Pandas 是 Python 数据分析的核心库,基于 NumPy 构建,提供了快速、灵活的数据结构,主要用于处理表格型 或异质性数据,类似于 Excel 表格或 SQL 数据库。
与Numpy不同,Numpy中的ndarray既可以是一维也可以是二维------体现特性多维性,而在Pandas中将一二维数据分别处理,一维使用series而二维是dataframe。本帖先总结series。
简答来说,Series相当于关系型数据库中的一列,亦或者说是表格的一列。

一开始要记得把Pandas包导入:
python
import pandas as pd
import numpy as np一.创建
常规的创建方式是通过列表传参:
python
s=pd.Series([1,2,3,4,5])除了传参数值本身,还可以传参序号------即索引:
python
s1=pd.Series([1,2,3,4,5],index=['f','b','c','d','e'])既可以像我这样以离经叛道随意胡写,也可以写标准的顺序,主打一个从心所欲不逾矩:

就好比一列数据的表头一样,Series类型还支持取名,通过name参数来定义:
python
s2=pd.Series(['a','b','c','d','e'],name="小写字母")
print(s2)顺便说一句,默认的索引依旧是从0开始:

索引和数值的二元对立,有点类似键值对,因此可以用字典来传参:
python
s3=pd.Series({"one":1,"two":2,"three":3,"four":4,"five":5})
print(s3)
还可以通过原有Series来阶段一部分形成新的半个副本一样:
python
s4=pd.Series(s3,index=['one','two'])#只选取其中一部分二.属性
value表示Series的数值集合,而index则是索引集合,本质还是面向对象,通过属性调用即可:
python
print(s3.values,s3.index)
类似ndarray也可以通过索引/下标进行切片,分为显示索引和隐式索引:因为可以自定义索引,通过我们自己定义的索引来访问就是显式索引,如下的切片:两侧都是闭区间!
python
print(s3.loc["one":"three"])#显式索引隐式索引则是默认的索引即下标------或者说是位序减1,但注意这里是左闭右开!
python
print(s3.iloc[0:2])对比来看一下,并且注意调用的函数名是什么:

类似的还有访问单个元素的方式,同样包含显式和隐式两种,区别在于不能切片:
python
print(s3.at["one"])#类似但不支持切片
print(s3.iat[0])
三.访问
实际上除了上面的loc或者at以及两者的隐式版本,实际上可以像列表一样直接用下标访问,但是不推荐:
python
print(s3[0])更好的做法是通过索引标签来随机存取:
python
print(s3["one"])和ndarray一样也可以使用bool方法:
python
print(s3[s3>3])#依旧是布尔索引
四.方法
head和tail分别返回默认的最前五行和最后五行,填数字则按照数字的数量返回,超过最大值就返回所有:
python
s5=pd.Series([1,np.nan,None,3,4,5],index=["1","2","3","4","5","6"])
print(s5.head())#默认前五行
print(s5.tail())#默认后五行,填数字则按需返回,超过最大值就返回所有的元素
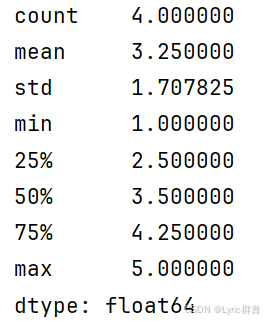
print(s5.tail(1))describe返回各种统计信息:
python
print(s5.describe())#返回所有描述信息需要注意元素none也会被视为NAN,统计信息一概不包含NAN在内。也可以单独计算一个,和ndarray类似,这里不再赘述:
返回索引,等价于index,前者是方法后者是属性:
python
print(s5.keys())判断哪个是缺失值:
python
print(s5.isna())判断列表的每一个元素是否在参数列表中:
python
print(s5.isin([4,5]))按值排序,NAN统一在后面:
python
print(s5.sort_values())返回众数,存在多个就都返回:
python
print(s5.mode())还有一些统计类的方法:
python
print(s.value_counts())#按值来统计
s.drop_duplicates()#去重,相较于unique会返回为列表,该方法还是原类型
print(s.nunique())#去重后的元素个数
s.sort_index()#按照索引排序