查询所有macth_all
使用macth_all会默认返回10条数据,原因:_search 查询默认采用的是分页查询,每页记录数size的默认值为10.如果想要显示更多数据,指定size
size 数量,有大小限制,最多只能返回10000条数据
GET /es_db/_search
#等同于
GET /es_db/_search
{
"query":{
"match_all": {}
}
}异常原因
1、查询结果的窗口太大,from+size的结果必须小于10000条
{
"query":{
"match_all":{} // 查询所有
},
"size":10 , // size数量是有限制的,最多返回10000条数据
"from":0 , // 分页,从第几条数据开始,默认为0,就是从第一条数据开始
""
}查询文档
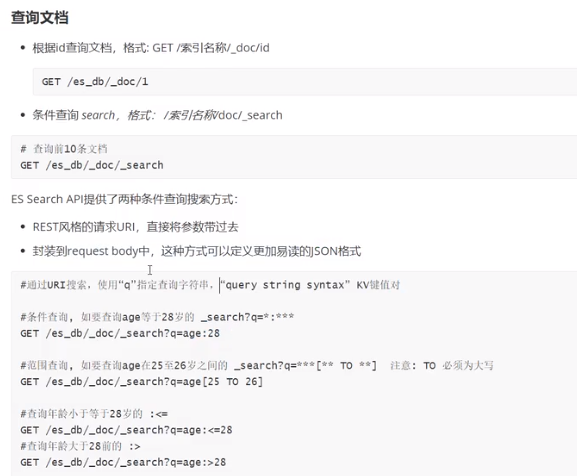

指定字段排序sort
{
"query":{
"match_all":{}
},
"sort":[ // 排序 desc降序、asc升序
//
{
"create_time": {
"order": "asc"
}
},
{
"age": {
"order": "desc"
}
}
]
}
{
"query":{
"match_all":{}
},
"sort":{
"price":{
"order":"desc" //price 降序
}
}
}返回指定字段 _source
{
"query":{
"match_all":{}
},
"_source":["字段名1","字段名2",...]
}match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找,而term会直接对关键词进行查找。一般模糊查找的时候,多用match,而精确查找时可以使用term。
match查询
match在匹配时会对所查的关键词进行分词、然后按分词匹配查找
match支持以下参数:
- query:指定匹配的值
- operator:匹配条件类型
-
- and:条件分词后都要匹配
- or:条件分词后有一个匹配即可(默认)
-
minmum_should_match:最低匹配度,即条件在倒排索引中最低的匹配度
{
"query":{
"match":{
// 只要是带天河公园分词的字符都会匹配到并返回回来
"address":"天河公园"
// address是字段,天河公园就是要查询字段后的内容
}
}
}{
"query":{
"match":{
// "operator":"and" 意思是内容里面必须带有广州公园四个字的分词
"address":{
"query":"广州公园",
"operator":"and"
}
}
}
}{
"query":{
"match":{
"address":{
"query":"广州白云山公园"
"minimum_should_match":2
// minimum_should_match:2意思是必须匹配至少两个分词
// 使用minimum_should_match可以更加精确查找
}
}
}
}
关键词查询term
term用来使用关键词查询(精确匹配),还可以用来查询没有被进行分词的数据类型,term是表达语义的最小的单位,match在匹配时会对所查询的关键及进行分词、然后进行分词匹配查询、而term会直接对关键词进行查找、一般模糊查询的时候用match、精确查找的时候可以使用term
{
"query":{
"term":{
"address":{
"value":"广州白云"
}
}
}
}
#关键词查询term(精确匹配)
PUT /product/_bulk
{"index":{"_id":1}}
{"productId":"xxx123","productName":"iPhone"}
{"index":{"_id":2}}
{"productId":"xxx111","productName":"iPad"}
#思考 查询iPhone 需要.keyword
GET /product/_search
{
"query": {
"term": {
"productName.keyword": {
"value": "iPhone"
}
}
}
}使用query 精确匹配时还会算分 可以通过Constant Score将查询转换成一个Filtering,避免算分,并利用缓存,提高性能
- 将Query转成Filter,忽略TF-IDF计算,避免相关性算分的开销
- Filter可以有效利用缓存
范围查询range
- range 范围关键字
- gte 大于等于
- Ite 小于等于
- gt 大于
- It 小于
- now 当前时间
{
"query":{
// 查找年龄小于等于28 大于等于25
"range":{
"age":{
"gte":25,
"Ite":28
}
}
}
}
#range 年龄大于19 小于30的
POST /es_db/_search
{
"query": {
"range": {
"age": {
"gte": 19,
"lte": 30
}
}
}
}多id查询
# 多id 查询ids ids关键字:值为数组类型,用来根据一组id获取多个对应的文档
GET /es_db/_search
{
"query": {
"ids": {
"values": [1,2]
}
}
}
{
"query":{
"ids":{
"value":[1,2]
}
}
}布尔查询bool Query
一个bool查询,是一个或者多个查询子句的组合。总共包括4种子句,其中两种会影响算分,两种不影响算分
- must:相当于&&,必须匹配
- shoule:相当于|| 选择行匹配
- must_not:相当于!,必须不能匹配
- filter:必须匹配,可以使用缓存
注意:如果你的bool查询中,没有must条件,should中必须满足一条查询
多条件查询:如果要执行多个关键词的and搜索,必须使用布尔查询
{
"query":{
// bool可以组合多个语句
"bool":{
// 如果must里面需要查询多个条件 将must变为数组,里面套着对象的形式存在
"must":{
"match":{
"remark": "java developer"
}
},
// 匹配sex等于1的数据
"filter":{
"term":{
"sex":1
}
},
// 不匹配sex的value等于1的数据
"must_not":[
{
"term":{
"sex":{
"value":1
}
}
},
{
"match":{
"address":"白云山公园"
}
}
]
}
}
}
{
"query":{
"bool":{
"must":[
{
"term":{
"interest":{
"value":"跑步"
}
}
},
{
"term":{
"interest_count":1
}
}
]
}
}
}利用bool嵌套实现should not 逻辑
{
"query":{
"bool":{
"must":{
"match":{
"remark":"javaScript developer"
}
},
"should":[
{
"bool":{
"must_not":[
{
"term":{
"sex":1
}
}
]
}
}
]
}
}
}聚合查询aggs
如果想要对查询结果进行分组或者对查询结果进行统计分析
{ //分组查询
"aggs":{ //聚合操作
"名称":{ // 名称随便起名
"terms":{ // 分组
"field":"price" // 分组字段
}
}
}
}
{ // 求平均值
"aggs":{ //聚合操作
"名称":{ // 名称随便起名
"avg":{ // 平均值
"field":"price" // 分组字段
}
}
}
}
ranage filter
ranage语法: gt : 大于
lt : 小于
gte : 大于等于
lte :小于等于es去重
es去重的属性是cardinality;
--需要注意的是去重存在精度问题;-
-可以通过"precision_threshold": 40000 来增加准确性,需要注意的是值不能超过这个值,超过会不准
{
"aggs":{
"cardinality":{
"field": 去重字段,
"precision_threshold": 40000
}
}}
过滤器filter
bool: {
must: [
{
range: {
应打卡日期: {
lte:
this.changDate.slice(0, 4) +
"-" +
this.changDate.slice(5, 7) +
"-" +
this.changDate.slice(8, 10),
gte: this.add(
this.changDate.slice(0, 4) +
"-" +
this.changDate.slice(5, 7) +
"-" +
this.changDate.slice(8, 10),
n
),
// 时间格式必须得写
format: "yyyy-MM-dd",
time_zone: "+08:00",
},
},
},
{
bool: {
should: [
{
range: {
入职时间: {
lte: this.add(
this.changDate.slice(0, 4) +
"-" +
this.changDate.slice(5, 7) +
"-" +
this.changDate.slice(8, 10),
n
),
format: "yyyy-MM-dd",
time_zone: "+08:00",
},
},
},
{
bool: {
must_not: {
exists: {
field: "入职时间",
},
},
},
},
],
},
},
{
bool: {
should: [
{
bool: {
must_not: {
exists: {
field: "外出开始时间",
},
},
},
},
{
range: {
外出结束时间: {
lt: this.add(
this.changDate.slice(0, 4) +
"-" +
this.changDate.slice(5, 7) +
"-" +
this.changDate.slice(8, 10),
n
),
format: "yyyy-MM-dd",
time_zone: "+08:00",
},
},
},
{
range: {
外出开始时间: {
gt:
this.changDate.slice(0, 4) +
"-" +
this.changDate.slice(5, 7) +
"-" +
this.changDate.slice(8, 10),
format: "yyyy-MM-dd",
time_zone: "+08:00",
},
},
},
],
},
},
],
},短语查询match_phrase
// 因为es在内部对文档进行了分词处理,对于中文来说,就是一个字一个字分的,这个时候想要精确查找就需要使用 match_phrase
{
"query":{
"match_phrase": {
"title": "中国"
}
}
}查询结果过滤
// 之查看name和age连个属性,提高查询效率
{
"query": {
"match": {
"name": "顾"
}
},
"_source": ["name","age"]
}精确查询与模糊查询
- avg:求平均
- max:最大值
- min:最小值
-
sum:求和
// 需求1、查询from为gu的数据,并将age求出平均值
{
"query": {
"match": {
"from": "gu"
}
},
"aggs":{
"my_avg":{
"avg": {
"field": "age"
}
}
},
"size":0,
"_source":["name","age"]
}// 查询年龄的最大值
{
"query": {
"match_all": {}
},
"aggs": {
"my_max": {
"max": {
"field": "age"
}
}
},
"size": 0,
"_source": ["name","age","from"]
}// 查询年龄的最小值
{
"query": {
"match_all": {}
},
"aggs": {
"my_min": {
"min": {
"field": "age"
}
}
},
"size": 0,
"_source": ["name","age","from"]
}// 查询符合条件form为gu的年龄之和
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_sum": {
"sum": {
"field": "age"
}
}
},
"size": 0,
"_source": ["name","age","from"]
}
模糊查询
#模糊查询 使用fuzziness属性来进行模糊查询
#fuzzy 查询会用到两个很重要的参数 fuzziness,prefix_length
GET /es_db/_search
{
"query": {
"fuzzy": {
"address.keyword": {
"value": "北京博物院",
"fuzziness": 2
}
}
}
}es分组查询
// 要查询所有人的年龄段,并且按照15-20,20-25,25-30分组,并且算出每组的平均年龄。
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"age_group": { // 自定义别名
"range": { //range来做分组
"field": "age", // field是以age为分组
"ranges": [
{
"from": 15, // from和to是范围
"to": 20
},
{
"from": 20,
"to": 25
},
{
"from": 25,
"to": 30
}
]
}
}
}
}missing
该属性是根据某个指定的字段聚合返回为空的时候,可以添加一个指定的字符;
--- 比如下面的代码根据'项目负责人'聚合,如果'项目负责人'为空,就默认给一个横杠。
{
"terms":{
"field":"项目负责人",
"missing":"-"
}
}terms和term的区别
1、terms的特点
- 查询某个字段里含有多个关键词的文档
- 相对于term来,terms是在针对一个字段包含多个值的时候使用
-
通俗来说就是term查询一次可以匹配一个条件,terms一个可以匹配多个条件;
{
"query": {
"terms":{
"name": [
"张三"
"李四"
]} } }}
// 以上后面变成了中括号!!!也就是数组传值,表达为name为"张三"或 "李四"
2、term的特点
- term查询是完全匹配
-
term查询不会再进行分词,而是直接去分词库进行完全匹配查询;
{
"query": {
"term": {
"name.keyword": "张三"
}
}
}
POST 和PUT 都能起到创建/更新的作用。PUT需要对一个具体的资源进行操作也就是需要确定id才能进行更新/创建,而POST是可以针对整个资源集合进行操作的,如果不写id就由ES生成一个唯一id进行创建新文档,如果填了id那就针对这个id的文档进行创建/更新。