
🦌云深麋鹿
专栏 :C++ | 用C语言学数据结构 | Java

回顾:上篇标准库中的String类中,我们接触到了string类的各种较常用接口,接下来这篇文章让我们学着模拟它的底层实现吧~
放个目录
- [一 成员变量](#一 成员变量)
- [二 构造函数](#二 构造函数)
-
- [2.1 构造函数](#2.1 构造函数)
- [2.2 拷贝构造](#2.2 拷贝构造)
-
- [2.2.1 传统写法](#2.2.1 传统写法)
- [2.2.2 现代写法](#2.2.2 现代写法)
- [三 析构函数](#三 析构函数)
- [四 容量相关](#四 容量相关)
-
- [4.1 size](#4.1 size)
- [4.2 capacity](#4.2 capacity)
- [4.3 reserve](#4.3 reserve)
- [4.4 clear](#4.4 clear)
- [五 遍历](#五 遍历)
-
- [5.1 下标](#5.1 下标)
-
- [5.1.1 可修改版本](#5.1.1 可修改版本)
- [5.1.2 不可修改版本](#5.1.2 不可修改版本)
- [5.2 迭代器](#5.2 迭代器)
- [5.3 范围for](#5.3 范围for)
- [六 修改string](#六 修改string)
-
- [6.1 push_back](#6.1 push_back)
- [6.2 append](#6.2 append)
-
- [6.2.1 char](#6.2.1 char)
- [6.2.2 char*](#6.2.2 char*)
- [6.3 operator+=](#6.3 operator+=)
- [6.4 insert](#6.4 insert)
-
- [6.4.1 char](#6.4.1 char)
- [6.4.2 char*](#6.4.2 char*)
- [6.5 erase](#6.5 erase)
- [6.6 find](#6.6 find)
-
- [6.6.1 char*](#6.6.1 char*)
- [6.6.2 char](#6.6.2 char)
- [6.7 substr](#6.7 substr)
- [七 赋值函数](#七 赋值函数)
- [八 比较运算符重载](#八 比较运算符重载)
-
- [8.1 ==](#8.1 ==)
- [8.2 !=](#8.2 !=)
- [8.3 <](#8.3 <)
- [8.4 <=](#8.4 <=)
- [8.5 >](#8.5 >)
- [8.6 >=](#8.6 >=)
- [九 输入输出运算符重载](#九 输入输出运算符重载)
-
- [9.1 << 输出](#9.1 << 输出)
- [9.2 >> 输入](#9.2 >> 输入)
- [十 swap函数](#十 swap函数)
-
- [10.1 为什么要自己写一个swap](#10.1 为什么要自己写一个swap)
- [10.2 为什么swap是全局函数](#10.2 为什么swap是全局函数)
- [10.3 写一个string类里的swap](#10.3 写一个string类里的swap)
一 成员变量
cpp
char* _str = nullptr;
size_t _size = 0;
size_t _capacity = 0;声明的时候就直接给缺省值,以防没调用构造函数的随机情况。
1._str为字符数组,string类对它进行封装。
2._size描述了_str里的字符个数。(不包括 '\0')
3._capacity描述了_str的容量空间。(也不包括 '\0',所以我们开空间的时候要注意多开一个空间给 '\0')
二 构造函数
2.1 构造函数
cpp
string(const char* str = "")
:_size(str ? strlen(str) : 0)
{
_str = new char[_size + 1];
_capacity = _size;
if (str) {
memcpy(_str, str, _size + 1);
} else {
_str[0] = '\0';
}
}1.这里先用初始化列表初始化_size。
如果三个成员变量都用初始化列表是不合理的:
cpp
string(const char* str = "")
:_str(new char[_size + 1])
,_size(str ? strlen(str) : 0)
, _capacity(_size)
{}初始化_str的时候把_size展开成下面的三目表达式又会显得冗余。
2.这里用到三目运算符,处理了以下特殊情况:
cpp
string s(nullptr);3.函数体内,我们先给_str开辟空间,多开辟的一个空间是给 '\0' 留的。
4.把参数str的数据拷贝到_str,if-else依旧为了处理 2. 里的特殊情况。
5.这里用memcpy是为了把 '\0' (中间的或末尾的)也拷贝进_str。
2.2 拷贝构造
2.2.1 传统写法
cpp
string::string(const string& s)
{
if (s != nullptr) {
_capacity = s._capacity;
_size = s._size;
_str = new char[_capacity + 1];
memcpy(_str, s._str, _size + 1);
}
}1.排除 s 为 nullptr 的情况。
2.先初始化_capacity和_size。
3.用_capacity初始化_str。
4.类似于我们上一个构造函数,先new再memcpy。
2.2.2 现代写法
cpp
string::string(const string& s)
{
if (s != nullptr) {
string s2(s._str);
swap(s2);
}
}但是s._str中间可能会有 '\0' 。
cpp
string s("hello");
s += '\0';
s += "abc";
string s2(s);调试:

这样拷贝构造下来,s2就缺了后面半段。
所以我们用迭代区间的写法。
我们先写一个迭代器构造的代码模板:
cpp
template <class InputIterator>
string(InputIterator begin, InputIterator end) {
while (begin != end) {
*this += *begin;
++begin;
}
}从begin遍历到end,构造this。
再来写我们的拷贝构造:
cpp
string::string(const string& s)
{
if (s != nullptr) {
string s2(s.begin(), s.end());
swap(s2);
}
}调试:

三 析构函数
cpp
string::~string() {
if (_str != nullptr) {
delete[] _str;
_str = nullptr;
}
_size = _capacity = 0;
}1._str不是nullptr才释放空间。
2.再把_size和_capacity置零。
调试:

四 容量相关
4.1 size
cpp
size_t string::size() const {
return _size;
}返回_size,后面跟别的函数一起测试了。
4.2 capacity
cpp
size_t string::capacity() const {
return _capacity;
}返回_capacity。
4.3 reserve
预留空间。
cpp
void string::reserve(size_t capacity) {
if (capacity <= _size || capacity == _capacity) {
return;
}
char* newStr = new char[capacity + 1];
if (_str) {
memcpy(newStr, _str, _size + 1);
delete[] _str;
}
else {
newStr[0] = '\0';
}
_str = newStr;
_capacity = capacity;
}1.检查参数capacity,特殊情况直接返回。
2.先申请新的空间newStr。
3.这里申请 capacity + 1 个 char,最后的 +1 是给 '\0' 预留的。
4.若原_str不是nullptr,就把上面的数据拷贝到newStr。
5.若原_str是nullptr,就直接给newStr加上 '\0' 。
6._str指向我们要的空间newStr。
7.我们扩容完_str,修改_capacity。
4.4 clear
清空_str。
cpp
void string::clear() {
_str[0] = '\0';
_size = 0;
}测试代码:
cpp
string s("hello");
s.clear();调试运行:

五 遍历
5.1 下标
5.1.1 可修改版本
cpp
char& string::operator[](size_t pos) {
return _str[pos];
}测试代码:
cpp
string s("aaaaa");
for (int i = 0;i < s.size();++i) {
cout << ++s[i] << endl;
}运行:
5.1.2 不可修改版本
cpp
const char& string::operator[](size_t pos) const {
return _str[pos];
}测试代码:
cpp
const string s("aaaaa");
for (size_t i = 0;i < s.size();++i) {
cout << ++s[i] << endl;
}编译器报错:

5.2 迭代器
我们用指针模拟实现。
首先实现begin函数:
cpp
string::iterator string::begin() const {
return _str;
}和end函数:
cpp
string::iterator string::end() const {
return &_str[_size];
}定义一下迭代器:
cpp
typedef char* iterator;
typedef const char* const_iterator;测试代码(可修改):
cpp
string::iterator it = s.begin();
while (it != s.end()) {
cout << ++(*it) << endl;
++it;
}运行结果:
测试代码(不可修改):
cpp
string::const_iterator it = s.begin();
while (it != s.end()) {
(*it)++;
cout << *it << endl;
++it;
}编译器报错:

5.3 范围for
我们实现了begin函数和end函数,自然就可以用了。
cpp
for (char c:s) {
cout << c << endl;
}运行结果:
六 修改string
6.1 push_back
cpp
void string::push_back(char c) {
if (_size == _capacity) {
size_t newCapacity = _capacity == 0 ? 4 : _capacity * 2;
this->reserve(newCapacity);
}
_str[_size++] = c;
_str[_size] = '\0';
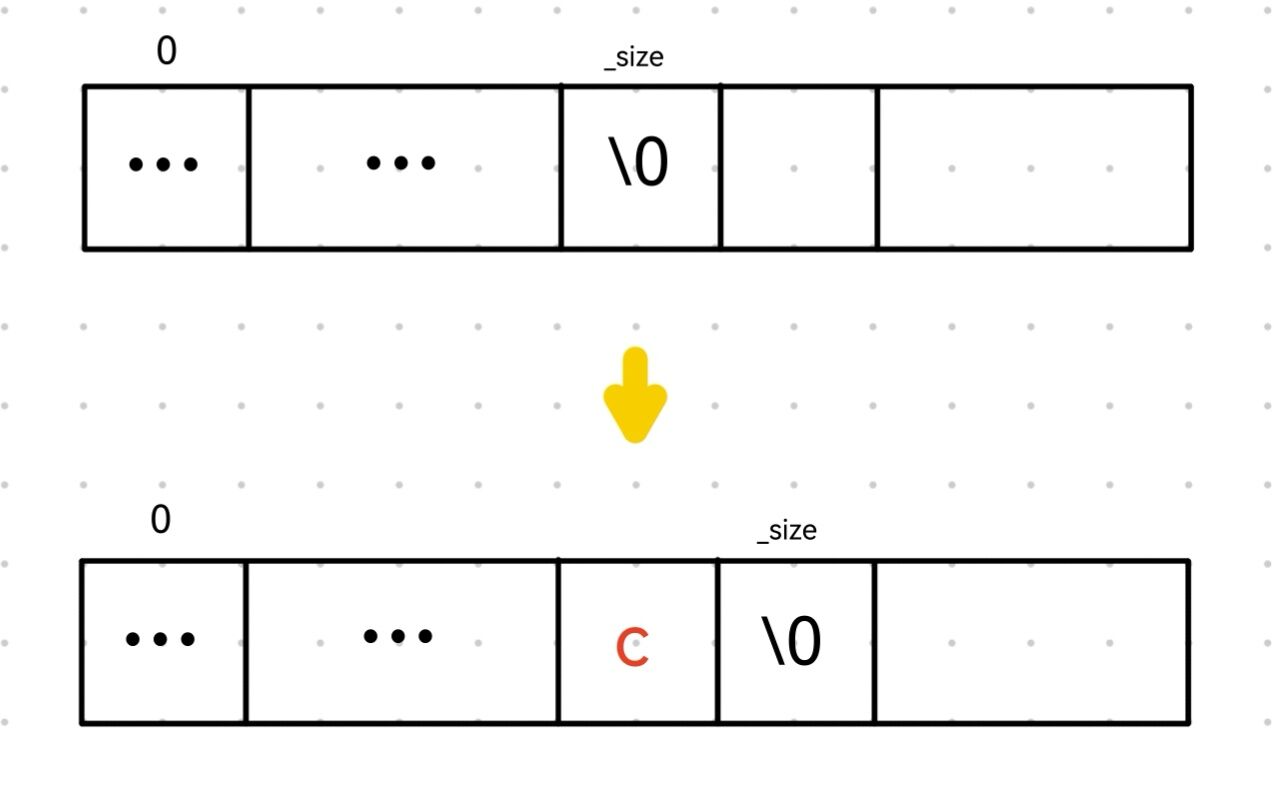
}1.如果满了(_size == _capacity)就扩容。
2.完了看图,后面的操作如图所示。
写个测试代码:
cpp
string s("hello");
s.push_back(':');
s.push_back(')');调试:

6.2 append
6.2.1 char
cpp
void string::append(size_t n, char c) {
if (n + _size >= _capacity) {
size_t newCapacity = (n + _size) > (_capacity * 2) ? n + _size : _capacity * 2;
this->reserve(newCapacity);
}
for (size_t i = 0;i < n;++i) {
_str[_size++] = c;
}
_str[_size] = '\0';
}1.这里也是先扩容。
2.跟 push_back 不一样的地方是:一条语句变成了一个for循环。
3.'\0' 不能忘。
写个测试代码:
cpp
string s("hello");
s.append(15,'a');调试:

1.这里原_capacity为5,2倍是10(小)。
2.参数n是15,15+5是20(大)。
3.所以 newCapacity 取 20。
继续调试:

6.2.2 char*
cpp
void string::append(const char* s) {
size_t length = strlen(s);
if (length + _size >= _capacity) {
size_t newCapacity = (length + _size) > (_capacity * 2) ? length + _size : _capacity * 2;
this->reserve(newCapacity);
}
for (size_t i = 0;i < length;++i) {
_str[_size++] = s[i];
}
_str[_size] = '\0';
}- 可以看出来跟①的不同点就是n变成了length。
测试代码:
cpp
s.append(" world");调试:

6.3 operator+=
接下来是我们很爱用的+=,我们直接复用前面的代码。
cpp
string& string::operator+=(char c) {
this->push_back(c);
return *this;
}
string& string::operator+=(const char* s) {
this->append(s);
return *this;
}- 返回引用方便连续+=。
测试代码:
cpp
string s("hello");
(s += ':') += ')';
s += " world";调试:

继续:

6.4 insert
6.4.1 char
先上一个我原先的代码,是错误代码:
cpp
string& string::insert(size_t pos, size_t n, char c) {
if (n == 0) {
return *this;
}
assert(pos <= _size);
if (n + _size > _capacity) {
size_t newCapacity = (n + _size) > (_capacity * 2) ? n + _size : _capacity * 2;
this->reserve(newCapacity);
}
for (size_t i = _size;i >= pos;--i) {
_str[i + n] = _str[i];
}
for (size_t i = pos;i < pos + n;++i) {
_str[i] = c;
}
_size += n;
return *this;
}如果我头插,pos为0,第一个for循环就会变成死循环。
cpp
string s("hello");
s.insert(0, 1, ':');可以看到运行后,退出代码不是0:

为什么死循环了呢?
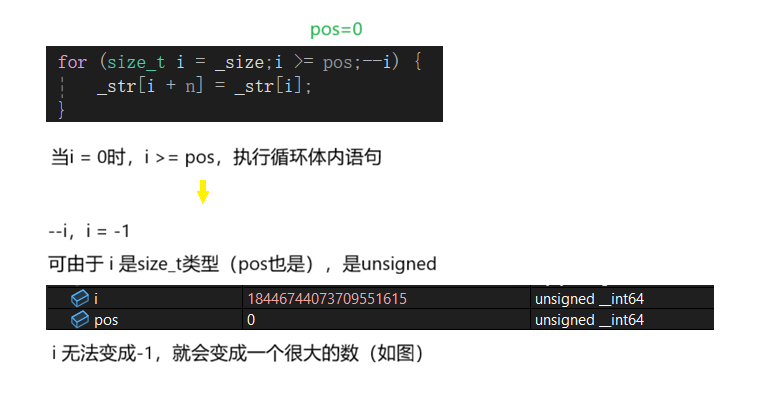
因为 i 永远都无法减到 -1 退出循环。
所以我们给这个for循环换个写法:
cpp
for (size_t i = _size + n;i >= pos + n;--i) {
_str[i] = _str[i - n];
}调试成功:

还有一种更高效的写法:
cpp
if (_size > pos) {
memmove(_str + pos + n, _str + pos, (_size - pos + 1) * sizeof(char));
}6.4.2 char*
cpp
string& string::insert(size_t pos, const char* s) {
if (s == nullptr) {
return *this;
}
assert(pos <= _size);
size_t length = strlen(s);
if (length == 0) {
return *this;
}
if (length + _size > _capacity) {
size_t newCapacity = (length + _size) > (_capacity * 2) ? length + _size : _capacity * 2;
this->reserve(newCapacity);
}
if (_size > pos) {
memmove(_str + pos + length, _str + pos, (_size - pos + 1) * sizeof(char));
}
for (size_t i = 0;i < length;++i) {
_str[i + pos] = s[i];
}
_size += length;
return *this;
}写测试代码:
cpp
string s("hello");
s.insert(0, 1, ':');
s.insert(0, "(");
s.insert(0,"(((((");调试:

6.5 erase
cpp
string& string::erase(size_t pos, size_t len) {
assert(pos < _size);
if (len == npos || pos + len >= _size) {
_str[pos] = '\0';
_size = pos;
return *this;
}
if(pos + len < _size) {
memmove(_str + pos, _str + pos + len, (_size - pos - len + 1) * sizeof(char));
}
_size -= len;
return *this;
}写测试代码:
cpp
string s("hello");
s.insert(0, 1, ':');
s.insert(0, "(");
s.insert(0,"(((((");
s.erase(0,7);调试:

6.6 find
6.6.1 char*
我们可以和C语言strstr函数相比较来看。

cpp
string s("hello");
char* pch = strstr(s.c_str(), "lo");
if (pch) {
size_t find1 = pch - s.c_str();
cout << find1 << endl;
}strstr返回的是char*类型的。
运行:

我们再来看find的模拟实现代码:
cpp
size_t string::find(const char* s, size_t pos) const {
if (s == nullptr || pos >= _size) {
return npos;
}
size_t len = strlen(s);
if (len == 0) {
return npos;
}
for (size_t i = pos;i < _size;++i) {
size_t j = 0;
while (_str[i+j] == s[j++]) {
if (j >= len) {
return i;
}
}
}
return npos;
}1.排除特殊情况:要找的字符串参数s为空指针,参数pos位置无效(超过被找字符串的_size),参数s为空字符串(即strlen(s)为0)。
2.进入for循环,下标i 遍历被找字符串;进入while循环,下标j 遍历参数s。
3.若 j 遍历了一整遍 参数s,if 判断 j >= len,则返回 s 被找到的首位置(即 下标i)。
4.否则 for 循环结束还没找到,返回npos。
写测试代码:
cpp
string s("hello");
size_t find2 = s.find("lo",1);
if (find2 != string::npos) {
cout << find2 << endl;
}运行:

6.6.2 char
cpp
size_t string::find(char c, size_t pos) const {
if (pos >= _size) {
return npos;
}
for (size_t i = pos;i < _size;++i) {
if (_str[i] == c) {
return i;
}
}
return npos;
}1.if语句排除pos参数不合法情况。
2.for语句从pos位置开始开始找参数c,找到返回下标。
3.否则未找到,返回npos。
写测试代码:
cpp
size_t find3 = s.find('l', 1);
if (find3 != string::npos) {
cout << find3 << endl;
}运行:

6.7 substr
cpp
string string::substr(size_t pos, size_t len) const {
if (pos >= _size || len == 0) {
return string();
}
size_t actual_len = std::min(len, _size - pos);
return string(_str + pos, _str + pos + actual_len);
}1.排除pos参数不合法 和 参数len不合法情况。
2.定义actual_len,用来存储合法长度(不超过最大长度_size - pos)。
3.迭代器构造,返回构造好的string。
测试代码:
cpp
string s1 = s.substr(2,2);
cout << s1.c_str() << endl;运行:

七 赋值函数
cpp
string& string::operator=(const string& s) {
if (this != &s) {
string tmp(s);
swap(tmp);
}
return *this;
}1.if语句排除自己给自己赋值的情况。
2.进入if语句,构造(复用拷贝构造)临时对象存储对s的拷贝。
3.交换临时对象 tmp 和 this,避免改变参数s。
4.完成赋值,返回当前this。
测试代码:
cpp
string s("hello");
string s1 = s;测试调试:

八 比较运算符重载
8.1 ==
cpp
bool string::operator==(const string& s) const {
if (_size != s._size) {
return false;
}
if (_str == nullptr || s._str == nullptr) {
return false;
}
for (int i = 0;i < _size;++i) {
if (_str[i] != s[i]) {
return false;
}
}
return true;
}1.排除俩string的_size不相等的情况。
2.排除俩string有一个为nullptr的情况。
3.遍历俩string,一一比较是否相等。
4.遍历完了都没有不相等的就返回true。
测试代码:
cpp
string s1("hello");
string s2(s1);
cout << ( s1 == s2 ) << endl;运行:

8.2 !=
cpp
bool string::operator!=(const string& s) const {
return !(*this == s);
}复用==的代码。
测试代码:
cpp
string s1("hello");
string s2(s1);
cout << ( s1 != s2 ) << endl;运行:

8.3 <
cpp
bool string::operator<(const string& s) const {
if (_str == nullptr || s._str == nullptr) {
return _str == nullptr && s._str != nullptr;
}
size_t size = std::min(_size, s._size);
for (int i = 0;i < _size;++i) {
if (_str[i] > s[i]) {
return false;
}
else if (_str[i] < s[i]) {
return true;
}
}
return _size < s._size;
}1.特殊处理nullptr情况。
① 若_str为nullptr,且s._str不为nullptr,则<,返回true。
② 否则_str和s._str都为nullptr,返回false。
③ s._str为nullptr,且_str不为nullptr,返回false。
2.定义size变量,存储要比较的俩string中较短的_size。
3.遍历俩string分三种情况: >(返回false), <(返回true),=(继续遍历比较)。
4.遍历完后若this还有多(即_size > s._size)则返回false,s还有多则返回true。(即_size < s._size)
测试代码:
cpp
string s1("hello");
string s2("helloo");
cout << ( s1 < s2 ) << endl;运行:

8.4 <=
cpp
bool string::operator<=(const string& s) const {
return *this == s || *this < s;
}代码复用。
测试代码:
cpp
string s1("hello");
string s2(s1);
string s3("helloo");
cout << ( s1 <= s2 ) << endl;
cout << ( s1 <= s3 ) << endl;运行:

8.5 >
cpp
bool string::operator>(const string& s) const {
return !(*this <= s);
}代码复用+1。
测试代码:
cpp
string s1("hello");
string s3("helloo");
cout << ( s3 > s1 ) << endl;运行:

8.6 >=
cpp
bool string::operator>=(const string& s) const {
return *this == s || *this > s;
}代码复用+1。
测试代码:
cpp
string s1("hello");
string s3("helloo");
string s4(s3);
cout << ( s3 >= s1 ) << endl;
cout << ( s3 >= s4 ) << endl;运行:
九 输入输出运算符重载
9.1 << 输出
cpp
ostream& operator<<(ostream& out, const string& s) {
for (size_t i = 0;i < s.size();++i) {
out << s[i];
}
return out;
}1.遍历各字符输出。
2.返回ostream对象,以便连续输出。
测试代码:
cpp
string s("hello");
cout << s << endl;运行:

9.2 >> 输入
cpp
istream& operator>>(istream& in, string& s) {
s.clear();
const size_t BUFFER_SIZE = 256;
char buff[BUFFER_SIZE];
size_t i = 0;
char c;
while (in.get(c) && c != '\n' && c != ' ') {
buff[i++] = c;
if (i == BUFFER_SIZE) {
s += buff;
i = 0;
}
}
if (i > 0) {
s += buff;
}
return in;
}1.输入前先清空待输入对象s。
2.在栈上开个buff缓存区(比直接加到s上效率高些),i用来记录缓存区末尾。
3.循环读取in中输入字符,默认结束符为 换行符'\n' 和 空格' '
4.循环读取字符c往buff里放。
5.buff满了就往s上加,buff刷新(即i = 0)。
6.最后结束循环,若buff里还有,直接往s上加。
7.返回istream对象,以便连续输入。
测试代码:
cpp
string s("hello");
cin >> s;运行输入:

调试:

十 swap函数
10.1 为什么要自己写一个swap
我们当前的自定义类型string,不能用算法库的swap函数,因为调用后类似于浅拷贝的"浅交换"的效果。
cpp
string s1("hello");
string s2("nihao");
std::swap(s1,s2);我们调试运行:

执行swap:

可以看到俩_str地址都改变了,但我们不想要这种效果,这种明显底层是深拷贝,效率太低了。
10.2 为什么swap是全局函数
这样就可以直接用,不用指明从属类:
cpp
string s1("hello");
string s2("nihao");
swap(s1,s2);调试运行:

swap后:

10.3 写一个string类里的swap
cpp
void string::swap(string& s2) {
std::swap(_str, s2._str);
std::swap(_size,s2._size);
std::swap(_capacity, s2._capacity);
}分别交换仨变量。
测试代码:
cpp
string s1("hello");
string s2("nihao");
s1.swap(s2);测试运行:

swap后:

可以看到俩_str地址还是原来那俩,只交换指针效率更高了。
容器string的学习就到这里啦,下一篇 容器vector 不久后就会更出来啦~

