1. 运维需求
SeaweedFS 是一个开源的分布式文件系统,专为高效处理海量小文件设计,具备高可用性、可扩展性和高性能的特点。
https://github.com/chrislusf/seaweedfs
我的安装目录:/opt/seaweedfs
test@sfs8:/opt/seaweedfs$ ls
bin conf
test@sfs8:/opt/seaweedfs$ ls bin
weed
test@sfs8:/opt/seaweedfs$ ls conf
master.conf volume.conf
seaweedfs集群主要用来存储所有业务系统的图片文件和视频文件。
**问题1:**集合列表能查询吗?可以。
**问题2:**卷ID列表能查询吗?可以。
**问题3:**文件ID(fid)列表能查询吗?不可以。
**运维需求:**业务系统数据库MySQL中,一些业务数据删除了,但是当时没有相应删除掉seaweedfs集群中的图片文件,有时运维人员因为紧急释放表空间就直接按时间点删除表数据记录了,导致现在根本不知道哪些文件失去联系了,七八年来积累的垃圾文件也不少,主要是目前seaweedfs集群磁盘空间已经比较紧张了,目前的市场情况基本没有新项目,故增加硬件设备是不可能的,只能全面清理垃圾文件。
解决方案:
1)清理掉哪些无主的垃圾文件,主要是多年来各种原因删除了数据库表中记录,但没有同步删除seaweedfs集群中的文件;业务系统一贯以来是业务模块对应集合collection,所以要查询出集合collection下所有文件fid,然后去集合对应的业务系统表比对,如果已经不存在这样的fid,则是需要删除的文件。
2)按业务数据的某个时间字段,删除掉N个月以前的业务流水记录,同步删除seaweedfs集群中的文件。
难点:
上面讲的第1)点,需要找到具体哪些文件fid是没有业务系统引用的,势必要从seaweedfs集群中扫描出所有fid列表,刚开始以为非常简单,后来发现seaweedfs集群根本没提供从collection集合查询接口。
注意:我们没有启动filer服务,没有使用目录来管理文件,而是创建集合collection来对应业务模块,而集合collection是作用在卷volume上的一种标签,所以通过filer服务接口查询目录下文件列表的方法行不通,这已经是既成事实了。
风险:
如果开发人员copy代码,导致2个业务模块共用了同一个集合名字,而现在如果只对其中一个A业务模块数据库表进行比对,就会导致误删除B业务模块的图片,对于一个运行了十年以上的平台,不排除有遗漏的风险。
2. 索引文件
索引文件名是:集合名_卷ID.idx
SeaweedFS索引文件格式: 每个条目固定16字节,结构: key (8字节) + offset (4字节) + size (4字节),采用大端字节序(网络字节序)。
在Linux系统上用vim以%!xxd方式打开:
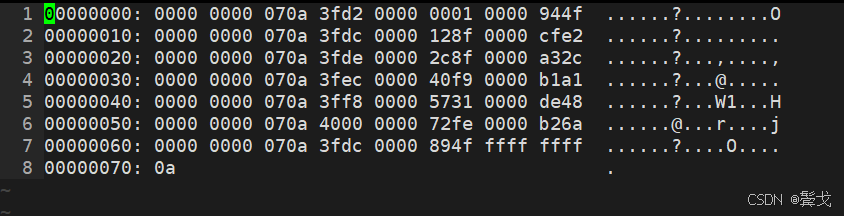
刚好vim打开hex方式下一行16个字节,可以清晰看到3个字段值。
编写一段Python代码来解析这3个字段值:
python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import argparse
import os
import struct
def parse_idx_file(idx_path, volume_id):
"""
解析volume索引文件(.idx),提取文件key信息
SeaweedFS索引文件格式:
- 每个条目固定16字节
- 结构: key (8字节) + offset (4字节) + size (4字节)
Args:
idx_path: 索引文件路径
volume_id: volume ID
Returns:
文件信息列表
"""
files = []
entry_size = 16 # 每个索引条目16字节
try:
with open(idx_path, 'rb') as f:
while True:
data = f.read(entry_size)
if len(data) < entry_size:
break
# 解析二进制数据
# key: 8字节,大端无符号整数
# offset: 4字节,大端无符号整数
# size: 4字节,大端有符号整数(负数表示已删除)
key, offset, size = struct.unpack('>QIi', data)
# size为0表示已删除,正数为正常文件
# 注意:实际size可能包含标志位,这里简化处理
if size > 0: # 只保留未删除的文件
# 从key中提取needle_id(通常是高8字节的一部分)
needle_id = key
key_hex = data[:8].hex()[8:]
files.append({
"volume_id": volume_id,
"needle_id": needle_id,
"key": key,
"offset": offset,
"size": size,
"fid": '%d,%s' % (volume_id, key_hex) # 构建fid
})
except Exception as e:
print(e)
return files
def scan_volume_files(volume_dir, collection, volume_id):
idx_path = os.path.join(volume_dir, '%s_%d.idx' % (collection, volume_id))
if not os.path.exists(idx_path):
print('不存在idx文件: ', idx_path)
return []
file_info_list = parse_idx_file(idx_path, volume_id)
return file_info_list
def main():
parser = argparse.ArgumentParser(description="SeaweedFS索引文件分析工具")
parser.add_argument('-d', "--volume-dir", default="/mnt/hdd4t/seaweedfs/volume/data", help="Volume数据目录")
parser.add_argument('-c', "--collection", default="", help="集合名称")
parser.add_argument('-i', "--volume-id", default="", help="Volumn ID")
args = parser.parse_args()
file_info_list = scan_volume_files(args.volume_dir, args.collection, int(args.volume_id))
for file_info in file_info_list:
print(file_info)
print('-' * 80)
print('总数: ', len(file_info_list))
if __name__ == '__main__':
main()在一个volume节点上执行: python3 ./index_file.py -c panorama_20250930 -i 9354
{'volume_id': 9355, 'offset': 1, 'key': 118112183, 'needle_id': 118112183, 'size': 39150, 'fid': '9355,070a3fb7'}
{'volume_id': 9355, 'offset': 4899, 'key': 118112200, 'needle_id': 118112200, 'size': 46920, 'fid': '9355,070a3fc8'}
{'volume_id': 9355, 'offset': 10768, 'key': 118112202, 'needle_id': 118112202, 'size': 44031, 'fid': '9355,070a3fca'}
{'volume_id': 9355, 'offset': 16276, 'key': 118112218, 'needle_id': 118112218, 'size': 57926, 'fid': '9355,070a3fda'}
{'volume_id': 9355, 'offset': 23521, 'key': 118112232, 'needle_id': 118112232, 'size': 56662, 'fid': '9355,070a3fe8'}
总数: 5
但是,我们发现seaweedfs系统上传文件接口返回的fid是这样的:9354,070a3fd22f5f7113,最后8个字节2f5f7113在.idx中根本不存在!
3 FID格式
FID 的标准格式为:
<VolumeId>,<NeedleId><Cookie>
- VolumeId:整数,标识逻辑卷。
- NeedleId:64 位无符号整数,标识文件在 Volume 内的位置,即上面讲的key。
- Cookie(可选):32 位随机数,增强安全性。
如FID是9354,070a3fd22f5f7113,volumeId是9354,needleId是070a3fd2,cookie是2f5f7113。虽然needleId是64位的,但并没有取全部8个字节形成的16个hex,而是只取8个hex,8个0000000丢掉了,这个一个误区,开始直接用它的16个hex去查询,自然不可能下载到文件。
从.idx文件分析提取所有FID看来是行不通的!
4 数据文件
数据文件名是:集合名_卷ID.dat 。
每个文件在.dat里都被存储为一个Needle结构:
一个
Needle的结构简化如下:
组成部分 字段名 类型 说明 Header (头部) Cookie uint32 例如: 94c473c4Id uint64 文件的Needle ID (例如: 076ca3ee)Size uint32 Body部分的大小 Body (主体) Data \[\]byte 文件的实际内容 CRC Checksum CRC 数据的校验和 Padding Padding \[\]byte 填充字节,保证内存对齐
同样,在Linux系统上用vim以%!xxd方式打开:
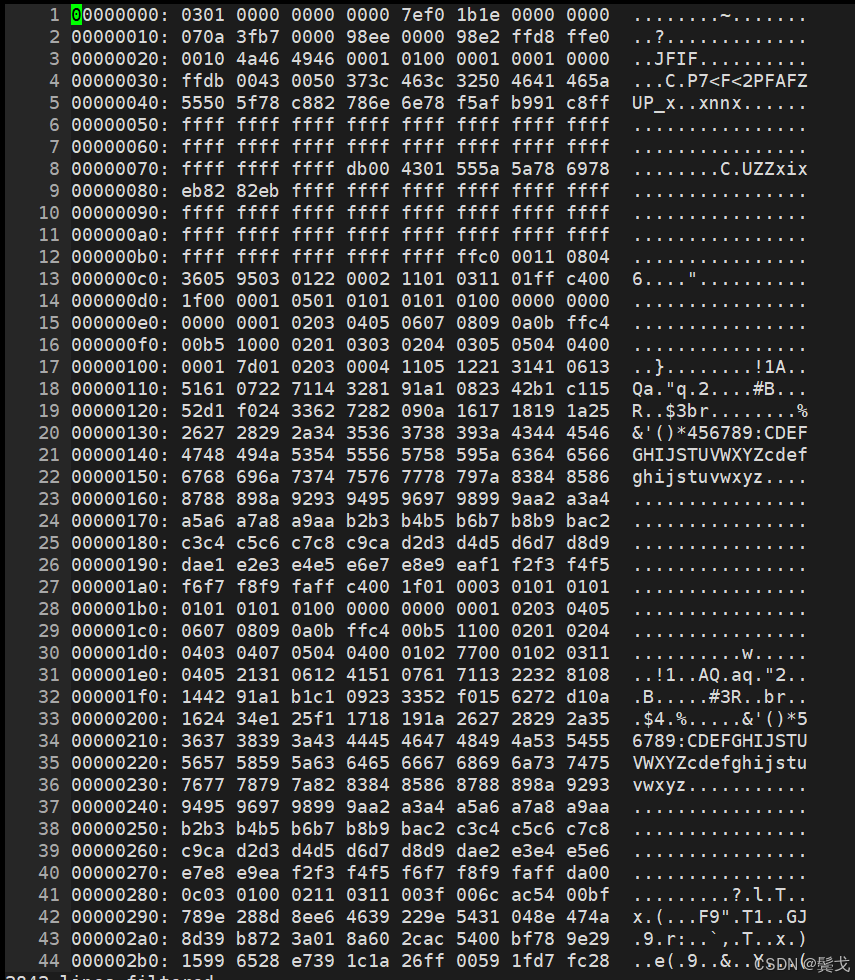
关于编写代码怎么解析,我是先用文心、deepseek、豆包查询了的,在细节上都没有处理对padding,文心和deepseek基本都正确,豆包连数据结构都没搞对。
要注意的是:
1)文件头部信息是8个字节,估计是版本信息。
2)Padding是16个字节对齐的,而且Padding <=8,还要多加8个字节长度。
可能seaweedfs系统不同版本有所不同,我的目前版本是:
./weed version
version 30GB 4.13 63f641a6c9e6ee7e1fec417cabba4edf88cebc53 linux amd64
编写一段Python代码来解析这些字段值:
python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import argparse
import struct
import os
def parse_seaweedfs_dat(file_path, volume_id):
"""
解析SeaweedFS的.dat文件,提取每个needle的Cookie、Id和Size信息
Args:
file_path: .dat文件的路径
"""
# Needle结构定义(根据SeaweedFS源码):
# Cookie: uint32 (4 bytes)
# Id: uint64 (8 bytes)
# Size: uint32 (4 bytes)
# Data: variable length (Size bytes)
# CRC: uint32 (4 bytes)
# Padding: variable length (aligned to 16 bytes)
file_info_list = []
header_size = 8 # 文件头部8个字节:0301 0000 0000 0000
NEEDLE_HEADER_SIZE = 16 # Cookie(4) + Id(8) + Size(4)
try:
with open(file_path, 'rb') as f:
file_size = os.path.getsize(file_path)
print("解析文件: %s" % file_path)
print("文件大小: %d 字节" % file_size)
print("-" * 80)
f.seek(header_size)
offset = header_size
while offset < file_size:
# 读取Needle头部 (Cookie + Id + Size)
header_data = f.read(NEEDLE_HEADER_SIZE)
if len(header_data) < NEEDLE_HEADER_SIZE:
print("警告: 文件末尾不完整,跳过剩余 %d 字节" % (file_size - offset))
break
# 解析头部
cookie, needle_id, data_size = struct.unpack('>IQI', header_data)
# 计算数据的起始位置和结束位置
data_start = offset + NEEDLE_HEADER_SIZE
data_end = data_start + data_size
print('cookie=%d, needle_id=%d, needle_header_size=%d, data_size=%d, data_start=%d, data_end=%d' % (
cookie, needle_id, NEEDLE_HEADER_SIZE, data_size, data_start, data_end))
# 读取CRC
f.seek(data_end)
CRC_SIZE = 4
crc_data = f.read(CRC_SIZE)
if len(crc_data) < CRC_SIZE:
print("警告: 无法读取CRC,可能在文件末尾")
break
# 计算Padding (对齐到16字节)
# SeaweedFS中,每个needle按16字节对齐
total_size = NEEDLE_HEADER_SIZE + data_size + CRC_SIZE
step = 16
padding = (step - (total_size % step))
# 没有看seaweedfs源代码, 具体不知道什么算法需要如下处理
if padding <= 8:
padding += 8
end_size = data_start + data_size + CRC_SIZE + padding
print('needle_header_size=%d, data_size=%d, crc_size=%d, total_size=%d, padding=%d -> end_size=%d' % (
NEEDLE_HEADER_SIZE, data_size, CRC_SIZE, total_size, padding, end_size))
# 跳过Padding
if padding > 0:
f.read(padding)
# 解析结果
cookie_hex = header_data[:4].hex()
key_hex = header_data[4:12].hex()[8:]
print('cookie_hex: %s, key_hex: %s' % (cookie_hex, key_hex))
fid = '%d,%s%s' % (volume_id, key_hex, cookie_hex) # 构建fid
file_info_list.append({
"volume_id": volume_id,
"needle_id": needle_id,
"key": needle_id,
"offset": offset,
"size": data_size,
"fid": fid
})
# 更新偏移量
offset = f.tell()
print('offset=%d' % offset)
print('-' * 100)
return file_info_list
except Exception as e:
print(e)
return []
def scan_volume_files(volume_dir, collection, volume_id):
dat_path = os.path.join(volume_dir, '%s_%d.dat' % (collection, volume_id))
if not os.path.exists(dat_path):
print('不存在.dat文件: ', dat_path)
return []
return parse_seaweedfs_dat(dat_path, volume_id)
def main():
parser = argparse.ArgumentParser(description='解析SeaweedFS的.dat文件')
parser.add_argument('-d', "--volume-dir", default="/mnt/hdd4t/seaweedfs/volume/data", help="Volume数据目录")
parser.add_argument('-c', "--collection", default="", help="集合名称")
parser.add_argument('-i', "--volume-id", type=int, default=0, help="Volumn ID")
args = parser.parse_args()
file_info_list = scan_volume_files(args.volume_dir, args.collection, args.volume_id)
for file_info in file_info_list:
print(file_info)
print('记录总数: %d' % len(file_info_list))
if __name__ == "__main__":
main()在一个volume节点上执行:python3 ./data_file.py -c panorama_20250930 -i 9355
解析文件: /mnt/hdd4t/seaweedfs/volume/data/panorama_20250930_9355.dat
文件大小: 244864 字节
cookie=2129664798, needle_id=118112183, needle_header_size=16, data_size=39150, data_start=24, data_end=39174
needle_header_size=16, data_size=39150, crc_size=4, total_size=39170, padding=14 -> end_size=39192
cookie_hex: 7ef01b1e, key_hex: 070a3fb7
offset=39192
cookie=303057104, needle_id=118112200, needle_header_size=16, data_size=46920, data_start=39208, data_end=86128
needle_header_size=16, data_size=46920, crc_size=4, total_size=46940, padding=12 -> end_size=86144
cookie_hex: 121048d0, key_hex: 070a3fc8
offset=86144
cookie=3851587033, needle_id=118112202, needle_header_size=16, data_size=44031, data_start=86160, data_end=130191
needle_header_size=16, data_size=44031, crc_size=4, total_size=44051, padding=13 -> end_size=130208
cookie_hex: e5928dd9, key_hex: 070a3fca
offset=130208
cookie=714988560, needle_id=118112218, needle_header_size=16, data_size=57926, data_start=130224, data_end=188150
needle_header_size=16, data_size=57926, crc_size=4, total_size=57946, padding=14 -> end_size=188168
cookie_hex: 2a9ddc10, key_hex: 070a3fda
offset=188168
cookie=1291575120, needle_id=118112232, needle_header_size=16, data_size=56662, data_start=188184, data_end=244846
needle_header_size=16, data_size=56662, crc_size=4, total_size=56682, padding=14 -> end_size=244864
cookie_hex: 4cfbdf50, key_hex: 070a3fe8
offset=244864
{'volume_id': 9355, 'key': 118112183, 'size': 39150, 'fid': '9355,070a3fb77ef01b1e', 'offset': 8, 'needle_id': 118112183}
{'volume_id': 9355, 'key': 118112200, 'size': 46920, 'fid': '9355,070a3fc8121048d0', 'offset': 39192, 'needle_id': 118112200}
{'volume_id': 9355, 'key': 118112202, 'size': 44031, 'fid': '9355,070a3fcae5928dd9', 'offset': 86144, 'needle_id': 118112202}
{'volume_id': 9355, 'key': 118112218, 'size': 57926, 'fid': '9355,070a3fda2a9ddc10', 'offset': 130208, 'needle_id': 118112218}
{'volume_id': 9355, 'key': 118112232, 'size': 56662, 'fid': '9355,070a3fe84cfbdf50', 'offset': 188168, 'needle_id': 118112232}
记录总数: 5
上图最后的打印,可以看到fid基本和我们平时系统上传文件时返回的格式一致了,然后编写代码下载一下来验证是否正确。
5 下载文件内容
python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os.path
import sys
import requests
def download_image(fid: str, dir_path: str):
print('fid=', fid)
url = f'http://seaweedfs:9333/{fid}'
r = requests.get(url)
if r.status_code != 200:
print('获取图片失败! ', r.raise_for_status(), r.content)
else:
print('获取图片成功, 长度: ', len(r.content))
file_name = '_'.join(fid.split(',')) + '.jpg'
saved_file_path = os.path.join(dir_path, file_name)
with open(saved_file_path, mode='wb') as f:
f.write(r.content)
print('保存到文件:', saved_file_path)
def usage():
print('usage: ./main.py [fid]')
print(' ./main.py 7905,06e80f89852ca01b')
def main():
if len(sys.argv) < 2:
usage()
return
download_image(sys.argv[1], './image')
if __name__ == "__main__":
main()在Linux系统上命令行执行:
python ./file_download.py 9355,070a3fe84cfbdf50
fid= 9355,070a3fe84cfbdf50
获取图片成功, 长度: 56650
保存到文件: ./image/9355_070a3fe84cfbdf50.jpg
成功下载文件内容说明我们的对.dat文件的分析是对的,从而达到了我们的目的,可以和业务系统数据库表中字段值进行比对,从而对不再引用的文件进行删除。
6 删除文件
获取Volume Server地址,直接发送HTTP DELETE请求进行删除文件。
bash
#!/usr/bin/env bash
if [ "$#" -lt "2" ]; then
echo "usage: ./file_delete.sh [volume_server ip:port] [fie]"
echo " ./file_delete.sh 192.168.3.2:9334 9353,070a3ff6882eea06"
else
VOLUME_SERVER="$1"
FID="$2"
echo "volume_server: $VOLUME_SERVER"
echo "fid: $FID"
# 发送DELETE请求
curl -X DELETE "http://${VOLUME_SERVER}/${FID}"
fi如果我们立即去看.dat文件,发现并没有真正删除掉文件内容,这种分块存储机制一般不会立即物理删除,大部分这类系统都是事后批量处理的。
7 删除后的处理机制
了解SeaweedFS的删除机制有助于理解删除操作的实际效果:
-
逻辑删除 :发送DELETE请求后,文件立即变得不可访问,但磁盘空间不会立即释放 ;
-
标记删除 :Volume Server只是在索引中标记文件为已删除,并在
.dat文件末尾追加一个标记 ; -
空间回收 :真正的空间回收通过**定期压缩(compaction)**完成。当volume中的垃圾数据超过阈值(默认30%)时,master会触发压缩 ;
-
手动触发压缩:
curl "http://<master_host>:9333/vol/vacuum?garbageThreshold=0.1"
curl "http://<volume_server_host>:8080/admin/volume/compact?volumeId=9353"
通过以下命令来查看指定卷的状态,确认其垃圾比例:
curl "http://192.168.1.100:8080/status?volumeId=10547&pretty=y"执行结果中有:
{ "Id": 9353, "Size": 48873, "ReplicaPlacement": { "node": 1 }, "Ttl": { "Count": 0, "Unit": 0 }, "DiskType": "", "DiskId": 0, "Collection": "panorama_20250930", "Version": 3, "FileCount": 1, "DeleteCount": 1, "DeletedByteCount": 48873, "ReadOnly": false, "CompactRevision": 0, "ModifiedAtSecond": 0, "RemoteStorageName": "", "RemoteStorageKey": "" }
我用来测试的集合下的文件很少,一直都没有触发真正的压缩删除,可能还有其他条件吧,这个就交给运维人员去折腾了。