当大模型吃掉App,从高德开放平台看AI服务重构
作为一个还在习惯用手机软件的老用户,最近有幸参加了一下高德开放平台的Al产品发布会。这场高德AI发布会给我提了个醒,大模型真正的商业化拐点,可能不在模型本身,而在它如何吃掉我们手机里的一个个App。当MCP协议让AI能实时调用地图、天气、打车服务时,"打开软件"这个动作本身,就开始变得不那么频繁了。

其实从24年上旬之前,SaaS(软件即服务)这个模式思维其实还挺流行的。具体来说,比如生活中在手机上安装一个地图软件,然后用这个地图软件上提供的服务,比如说导航、路线规划、交通情况查询这些服务。那个时候其实ChatGPT这类的大模型AI产品已经出来了,但是有个缺陷就是这些模型的判断基础数据面有些不是实时的、有些需要联网获取。所以我不会去询问这些AI,例如说今天的天起、帮我规划一条路线什么的,因为这里面缺少核心且必要的数据支撑。但是今年,我开始越来越频繁地使用AI来获取交通、金融、一些最新的新闻,反而是手机软件的使用频率开始下降。无他,主要是AI一句直达信息要害。
会上有一个非常有意思的技术发展流程图,给我留下很深刻的印象。从MCP、A2A到CLI,其实也不到一年多的时间,能感受到AI的技术管理体系和信息获取能力在不断成熟。

在去年4月前后,MCP就开始流行起来了。这个流行其实是类似于给AI大模型一个对接其他软件平台的能力接口,这边输入参数,然后平台这边处理完成以后再返回。其实从这里开始,AI大模型开始变得有些实际用处了,我现在还记得当时用的是Claude,只要接入地图类MCP,就可以让模型读取到当地的天起、交通状况等等,然后路线规划这些也不是问题。后来手机上大部分的AI程序也支持这类的功能了。这样子一来,好像提前规划路线的时候,我就不再需要点击软件,然后输入目的地,然后导航什么的。我开始更加习惯地将MCP接入到AI,然后问一句AI就好。这样子其实降低了我的操作成本和精力成本。
而从MCP能导入AI大模型开始,这个时候其实A2A(Agent-to-Agent)这个最初由谷歌提出的概念就开始变得流行。这个概念的意思是让不同厂商、不同平台的AI Agent智能体能够互相发现、协商、协作。这个其实还是出于技术层面的一些考量,让不同智能体装上不同的MCP,协作处理问题。这种协作本质上就是解决了一个问题,就是现在一个混合的智能体已经能够实现以前手机上的APP大部分的基本功能。
而为了方便管理这些功能,一般智能体就会把一个个功能封装成技能(SKILL),就像软件一样,和他们说用什么技能,就可以执行特定的技能。这个其实在编程软件中特别好用,比如特定的环境配置、特定的一些开发架构这些。
而在26年今年,对这些智能体的操作的上限进一步提高了,这些智能体可以通过电脑里面终端的指令来执行,比起使用图形化的操作页面,这种方式对程序员来说更加优化,也更加高效。
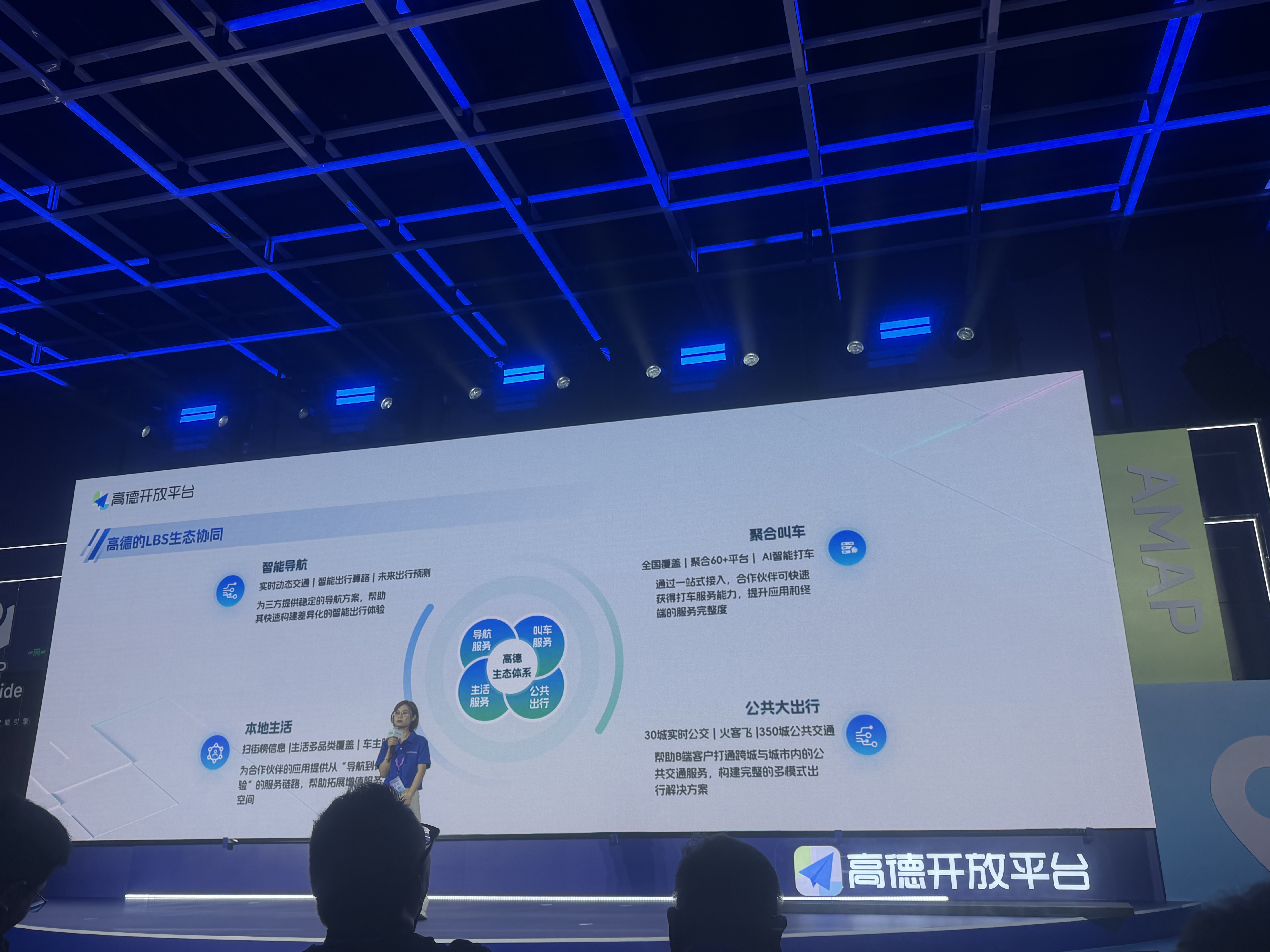
其实这些名称虽然看着多,其实本质上就是在用LLM大模型,然后周边配套一些列的大部分以前可能是SaaS的服务应用。比如说AI+地图、AI+买票,然后通过一套逐步成熟的、标准化的管理体系来管理他们。今天在会上我也看到高德开放平台里面就有一个,挺有意思的场景适配矩阵。这个矩阵本质上是涵盖了从软件开发到AI架构下的信息接入的各种方法,能看到高德开放平台已经可以提供一套完整的接入体系。

我把这个矩阵列成了下面的一张表格。这个矩阵的逻辑就是平台提供的一个服务接口。其实逻辑也非常清晰,就是从以前比如说不同操作系统下使用的SDK/API这种模式,到最近出现的各种AI调用MCP、SKILL的方式。同时下面还出现了一个AI工具台,这个是现在流行的积木化、无代码搭建的方式。
| 象限 | 类型 | 核心定位 | 实现方式 | AI云产品 | 集成周期 |
|---|---|---|---|---|---|
| 左上 | 🔵 接口集成型 | 标准化能力调用 | API/SDK快速接入 | API/SDK | 周级、月级 |
| 右上 | 🟢 技术赋能型 | 客户自建能力 | 通过Skill/MCP嵌入企业系统 | Skill/MCP Server | 分钟级/天级 |
| 左下 | 🟢 轻量即用型 | 开箱即用 | AI工具台开箱即用,零开发门槛 | AI工具台 | 分钟级 |
| 右下 | 🔵 全案服务型 | 全托管服务 | Agent + AI工具台,全托管服务 | Agent/AI工具台 | 天级 |
当然,严格来说,APP提供的不仅仅是各种信息的接口,最根本的还是平台的服务信息数据本身。如果需要从各类层出不穷的、功能相似的APP中脱颖而出,APP之间的竞争的核心有时候还是回到平台基础信息服务本身。能感觉到现在AI赛道也开始出现类似的这种趋势。其实在23年大模型刚出来的时候,可能模型在处理基础文本信息的时候仍然存在较大差距。但是随着三年发展下来,特别是国内的千问、Deepseek这类大模型的成长,其实在处理这些基础的信息,或者说是简单的场景基本上差异化越来越小了。所以业内出现了这个基座模型和垂直模型的概念,也就是前者是处理海量的通用文本,后者就用来处理领域专业数据(医疗病历、法律条文、金融报告等)。从基座模型转化为垂直模型的过程一般是通过微调、蒸馏、 RAG增强这些办法来实现的。本质上来说,这个很吃专业数据,比如说,RAG这种就是外挂领域知识库。我列了一个表格作为例子,用一个简单的场景,比如说让大模型告诉我们天气情况。
| 方式 | 上传PDF | MCP调天气数据 | 真正的领域知识库(RAG) |
|---|---|---|---|
| 本质 | 一次性文档投喂 | 实时API查询 | 结构化检索增强系统 |
| 数据形态 | 非结构化文本 | 实时结构化数据 | 向量化索引+元数据管理 |
| 检索能力 | 弱(靠模型记忆或简单匹配) | 强(精准API返回) | 语义检索+过滤+重排序 |
| 更新维护 | 手动重新上传 | 自动实时 | 增量更新、版本管理 |
| 可控性 | 低(黑盒引用) | 中(API可控) | 高(可追溯引用源) |
表格里面我给出了三种方法,一种方法就是把信息存在文档里面,然后让AI读取分析,另外一种是外来读取,然后第三种是客观的RAG领域知识库。工作场景中最常见的就是这三种方法了。但是这三种方式最怕遇到的问题就是,如果有一部分数据是缺失的,但是AI会自己编一个结论、说法给我们。这个缺失有的时候是技术层面上没有获取到的、有的是MCP接入平台本身可能也不具备这些数据储备,最后用起来往往没有还需要核查。当然,有的时候如果模型推理逻辑不对,这个结论也是不完全可信的。

那反过来理解,只要全程数据给充足给完善,结论往往越可靠。这个也是现场技术人员分享的技术观点,即能够提供一个可审计的业务结果。这个思路主要是通过确保模型的推理是基于可查看明确的数据,现场演示了AI用的一张张实时提供、存储的Excel表格进行推理,然后问题分析步步都有流程,让最后的生成的结论和报告的可信度更高、更严禁。
当然,这里也就存在着一个过去互联网时代的逻辑:平台积累的数据是企业最宝贵的数字财富。这个我在以前还不太理解。今天感觉AI同质化竞争的时代下,这个还真是企业的护城河。当下AI助手、基座模型比较多,其实差距不算很大。如果平台服务之间真正需要拉开差距,大部分是在垂直模型这个赛道上做差异化竞争。用这些年沉淀的数据做专业领域内更加专业的垂直模型。公司平台过去积累的海量数据,也许会成为未来各大公司在AI赛道的竞争点吧。

现场还有一个挺有意思的分享,也拓宽了我对AI产品开发思路。一直以来我对AI、AIOT和人机交互都不陌生。而LLM当下的产品力最突出的地方在于多模态处理能力,对于处理端侧的信息非常有帮助。但是之前由于便携式设备和端侧边缘计算的一些矛盾,其实AI在便携式设备的利用还不算充分。在2023年底开始加速、2024-2025年爆发的新浪潮后,现在AI植入边缘设备又开始流行起来。现场推出的高德空间智能开放平台给出了几个案例产品,还是非常有参考价值的。用分享工作人员的话来说,就是可以"打通空间智能感知到服务全链路"。
现场提出了一个有意思的产品,大致是植入智能眼镜、智能手表的AI打车服务。这个场景是通过语音交互,将用户的需求收集起来,比如目的地、推荐餐厅这些。然后用自身平台的数据优势,比如数据导航优势、打车服务整合等等,为用户提供服务。虽然这个过程涉及的技术环节比较复杂,但是从用户的场景来说,就是一个带着AI设备的用户,对设备说我想去当地最大的游乐园玩,过几分钟可以在路口坐上共享出租车。整个交互过程可以感受到往后人机交互的趋势是越来越简洁的。
回过头看,从SaaS到MCP再到A2A,名称迭代很快,但本质没变,这个过程是LLM正在吞掉传统软件的服务层。当基座模型的能力差距越来越小,真正拉开身位的反而是谁掌握了不可替代的领域数据。2026年的AI竞争,模型是入场券,数据也许才是护城河了。