在大模型Agent面试中,规划能力始终是考察的核心重点。阿里大模型二面抛出的这道题,"在Agent的设计中,规划能力至关重要,请谈谈目前有哪些主流方法可以赋予LLM规划能力?",看似是让我们罗列CoT、ToT、GoT等方法,实则考察的是对Agent核心能力的系统性理解,以及对各类规划方法的演进逻辑、适用场景和工程实践选型的深度认知。很多面试者容易陷入误区,只是简单展开每个方法的定义,却无法讲清它们之间的关联、各自解决的核心问题,以及在实际Agent开发中该如何选择。今天我们就从题目本质出发,一步步拆解赋予LLM规划能力的主流方法,用通俗易懂的语言梳理演进脉络,结合实际场景分析选型逻辑,帮大家彻底吃透这道面试高频题,也能更清晰地理解Agent规划能力的核心价值。
在聊具体方法之前,我们首先要明确一个核心问题,为什么规划能力是Agent的核心竞争力?一个完整的Agent体系,通常包含四大核心模块:感知、规划、记忆和行动。感知负责接收和理解用户需求、外部环境信息,相当于Agent的"眼睛和耳朵";记忆负责存储历史交互信息、中间推理结果和经验教训,相当于Agent的"大脑缓存和知识库";行动负责执行规划好的步骤,完成具体任务,相当于Agent的"手脚";而规划,就是整个Agent的"核心大脑",它决定了Agent面对复杂任务时,该如何将任务拆解成可执行的子步骤,该以什么顺序执行这些步骤,遇到错误或阻碍时该如何调整策略。
如果没有规划能力,LLM就只能停留在普通Chatbot的层面,做简单的"一问一答"式被动应答。用户说什么,它就回应什么,无法处理需要多步骤、多逻辑的复杂任务。比如用户让Chatbot"帮我写一篇关于大模型Agent规划能力的行业分析报告",普通Chatbot可能只会给出一个简单的框架,或者零散的观点,无法系统性地拆解出"确定报告主题、收集行业数据、梳理核心方法、分析应用场景、总结趋势挑战"这些子步骤,更无法规划每个步骤的执行顺序和具体内容。而具备规划能力的Agent,就能清晰地拆解任务、规划流程,一步步推进,最终完成完整的报告。可以说,规划能力是区分普通Chatbot和智能Agent的核心分水岭,也是Agent能够实现"主动思考、自主执行"的关键。
而赋予LLM规划能力的所有主流方法,本质上都是在解决同一个核心问题:如何组织LLM的推理过程,让它能够系统地分解和解决复杂问题。不同方法的核心区别,在于对"推理过程"的结构化程度不同,从最简单的线性链条,到树状分支,再到任意图结构,复杂度逐步递增,适用场景也各不相同。接下来,我们就沿着"推理结构从简单到复杂"的演进脉络,逐一解析这些主流方法,讲清它们的核心逻辑、优势局限,以及实际应用场景。
一、CoT(Chain-of-Thought):线性链式推理,开启LLM规划能力的起点
1.1 CoT的核心逻辑:显式化中间推理步骤
CoT,即思维链,是赋予LLM规划能力的基础方法,也是一切后续进阶方法的起点,由Google在2022年的论文中正式提出。在CoT出现之前,我们与LLM的交互方式大多是"直接提问、直接要答案",也就是所谓的标准提示法。比如我们问LLM:"Roger有5个网球,又买了2罐,每罐3个,他现在有多少个网球?",普通LLM会直接输出"11"这个答案。这种方式对于简单的、单步骤的问题完全够用,但遇到需要多步推理的复杂问题,就很容易出错。因为LLM被迫在一次前向传播中完成所有推理和计算,中间没有任何缓冲,一旦某个环节出现偏差,最终答案就会出错。
CoT的核心洞察非常简单却极具突破性:让LLM把中间推理步骤显式地写出来,而不是直接输出最终答案。还是刚才那个网球的问题,加入CoT提示后,LLM会输出:"Roger一开始有5个网球,他买了2罐网球,每罐有3个,那么2罐网球的总数就是2乘以3等于6个。接下来把一开始有的5个和新买的6个加起来,5加6等于11个,所以他现在有11个网球。" 看似只是多了几句中间推理的话,但效果提升却非常显著。因为每一步的中间结果,都会成为下一步推理的"垫脚石",把复杂的多步推理,拆解成一个个简单的单步推理,大幅降低了LLM的推理难度,也减少了出错的概率。
1.4 CoT线性推理流程架构图
接收用户问题
LLM启动CoT推理
步骤1:显式推理中间过程1
步骤2:基于中间结果推理中间过程2
...依次推进
步骤N:得出最终答案
上图清晰呈现了CoT的线性推理流程,整个过程单向推进,无分支、无回溯,每一步推理都依赖上一步的中间结果,结构简单且高效,适合简单多步推理任务。
1.2 CoT的两种触发方式:少样本与零样本
在实际使用中,CoT主要有两种触发方式,操作都非常简单。第一种是少样本思维链,也就是在提示词中,给LLM几个带完整推理过程的示例,让LLM模仿这种推理风格,进而对新问题进行逐步推理。比如我们想让LLM解决数学应用题,就可以先给出2-3道类似的应用题,每道题都附上详细的解题步骤和推理过程,LLM就能快速学会这种"一步一步思考"的方式。第二种是零样本思维链,这种方式更简单粗暴,不需要提供任何示例,只需要在问题的末尾加上一句"让我们一步一步思考",LLM就能自动展开推理链,显式地输出中间步骤。这也说明,LLM本身就具备逐步推理的能力,CoT只是通过提示词的方式,把这种潜在能力激活了。
1.3 CoT的局限与适用场景
虽然CoT开启了LLM规划能力的大门,在多步推理任务中表现出了远超标准提示法的效果,但它也存在一个本质的局限:推理过程是单条链路的、线性的,并且不可回退。也就是说,LLM从第一步推理开始,一步接一步地往下推进,一旦中间某一步推理出错,后面所有的步骤都会跟着出错,没有任何"纠错"或者"换一条路试试"的机制。比如一道数学题,CoT推理到第二步时计算错误,那么后续的所有计算都会基于这个错误的结果,最终得出错误的答案,而且无法自行发现和修正这个错误。
这种局限决定了CoT只适用于那些只有一条正确推理路径、步骤相对简单的任务,比如简单的数学计算、基础的逻辑推理、短文本的分析总结等。对于那些有多种可能解法、需要灵活调整推理方向的复杂任务,CoT就显得力不从心了。也正是因为这个局限,后续的研究者们才在CoT的基础上,不断迭代优化,提出了更具灵活性和鲁棒性的规划方法。
二、Self-Consistency(自洽性采样):多条链路投票,提升推理鲁棒性
2.1 Self-Consistency的核心思路与执行步骤
在CoT的基础上,研究者们提出了一个非常自然的改进思路:既然一条推理链路可能会走错,那我们就多生成几条不同的推理链路,最后通过投票的方式,选择最靠谱的答案。这就是Self-Consistency,即自洽性采样方法,它的核心目标是解决CoT"一条路走到黑"的局限,提升LLM推理的鲁棒性。
Self-Consistency的具体做法非常清晰,主要分为三个步骤。第一步,针对同一个问题,使用CoT的方式,让LLM生成多条不同的推理链路。这里需要注意的是,为了让每条推理链路都有所不同,我们需要调高LLM的温度参数,引入一定的随机性,这样LLM才会在推理过程中选择不同的中间步骤和表达方式。第二步,收集每条推理链路得出的最终答案,统计所有答案的出现次数。第三步,将出现次数最多的答案作为最终输出,也就是"少数服从多数"的投票原则。
2.4 Self-Consistency多链路投票流程架构图
接收用户问题
调高温度参数,生成多条CoT推理链路
链路1:CoT推理→答案1
链路2:CoT推理→答案2
链路N:CoT推理→答案N
收集所有答案,统计票数
票数最多的答案作为最终输出
该架构图体现了Self-Consistency"多链路生成+投票筛选"的核心逻辑,通过多条独立CoT链路的冗余推理,结合投票机制提升答案的鲁棒性,弥补了单一CoT链路易出错的缺陷。
2.2 Self-Consistency的优势的与实际应用
这个方法的直觉的来自于人类的解题经验:如果我们用三种不同的方法解一道数学题,三种方法都得到了同一个答案,那么这个答案大概率是正确的;如果其中两种方法得到了同一个答案,另一种方法得到了不同的答案,那么我们会更倾向于相信出现两次的答案。Self-Consistency正是利用了这种统计规律,通过多条独立推理链路的投票,来降低单条链路出错的概率,提升推理结果的可靠性。
2.3 Self-Consistency的局限:链路独立无交互
在实际应用中,Self-Consistency在数学推理、常识推理、逻辑推理等任务上表现出了非常好的效果。比如在复杂的数学应用题中,CoT可能会因为一步计算错误导致最终答案出错,而Self-Consistency通过生成10条甚至20条推理链路,其中大部分链路都会得出正确答案,通过投票就能筛选出正确结果,大幅降低了出错的概率。而且它的实现非常简单,只需要在CoT的基础上增加多轮采样和投票环节,不需要对LLM本身进行微调,成本很低。
但Self-Consistency也存在明显的局限:多条推理链路之间是完全独立的,不会互相交流信息,也不会共享中间推理结果。也就是说,如果第一条推理链路在中间步骤发现了一个关键线索,或者找到了一种更优的推理思路,第二条、第三条推理链路在推理过程中完全无法利用这个线索和思路,还是会闷头自己推进,相当于重复做了很多无用功。这种"各自为战"的模式,不仅浪费了计算资源,也限制了推理能力的进一步提升。理想情况下,我们希望不同的推理路径之间能够互相启发、共享信息,让推理过程更高效、更精准。
正是为了解决这个问题,Tree-of-Thought(ToT)方法应运而生,它将LLM的推理过程从"单条链"升级为"树状结构",实现了推理过程的可回溯、可探索。
三、ToT(Tree-of-Thought):树状分支探索,实现可控的推理搜索
3.1 ToT的核心思想:打破线性,构建树状推理结构
ToT,即思维树,由Yao等人在2023年的论文中正式提出,它的核心思想是打破CoT的线性限制,将推理过程从一条链变成一棵树,在推理的每一步都生成多个分支候选,然后通过自我评估选择最有希望的分支继续探索,必要时还可以回溯到之前的节点,换一条分支重新推进。简单来说,ToT就是让LLM学会"多想想、多试试",而不是"一条路走到黑"。
3.2 ToT的四大工作流程(结合实例解析)
ToT的工作流程主要分为四个核心步骤,我们可以结合一个具体的例子来理解。假设我们让LLM解决一个24点游戏问题:给定4个数字1、3、5、7,用加减乘除四种运算,每个数字只能用一次,组合成24。
第一步,生成思维节点。在推理的每一步,LLM会生成多个可能的推理方向,也就是多个"思维节点"。比如在第一步,LLM可能会生成三个候选节点:第一个是1+3=4,第二个是3×5=15,第三个是7-5=2。每个节点都代表一种可能的推理方向,相当于树的一个分支。
第二步,自我评估。LLM会对每个候选节点进行自我评估,判断每个推理方向的前景如何,是"很有希望接近24""有可能接近24"还是"肯定无法得到24"。比如对于第一步生成的三个节点,LLM会评估:1+3=4,后续需要用5和7组合出6(4×6=24),但5和7无法通过加减乘除得到6,所以这个节点的前景较差;3×5=15,后续需要用1和7组合出9(15+9=24),1和7可以通过7+1=8,接近9,前景中等;7-5=2,后续需要用1和3组合出12(2×12=24),1和3可以通过3×4,但没有4,不过可以通过(1+3)×2=8,不对,再想想,(3-1)×2=4,也不对,哦,不对,7-5=2,然后1+3=4,2×4=8,不对,等等,可能LLM会重新评估,发现7-5=2,后续用1和3组合出12确实有难度,但3×5=15,后续1+7=8,15+8=23,差1,或者7-1=6,15+6=21,也差一点,但比第一个节点好,而还有一个可能的节点是5+7=12,后续用1和3组合出2(12×2=24),1和3可以通过3-1=2,这个前景就很好。
第三步,分支选择与探索。基于自我评估的结果,系统会选择最优的一个或几个节点继续往下展开,形成新的分支。比如刚才的例子中,LLM评估出"5+7=12"这个节点前景最好,就会以这个节点为基础,继续生成下一步的候选节点:12×(3-1)=24,或者12×3-1=35,等等。然后再对这些新的节点进行评估,选择最优的分支继续探索。
第四步,回溯。如果某个分支推着推着发现走不通了,比如LLM选择了"3×5=15"这个分支,后续无论怎么组合1和7,都无法得到24,这时候就会回溯到上一个节点,换一个前景较好的分支重新探索,比如换成"5+7=12"这个分支,继续推进,直到找到正确的答案。
3.5 ToT树状推理流程架构图
前景优
前景差
接收用户问题(如24点游戏)
生成初始思维节点(多个候选分支)
自我评估各节点前景
评估结果
选择最优节点,展开新分支
舍弃该分支,回溯至上一节点
生成新的思维节点,重复评估
探索至终点,得出正确答案
上图完整呈现了ToT的树状探索流程,核心包含"生成节点-自我评估-分支选择-回溯"四大环节,打破了线性推理的局限,通过树状分支和回溯机制,实现了多路径的灵活探索。
3.3 ToT的优势与适用场景
从这个例子可以看出,ToT的本质是将LLM的推理过程,转化成了一个可控的搜索问题,我们可以用经典的搜索算法,比如广度优先搜索(BFS)来逐层展开所有可能的分支,全面探索所有推理方向;也可以用深度优先搜索(DFS)来沿着一个有希望的分支深入探索,走不通再回头。这种模式,完美解决了CoT"一条路走到黑"和Self-Consistency"多条路互不相干"的局限,让LLM的推理过程更具灵活性和可控性。
3.4 ToT的局限:分支隔离无聚合
ToT的优势不仅体现在24点游戏这种逻辑推理任务上,在其他复杂任务中也表现出了强大的能力,比如创意写作、代码调试、复杂问题分析等。比如创意写作中,LLM可以生成多个写作方向(分支),评估每个方向的可行性和吸引力,选择最优的方向继续写作,写不下去的时候可以回溯,换一个方向重新构思。在代码调试中,LLM可以生成多个可能的bug原因(分支),逐一排查,找到真正的问题所在。
但ToT也有它的局限,它的推理结构虽然是树状的,但仍然存在层级限制,信息只能从父节点流向子节点,不同分支之间仍然是隔离的,无法实现中间信息的共享和聚合。而在很多实际的复杂推理场景中,我们需要将多个分支的中间结论汇总合并,形成一个新的结论,这种"先发散、再收敛"的模式,ToT是无法实现的。于是,Graph-of-Thought(GoT)方法应运而生,它将推理结构从"树"升级为"图",实现了更自由、更复杂的推理。
四、GoT(Graph-of-Thought):图结构自由推理,实现思维的聚合与收敛
4.1 GoT的核心突破:从树状到图状,新增思维聚合能力
GoT,即思维图,由Besta等人在2023年提出,它是在ToT的基础上,进一步打破了树结构的层级限制,允许推理节点之间形成更自由、更复杂的连接关系,本质上是一张任意有向图。如果说CoT是一条线,ToT是一棵树,那么GoT就是一张网,它让LLM的推理过程变得更加灵活,能够实现思维的发散与收敛,处理更复杂的推理任务。
GoT相比ToT,最关键的新增能力是"思维聚合"(Aggregation)。在ToT的树结构中,信息只能从父节点流向子节点,不同分支之间是完全隔离的,无法共享中间结论。而在GoT中,通过引入聚合操作,允许多个思维节点的输出合并成一个新节点的输入,形成类似有向无环图(DAG)甚至包含环路的图结构。这种聚合能力,让LLM能够实现"先发散、再收敛"的推理模式,这也是GoT最核心的突破。
4.2 GoT的推理模式(结合实例解析)
我们可以结合一个实际的例子,来理解GoT的聚合能力。假设我们让LLM分析一篇长篇行业报告,核心任务是总结报告的核心观点,并分析行业未来的发展趋势。这个任务如果用ToT来处理,LLM可能会生成多个分支,分别提取报告各个章节的关键信息,但这些分支之间是隔离的,无法将各个章节的关键信息汇总起来,形成一个全局的核心观点。而用GoT来处理,整个推理过程会是这样的:
第一步,发散生成分支。LLM会生成多个思维节点,每个节点负责提取报告一个章节的关键信息,比如节点1提取第一章的行业现状,节点2提取第二章的市场规模,节点3提取第三章的竞争格局,节点4提取第四章的技术趋势,节点5提取第五章的政策影响。这一步和ToT的发散过程类似,都是生成多个分支,探索不同的推理方向。
第二步,聚合形成新节点。LLM会将节点1到节点5的输出进行聚合,合并成一个新的节点------"行业核心信息汇总",这个新节点包含了报告所有章节的关键信息,是对各个分支中间结论的汇总和整合。这一步是ToT无法实现的,也是GoT的核心优势,它让不同分支的信息能够互相融合,形成更全面、更系统的中间结论。
第三步,收敛推理得出结论。基于"行业核心信息汇总"这个聚合节点,LLM再进一步推理,生成"行业核心观点"和"未来发展趋势"两个节点,最终完成整个任务。整个过程是"先发散(提取各章节信息)、再收敛(汇总核心信息)、再推理(得出最终结论)",完美契合复杂任务的推理逻辑。
4.4 GoT图状推理流程架构图
接收复杂任务(如多文档分析)
发散生成分支节点(多维度推理)
节点1:提取章节1信息
节点2:提取章节2信息
节点N:提取章节N信息
聚合操作:汇总所有分支中间结果
收敛推理:生成全局核心结论
输出最终结果
该架构图突出了GoT的核心优势------聚合能力,通过"发散生成-聚合汇总-收敛推理"的流程,实现了不同分支信息的融合,打破了树状结构的层级隔离,适配多源信息融合类复杂任务。
4.3 GoT的优势、局限与应用前景
从图论的角度来看,CoT是一条路径(Path),ToT是一棵树(Tree),GoT是一张图(Graph)。路径是树的特例,树是图的特例,所以GoT在理论上的表达能力是最强的,它能够处理任何复杂的推理场景,尤其是那些需要多源信息融合、多方向发散再收敛的任务,比如多文档摘要、多源数据分析、复杂决策制定等。
但表达能力强也意味着控制复杂度更高。GoT的推理空间是任意有向图,搜索空间比ToT大得多,需要更精细的调度策略和评估机制,否则很容易出现推理混乱、效率低下的问题。目前,GoT在工程中的应用还相对较少,更多停留在研究阶段,但它的聚合思想,对Agent规划能力的发展具有重要的启发意义,尤其是在处理复杂的多源信息融合任务时,GoT的优势会更加明显。随着技术的不断迭代,GoT未来有望成为复杂Agent规划的核心方法。
五、其他重要的规划方法:工程实践中的核心补充
除了上面这条"链→树→图"的主流演进线之外,在实际的Agent工程实践中,还有几种非常重要的规划方法,它们不局限于"推理结构"的优化,而是从"流程设计""经验学习""混合协同"的角度,赋予LLM更强的规划能力,也是面试中经常会问到的重点,我们逐一梳理。
(一)Plan-and-Execute(规划-执行分离):工程实践中的高效策略
Plan-and-Execute,即规划-执行分离,是一种偏工程实践的规划策略,它的核心思路是将Agent的规划和执行拆分成两个独立的阶段,各司其职、互相配合,避免规划过程被执行细节干扰,提升任务执行的效率和稳定性。
具体来说,Plan-and-Execute包含两个核心模块:Planner(规划器)和Executor(执行器)。Planner由LLM担任,负责对用户的复杂任务进行全局规划,输出一个完整的、可执行的步骤清单,这个步骤清单需要明确每个步骤的目标、执行顺序和注意事项,不需要关注具体的执行细节。Executor也由LLM担任,负责按照Planner输出的步骤清单,逐步执行每个步骤,在执行过程中处理具体的细节问题,遇到无法解决的问题时,反馈给Planner,由Planner调整规划步骤,再由Executor继续执行。
比如用户让Agent"帮我写一篇关于大模型Agent规划能力的行业分析报告,要求包含核心方法、应用场景和未来趋势,字数不少于2000字"。Planner会先进行全局规划,输出步骤清单:1. 确定报告的整体框架,分为引言、核心规划方法、应用场景、未来趋势、总结五个部分;2. 收集大模型Agent规划能力的相关行业数据和案例;3. 梳理各核心规划方法的原理、优势和局限;4. 分析规划能力在不同行业的应用场景和落地案例;5. 预测未来规划能力的发展趋势和挑战;6. 整合所有内容,撰写完整报告,调整语言和结构,确保字数达标。
然后Executor会按照这个步骤清单,逐步执行:先搭建报告框架,再收集相关数据,然后逐一撰写每个部分的内容,最后整合优化。如果在执行过程中,比如收集数据时发现某类方法的行业案例不足,Executor会反馈给Planner,Planner会调整规划步骤,再由Executor继续执行。
5.1 Plan-and-Execute规划-执行分离流程架构图
无问题
有问题
接收用户复杂任务
Planner(规划器):全局规划,输出步骤清单
Executor(执行器):按步骤执行具体操作
执行是否遇到问题
继续执行下一步骤,直至完成
反馈问题给Planner
Planner调整规划步骤
输出最终任务结果
上图清晰展示了Plan-and-Execute"规划与执行分离"的核心架构,Planner专注全局规划,Executor专注步骤执行,两者通过反馈机制联动,确保任务高效、稳定推进,适配步骤繁琐、逻辑确定的任务。
Plan-and-Execute的优势非常明显:它将规划和执行解耦,Planner可以纵览全局,专注于任务的整体拆解和步骤规划,不会被执行过程中的细节干扰;Executor可以专注于具体步骤的执行,处理细节问题,提升执行效率。这种方法适合那些步骤较多、逻辑相对确定,但细节较为繁琐的任务,比如行业报告撰写、复杂流程自动化、多步骤数据处理等。目前,LangChain和LangGraph等主流Agent开发框架中,都有对应的Plan-and-Execute Agent实现,开发者可以直接调用,大幅降低了Agent的开发成本。
(二)Reflexion(反思机制):让Agent从失败中学习
Reflexion,即反思机制,是在Plan-and-Execute的基础上,加入了"复盘"环节,赋予Agent从失败中学习的能力,让Agent能够不断优化规划策略,避免重复犯同样的错误,相当于人类的"吃一堑长一智"。
在没有反思机制的Agent中,当任务执行失败后,Agent只会简单地重试,或者直接放弃,无法总结失败的原因,下次遇到类似的任务,仍然可能犯同样的错误。而具备Reflexion机制的Agent,在任务执行失败后,会先进入"反思阶段",回顾整个推理和执行过程,总结出"哪里做错了、为什么会做错、下次应该怎么改进"的经验教训,然后把这些反思内容存入Agent的记忆模块,在下一次尝试执行类似任务时,参考这些经验教训,调整规划和执行策略,避免重复犯错。
举个例子,假设Agent需要完成"帮用户预订一张从北京到上海的高铁票,要求是明天上午的车次,价格不超过500元"。第一次执行时,Agent可能因为没有确认高铁票的预售时间,导致预订失败。这时候,Reflexion机制会启动,Agent会反思:"本次预订失败的原因是没有确认高铁票的预售时间,明天的车票可能已经售罄,或者预售时间还没到。下次预订时,应该先查询高铁票的预售时间,确认有票后再进行预订,同时可以设置价格提醒,确保价格不超过500元。" 然后把这些反思内容存入记忆。
下次用户让Agent预订类似的高铁票时,Agent会从记忆中提取之前的反思经验,先查询预售时间,确认有票后,再筛选价格不超过500元的车次,完成预订,避免了再次因为预售时间的问题导致失败。
5.2 Reflexion反思机制流程架构图
成功
失败
接收任务,启动规划执行
重新执行任务
任务是否成功
输出结果,任务结束
反思阶段:总结失败原因、改进建议
将反思内容存入记忆模块
基于记忆中的反思经验,调整规划策略
该架构图体现了Reflexion"执行-反思-记忆-优化"的闭环逻辑,核心是通过失败后的反思总结,将经验存入记忆,指导后续规划优化,实现Agent的持续自我提升。
Reflexion的核心价值,在于让Agent具备了"持续改进"的能力,它不需要人类手动干预,就能通过自我反思,不断优化规划和执行策略,适应复杂多变的任务场景。这种方法适合那些需要Agent长期运行、持续处理类似任务的场景,比如智能客服、自动化运维、长期任务管理等。随着Agent应用场景的不断拓展,Reflexion机制也越来越成为Agent规划能力的核心组成部分。
(三)LLM+P(LLM + 经典规划器):混合协同,兼顾灵活性与严谨性
LLM+P,即LLM与经典规划器结合的混合方法,它的核心思路是将LLM的自然语言理解能力,与经典AI规划算法(如PDDL规划器)的严格推理能力结合在一起,取长补短,兼顾推理的灵活性和严谨性。
我们知道,LLM的优势在于自然语言理解和灵活推理,能够轻松处理模糊的、非结构化的自然语言需求,但它的推理过程不够严谨,容易出现逻辑错误,尤其是在需要严格逻辑保证的任务中,可靠性不足。而经典AI规划算法,比如PDDL(规划领域定义语言)规划器,具有严格的逻辑推理能力,能够基于结构化的问题描述,求解最优的行动序列,推理过程严谨、可靠,但它无法处理非结构化的自然语言需求,只能接受结构化的输入。
LLM+P的混合方法,就是让两者各司其职、协同工作,具体流程分为三个步骤:第一步,LLM负责接收用户的自然语言需求,将其转化为结构化的规划问题描述,也就是PDDL格式的描述,这个过程主要利用LLM的自然语言理解能力,将模糊的需求转化为严谨的结构化信息;第二步,将PDDL格式的问题描述交给经典规划器,由经典规划器求解最优的行动序列,这个过程利用经典规划器的严格推理能力,确保行动序列的逻辑性和最优性;第三步,LLM再将经典规划器输出的最优行动序列,翻译成自然语言,返回给用户,让用户能够轻松理解。
这种混合方法的优势非常明显,它既解决了经典规划器无法处理自然语言需求的问题,又解决了LLM推理不够严谨的问题,兼顾了灵活性和严谨性。它的适用场景主要是那些需要严格逻辑保证的任务,比如机器人路径规划、自动化流程调度、复杂任务的最优路径求解等。比如在机器人路径规划中,用户用自然语言说"让机器人从客厅走到卧室,避开障碍物,最快到达",LLM会将这个需求转化为PDDL格式的问题描述,经典规划器会基于机器人的位置、障碍物的位置,求解最优的路径,然后LLM再将路径翻译成自然语言,告诉机器人"先直走5米,再左转3米,避开沙发,然后直走4米到达卧室"。
5.3 LLM+P混合协同流程架构图
用户自然语言需求
LLM:将自然语言转化为结构化PDDL描述
经典规划器(如PDDL规划器):基于PDDL求解最优行动序列
LLM:将最优行动序列翻译成自然语言
输出最终结果(可执行指令/答案)
上图呈现了LLM+P的混合协同流程,LLM负责自然语言与结构化描述的转换,经典规划器负责严格逻辑推理,两者各司其职、优势互补,兼顾了推理的灵活性和严谨性。
目前,LLM+P的混合方法在机器人、自动化、工业控制等领域应用较为广泛,它充分发挥了LLM和经典规划器的优势,让Agent的规划能力既灵活又严谨,满足了复杂场景下的规划需求。
六、工程选型思考:从简单到复杂,按需升级
6.1 选型核心原则:拒绝盲目复杂,按需循序渐进
聊完了所有主流的规划方法,我们回到面试的核心问题------在实际的Agent开发中,该如何选择这些规划方法?很多面试者在回答这道题时,容易陷入"追求复杂"的误区,认为方法越复杂,效果越好,其实不然。在工程实践中,选型的核心原则是"按需选择、循序渐进",先用最简单的方法跑通任务,再根据效果瓶颈,针对性地升级方法,因为复杂度本身就是成本,不仅是计算成本,还有工程维护成本和调试难度。
6.2 分场景选型指南(附实操建议)
聊完了所有主流的规划方法,我们回到面试的核心问题------在实际的Agent开发中,该如何选择这些规划方法?很多面试者在回答这道题时,容易陷入"追求复杂"的误区,认为方法越复杂,效果越好,其实不然。在工程实践中,选型的核心原则是"按需选择、循序渐进",先用最简单的方法跑通任务,再根据效果瓶颈,针对性地升级方法,因为复杂度本身就是成本,不仅是计算成本,还有工程维护成本和调试难度。
我们结合不同的任务场景,梳理一下具体的选型思路,帮助大家在面试中能够清晰地阐述选型逻辑,也能在实际开发中少走弯路。
第一种场景,常规的简单多步推理任务,比如简单的数学计算、短文本分析、基础逻辑推理等。这类任务只有一条正确的推理路径,步骤相对简单,不需要复杂的探索和回溯。此时,CoT配合ReAct框架就完全够用了。ReAct框架能够让Agent"思考-行动-观察"循环,配合CoT的线性推理,既简单高效,又能保证推理的准确性,而且延迟低、成本低,是大多数常规场景的首选。
第二种场景,复杂的多步推理任务,存在多种可能的解题路径,需要灵活探索和回溯,比如24点游戏、复杂数学应用题、创意写作、代码调试等。这类任务CoT无法满足需求,Self-Consistency虽然能提升鲁棒性,但效率较低,此时ToT是更好的选择。ToT通过树状分支探索和自我评估,能够高效地探索最优的推理路径,走不通还能回溯,兼顾了灵活性和效率,是复杂推理任务的核心选型。
第三种场景,需要多源信息融合、先发散再收敛的复杂任务,比如多文档摘要、多源数据分析、复杂决策制定等。这类任务需要将多个分支的中间信息进行聚合,形成全局结论,ToT的树结构无法实现,此时可以考虑GoT。虽然GoT目前工程应用较少,但它的聚合思想能够很好地满足这类任务的需求,适合在研究型项目或高复杂度的场景中尝试使用。
第四种场景,步骤较多、逻辑相对确定,但细节繁琐的任务,比如行业报告撰写、复杂流程自动化、多步骤数据处理等。这类任务的核心是"全局规划+分步执行",需要避免规划被执行细节干扰,此时Plan-and-Execute是最优选择。它将规划和执行解耦,便于分别优化和调试,在企业级应用中非常实用,也是工程实践中使用频率很高的方法。
第五种场景,需要Agent长期运行、持续处理类似任务,需要不断优化规划策略的场景,比如智能客服、自动化运维、长期任务管理等。这类场景需要Agent具备从失败中学习的能力,此时Reflexion机制是必不可少的。可以将Reflexion与Plan-and-Execute结合,让Agent在规划执行的过程中,不断反思总结,持续改进,提升长期运行的稳定性和效率。
第六种场景,需要严格逻辑保证的任务,比如机器人路径规划、自动化流程调度、复杂任务的最优路径求解等。这类任务对推理的严谨性要求很高,LLM的单独推理无法满足需求,此时LLM+P的混合方法是最佳选择。它结合了LLM的自然语言理解能力和经典规划器的严格推理能力,兼顾灵活性和严谨性,能够满足这类场景的需求。
6.4 主流规划方法选型流程架构图
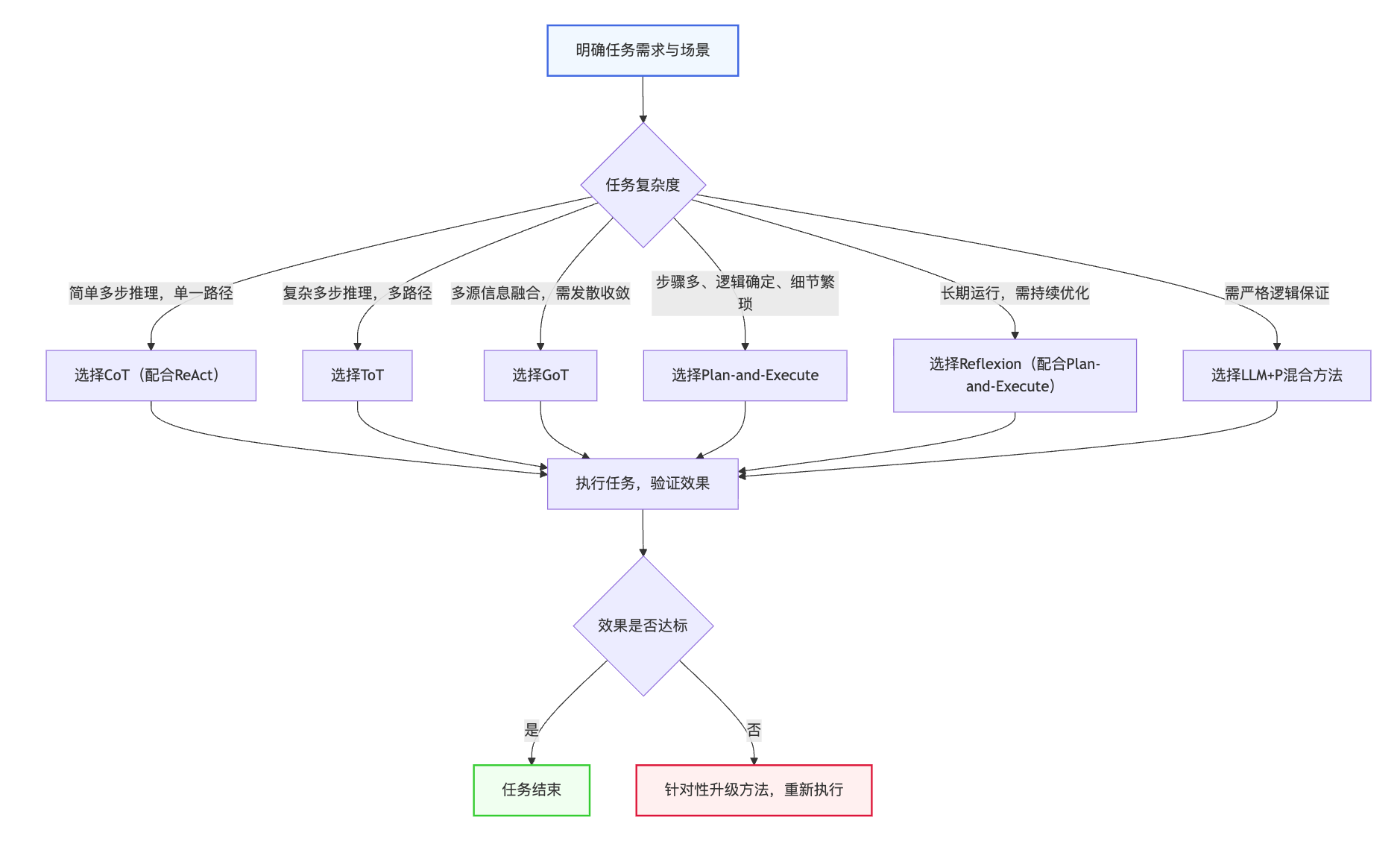
该选型架构图整合了所有主流方法的适用场景,形成"场景判断-方法选择-效果验证-优化迭代"的完整流程,为实际Agent开发中的规划方法选型提供了清晰的实操指引。
6.3 选型经验总结:先跑通再优化
总结一下,工程选型的经验性原则是:"先简单后复杂,先跑通再优化"。不要一上来就用最复杂的方法,比如GoT,因为它的控制复杂度高,工程维护成本高,而且很多场景下,简单的CoT或Plan-and-Execute就能满足需求。正确的做法是,先根据任务场景,选择最简单、最适合的方法,跑通整个任务流程,然后通过测试,发现效果瓶颈,比如推理准确率不高、无法处理多路径推理、无法从失败中学习等,再针对性地升级方法,比如从CoT升级到ToT,从Plan-and-Execute升级到Reflexion+Plan-and-Execute,这样既能保证任务效果,又能控制开发成本和复杂度。
七、面试答题思路总结
7.1 答题核心框架:三层递进,突出逻辑与实践
回到阿里大模型二面的这道题,我们可以梳理出清晰的答题思路,帮助大家在面试中脱颖而出。答题的核心不是罗列方法,而是讲清"演进逻辑+核心价值+选型思路",具体可以分为三个层次:
7.2 答题细节拆解:每个层次的重点的表达
回到阿里大模型二面的这道题,我们可以梳理出清晰的答题思路,帮助大家在面试中脱颖而出。答题的核心不是罗列方法,而是讲清"演进逻辑+核心价值+选型思路",具体可以分为三个层次:
第一层,开篇点题,说明规划能力在Agent中的核心地位。先解释Agent的四大核心模块,强调规划能力是Agent的"核心大脑",是区分普通Chatbot和智能Agent的分水岭,然后点明赋予LLM规划能力的核心本质------组织LLM的推理过程,解决复杂任务的分解和执行问题。
第二层,梳理主流方法的演进脉络,讲清彼此的关联和优劣。沿着"链→树→图"的主线,依次讲解CoT、Self-Consistency、ToT、GoT,每个方法重点讲"核心逻辑、解决的问题、优势局限",让面试官看到你对方法的深度理解,而不是简单的记忆。然后补充Plan-and-Execute、Reflexion、LLM+P这三种工程实践中的重要方法,说明它们的适用场景,体现你的工程思维。
第三层,结合工程实践,阐述选型思路。强调"先简单后复杂,按需升级"的原则,结合不同的任务场景,说明每种方法的选型逻辑,体现你的实践能力和思考深度,让面试官知道你不仅懂理论,还能在实际开发中灵活运用。
7.3 答题收尾:总结升华,体现思维深度
最后,我们可以用一段简洁的话,总结所有方法的核心价值:无论是CoT的线性推理,ToT的树状探索,还是GoT的图状聚合,无论是Plan-and-Execute的解耦策略,还是Reflexion的反思学习,本质上都是为了让LLM能够更系统、更灵活、更高效地处理复杂任务,赋予Agent真正的"思考能力"。而在实际开发中,没有最好的方法,只有最适合的方法,按需选型、循序渐进,才能打造出高效、稳定的智能Agent。
通过这样的答题思路,既能展现你的理论功底,又能体现你的工程思维和面试准备的充分性,轻松应对阿里大模型二面的这道高频题。同时,也能帮助我们更系统地理解LLM规划能力的核心,为后续的Agent开发和学习打下坚实的基础。