🚀 ICML 2025 | GS-Bias: Global-Spatial Bias Learner for Single-Image Test-Time Adaptation of Vision-Language Models
💡 导读
最近,面向视觉语言模型的测试时间适应(Test Time Adaptation, TTA 引起了越来越多的关注,特别是通过使用单个图像的多个增强视图来提升零样本泛化。不幸的是,现有方法未能在性能和效率之间取得令人满意的平衡,要么是由于调整文本提示的过高开销,要么是由于手工制作的、无训练的视觉特征增强带来的不稳定收益。 本文提出了一种高效且有效的全新TTA范式------GS-Bias ,在TTA过程中引入了两个可学习的偏置,分别为全局偏置和空间偏置。具体而言,全局偏置通过学习增强视图之间的一致性来捕捉测试图像的全局语义特征,而空间偏置则学习图像空间视觉表示中区域之间的语义一致性。值得强调的是,这两组偏置直接添加到预训练VLM输出的logits中,从而避免了对VLM的完全反向传播。 这使得GS-Bias在实现15个基准数据集上的最先进性能的同时,具备了极高的效率。例如,它在跨数据集泛化方面比TPT提高了2.23%,在领域泛化方面提高了2.72%,而在ImageNet上仅需使用TPT内存的6.5%。
🔗 论文地址 :https://arxiv.org/abs/2507.11969
💻 代码开源 :https://github.com/hzhxmu/GS-Bias
🧐 核心痛点:性能与效率的"鱼与熊掌"
在追求视觉语言模型的测试时自适应时,研究者们长期被困在两难境地:
-
效率的"高昂代价":
- 反向传播负载过重:基于 Prompt Tuning 的方法(如TPT),需要让梯度流经整个深度网络,导致成倍的显存消耗,这对于实时性要求高的场景是不可接受的。
-
性能的"不稳定性":
- 语义对齐困难:基于无训练聚类的视觉特征增强方法(如MTA),难以捕捉到深层的语义连贯性,导致分类精度触及瓶颈。
🛠️ 技术创新:Global-Spatial Bias Learner (GS-Bias)
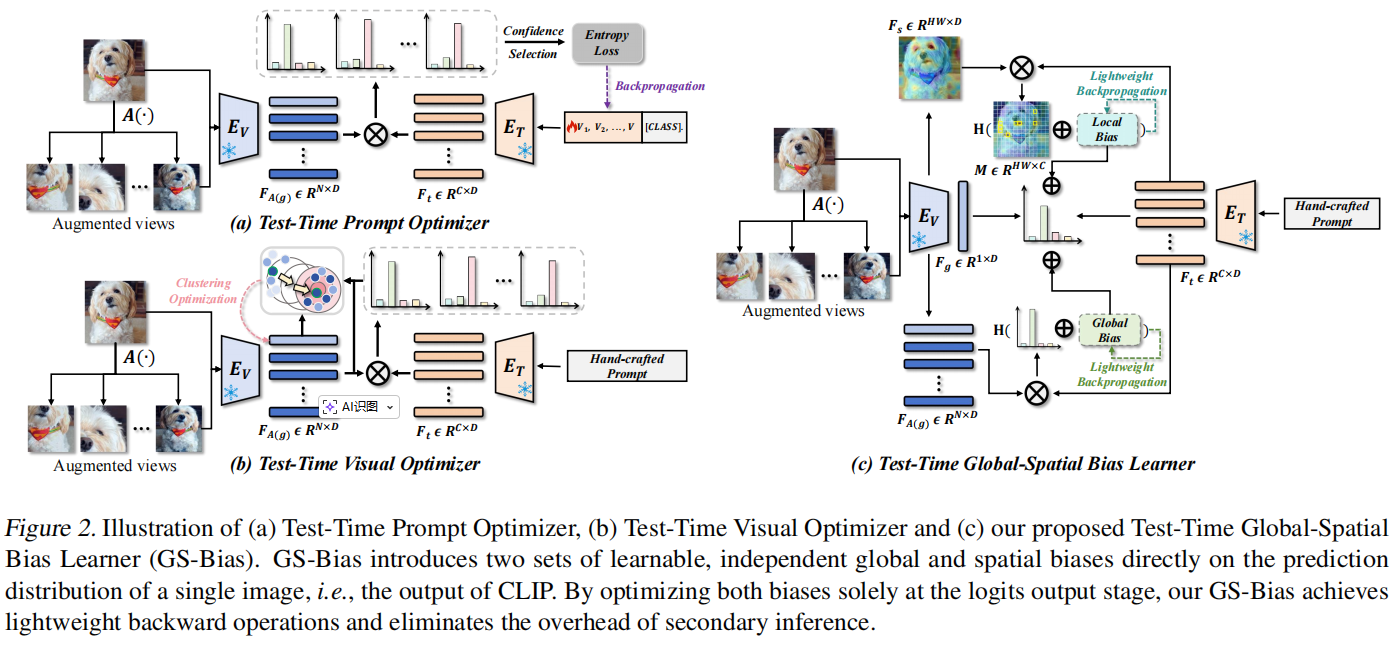
GS-Bias 另辟蹊径,不修改模型输入或内部特征,而是直接在 Logits(输出层) 引入两类可学习的轻量级偏置 :
- 全局偏置(Global Bias) :
- 通过学习不同增强视图之间的一致性,捕捉测试图像的全局语义特征 。
- 空间偏置(Spatial Bias) :
- 利用视觉编码器中的空间特征,通过 Top-K 策略选择与任务最相关的区域,学习图像内部的语义连贯性。
✨ 最大亮点:优化仅发生在输出端,彻底告别了全网络反向传播,实现了极速、轻量的在线自适应 。
📊 实验表现
在涵盖跨数据集泛化、领域泛化等 15 个基准测试中,GS-Bias 表现出色 :
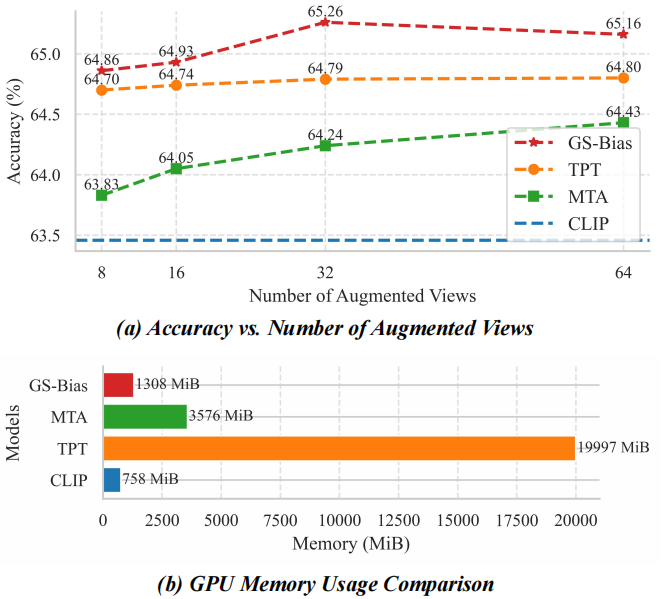
- 更强性能 :在跨数据集泛化上比 TPT 提升了 2.23% ,在领域泛化上提升了 2.72% 。
- 极低显存 :在 ImageNet 上,GS-Bias 仅需 1308 MiB 显存,对比 TPT 的 19997 MiB ,降低了 93.5% 。
- 全面超越:在 10 个跨数据集基准测试中,GS-Bias 在所有数据集上均优于原始 CLIP 的方法 。
🌟 总结
GS-Bias 为大规模视觉语言预训练模型的下游部署开辟了低功耗、高精度 的新路径。其 "即插即用"且资源敏感度极低的特性,展现了巨大的工业应用潜力。这种技术能够精准赋能于对实时性与可靠性有严苛要求的场景,例如自动驾驶在恶劣天气下的鲁棒性感知,以及医疗影像中病灶动态演变的精准分析。