
大家好,我是半夏之沫 😁😁 一名金融科技领域的JAVA 系统研发😊😊
我希望将自己工作和学习中的经验以最朴实 ,最严谨 的方式分享给大家,共同进步👉💓👈
👉👉👉👉👉👉👉👉💓写作不易,期待大家的关注和点赞💓👈👈👈👈👈👈👈👈
1. 注意力机制Attention
帝江号 最近新招募了一位干员 ,名字叫汤汤。
干员能力的高低,用能力值 来表示,能力值 的评定暂时基于干员的力量 属性,下面是帝江号上已经招募的干员的力量 属性和其能力值的对应关系。
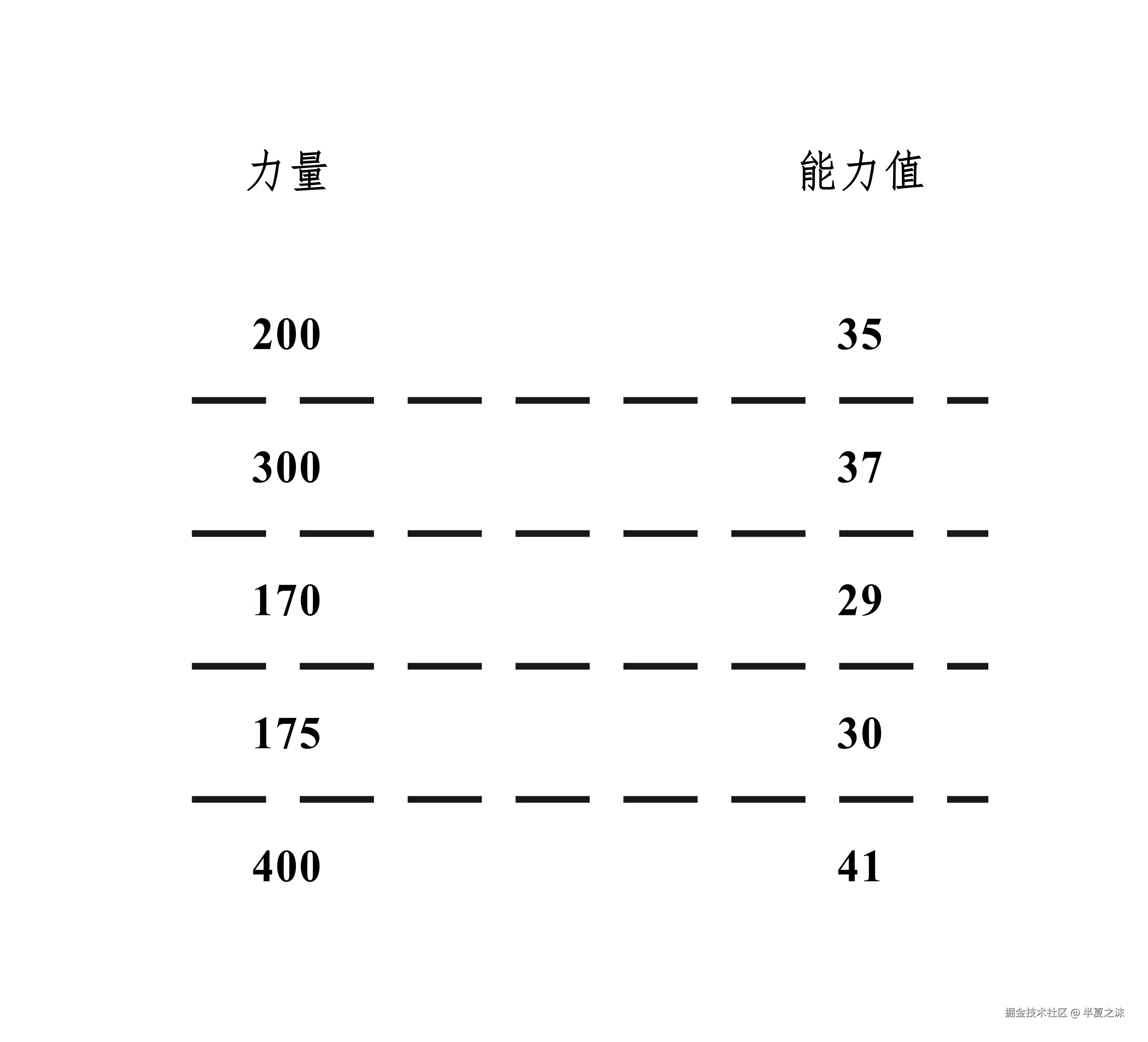
现在已知汤汤 的力量是207 ,那么汤汤 的能力值该如何计算。
塔卫二 的守护者,巴别塔恶灵 意志的传承者-管理员自然有一套计算方式。

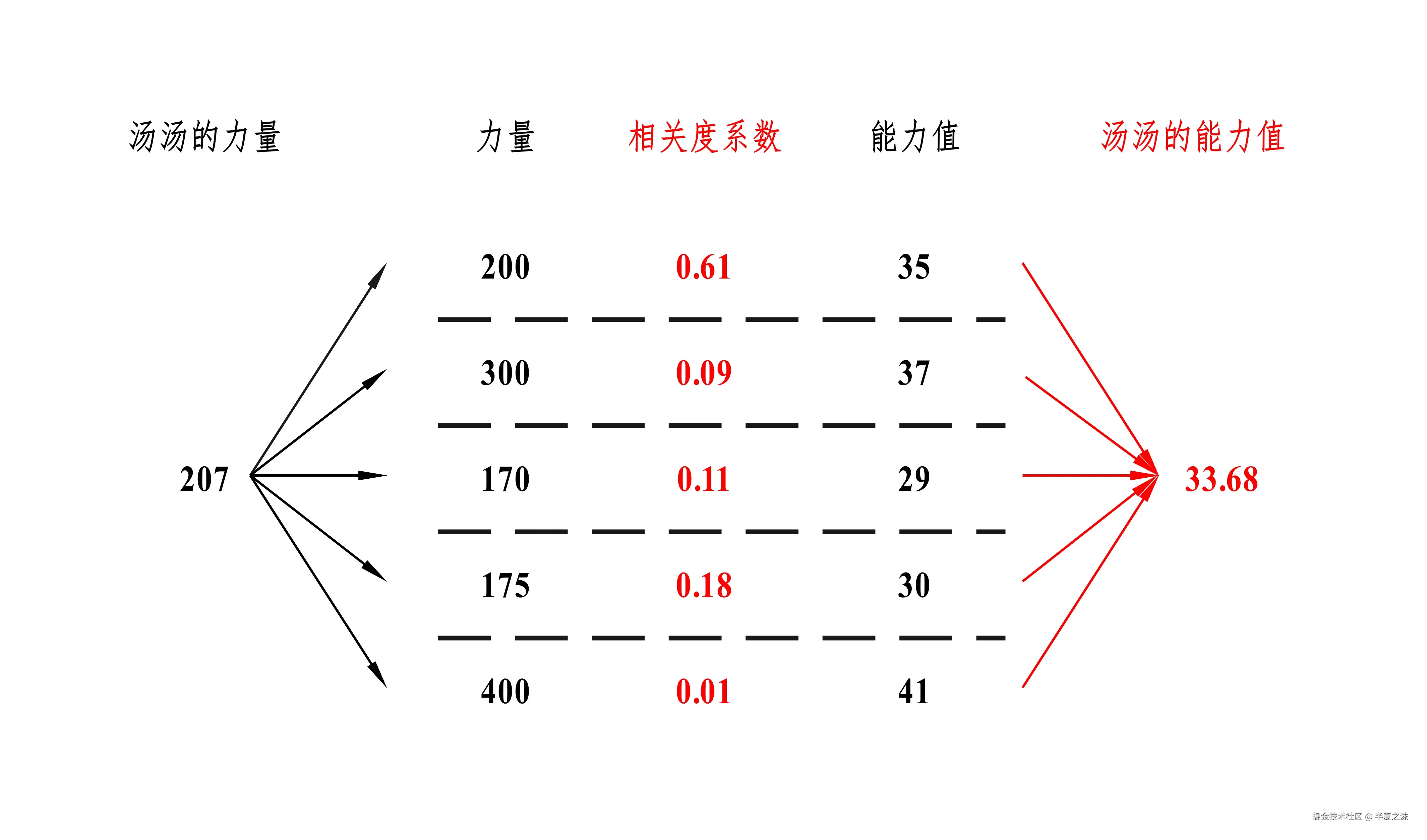
既然汤汤 的力量是207 ,管理员觉得根据汤汤的力量 去与已有干员的力量进行相关度系数 计算,然后再分别将已有干员的能力值与相关度系数做加权求和,就可以得到汤汤的能力值,如下所示。
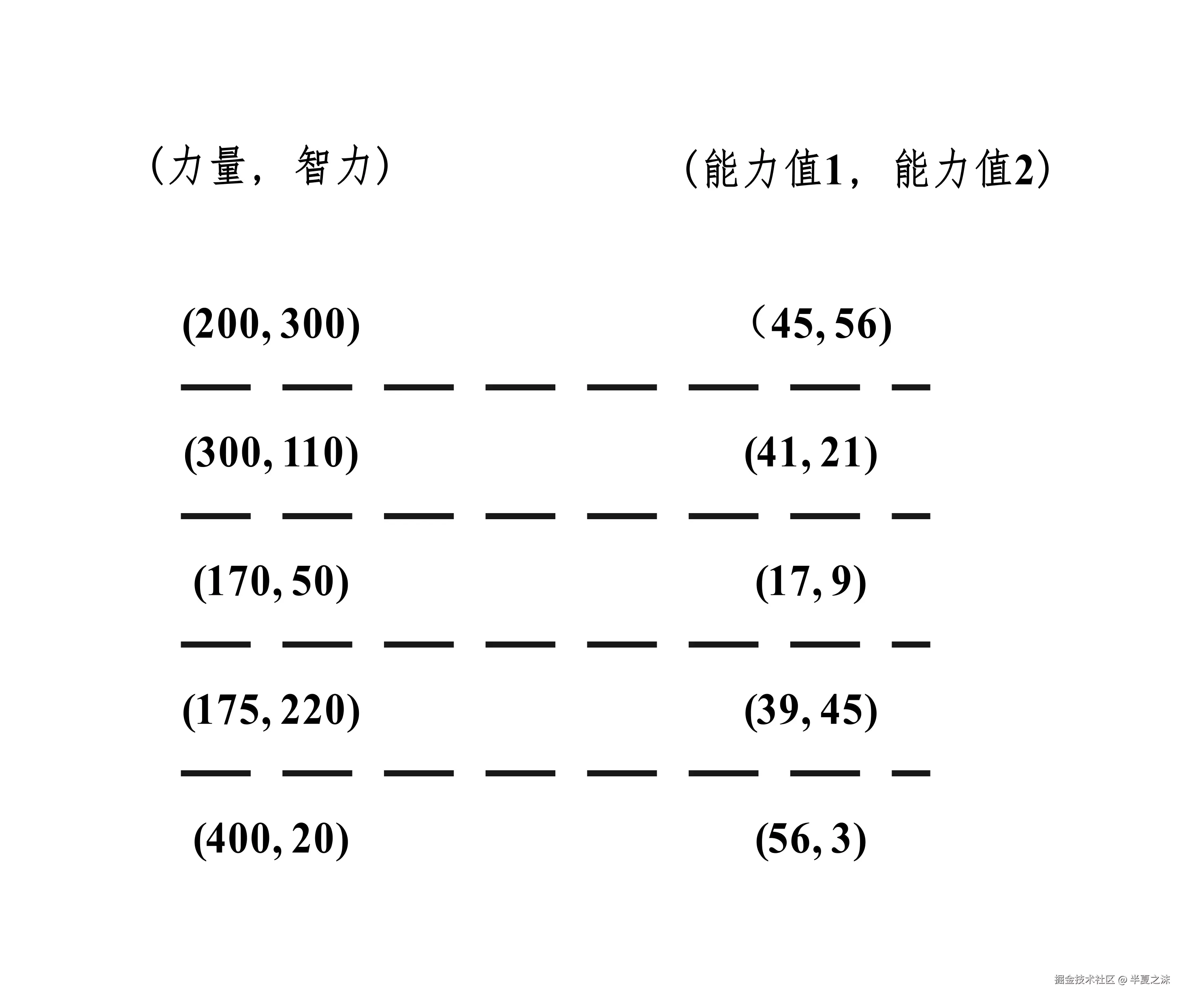
但是干员不仅仅有力量 属性,还会有智力 属性,如果只 靠力量评估干员的能力值,评判结果难以让干员信服,所以管理员基于力量 和智力,重新给已有干员做了能力值评估,如下所示。
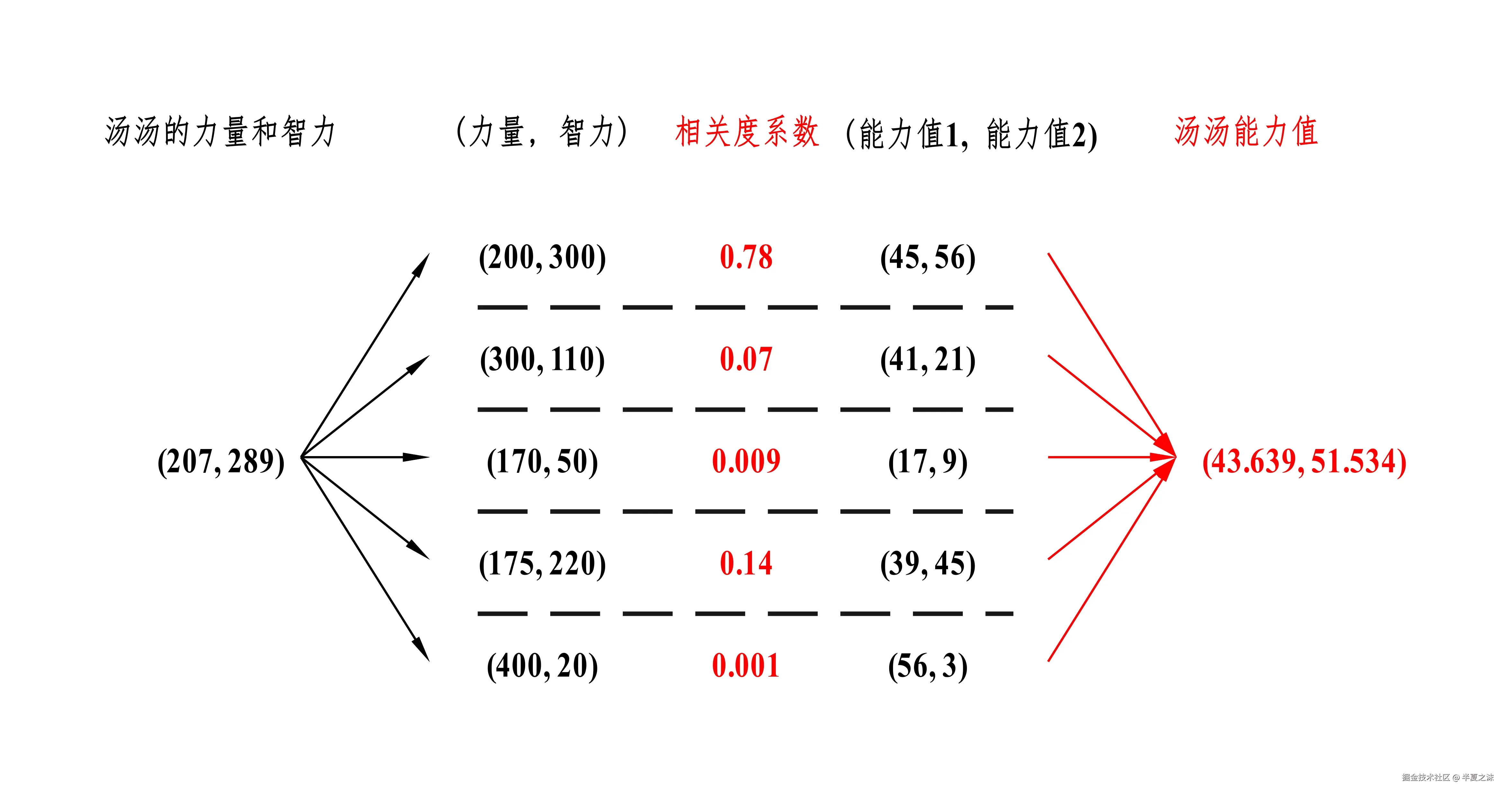
已知汤汤 的力量是207 ,智力是289 ,重新计算相关度系数 ,然后加权求和 ,得到汤汤的能力值如下所示。
随着游戏版本来到3.0 ,干员属性的个数扩充到了12288 ,此时干员能力值的计算就变成下面这样。

在该情景下,要评判汤汤 的能力值,需要参考已有干员的能力值情况,如果有一个干员的属性和汤汤的相似度 很高 ,那么在评估汤汤的能力值时就应该更多 的参考这个干员的能力值情况,即需要将更多 的注意力 放在和汤汤属性相似度更高 的干员身上,这就是注意力机制。
2. 自注意力机制Self-Attention
现在管理员 手下有一批干员 ,干员数量为50 个,每个干员的属性个数有12288个。
这50个干员的属性可以表示如下。

现在管理员 觉得既然大家作为一个Team,彼此之间需要多交流切磋。
对于每个干员而言,都需要从自己的角度出发,判断自己对每个干员的注意力高低,自己越 注意的干员,就越应该从这个干员身上学习一些属性。
陈千语 此时犯了迷糊,问管理员 怎么才能判断自己对每个干员的注意力 高低呢,管理员说需要将更多的注意力给到和自己属性更加相似的干员。
当每个干员都根据各自对其他干员的注意力 高低完成了属性学习后,每个干员的属性就会因为受到其他干员的影响而发生一点变化,下图展示了汤汤的属性变化过程。
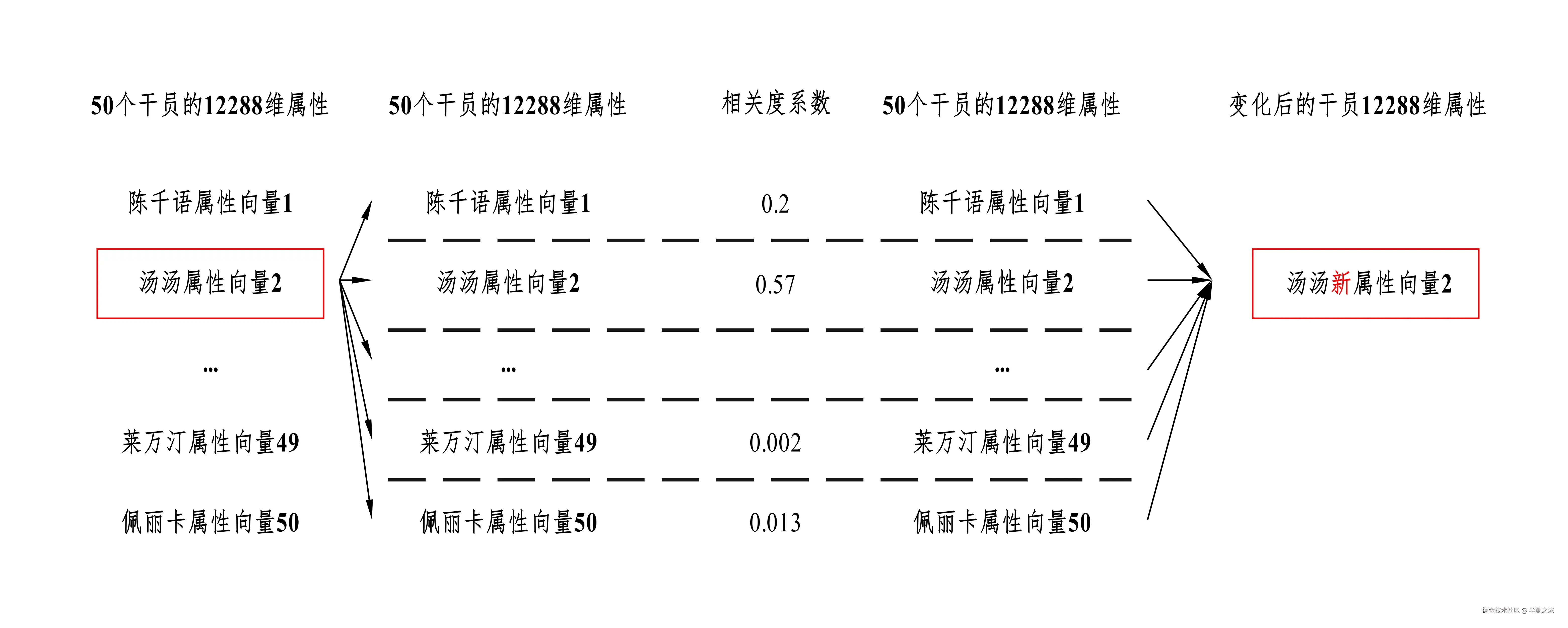
根据上面的变化过程,可以依次得到50个干员变化后的属性。
但这个时候管理员 觉得还有问题,因为终末地 里有很多副本,干员的属性在不同的副本里其实是需要调整 的,所以干员间的注意力 需要和干员在不同 副本里的属性的相似度有关,此时管理员通过神经网络学习得到了三个矩阵。
- 其中一个矩阵是 Wq,将干员的12288 维属性通过 Wq做一次线性变换就能得到干员在影拓丰碑 副本里面的12288 维属性,称这组属性是 q属性;
- 其中一个矩阵是 Wk,将干员的12288 维属性通过 Wk做一次线性变换就能得到干员在协议空间 副本里面的12288 维属性,称这组属性是 k属性;
- 其中一个矩阵是 Wv,将干员的12288 维属性通过 Wv做一次线性变换就能得到干员在密境行者 副本里面的12288 维属性,称这组属性是 v属性。
现在重新展示汤汤的属性变化过程。
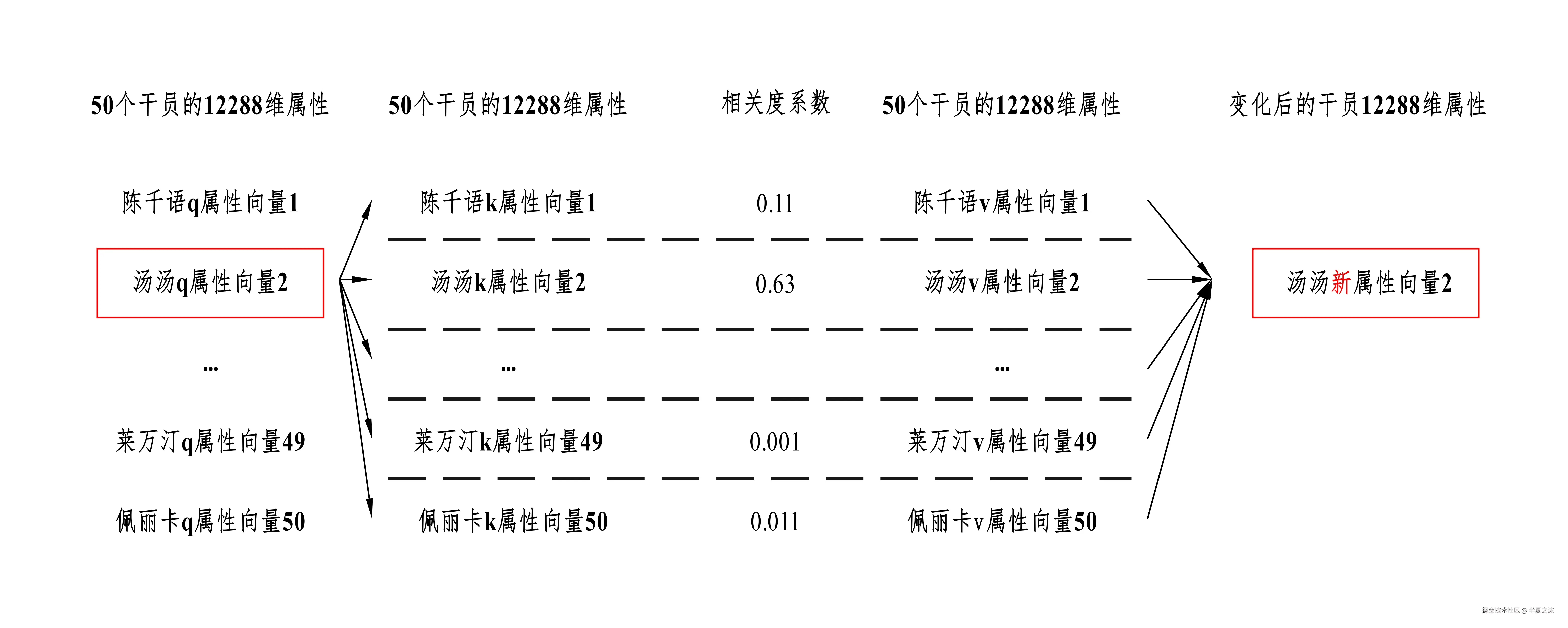
根据上面的变化过程,可以依次得到50个干员变化后的属性。
将50 个干员的 q属性(查询向量Query )全部组合在一起就能得到一个 50×12288的 Q矩阵。
将50 个干员的 k属性(键向量Key )全部组合在一起就能得到一个 50×12288的 K矩阵。
将50 个干员的 k属性(值向量Key )全部组合在一起就能得到一个 50×12288的 V矩阵。
自注意力机制 就是组内的每个干员都用自己在不同 副本里的属性来和组内 干员在不同副本里的属性计算相关度系数 ,相关度系数越高 则表明对这个干员的注意力 就需要越高,从而就应该学习这个干员更多的属性。
3. 多头自注意力机制Multi-head Self Attention
在终末地 更新了多个版本之后,管理员觉得之前的 Wq, Wk和 Wv不是那么好了,因为每个版本都有不同的副本,干员的属性在每个版本的不同副本里都应该得到调整,聪明的管理员立马想到了解决办法,那就是准备多组 Wq, Wk和 Wv,因为现在已经更新了96 个版本,所以管理员通过神经网络 学习了96 组 Wq, Wk和 Wv,并且聪明的管理员还将 W矩阵的维度从 12288×12288维降低到了 12288×128,这样可以在计算相关度系数时极大的降低计算量。
引入了96 组 12288×128维度的 Wq, Wk和 Wv后,再来看看汤汤的属性变化过程。
因为 Wq, Wk和 Wv的维度变成了 12288×128,所以每个版本得到的属性向量只有128 维,但一共有96 个版本,所以把96 个版本得到的属性向量全部拼接起来就可以还原回12288 维的属性向量,最后通过一个 12288×12288维的 Wo进行线性变换后,就可以得到汤汤 的变换后的12288维属性向量。
这就是多头自注意力机制 ,在自注意力机制 上将一组 Wq, Wk和 Wv扩展成了多组 Wq, Wk和 Wv,让干员的属性能在不同版本的不同副本里进行相关度计算,最终干员的变换后的属性就包含其他干员在不同版本不同副本里的属性信息。
4. 公式补充
自注意力 机制多用于计算一段 文字中一个 词对另一个 词的依赖关系,从而让每个 词都能聚合上下文信息。
将一段文字进行Tokenization ,Embedding 和Positional Encoding 后,这段文字的每一个Token 都可以表示成一个向量 x,这段文字的所有Token 的向量可以表示成 {xi∈Rd}i=1t,这里 t表示Token 个数, d表示每Token的向量维度。
在自注意力 机制中有三个元素,分别是查询 qi,键 ki和值 vi,这三个元素是通过输入向量 x经过 Wq, Wk和 Wv做线性变换依次得到的,表示如下。
xiWq=qi
xiWk=ki
xiWv=vi
其中 Wq∈Rd×dq, Wk∈Rd×dk, Wv∈Rd×dv, {qi∈Rdq}i=1t, {ki∈Rdk}i=1t, {vi∈Rdv}i=1t。
如果要计算 i位置的Token 需要聚合 的上下文信息,首先 需要将 qi分别与 k做点积 运算得到匹配分数,如下所示。
qi⋅k1
qi⋅k2
...
qi⋅kt
然后 需要对所有匹配分数进行缩放,如下所示。
d qi⋅k1
d qi⋅k2
...
d qi⋅kt
再然后 做 Softmax就得到了相关系数,如下所示。
j=1∑ted qi⋅kjed qi⋅k1
j=1∑ted qi⋅kjed qi⋅k2
...
j=1∑ted qi⋅kjed qi⋅kt
最后 将相关度系数与 {vi∈Rdv}i=1t进行加权求和 就可以得到 i位置的Token 聚合完上下文信息后的向量 zi。
zi=j=1∑ted qi⋅kjed qi⋅k1v1+j=1∑ted qi⋅kjed qi⋅k2v2+...+j=1∑ted qi⋅kjed qi⋅ktvt
上述计算过程就是下面公式的展开。
Z=Attention(Q,K,V)=Softmax(d QKT)V
在引入多头自注意力机制 后, i位置的Token 的向量 xi需要通过 N组 Wq, Wk和 Wv线性变换到 N个不同表示子空间 中,然后通过上述计算得到 N组 Z={zi∈Rdv}i=1t, N组 Z首尾拼到一起可以得到 {zi∈RNdv}i=1t,最后将拼接得到的 Z再通过一个 Wo∈RNdv×d做线性变换得到最终 的输出,最终的输出中 i位置的Token 就聚合了不同表示子空间中上下文的信息。
大家好,我是半夏之沫 😁😁 一名金融科技领域的JAVA 系统研发😊😊
我希望将自己工作和学习中的经验以最朴实 ,最严谨 的方式分享给大家,共同进步👉💓👈
👉👉👉👉👉👉👉👉💓写作不易,期待大家的关注和点赞💓👈👈👈👈👈👈👈👈
