ShardingSphere 提供了高度抽象的配置体系,开发者只需通过声明式配置即可定义分片规则、读写分离策略、数据脱敏规则等,而无需关心底层的复杂实现。那么,这套配置体系究竟是如何设计的?它包含了哪些核心概念?不同的配置方式背后又遵循着怎样的实现原理?本篇将深入剖析 ShardingSphere 的配置体系,为你揭开其神秘面纱。
一、行表达式:配置的"语法糖"
在深入配置体系之前,必须先了解 ShardingSphere 中一个极其实用的功能------行表达式。它是一种轻量级的动态表达式语言,用于简化配置中的重复性描述,尤其在定义数据节点和分片算法时发挥着重要作用。
1.1 行表达式的基本语法
行表达式的使用非常直观,只需要在配置中使用 ${expression} 或 $->{expression} 形式即可。其中,${begin..end} 表示从 begin 到 end 的范围区间,而多个 ${expression} 之间用 . 连接,表示多个范围的笛卡尔积。例如,表达式 ds${0..1}.user${0..1} 将解析为:
-
ds0.user0 -
ds0.user1 -
ds1.user0 -
ds1.user1
这一过程可以用下图直观展示:
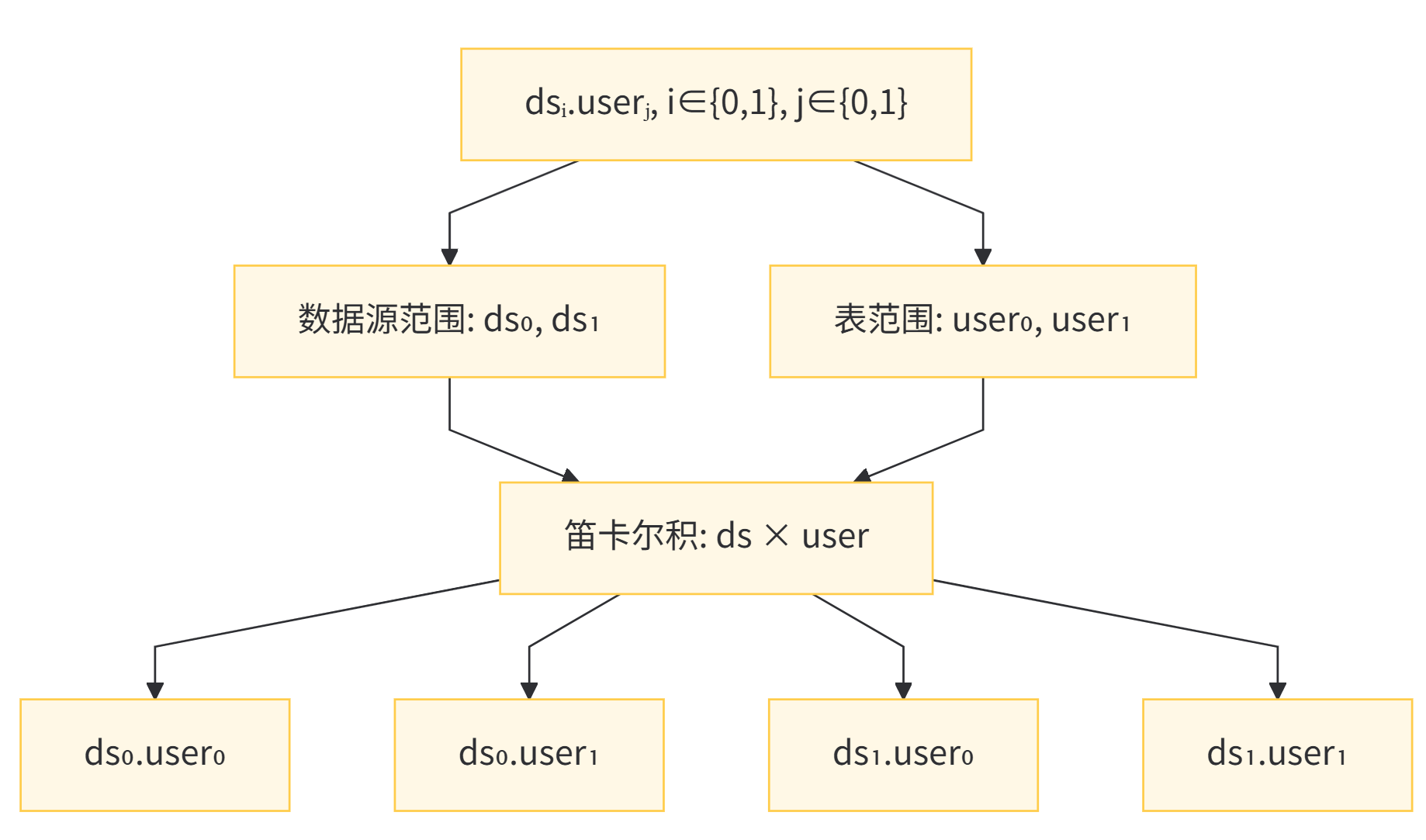
除了范围表示法,行表达式还支持枚举:${[enum1, enum2, ...]}。因此,上面的表达式也可以写成 ds${[0,1]}.user${[0,1]},效果完全相同。
1.2 行表达式在分片算法中的应用
行表达式另一个典型应用场景是配置分片算法。例如,我们见过这样的配置:ds${age % 2},它表示根据 age 字段对 2 取模,动态路由到 ds0 或 ds1。这种表达方式极大地简化了分片算法的配置,开发者无需编写复杂的 Java 代码,只需一行表达式即可完成。
1.3 注意事项
由于 ${expression} 与 Spring 属性占位符(如 ${...})存在冲突,当在 Spring 环境中使用时,推荐采用 $->{expression} 的形式以避免解析混淆。
行表达式作为配置的"语法糖",让 ShardingSphere 的配置变得更加简洁、直观。接下来,我们将正式进入配置体系的核心,看看 ShardingSphere 到底定义了哪些配置项。
二、ShardingSphere 核心配置解析
ShardingSphere 的配置体系以规则为中心,每种功能(分片、读写分离、数据脱敏等)对应一个规则配置类。其中,分片引擎是最核心的功能,其配置也是最复杂的。下面我们以分片引擎为例,逐一剖析其核心配置项。
2.1 ShardingRuleConfiguration:分片规则的顶层入口
ShardingRuleConfiguration 是所有分片相关配置的容器,它聚合了多个子配置,包括表规则、绑定表、广播表、默认策略等。其类结构如下:

各属性含义如下:
| 属性 | 类型 | 说明 |
|---|---|---|
tableRuleConfigs |
Collection<TableRuleConfiguration> |
表分片规则列表,每个逻辑表对应一个配置,是必须配置的项。 |
bindingTableGroups |
Collection<String> |
绑定表组,将具有相同分片规则的主表与子表关联,避免跨库关联查询。 |
broadcastTables |
Collection<String> |
广播表,指那些数据量小、需要同步到所有分片的表(如字典表)。 |
defaultDataSourceName |
String |
默认数据源,当分片规则无法匹配时,路由到该数据源。 |
defaultDatabaseShardingStrategyConfig |
ShardingStrategyConfiguration |
默认分库策略,若表规则未指定分库策略,则使用此默认策略。 |
defaultTableShardingStrategyConfig |
ShardingStrategyConfiguration |
默认分表策略,若表规则未指定分表策略,则使用此默认策略。 |
defaultKeyGeneratorConfig |
KeyGeneratorConfiguration |
默认自增列生成器配置。 |
masterSlaveRuleConfigs |
Collection<MasterSlaveRuleConfiguration> |
读写分离规则配置,可定义多个主从架构。 |
encryptRuleConfig |
EncryptRuleConfiguration |
数据脱敏规则配置。 |
2.2 TableRuleConfiguration:表级分片规则
TableRuleConfiguration 是实际定义逻辑表如何分片的配置类。其核心属性如下:

-
logicTable :逻辑表名,在 SQL 中使用的表名,例如
t_order。 -
actualDataNodes :真实数据节点,由数据源名和表名组成,支持行表达式。例如
ds${0..1}.t_order${0..1}。 -
databaseShardingStrategyConfig:分库策略,决定 SQL 路由到哪个数据源。
-
tableShardingStrategyConfig:分表策略,决定 SQL 路由到该数据源下的哪张表。
-
keyGeneratorConfig:分布式主键生成器配置,如雪花算法、UUID 等。
2.3 ShardingStrategyConfiguration:分片策略的抽象
ShardingStrategyConfiguration 是一个空接口,其实现类代表了不同的分片策略。类层次结构如下:

-
StandardShardingStrategy :标准分片策略,支持单分片键,并提供精确分片算法(
PreciseShardingAlgorithm)和范围分片算法(RangeShardingAlgorithm)。 -
ComplexShardingStrategy :复合分片策略,支持多分片键,使用
ComplexKeysShardingAlgorithm。 -
InlineShardingStrategy :行表达式分片策略,通过行表达式定义分片算法,如
age % 2。 -
HintShardingStrategy:强制路由分片策略,通过 Hint 方式指定分片目标,不依赖 SQL 中的分片键。
-
NoneShardingStrategy:无分片策略,适用于不需要分片的表。
2.4 KeyGeneratorConfiguration:分布式主键生成器
分布式环境下,数据库自增主键无法保证全局唯一,因此需要引入分布式主键生成器。KeyGeneratorConfiguration 用于配置生成器:
public class KeyGeneratorConfiguration {
private String column; // 自增列名
private String type; // 生成器类型,如 SNOWFLAKE、UUID
private Properties props; // 生成器属性,如雪花算法的 workerId
}ShardingSphere 内置了雪花算法(SNOWFLAKE)和 UUID 两种实现,开发者也可通过 SPI 机制自定义。
三、四种配置方式详解
ShardingSphere 提供了四种配置方式,以适应不同的开发场景和团队偏好。下面逐一介绍其特点及使用示例。
3.1 Java 代码配置
Java 代码配置是最原始的方式,直接使用 ShardingSphere 提供的 API 构建配置对象。优点是类型安全、IDE 友好,适合对底层原理的学习和定制化开发;缺点是配置变更需重新编译,不利于动态管理。
示例:构建分片数据源
java
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("ds0", createDataSource("jdbc:mysql://localhost:3306/ds0"));
dataSourceMap.put("ds1", createDataSource("jdbc:mysql://localhost:3306/ds1"));
// 配置 t_order 表规则
TableRuleConfiguration orderTableRule = new TableRuleConfiguration("t_order", "ds${0..1}.t_order${0..1}");
orderTableRule.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}"));
orderTableRule.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order${order_id % 2}"));
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRule);
// 获取数据源
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new Properties());3.2 Yaml 配置
Yaml 配置是 ShardingSphere 官方推荐的配置方式,具有结构清晰、可读性强、易于版本管理等优点。配置可独立于代码存放,通过加载 Yaml 文件动态创建数据源。
示例:分片配置 sharding.yaml
java
dataSources:
ds0: !!com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/ds0
username: root
password: root
ds1: !!com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/ds1
username: root
password: root
shardingRule:
tables:
t_order:
actualDataNodes: ds${0..1}.t_order${0..1}
databaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds${user_id % 2}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order${order_id % 2}
bindingTables:
- t_order
defaultDataSourceName: ds0加载 Yaml 文件
java
File yamlFile = new File("path/to/sharding.yaml");
DataSource dataSource = YamlShardingDataSourceFactory.createDataSource(yamlFile);3.3 Spring Boot 配置
Spring Boot 已成为 Java 微服务的事实标准,ShardingSphere 提供了 spring-boot-starter,只需在 application.properties 或 application.yml 中添加配置即可。
示例:Spring Boot 分片配置
java
# 数据源定义
spring.shardingsphere.datasource.names=ds0,ds1
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/ds0
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=root
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://localhost:3306/ds1
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root
# 分片规则
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
spring.shardingsphere.sharding.binding-tables=t_order
# 属性配置
spring.shardingsphere.props.sql.show=true通过这四种方式,开发者可以根据项目实际情况灵活选择。其中,Yaml 和 Spring Boot 配置是当前最主流的用法。
四、配置体系的实现原理
了解了配置的使用方式后,我们不禁要问:这些配置是如何转化为 ShardingSphere 内部对象的?其底层实现机制是什么?下面以 Yaml 配置为例,深入剖析配置体系的实现原理。
4.1 从 ShardingRuleConfiguration 到 DataSource
无论采用哪种配置方式,最终目标都是构建一个 DataSource 对象,供应用使用。以 Java 代码配置为例,ShardingDataSourceFactory 是入口:
java
public final class ShardingDataSourceFactory {
public static DataSource createDataSource(
Map<String, DataSource> dataSourceMap,
ShardingRuleConfiguration shardingRuleConfig,
Properties props) throws SQLException {
return new ShardingDataSource(dataSourceMap, new ShardingRule(shardingRuleConfig, dataSourceMap.keySet()), props);
}
}ShardingRule 是对 ShardingRuleConfiguration 的封装,内部完成了规则校验、策略初始化等操作。因此,配置体系的核心就是将外部配置(Yaml/Spring)转换为 ShardingRuleConfiguration 对象。
4.2 Yaml 配置的加载与转换
ShardingSphere 为 Yaml 配置设计了一套完整的解析与转换机制,核心类图如下:
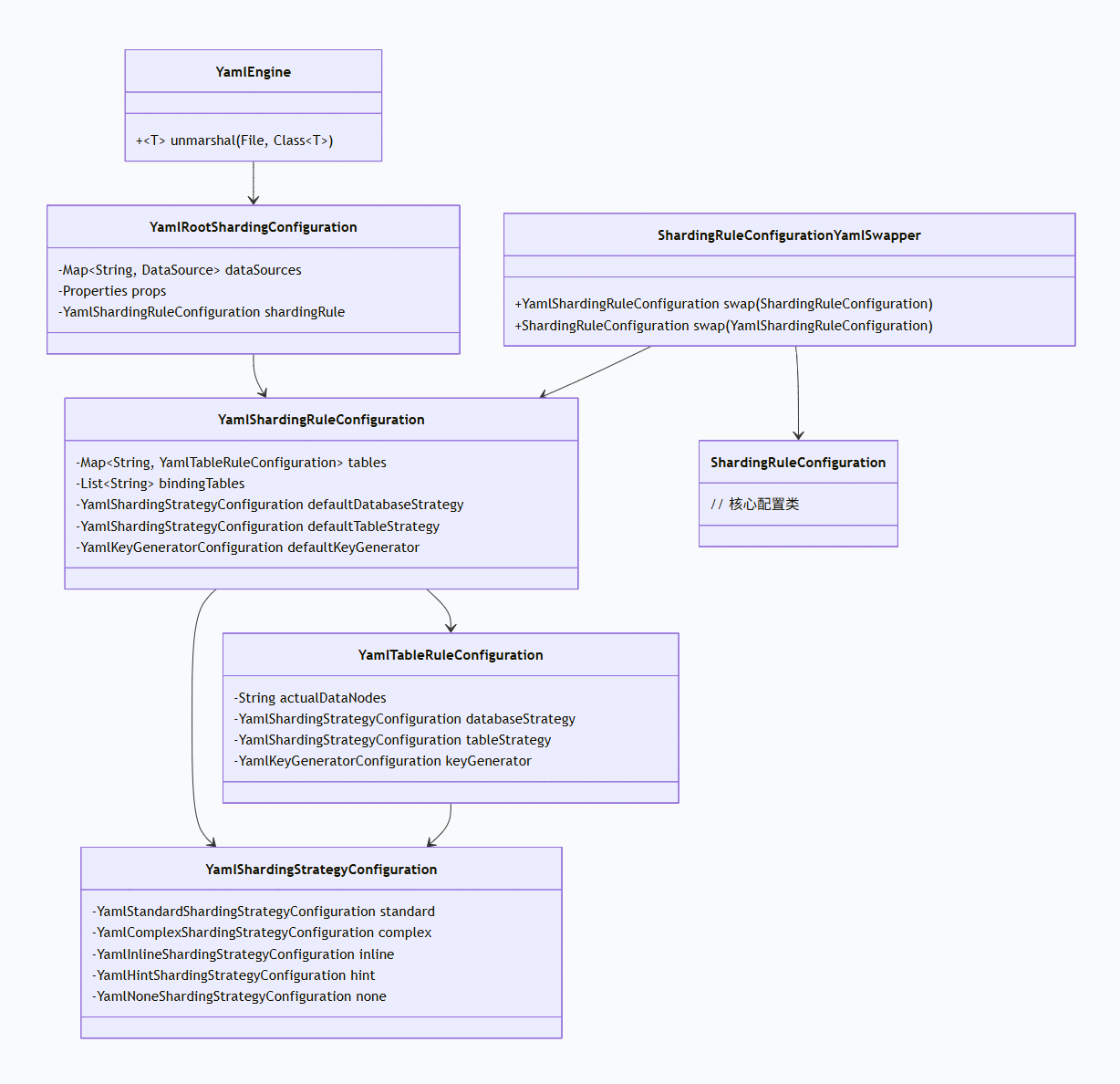
流程如下:
-
加载 Yaml 文件 :
YamlEngine.unmarshal(yamlFile, YamlRootShardingConfiguration.class)通过 SnakeYAML 库将文件内容解析为YamlRootShardingConfiguration对象。 -
获取 Yaml 规则 :从
YamlRootShardingConfiguration中获取YamlShardingRuleConfiguration。 -
转换为核心规则 :调用
ShardingRuleConfigurationYamlSwapper.swap(yamlShardingRuleConfiguration),将 Yaml 配置对象转换为ShardingRuleConfiguration。 -
创建 DataSource :将
dataSourceMap、转换后的ShardingRuleConfiguration和props传入ShardingDataSourceFactory.createDataSource,最终得到DataSource。
其中,ShardingRuleConfigurationYamlSwapper 的 swap 方法实现了字段的一一映射,代码结构清晰,例如:
java
@Override
public ShardingRuleConfiguration swap(final YamlShardingRuleConfiguration yamlConfiguration) {
ShardingRuleConfiguration result = new ShardingRuleConfiguration();
// 转换表规则
for (Entry<String, YamlTableRuleConfiguration> entry : yamlConfiguration.getTables().entrySet()) {
YamlTableRuleConfiguration tableRuleConfig = entry.getValue();
tableRuleConfig.setLogicTable(entry.getKey());
result.getTableRuleConfigs().add(tableRuleConfigurationYamlSwapper.swap(tableRuleConfig));
}
// 转换绑定表
result.getBindingTableGroups().addAll(yamlConfiguration.getBindingTables());
// 转换默认策略
if (null != yamlConfiguration.getDefaultDatabaseStrategy()) {
result.setDefaultDatabaseShardingStrategyConfig(
shardingStrategyConfigurationYamlSwapper.swap(yamlConfiguration.getDefaultDatabaseStrategy()));
}
// ... 其他字段
return result;
}4.3 Spring 命名空间与 Spring Boot 的实现
Spring 命名空间和 Spring Boot Starter 的实现原理类似,都是通过 Spring 的扩展机制将配置转换为 ShardingSphere 的内部对象。
-
Spring 命名空间 :通过实现
NamespaceHandler和BeanDefinitionParser,将 XML 元素解析为对应的BeanDefinition,最终创建出DataSource实例。 -
Spring Boot Starter :通过
@Configuration和@ConditionalOnProperty等注解,自动加载配置并创建DataSource。其核心是ShardingSphereAutoConfiguration类,它读取spring.shardingsphere前缀的配置,构建规则对象并返回数据源。
由于篇幅限制,这里不再展开,后续将专门讲解 ShardingSphere 与 Spring 的集成原理。
五、小结
本篇深入剖析了 ShardingSphere 的配置体系,从行表达式这一"语法糖"入手,详细介绍了分片核心配置项(ShardingRuleConfiguration、TableRuleConfiguration、ShardingStrategyConfiguration、KeyGeneratorConfiguration)的含义与作用。随后,我们对比了四种配置方式(Java 代码、Yaml、Spring 命名空间、Spring Boot),并给出了具体示例。最后,从源码层面揭示了 Yaml 配置的加载与转换机制,帮助读者理解配置体系的底层实现。
掌握配置体系是熟练使用 ShardingSphere 的基础。后续,我们将基于这些配置,深入探讨分片引擎的执行流程、读写分离、数据脱敏等高级功能。
思考题:在 ShardingSphere 中,配置体系相关的核心类之间存在什么样的关联关系?结合本篇的类图,尝试画出 Yaml 配置到核心配置的完整转换链条。欢迎在评论区分享你的理解。