立的子问题。目标是利用并行计算资源同时解决这些子问题。其次, mCore 借助从信道条件和相关性中获得的洞察力,明智地将庞大的搜索空间缩小到一个更小但最有希望的搜索子空间。
不出所料,分解 OPT 或缩小搜索空间并非易事,因为我们有多组决策变量(即 xkb(t)x_k^b(t)xkb(t) 、 yk(t)y_k(t)yk(t) 和 zkm(t)z_k^m(t)zkm(t) ),并且它们之间紧密耦合。这些组合使得解空间极其庞大。因此,穷尽检查所有可能性的简单并行算法是行不通的。为了解决这个问题, mCore 明智地通过多阶段优化来解决 OPT。在每个阶段, mCore 专注于一种类型的变量(即 xkb(t)x_k^b(t)xkb(t) 、 yk(t)y_k(t)yk(t) 或 zkm(t)z_k^m(t)zkm(t) )。也就是说,每个阶段要么将优化问题连同该类型的变量分解为若干个独立的子问题,要么将该类型变量的搜索空间限制在一个更小但最有希望的子空间内,或者两者兼而有之。
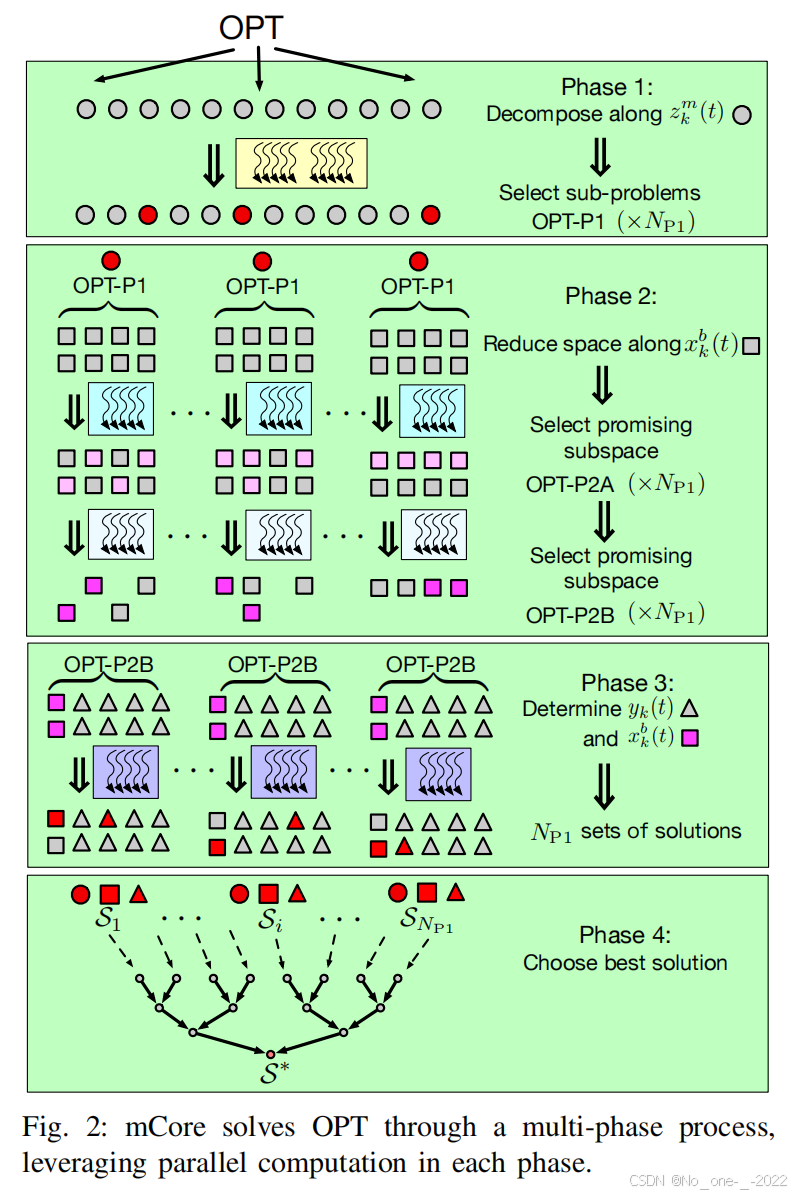
图 2 说明了多阶段优化。在阶段 1,问题 OPT 沿着 zkm(t)z_k^m(t)zkm(t) 变量被分解,这对应于一个 MCS 选择问题。从 ∣M∣∣K∣|\mathcal{M}|^{|\mathcal{K}|}∣M∣∣K∣ 种可能的 MCS 指派中, mCore 基于信道条件选择了 NP1N_{\text{P1}}NP1 个有希望的候选者。因此,问题 OPT 被拆分为 NP1N_{\text{P1}}NP1 个独立的子问题,命名为 OPT-P1。
在阶段 2,我们专注于沿着 xkb(t)x_k^b(t)xkb(t) 变量缩减搜索空间,这意味着 MU-MIMO 传输的用户选择问题。阶段 2 由两个步骤组成。
- 步骤 A 评估被长期平均速率 R~k(t−1)\tilde{R}_k(t-1)R~k(t−1) 归一化的信道质量 qkbq_k^bqkb 。然后, RB bbb 的分配被限制在用户的一个子集 K~b⊂K\tilde{\mathcal{K}}^b \subset \mathcal{K}K~b⊂K 内。Step A 利用归一化信道质量,剔除了条件差的用户。
- 在阶段 2 的步骤 B 中, mCore 测量用户 K~b\tilde{\mathcal{K}}^bK~b 之间的信道正交性,然后 RB 的分配进一步被限制在一个更小的用户集合 Kb⊂K~b\mathcal{K}^b \subset \tilde{\mathcal{K}}^bKb⊂K~b ( ∣Kb∣≤NT|\mathcal{K}^b| \le N_{\text{T}}∣Kb∣≤NT )内,该集合内的用户具有良好的正交性。Step B 利用正交性测量,剔除了那些相互之间干扰极大、凑在一起也无法解码的用户组合。
经过阶段 2 之后,我们仍然有 NP1N_{\text{P1}}NP1 个独立的子问题,命名为 OPT-P2B,而 RB 分配可能性的数量从 ∣B∣(∣K∣1)+⋯+(∣K∣NT)|\mathcal{B}| \left \\binom{\|\\mathcal{K}\|}{1} + \\cdots + \\binom{\|\\mathcal{K}\|}{N_{\\text{T}}} \\right∣B∣(1∣K∣)+⋯+(NT∣K∣) 减少到了 ∣B∣(∣Kb∣1)+⋯+(∣Kb∣∣Kb∣)|\mathcal{B}| \left \\binom{\|\\mathcal{K}\^b\|}{1} + \\cdots + \\binom{\|\\mathcal{K}\^b\|}{\|\\mathcal{K}\^b\|} \\right∣B∣(1∣Kb∣)+⋯+(∣Kb∣∣Kb∣) 。
既然对于不同的 bbb , ∣Kb∣|\mathcal{K}^b|∣Kb∣ 的值不同,那么总的组合数绝对不能简单地用 ∣B∣|\mathcal{B}|∣B∣ 去相乘。正确的写法应该是对所有 b∈Bb \in \mathcal{B}b∈B 上的组合数进行求和:∏b∈B∑i=1∣Kb∣(∣Kb∣i)\prod_{b \in \mathcal{B}} \left \\sum_{i=1}\^{\|\\mathcal{K}\^b\|} \\binom{\|\\mathcal{K}\^b\|}{i} \\rightb∈B∏ i=1∑∣Kb∣(i∣Kb∣)
在阶段 3,我们专注于确定每个用户的数据流数量,即决定 yk(t)y_k(t)yk(t) 变量。同时我们也确定 xkb(t)x_k^b(t)xkb(t) 变量。阶段 3 有两个步骤。
- 在步骤 A 中,我们通过允许在不同 RB 上的数据流数量不同,将 yk(t)y_k(t)yk(t) 放宽为一组 ykb(t)y_k^b(t)ykb(t) 。这有效地将问题 OPT-P2B 在不同的 RB 之间解耦。因此,问题 OPT-P2B 被分解为 NP1∣B∣N_{\text{P1}}|\mathcal{B}|NP1∣B∣ 个独立的子问题,表示为 OPT-P3A。现在的 OPT-P3A 是一个小问题,利用大规模并行计算资源,通过检查所有有希望的解就可以很容易地解决。
- 在步骤 B 中,我们解决原始问题 OPT 的可行性(即由于在阶段 3 步骤 A 中放宽 yk(t)y_k(t)yk(t) 而导致的那些不可行解)。这是通过另外 NP1∣K∣N_{\text{P1}}|\mathcal{K}|NP1∣K∣ 个独立的子问题(表示为 OPT-P3B)来完成的。
经过阶段 3 之后,我们得到了 NP1N_{\text{P1}}NP1 组有希望且可行的解作为调度候选者。最后在阶段 4,从 NP1N_{\text{P1}}NP1 个中间最佳解中,选择最好的那个作为问题 OPT 的最终调度方案。
B. Design Details
详细的设计遵循两个原则:
- 探索并行性:分解应该能够生成大量独立的子问题,使其可以适应给定的 GPU 平台。此外,每个子问题应该具有相同的结构,以便我们可以利用 GPU 的单指令多数据流 (SIMD) 架构来实现高效率。
- 寻找最有希望的搜索空间:利用从信道条件和相关性中获得的洞察力,将搜索空间缩减为一个更小但最有希望的区域。
阶段 3-A
对 yk(t)y_k(t)yk(t) 进行松弛后,对于每个 b∈Bb \in \mathcal{B}b∈B ,我们有以下子问题,
OPT-P3A ( ×NP1∣B∣\times N_{\text{P1}}|\mathcal{B}|×NP1∣B∣ )
max∑k∈Kb∑f=1ykb(t)rkb,f,mk∗(t)R~k(t−1)xkb(t)s.t.约束 (2), (8), (9),ykb(t)≤NR,∑k∈Kxkb(t)ykb(t)≤NT. \begin{aligned} \max \quad & \sum_{k \in \mathcal{K}^b} \sum_{f=1}^{y_k^b(t)} \frac{r_k^{b,f,m_k^*}(t)}{\tilde{R}k(t-1)} x_k^b(t) \\ \text{s.t.} \quad & \text{约束 (2), (8), (9)}, \\ & y_k^b(t) \le N{\text{R}}, \\ & \sum_{k \in \mathcal{K}} x_k^b(t) y_k^b(t) \le N_{\text{T}}. \end{aligned} maxs.t.k∈Kb∑f=1∑ykb(t)R~k(t−1)rkb,f,mk∗(t)xkb(t)约束 (2), (8), (9),ykb(t)≤NR,k∈K∑xkb(t)ykb(t)≤NT.
在问题 OPT-P3A 中,对于 ykb(t)y_k^b(t)ykb(t) ,我们总共有 (NR+1)∣Kb∣(N_{\text{R}}+1)^{|\mathcal{K}^b|}(NR+1)∣Kb∣ 种可能性。在实践中, NRN_{\text{R}}NR 通常在 2 到 4 之间。 mCore 将限制 ykb(t)y_k^b(t)ykb(t) 以满足 0≤ykb(t)≤20 \le y_k^b(t) \le 20≤ykb(t)≤2 ,因为在一个用户上发送过多的数据流不太可能提高总速率 6, 7 (一个 RB 上数据流总数的约束与 (4) 保持相同)。那么当 ∣Kb∣=4|\mathcal{K}^b|=4∣Kb∣=4 时, ykb(t)y_k^b(t)ykb(t) 的总可能性数量为 34=813^4 = 8134=81 。 mCore 并行地进行穷举搜索,以评估问题 OPT-P3A 的目标值。请注意, xkb(t)x_k^b(t)xkb(t) 的指派由 ykb(t)y_k^b(t)ykb(t) 隐含决定。也就是说,当 ykb(t)y_k^b(t)ykb(t) 被指派为 0 时,则 xkb(t)=0x_k^b(t) = 0xkb(t)=0 (即,用户 kkk 未被调度在 RB bbb 上);当 ykb(t)y_k^b(t)ykb(t) 被指派为 1 或 2 时,则 xkb(t)=1x_k^b(t) = 1xkb(t)=1 (即,用户 kkk 被调度在 RB bbb 上)。
mCore 通过并行地穷举搜索所有可能的 ykb(t)y_k^b(t)ykb(t) 和 xkb(t)x_k^b(t)xkb(t) 来找到 OPT-P3A 的最优解。我们将 ykb(t)y_k^b(t)ykb(t) 和 xkb(t)x_k^b(t)xkb(t) 的最优解分别记为 ykb∗(t)y_k^{b*}(t)ykb∗(t) 和 xkb∗(t)x_k^{b*}(t)xkb∗(t) 。
阶段 3-B
现在,我们解决如果 xkb∗(t)=xkb′∗(t)=1x_k^{b*}(t) = x_k^{b'*}(t) = 1xkb∗(t)=xkb′∗(t)=1 时,对于 b≠b′b \neq b'b=b′ 产生的 ykb∗(t)≠ykb′∗(t)y_k^{b*}(t) \neq y_k^{b'*}(t)ykb∗(t)=ykb′∗(t) 冲突(即确定最终的 xkb(t)x_k^b(t)xkb(t) 和 yk(t)y_k(t)yk(t) )。我们应用以下启发式方法来确定最终的 xkb(t)x_k^b(t)xkb(t) 和 yk(t)y_k(t)yk(t) 。最终的调度方案将在用户之间独立确定。当我们确定关于用户 kkk 的调度方案时,我们通过令所有的 k′∈K,k′≠k,b∈Bk' \in \mathcal{K}, k' \neq k, b \in \mathcal{B}k′∈K,k′=k,b∈B 的 xk′b(t)=xk′b∗(t)x_{k'}^b(t) = x_{k'}^{b*}(t)xk′b(t)=xk′b∗(t) 且 yk′(t)=yk′b∗(t)y_{k'}(t) = y_{k'}^{b*}(t)yk′(t)=yk′b∗(t) 来固定所有其他用户的解。
然后,我们从那些满足可行性约束的解中,选择出能使 OPT (使用来自阶段 1 的 MCS mk∗m_k^*mk∗ )中的 PF 目标值最大化的 xkb(t)x_k^b(t)xkb(t) 和 yk(t)y_k(t)yk(t) 。记 υ(xkb,yk,{xk′b∗}/xkb∗,{yk′b∗}/ykb∗)\upsilon\left(x_k^b, y_k, \{x_{k'}^{b*}\}/x_k^{b*}, \{y_{k'}^{b*}\}/y_k^{b*}\right)υ(xkb,yk,{xk′b∗}/xkb∗,{yk′b∗}/ykb∗) 为由 xkb(t)x_k^b(t)xkb(t) 、 yk(t)y_k(t)yk(t) 、对所有 k′∈K,k′≠k,b∈Bk' \in \mathcal{K}, k' \neq k, b \in \mathcal{B}k′∈K,k′=k,b∈B 都有 xk′b(t)=xk′b∗(t)x_{k'}^b(t) = x_{k'}^{b*}(t)xk′b(t)=xk′b∗(t) 以及 yk′(t)=yk′b∗(t)y_{k'}(t) = y_{k'}^{b*}(t)yk′(t)=yk′b∗(t) 所实现的 PF 目标值,它可以由下式给出:
υ(xkb,yk,{xk′b∗}/xkb∗,{yk′b∗}/ykb∗)=∑b∈BKb∋k∑f=1yk(t)rkb,f,mk∗(t)R~k(t−1)xkb(t)+∑b∈B∑k′∈Kbk′≠k∑f=1yk′b∗(t)rk′b,f,mk′∗(t)R~k′(t−1)xk′b∗(t).(19) \upsilon\left(x_k^b, y_k, \{x_{k'}^{b*}\}/x_k^{b*}, \{y_{k'}^{b*}\}/y_k^{b*}\right) = \sum_{b \in \mathcal{B}}^{\mathcal{K}^b \ni k} \sum_{f=1}^{y_k(t)} \frac{r_k^{b,f,m_k^*}(t)}{\tilde{R}k(t-1)} x_k^b(t) + \sum{b \in \mathcal{B}} \sum_{k' \in \mathcal{K}^b}^{k' \neq k} \sum_{f=1}^{y_{k'}^{b*}(t)} \frac{r_{k'}^{b,f,m_{k'}^*}(t)}{\tilde{R}{k'}(t-1)} x{k'}^{b*}(t). \tag{19} υ(xkb,yk,{xk′b∗}/xkb∗,{yk′b∗}/ykb∗)=b∈B∑Kb∋kf=1∑yk(t)R~k(t−1)rkb,f,mk∗(t)xkb(t)+b∈B∑k′∈Kb∑k′=kf=1∑yk′b∗(t)R~k′(t−1)rk′b,f,mk′∗(t)xk′b∗(t).(19)
- 顶部的 Kb∋k\mathcal{K}^b \ni kKb∋k:这是一个过滤条件(约束)。它表示我们在遍历 RB 时,只挑出那些,其候选用户集合 Kb\mathcal{K}^bKb 中包含当前目标用户 kkk 的资源块。
注意,第二项是一个常数,因为所有变量都已被固定。唯一的变量是第一项中的 xkb(t)x_k^b(t)xkb(t) 和 yk(t)y_k(t)yk(t) 。为了保证原问题中与 xkb(t)x_k^b(t)xkb(t) 和 yk(t)y_k(t)yk(t) 相关的可行性约束(即约束 (2) 和 (4) ),我们对所有 b∈Bb \in \mathcal{B}b∈B 施加 xkb(t)≤xkb∗(t)x_k^b(t) \le x_k^{b*}(t)xkb(t)≤xkb∗(t) 和 xkb(t)yk(t)≤xkb∗(t)ykb∗(t)x_k^b(t)y_k(t) \le x_k^{b*}(t)y_k^{b*}(t)xkb(t)yk(t)≤xkb∗(t)ykb∗(t) 限制。由于 xkb∗x_k^{b*}xkb∗ 和 ykb∗(t)y_k^{b*}(t)ykb∗(t) 是问题 OPT-P3A 的解,它们必须在任何特定的 RB bbb 上满足可行性约束 (2) 和 (4) 。很容易验证,在施加了这些约束后,这样的 xkb(t)x_k^b(t)xkb(t) 和 yk(t)y_k(t)yk(t) 将会满足 (2) 和 (4) 。形式上,对于每个 k∈Kk \in \mathcal{K}k∈K ,我们有以下优化问题来确定 xkb(t)x_k^b(t)xkb(t) 和 yk(t)y_k(t)yk(t) 。
OPT-P3B ( ×NP1∣K∣\times N_{\text{P1}}|\mathcal{K}|×NP1∣K∣ )
max∑b∈BKb∋k∑f=1yk(t)rkb,f,mk∗(t)R~k(t−1)xkb(t)s.t.约束 (8), (9),xkb(t)≤xkb∗(t),对于所有 b∈B;xkb(t)yk(t)≤xkb∗(t)ykb∗(t),对于所有 b∈B. \begin{aligned} \max \quad & \sum_{b \in \mathcal{B}}^{\mathcal{K}^b \ni k} \sum_{f=1}^{y_k(t)} \frac{r_k^{b,f,m_k^*}(t)}{\tilde{R}_k(t-1)} x_k^b(t) \\ \text{s.t.} \quad & \text{约束 (8), (9)}, \\ & x_k^b(t) \le x_k^{b*}(t), \quad \text{对于所有 } b \in \mathcal{B}; \\ & x_k^b(t)y_k(t) \le x_k^{b*}(t)y_k^{b*}(t), \quad \text{对于所有 } b \in \mathcal{B}. \end{aligned} maxs.t.b∈B∑Kb∋kf=1∑yk(t)R~k(t−1)rkb,f,mk∗(t)xkb(t)约束 (8), (9),xkb(t)≤xkb∗(t),对于所有 b∈B;xkb(t)yk(t)≤xkb∗(t)ykb∗(t),对于所有 b∈B.
- 取消下标 bbb,在数学上强制要求流数统一。
- 组合优化中极其经典的 Relaxation and Projection(松弛与投影) 哲学
- 分配用户数上限(对应约束 2):∑i∈Kxib∗(t)≤NT\sum_{i \in \mathcal{K}} x_i^{b*}(t) \le N_{\text{T}}∑i∈Kxib∗(t)≤NT
- 空间数据流上限(对应约束 4):∑i∈Kxib∗(t)yib∗(t)≤NT\sum_{i \in \mathcal{K}} x_i^{b*}(t)y_i^{b*}(t) \le N_{\text{T}}∑i∈Kxib∗(t)yib∗(t)≤NT
在阶段 1 中,我们有 NP1N_{\text{P1}}NP1 种不同的 MCS 指派。因此,存在 ∣K∣×NP1|\mathcal{K}| \times N_{\text{P1}}∣K∣×NP1 个独立的 OPT-P3B 问题。每个问题都相当简单,因为 yk(t)y_k(t)yk(t) 只有两种可能性,并且 xkb(t)x_k^b(t)xkb(t) 被限制在一个很小的集合内。 mCore 寻找这 ∣K∣×NP1|\mathcal{K}| \times N_{\text{P1}}∣K∣×NP1 个 OPT-P3B 问题的最优解。在这 ∣K∣NP1|\mathcal{K}| N_{\text{P1}}∣K∣NP1 个问题中,每 ∣K∣|\mathcal{K}|∣K∣ 个问题对应于一种 MCS 指派 Siz\mathcal{S}_i^zSiz 。 xkb(t)x_k^b(t)xkb(t) 和 yk(t)y_k(t)yk(t) 的这 ∣K∣|\mathcal{K}|∣K∣ 个解(对应 ∣K∣|\mathcal{K}|∣K∣ 个用户),连同相应的 MCS 指派 Siz\mathcal{S}_i^zSiz ,构成了一个完整的解集。将完整的解集记为 Si=(Six,Siy,Siz)\mathcal{S}_i = (\mathcal{S}_i^x, \mathcal{S}_i^y, \mathcal{S}_i^z)Si=(Six,Siy,Siz) ,其中 Six\mathcal{S}_i^xSix 和 Siy\mathcal{S}_i^ySiy 是对应于(来自阶段 1 的)第 iii 个 MCS 指派 Siz\mathcal{S}i^zSiz 的 xkb(t)x_k^b(t)xkb(t) 和 yk(t)y_k(t)yk(t) 的解。在求解 OPT-P3B 之后, mCore 获得了 OPT 的 NP1N{\text{P1}}NP1 组可行解 S1,S2,⋯ ,SNP1\mathcal{S}1, \mathcal{S}2, \cdots, \mathcal{S}{N{\text{P1}}}S1,S2,⋯,SNP1 。