一、 引言:Serverless 时代的分布式内核革命
1.1 行业背景与挑战
Serverless 从概念提出至今,经历了从 FaaS(函数即服务)到通用计算平台的演进,其核心逻辑始终未变:让开发者专注于业务而非基础设施。但生成式 AI 的爆发正在改写这一叙事------当大模型训练动辄需要千卡集群、推理场景对延迟极度敏感时,传统 Serverless 架构在异构资源调度、显存管理、冷启动优化等维度开始显得力不从心。
当下的 AI 工程实践普遍存在一个矛盾:开发者被迫在易用性与性能之间做取舍。选择 Ray、Spark 或 Kubernetes 这类成熟框架,意味着要显式处理分布式状态、节点容错、数据亲和性等底层细节;而追求简化部署的托管服务,往往又难以满足 GPU 利用率与通信效率的严苛要求。这种"显式分布式"的开发模式,实质上把本应由基础设施承担的复杂性转嫁到了应用层。
硬件层面的约束同样尖锐。GPU/NPU 的 HBM 容量增长远慢于模型参数规模,迫使系统必须在 HBM、主机内存、持久化存储之间频繁换入换出数据。问题在于,传统 I/O 栈的多级缓冲设计带来了过多的数据搬运开销------在某些推理场景中,拷贝耗时甚至超过实际计算时间。
1.2 openYuanrong 的核心愿景
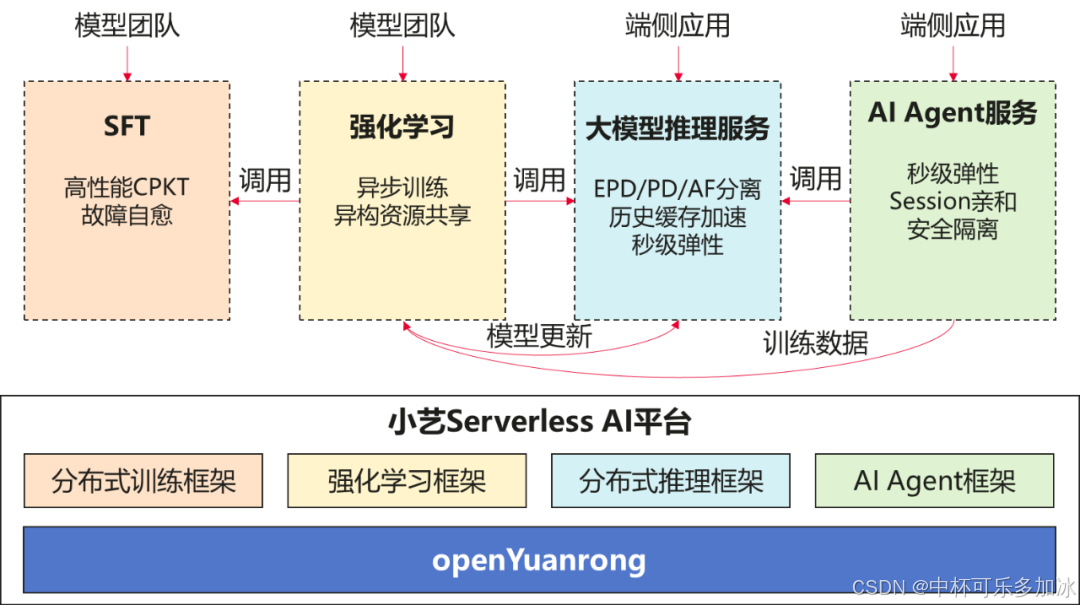
在这一背景下,华为开源了业界首个 Serverless 分布式计算引擎 ------ openYuanrong,其用"分布式内核"的思路重新界定 Serverless 的边界。

其设计目标可以概括为一句话:让分布式集群的编程体验逼近单机。它不仅提供了单机般的编程体验,更在底层通过创新的分布式内核技术,实现了极致的运行性能。
openYuanrong 通过"分布式内核"的设计理念,屏蔽底层硬件的复杂性,通过将计算与数据深度耦合,openYuanrong 能够实现毫秒级的任务调度和近乎零拷贝的数据访问,为大模型推理等高性能场景提供了坚实的基础设施支撑。
本文将重点深入探讨 openYuanrong 的数据系统如何支持 GPU 生态,利用 GPU 硬件实现 D2D(Device-to-Device)高速传输,并构建多级缓存体系以大幅提升推理性能。
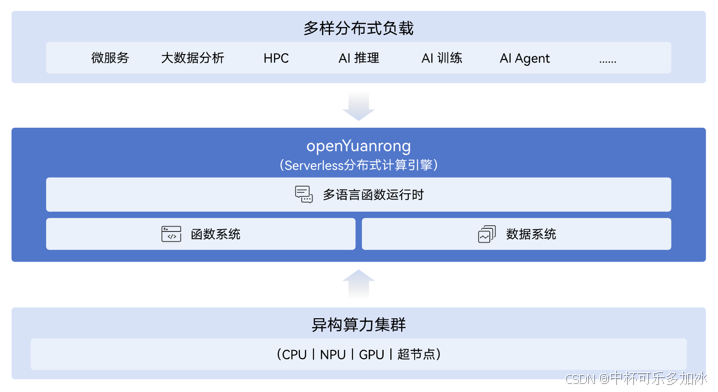
二、 openYuanrong 架构全景
2.1 多语言函数运行时与 DPOSIX 标准
openYuanrong 的架构设计遵循了"解耦与协同"的原则,通过三大核心子系统实现了"单机编程、分布式运行"的目标。
多语言函数运行时(Function Runtime) 是 openYuanrong 的执行基石,支持 Python、Java、C++、Go 等多种主流编程语言。系统通过轻量化沙箱技术实现了高性能的实例隔离,确保了多租户环境下的安全性。openYuanrong 创新性地提出了分布式 POSIX(DPOSIX)标准。传统的 POSIX 是为单机操作系统设计的,而 DPOSIX 将其扩展到了分布式环境。
它定义了一套标准的函数(Function)、状态(State)、数据对象(Object)和数据流(Stream)抽象。通过 DPOSIX,开发者可以使用熟悉的编程范式来处理跨节点的资源,系统底层会自动处理复杂的网络通信、一致性维护和容错机制。这种抽象不仅降低了开发难度,还为跨平台的 Serverless 应用提供了标准化的运行环境。
2.2 函数系统
函数系统(Function System) 负责实例的生命周期管理、细粒度调度和弹性伸缩。调度器能够感知数据的位置,尽量将计算任务分配到数据所在的节点,减少网络传输。通过实例预热、快照恢复和轻量化启动协议,openYuanrong 实现了毫秒级的冷启动响应,远超传统容器的启动速度。这种细粒度的调度能力,结合对数据局部性的感知,能够有效降低数据传输开销,提升整体计算效率。
2.3 数据系统
数据系统(Data System) 是 openYuanrong 的存储底座,定位为内存中心、随计算节点分布的异构缓存层。它对集群内的所有数据对象暴露统一访问接口,并在底层自动处理 HBM、DRAM、SSD 之间的数据升降级与淘汰策略。
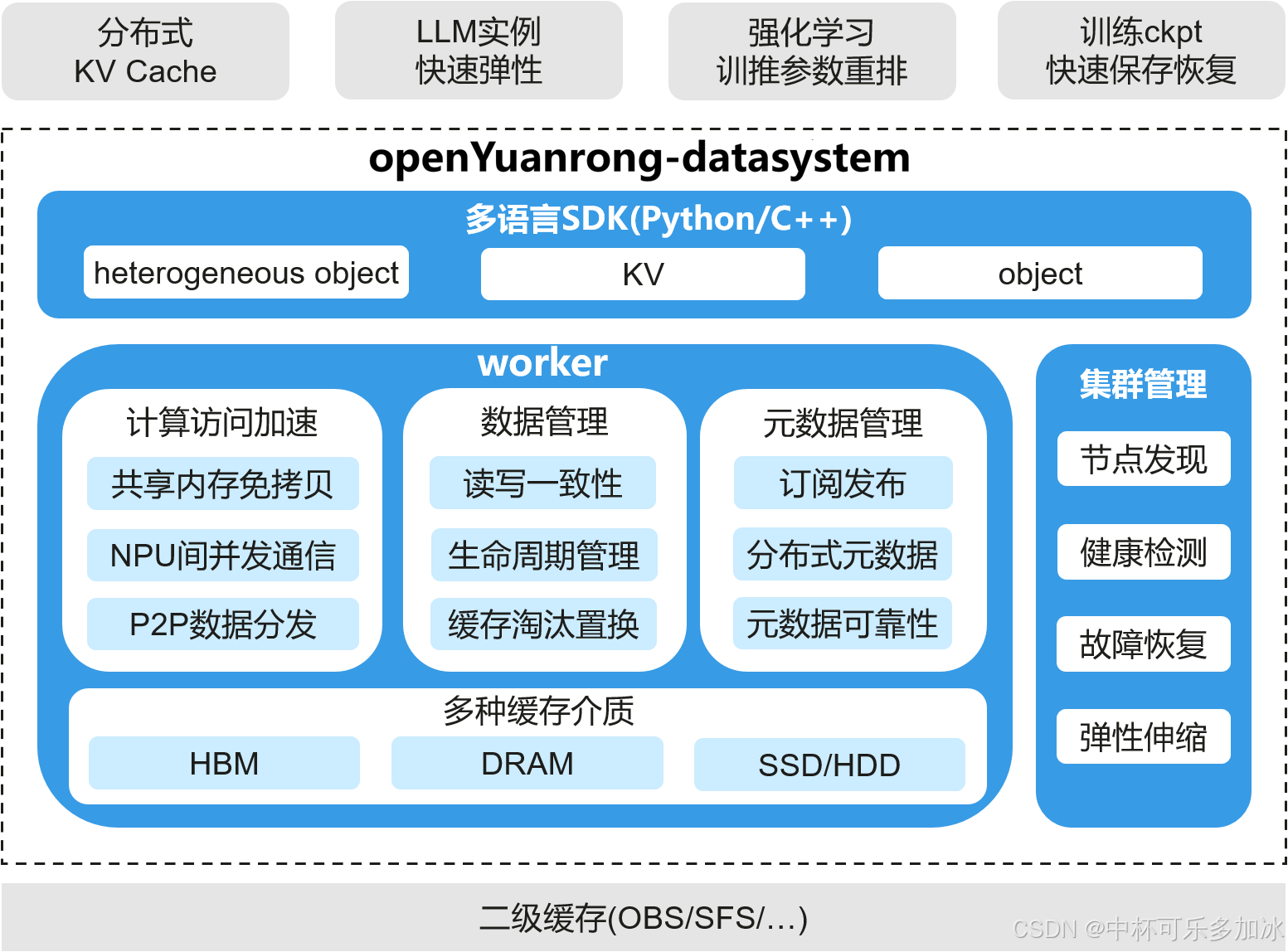
GPU 的高效利用很大程度上取决于数据能否在正确的时间出现在正确的位置。为此,数据系统采用两项关键设计:
- 一是计算旁置与共享内存机制。 函数实例间的数据交换通过共享内存段完成,避免序列化/反序列化及用户态-内核态切换带来的拷贝开销。配合分布式 Object Directory,系统能够自动维护数据副本的分布与生命周期,向上层提供对象引用(Future)和键值两种访问语义。
- 二是异构感知的存储层级。 数据系统识别 HBM、DRAM、SSD 的带宽与容量差异,支持 D2D(Device-to-Device)、H2D/D2H(Host-Device)、H2H(Host-to-Host)多种传输路径,并在可行时启用零拷贝传输。这种设计使得热数据尽可能驻留 HBM,温数据下沉至 DRAM 或本地 SSD,同时保持跨节点访问的透明性。
元数据管理同样遵循局部性原则。每个计算节点维护独立的元数据目录,实现故障域隔离与本地快速访问。相比集中式元数据服务,这种分片化设计将跨机架、跨节点的远程查询降至最低,在管理平面分布式化的同时,保证了数据路径的低延迟与高吞吐。
三、 openYuanrong 安装部署详解
3.1 环境要求与准备工作
在开始安装 openYuanrong 之前,需要确保目标机器满足以下环境要求。openYuanrong 是一个支持 Linux x86_64 及 aarch64(ARM)架构的分布式函数计算平台,对操作系统和依赖组件有明确的版本要求。
| 组件 | 版本要求 |
|---|---|
| 操作系统 | Linux x86_64 / aarch64 (ARM) |
| Python | python<=3.11, >=3.9 |
| Java | java 8/17/21 |
| C++ | gcc>=10.3.0 且 stdc++>=14 |
对于生产环境部署,还需要额外考虑网络配置、存储容量规划以及安全策略等因素。建议在正式部署前,在测试环境中进行充分的验证。
3.2 安装 openYuanrong
3.2.1 pip 安装(推荐方式)
openYuanrong 提供了官方预编译的 wheel 包,可以通过 pip 直接安装。这种方式适合快速入门和开发测试场景。安装命令因操作系统架构不同而有所差异。
对于 Linux x86_64 架构:
bash
pip install https://openyuanrong.obs.cn-southwest-2.myhuaweicloud.com/release/0.7.0/linux/x86_64/openyuanrong-0.7.0-cp39-cp39-manylinux_2_34_x86_64.whl对于 Linux aarch64 (ARM) 架构:
bash
pip install https://openyuanrong.obs.cn-southwest-2.myhuaweicloud.com/release/0.7.0/linux/aarch64/openyuanrong-0.7.0-cp39-cp39-manylinux_2_34_aarch64.whl安装完成后,可使用 yr version 命令验证安装是否成功,该命令会显示 SDK 路径和版本信息。
3.2.2 源码编译安装
对于有自定义需求的场景,可以从源码编译 openYuanrong。源码编译允许开发者根据具体场景进行定制优化。在完成源码编译后,需要将编译生成的库文件路径添加到系统环境变量中,以确保 SDK 能够正确加载。
3.3 集群部署架构
openYuanrong 集群采用主从架构设计,由主节点和从节点组成。主节点负责集群管理、函数调度和请求转发等核心工作;从节点负责运行具体的分布式任务。这种架构设计既保证了集群管理的集中性,又实现了计算资源的水平扩展能力。
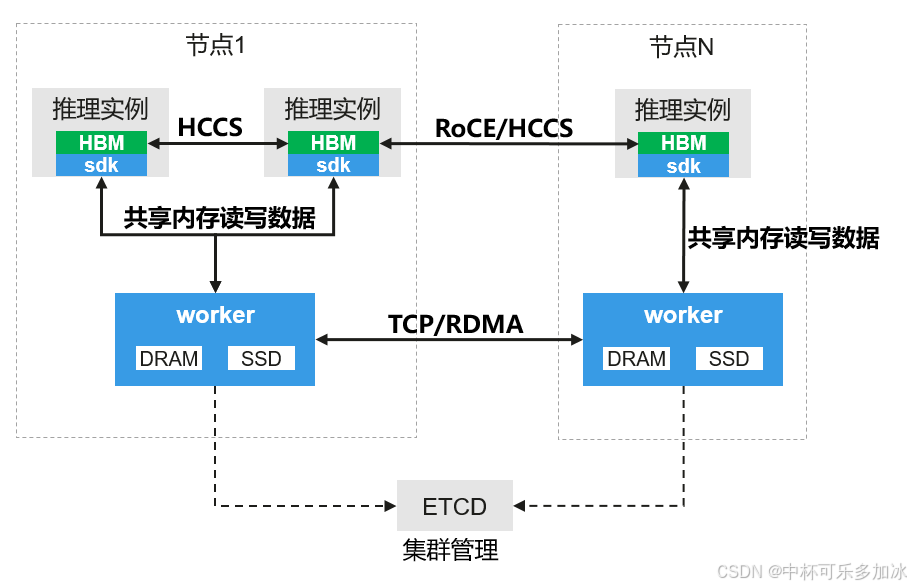
3.3.1 主节点组件
主节点是集群的控制平面,部署以下核心组件:
| 组件 | 说明 |
|---|---|
| function master | 负责拓扑管理、全局函数调度、函数实例生命周期管理及 function agent 组件的扩缩容 |
| function scheduler | 负责函数服务的调度,不使用函数服务时可不部署 |
| frontend | 提供 REST API 用于调用服务、订阅流服务等数据处理,不使用函数服务时可不部署 |
| meta service | 提供 REST API 用于函数创建、资源池创建等管理操作,不使用函数服务时可不部署 |
| dashboard | 作为运维平台提供集群、节点等指标、任务状态及日志的展示能力,可以按需选择部署,运行依赖 collector 组件 |
| etcd | 第三方开源组件,用于存储集群组件注册信息、函数元数据以及实例状态等信息 |
3.3.2 从节点组件
从节点是集群的计算平面,部署以下组件:
| 组件 | 说明 |
|---|---|
| function proxy | 负责消息转发、本地函数调度及实例生命周期管理 |
| function agent | 最小资源单元,负责函数代码包下载和解压、网络安全隔离配置等。与 runtime manager 共进程部署 |
| runtime manager | 负责 cpu、memory 等资源采集和上报、函数进程生命周期管理等。与 function agent 共进程部署 |
| data worker | 提供数据对象的存取等能力 |
| collector | 负责收集指标、日志等数据,可以按需选择部署 |
3.4 集群部署步骤
3.4.1 单节点快速部署
对于学习和开发测试场景,可以使用单节点快速部署方式。在单节点上同时部署主从组件,通过默认配置即可启动服务:
bash
# 启动服务
yr start
# 查看状态
yr status
# 停止服务
yr stop这种部署方式简单快捷,适合初次接触 openYuanrong 的开发者快速上手。
3.4.2 多节点生产环境部署
对于生产环境,需要在多台主机上分别部署主节点和从节点。以下是生产环境部署的详细步骤:
主节点部署命令:
bash
yr start --master -l DEBUG \
--runtime_direct_connection_enable=true \
--enable_separated_redirect_runtime_std=true \
--etcd_addr_list=${MASTER_IP} \
--etcd_port=22440 \
--etcd_peer_port=22441从节点部署命令:
bash
yr start -l DEBUG \
--runtime_direct_connection_enable=true \
--enable_separated_redirect_runtime_std=true \
--etcd_addr_list=${MASTER_IP} \
--etcd_port=22440 \
--etcd_peer_port=22441其中,${MASTER_IP} 需要替换为主节点的实际 IP 地址。runtime_direct_connection_enable=true 参数启用了运行时直接连接模式,可以提升数据传输效率。
部署验证:
bash
yr status --etcd_endpoint ${MASTER_IP}:22440预期输出应显示当前运行的 agent 节点数量,例如:current running agents: 2 表示集群已成功部署两个从节点。
3.5 多语言 SDK 配置
openYuanrong 支持 Python、Java、C++ 等多种编程语言,提供了丰富的 SDK 供开发者使用。
3.5.1 Python SDK
安装 openYuanrong 后即可直接使用 Python SDK,无需额外配置。SDK 会自动初始化环境。在 Driver 中调用 yr.init() 接口时,如果未配置 openYuanrong 集群地址,SDK 会尝试拉起一个临时环境,该环境在进程退出时自动销毁。
3.5.2 Java SDK
Java SDK 需要通过 Maven 进行依赖管理。首先需要安装 SDK 的 jar 包:
bash
# 安装 yr-api-sdk
mvn install:install-file -Dfile=./yr-api-sdk-1.0.0.jar -DartifactId=yr-api-sdk \
-DgroupId=org.yuanrong -Dversion=1.0.0 -Dpackaging=jar -DpomFile=./pom.xml
# 安装 faas-function-sdk
mvn install:install-file -Dfile=./faas-function-sdk-1.0.0.jar -DartifactId=faas-function-sdk \
-DgroupId=org.yuanrong -Dversion=1.0.0 -Dpackaging=jar -DpomFile=./pom.xml然后在项目的 pom.xml 中添加相应依赖即可使用。
3.5.3 C++ SDK
C++ SDK 的头文件和库文件位于安装目录下的 yr/inner/runtime/sdk/cpp/ 目录中。开发者可以查看该目录下的 include 和 lib 目录来了解 API 接口和链接方式。
四、 openYuanrong 数据系统与 GPU 生态的硬件级融合
4.1 以内存为中心的异构存储架构与多级缓存
在 AI 推理场景中,GPU 的显存(HBM)容量往往是极其有限的,而大模型的 KV Cache 等中间数据量却非常庞大。openYuanrong 的数据系统通过构建异构多级缓存体系,完美解决了这一矛盾。openYuanrong 将集群中的各类存储介质抽象为一个分层资源池。
L1 级为 GPU 显存(HBM),提供极高带宽和极低延迟,用于存储当前计算的热数据,如模型权重和当前 Token 的 KV Cache。L2 级为主机内存(DRAM),作为 HBM 的延伸,存储温数据并支持跨节点共享。L3 级为本地或分布式 SSD,存储冷数据并支持自动溢出与回填,从而突破物理内存的容量限制。这种分层架构通过智能调度算法,确保数据在不同层级之间高效流转,最大化利用各级存储的优势。
4.2 GPU 生态的深度集成与硬件拓扑感知
openYuanrong 深度集成了主流的 AI 框架,如 vLLM、MindSpore 和 PyTorch。系统将 CPU 和各类加速器(GPU/NPU)视为对等的计算资源,支持细粒度的资源申请和调度。在部署推理实例时,openYuanrong 会自动识别节点内的硬件拓扑,例如 NVLink 的互联情况,以优化通信路径并提升整体算力利用率。这种对硬件拓扑的深度感知,使得 openYuanrong 能够智能地选择最优的数据传输路径和计算资源分配策略,从而在异构计算环境中实现最佳性能。
4.3 D2D 高速传输
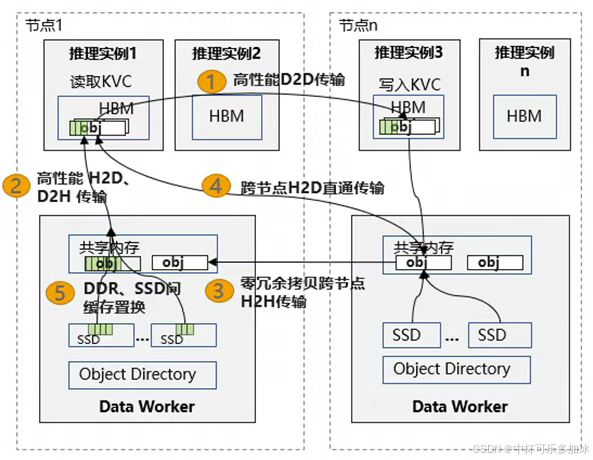
在多卡分布式推理中,卡间通信(D2D)的效率直接决定了系统的整体吞吐。openYuanrong 充分利用了现代 GPU 的硬件特性,实现了多种高效的传输机制。传统的卡间通信往往需要经过主机内存中转,这不仅增加了延迟,还占用了宝贵的 PCIe 带宽。openYuanrong 支持 GPUDirect P2P 技术,允许一个 GPU 通过 PCIe 总线或 NVLink 直接访问另一个 GPU 的显存,无需 CPU 参与数据搬运。系统能够自动识别节点内的 GPU 拓扑,并动态建立最优的 P2P 通信链路。如果检测到 NVLink,则优先使用高带宽的 NVLink 路径,确保数据传输的极致性能。
对于跨节点的 GPU 通信,openYuanrong 采用了 RDMA(Remote Direct Memory Access)技术。针对 KB 级的小数据搬运,系统通过大页聚合技术减少了系统调用的次数和页表查找开销。同时,利用 GPU 内部的 SDMA(System Direct Memory Access)引擎,实现了单卡高达 20GB/s 的传输吞吐。这在模型参数加载和 KV Cache 迁移场景中表现尤为突出,显著缩短了数据准备时间。在同节点内的进程间通信中,openYuanrong 通过共享内存与通信内存的复用机制,实现了数据的零冗余拷贝。Data Worker 管理一块全局共享内存,不同函数实例通过映射同一块物理内存来交换数据。实测传输速率可达 48GB/s,充分发挥了底层互联总线的带宽潜力,为高频数据交换提供了保障。
五、 核心突破
5.1 RH2D 直通访问的底层原理与 GPU NIC 交互
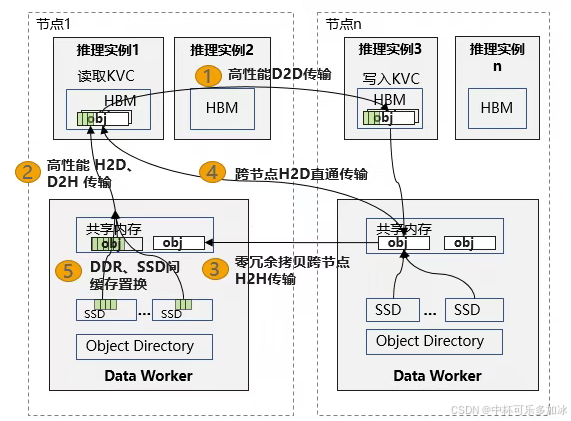
PD(Prefill-Decode)分离架构已成为大模型推理吞吐优化的常规手段,但其带来的数据移动问题同样突出:Prefill 阶段产生的 KV Cache 需要跨节点传输至 Decode 节点,而传统网络栈的多级缓冲和 CPU 介入往往成为延迟的主要来源。openYuanrong 的 RH2D(Remote Host-to-Device) 技术试图缩短这一路径------核心思路是将跨节点访问的语义从"网络 I/O"转为"内存语义",即远端节点的数据如同本地内存般直接可写。
实现这一机制依赖于支持 RDMA 的 GPU NIC。RH2D 模式下,数据经 RDMA 网络到达本地后,不经由 CPU 内存中转,直接通过 PCIe(或 CXL/UB 等互联总线)写入目标 GPU 的 HBM。Data Worker 在初始化阶段即完成 GPU 显存区域向 NIC 的注册,使远端节点获得对该区域的直接写入权限。这一设计的收益体现在两方面:一是消除了 CPU 侧的数据拷贝与上下文切换;二是将 CPU 从数据搬运中解放出来,使其专注于调度与控制面逻辑。
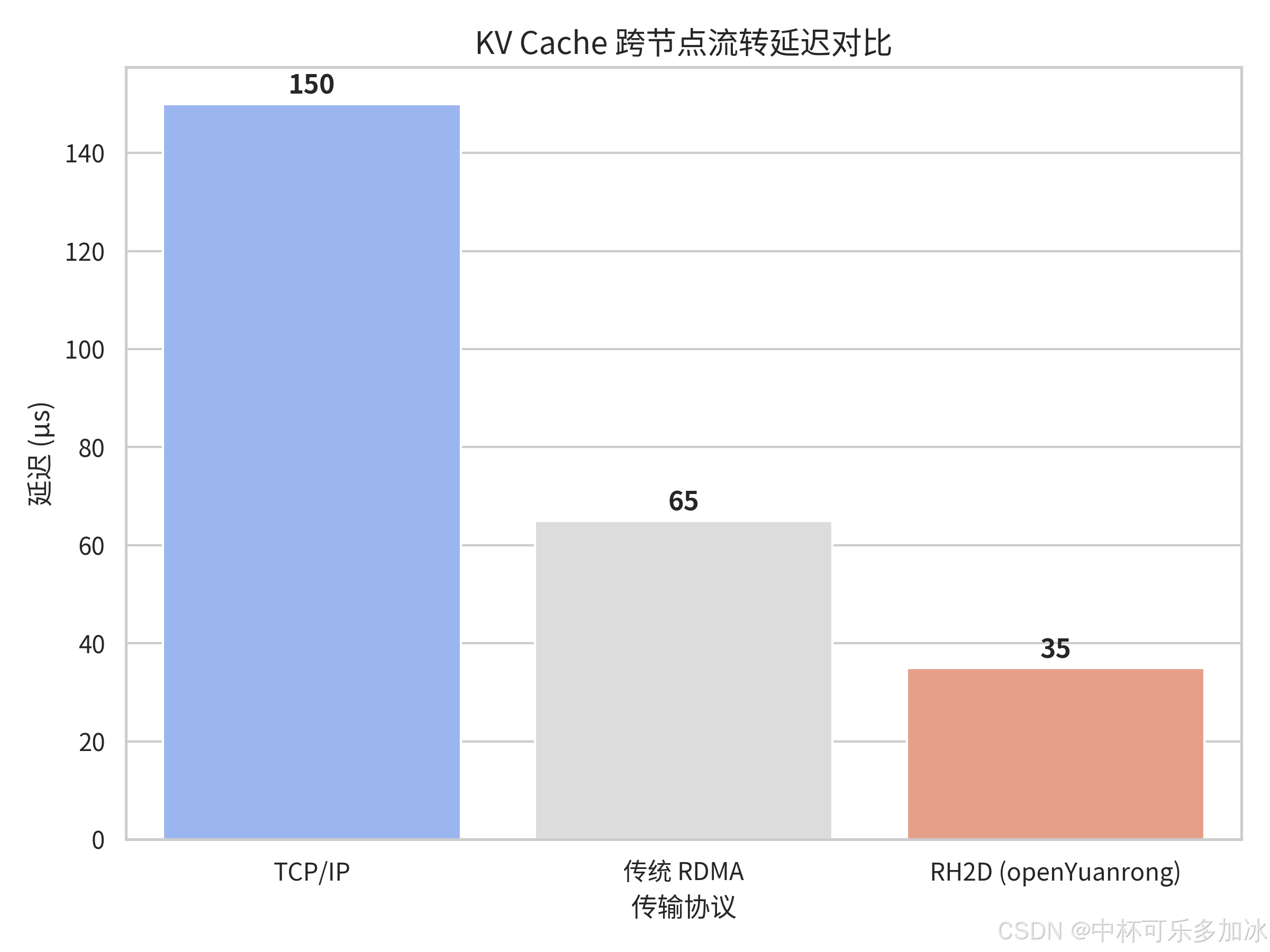
5.2 PD 分离场景下的极致性能表现与 KV Cache 跨机流转
Decode 阶段的 TTFT(Time To First Token)直接决定用户感知延迟。openYuanrong 的数据系统识别到 PD 任务流后,会预先建立 RH2D 传输链路,将 KV Cache 的跨机访问延迟压缩至接近本地内存访问量级------在 100Gbps 或更高带宽的网络环境下,端到端延迟可控制在数十微秒级别。
实际测试部署数据表明,RH2D 可将 KV Cache 的跨节点流转耗时降低 40% 以上。对于长序列推理场景,这意味着 Decode 节点能够更快接管 Prefill 结果,缩短首 token 生成等待时间。需要指出的是,这一优化对实时性要求高的交互式应用价值显著,但对吞吐优先的离线批处理场景边际收益递减。
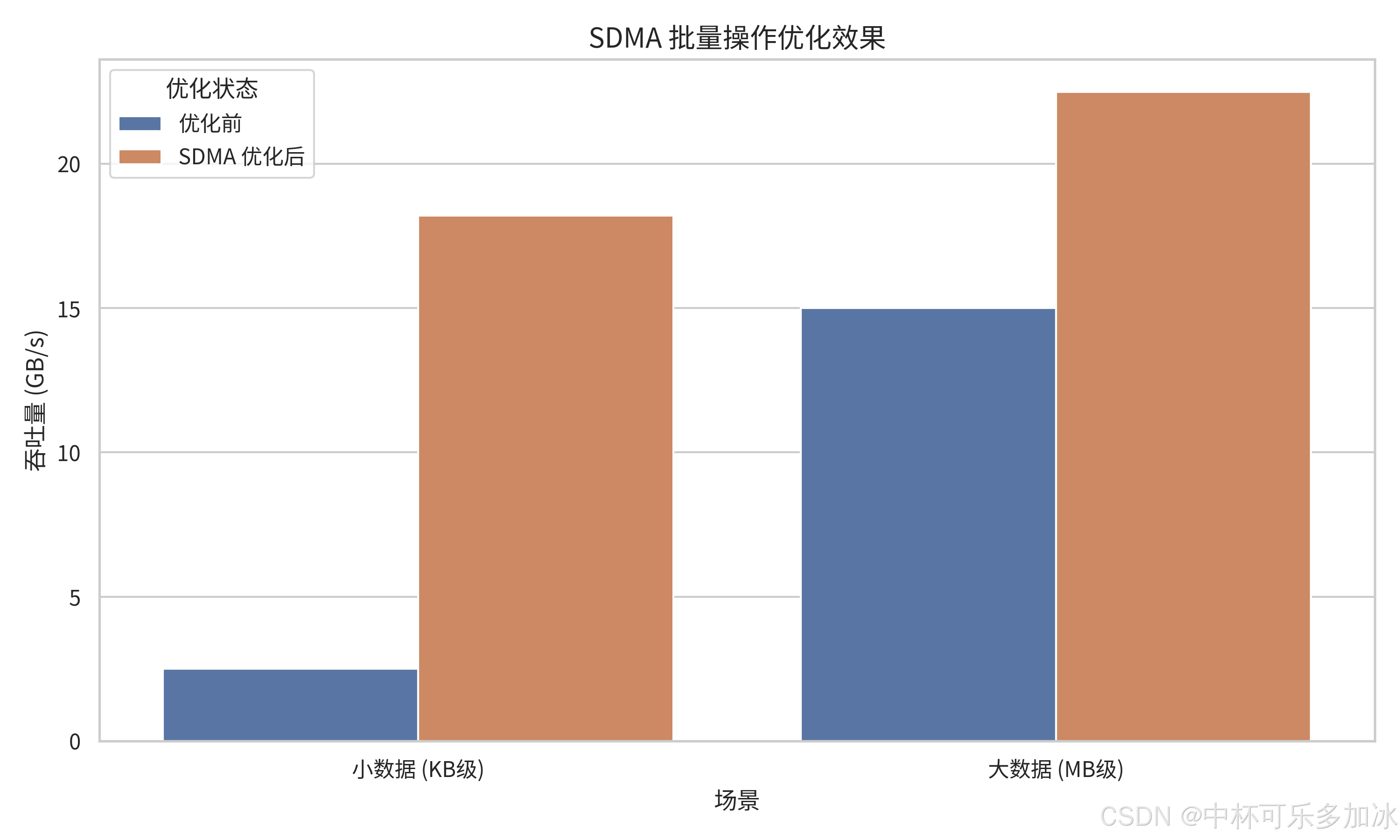
5.3 D2H/H2D 硬件加速与 SDMA 批量操作
节点内部的 GPU-主机数据交换(D2H/H2D)同样是关键路径。openYuanrong 针对两类典型负载做了优化:
- 小数据高频访问。 推理过程中的增量 KV Cache 多为 KB 级碎片,频繁系统调用和离散内存访问开销显著。系统利用 GPU 内置的 SDMA(System Direct Memory Access)引擎------独立于计算核心的硬件搬运单元------实现数据传输与计算并行。同时采用大页聚合策略,将零散请求合并为连续传输,减少页表遍历与 TLB miss。
- 高带宽场景。 通过共享内存与通信内存复用,消除进程间冗余拷贝,在 UB(Unified Bus)互联架构上实测单卡传输速率达 48GB/s;对于支持主机内存直写的 NPU NIC,可避免 KV Cache 等场景下的 HBM 中转,进一步压低跨机访问延迟。
实测数据显示,优化后的单卡 H2D/D2H 吞吐稳定在 20GB/s 以上,SDMA 批量操作对小数据场景的延迟改善尤为明显。
六、 GPU 多级缓存调度算法与分布式 Future 机制
6.1 异构多级缓存调度算法与热度感知迁移
LLM 推理中的 KV Cache 管理面临一个典型矛盾:HBM 带宽充足但容量受限,DRAM 和 SSD 容量充裕却延迟较高。手动管理数据在三者之间的分布不仅繁琐,且容易因策略不当导致 GPU 空转或内存溢出。
openYuanrong 的分级缓存体系将这一决策自动化。系统以 HBM、DRAM、SSD 构成三级存储池,通过以下机制实现数据流动:
- 热度追踪与分层驻留。 运行时监控每个 KV Cache 块的访问频率:热数据(近期高频访问)保留于 HBM;温数据(访问频率下降)降级至 DRAM;冷数据(长时间未访问)溢出到 SSD。分层阈值可根据负载特征动态调整。
- 预取与回填。 基于对任务流的模式识别,系统在 Decode 阶段启动前,将预测命中的 KV Cache 从 DRAM/SSD 异步回填至 HBM。该过程与计算流水线重叠,尽量掩盖传输延迟。
这一调度策略的实质是以带宽换容量------用 DRAM/SSD 的闲置带宽缓解 HBM 的容量压力,使单卡可处理的序列长度超出物理显存限制。但需注意,当工作集显著超出 HBM 容量时,频繁的跨层迁移仍会引入不可忽略的延迟抖动。
6.2 分布式对象引用(Future)与生命周期自动化
分布式并行编程中,数据生命周期的手动管理容易出错:过早释放导致空指针,过晚释放造成内存泄漏,跨节点传递时状态同步复杂。
openYuanrong 采用了分布式 Future 机制简化这一流程:
- 发布-订阅模型。 任务 B 对任务 A 的输出建立订阅关系,无需轮询或阻塞等待。任务 A 完成写入后,Object Directory 向所有订阅者推送就绪通知,实现计算与调度的解耦。
- 引用计数与自动回收。 Object Directory 维护全局引用计数:Future 被传递或复制时计数递增,超出作用域时递减;归零后触发内存回收。该机制覆盖单节点共享内存与跨节点远程对象,开发者无需显式调用释放接口。
- 一致性边界。 系统保证 Future 的"写后读"一致性------订阅者收到通知时,数据已完整写入共享内存或完成 RDMA 传输。对于需要更强一致性的场景(如多写入者),需配合额外的同步原语使用。
这一设计将分布式数据管理从"显式控制"转为"声明式依赖",降低了并行编程的心智负担,但并未完全消除对数据流逻辑的理解需求------开发者仍需合理规划任务粒度与依赖关系,以避免引用循环或过早订阅导致的内存膨胀。
6.3 编程模型与代码实践
openYuanrong 提供了简洁的 API,使得开发者能够以单机编程的方式实现复杂的分布式逻辑。以下代码示例展示了如何利用 openYuanrong 的数据系统和函数系统,在 PD 分离场景下优化 KV Cache 的跨机流转:
python
import yuanrong_data as yr_data
import yuanrong_function as yr_func
# 初始化数据系统客户端
client = yr_data.Client()
# 示例:利用 RH2D 优化 PD 分离场景下的 KV Cache 跨机流转
@yr_func.remote(resources={"gpu": 1})
def prefill_task(input_ids):
# 执行 Prefill 阶段,生成 KV Cache
# 数据系统会自动利用 SDMA 批量操作和内存大页聚合进行 H2D 传输
kv_cache = compute_prefill(input_ids)
# 将 KV Cache 存入数据系统,指定 media="HBM" 触发 D2D/RH2D 逻辑
# 系统会自动管理副本和生命周期,无需开发者手动干预
return client.put("kv_cache_ref", kv_cache, media="HBM")
@yr_func.remote(resources={"gpu": 1})
def decode_task(kv_cache_ref, next_token):
# 依赖 prefill_task 的返回结果 (Future)
# openYuanrong 会自动处理数据就绪通知和依赖协调
# 如果 kv_cache_ref 在远端,系统会触发 RH2D 直通访问,直接写入本地 GPU 显存
result = compute_decode(kv_cache_ref, next_token)
return result
# 触发分布式执行,开发者只需关注逻辑,无需关心底层硬件传输细节
input_data = [1, 2, 3]
kv_ref = prefill_task.invoke(input_data)
# decode_task 会在 kv_ref 就绪后自动在合适的节点启动,并利用硬件加速路径拉取数据
final_output = decode_task.invoke(kv_ref, 42)
print(final_output.get()) # 阻塞等待最终结果七、 实践案例:多机大模型推理与弹性扩缩容
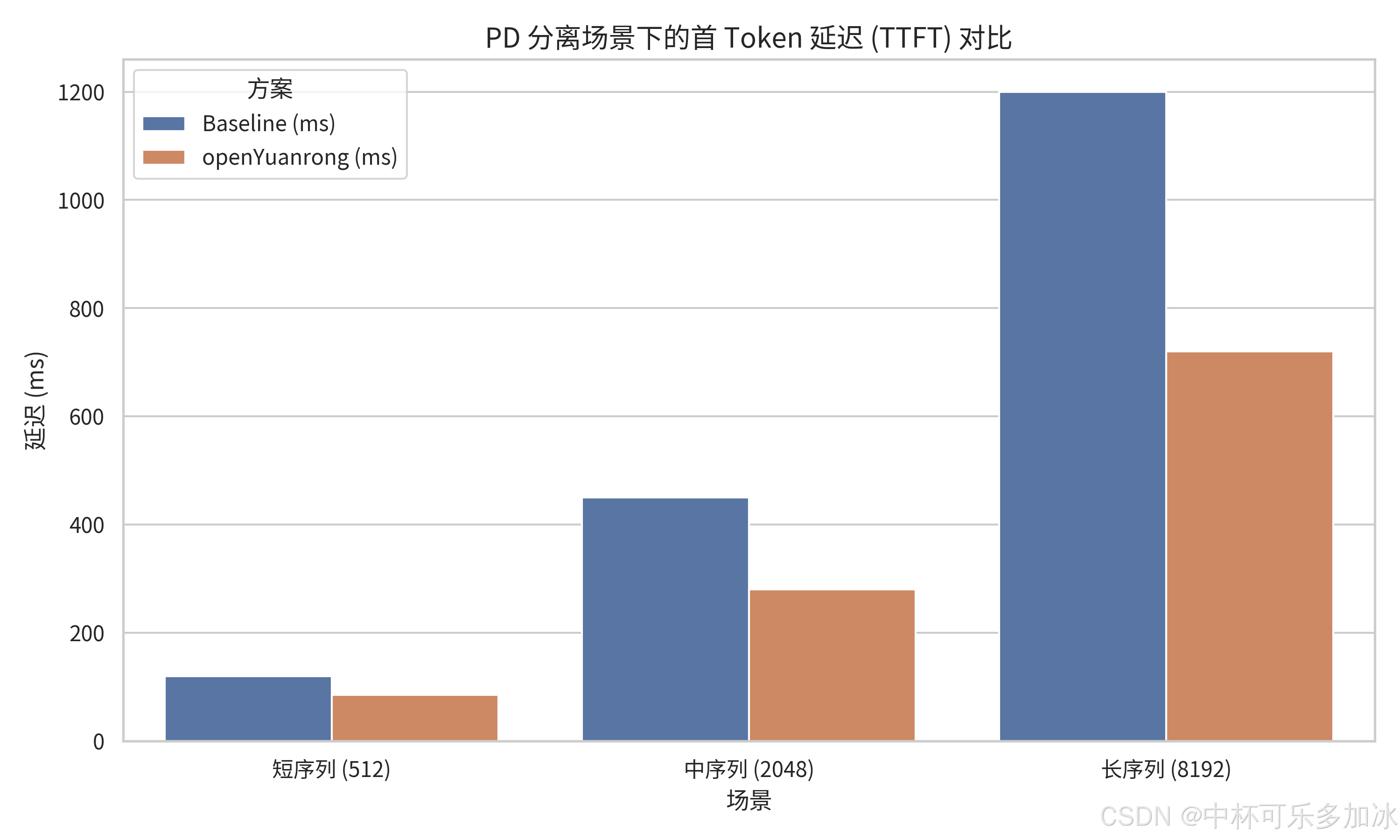
7.1 基于 vLLM 部署多机 PD 分离服务
7.1.1 方案概述与核心挑战
在实际的 AI 推理部署中,开发者面临着诸多技术挑战。计算复杂度与序列长度平方成正比的特性,使得长序列推理的计算成本急剧上升;同时,KV Cache 占用大量显存,限制了在有限硬件资源下能够处理的最大上下文长度。openYuanrong 通过异构分布式多级缓存能力,为这些问题提供了优雅的解决方案。
7.1.2 解决方案架构
该方案采用 PD 分离架构部署多机推理服务。Prefill 节点和 Decode 节点分别承担不同的计算任务,通过 openYuanrong 的数据系统实现 KV Cache 的高速跨机传递。系统利用 HBM/DRAM/SSD 构成的多级缓存体系,有效解决了显存瓶颈问题。当缓存空间不足时,系统会自动将冷数据溢出到 SSD,并在需要时快速回填到高速存储层。这种架构不仅提升了单机的显存利用率,还通过分布式缓存显著降低了跨节点的 KV Cache 访问延迟。
7.1.3 部署步骤详解
准备工作清单:
| 准备项 | 说明 |
|---|---|
| 主机数量 | 2 台昇腾主机(每台至少 1 张 NPU 卡) |
| 模型目录 | /workspace/models/qwen2.5_7B |
| 工具目录 | /workspace/tools/deploy |
| Docker 镜像 | quay.io/ascend/vllm-ascend:v0.10.0rc1-openeuler |
| 模型 | Qwen2.5-7B-Instruct |
第一步:启动容器
bash
docker run \
--name "docker_name" \
--privileged -itu root -d --shm-size 64g \
--net=host \
--device=/dev/davinci0:/dev/davinci0 \
--device=/dev/davinci1:/dev/davinci1 \
--device=/dev/davinci_manager:/dev/davinci_manager \
--device=/dev/devmm_svm:/dev/devmm_svm \
--device=/dev/hisi_hdc:/dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /workspace:/workspace \
-it quay.io/ascend/vllm-ascend:v0.10.0rc1-openeuler bash第二步:为 vLLM Ascend 打补丁
bash
cd /vllm-workspace/vllm-ascend
git am /workspace/tools/patch/0001-implement-yr-datasystem-connector-and-support-multimoda.patch
python setup.py develop第三步:安装 openYuanrong
对于 Linux x86_64 架构:
bash
pip install https://openyuanrong.obs.cn-southwest-2.myhuaweicloud.com/release/0.7.0/linux/x86_64/openyuanrong-0.7.0-cp311-cp311-manylinux_2_34_x86_64.whl
pip install https://openyuanrong.obs.cn-southwest-2.myhuaweicloud.com/release/0.7.0/linux/x86_64/openyuanrong_datasystem-0.7.0-cp311-cp311-manylinux_2_34_x86_64.whl对于 Linux aarch64 架构:
bash
pip install https://openyuanrong.obs.cn-southwest-2.myhuaweicloud.com/release/0.7.0/linux/aarch64/openyuanrong-0.7.0-cp311-cp311-manylinux_2_34_aarch64.whl
pip install https://openyuanrong.obs.cn-southwest-2.myhuaweicloud.com/release/0.7.0/linux/aarch64/openyuanrong_datasystem-0.7.0-cp311-cp311-manylinux_2_34_aarch64.whl第四步:部署 openYuanrong 集群
主节点部署:
bash
yr start --master -l DEBUG --runtime_direct_connection_enable=true --enable_separated_redirect_runtime_std=true --etcd_addr_list=${MASTER_IP} --etcd_port=22440 --etcd_peer_port=22441从节点部署:
bash
yr start -l DEBUG --runtime_direct_connection_enable=true --enable_separated_redirect_runtime_std=true --etcd_addr_list=${MASTER_IP} --etcd_port=22440 --etcd_peer_port=22441验证部署:
bash
yr status --etcd_endpoint ${MASTER_IP}:22440
# 预期输出:current running agents: 2第五步:配置环境变量
bash
export SERVER_IP=xx.xx.xx.xx
export SERVER_PORT=9000
export MODEL_PATH="/workspace/models/qwen2.5_7B"
export PYTHONPATH=$PYTHONPATH:/workspace/tools/deploy
export VLLM_USE_V1=1
export VLLM_WORKER_MULTIPROC_METHOD=spawn
export vLLM_MODEL_MEMORY_USE_GB=20
export USING_PREFIX_CONNECTOR=1
export PREFILL_INS_NUM=1
export DECODE_INS_NUM=1
export PTP=4
export DTP=4
export PDP=1
export DDP=1第六步:部署 PD 分离推理实例
bash
bash run_vllm_on_yr.sh deploy成功标志:
Succeeded to init YR, jobID is job-d9f59ff7
Started server process [40250]
Application startup complete.
Uvicorn running on http://:9000第七步:验证推理服务
bash
curl -X POST "http://${SERVER_IP}:${SERVER_PORT}/v1/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "'"${MODEL_PATH}"'",
"prompt": "介绍一下北京故宫,从地理位置、历史地位以及政治地位角度来说明",
"max_tokens": 50,
"temperature": 0
}'
7.1.4 性能测试结果
| 指标 | 效果 |
|---|---|
| TTFT(首 token 生成时间) | 下降 20% |
| 部署架构 | PD 分离(Prefill-Decode) |
| 主机数量 | 2 台昇腾主机 |
| 实例配置 | PREFILL_INS_NUM=1, DECODE_INS_NUM=1 |
7.2 推理实例弹性扩缩容:模型加载速度 10 倍提升
7.2.1 方案背景与核心问题
大模型推理在面对高负载或突发情况时,推理实例的弹性速度至关重要。更快的弹性速度允许系统根据实时负载自动调整计算资源,高负载时快速扩展,低负载时及时释放,从而避免资源浪费。然而,随着模型越来越大,模型加载速度成为了制约弹性响应的核心瓶颈。传统的扩容方式需要重新加载完整的模型参数,导致新实例的启动时间过长,无法满足实时业务的需求。
openYuanrong 提供了创新的解决方案:基于异构数据对象 API,实现模型一次冷加载,通过异构对象共享模型参数。当需要再次扩容推理实例时,可以直接从已部署实例的显存中高速同步模型参数,无需从头加载。
7.2.2 部署首个 Qwen 推理实例
配置环境变量:
bash
export SERVER_IP=127.0.0.1
export SERVER_PORT=9000
export MODEL_PATH="/workspace/models/qwen2.5_7B"
export PYTHONPATH=$PYTHONPATH:/workspace/tools/deploy
export VLLM_USE_V1=1
export VLLM_WORKER_MULTIPROC_METHOD=spawn
export vLLM_MODEL_MEMORY_USE_GB=20
export PROTOCOLS_BUFFERS_PYTHON_IMPLEMENTATION=python
export LD_LIBRARY_PATH=${YR_INSTALL_PATH}/functionsystem/lib:$LD_LIBRARY_PATH
export HCL_OP_EXPANSION_MODE="AIV"
export USING_PREFIX_CONNECTOR=1
# 部署 PD 合并的推理实例
export PREFILL_INS_NUM=1
export DECODE_INS_NUM=0
export PTP=2部署命令:
bash
cd /workspace/tools/deploy
bash run_vllm_on_yr.sh deploy成功输出:
[2025-10-21 03:10:47.616 INFO] Succeeded to init YR, jobID is job-6dc821f8
INFO: Started server process [921319]
INFO: Uvicorn running on http://127.0.0.1:9000首次模型加载用时约 15.8 秒。
7.2.3 扩容推理实例
当业务负载增加需要扩容时,只需调用扩缩容接口:
bash
curl --location --request POST 'http://${SERVER_IP}:${SERVER_PORT}/scaleout'扩容后,新实例从已部署实例的显存中快速同步模型参数,模型加载用时仅约 1.5 秒。
7.2.4 性能优化效果
| 指标 | 首次加载 | 扩容加载 | 提升倍数 |
|---|---|---|---|
| 模型加载时间 | ~15.8 秒 | ~1.5 秒 | 10 倍 |
7.2.5 核心技术要点
该方案的核心技术要点包括三个方面。首先是异构数据对象 API 的应用:通过 dev_mset() 和 dev_mget() 接口实现模型参数的高速同步,这两个接口能够直接在 GPU 显存之间进行数据传输,绕过 CPU 中转,显著降低延迟。其次是补丁核心逻辑的设计:首次加载时使用默认方式加载模型,并将模型元数据发布到数据系统;扩容时则从已部署实例的显存中快速同步模型参数,避免了重复的磁盘 I/O 和模型初始化开销。第三是 vLLM 适配实现:通过 fast_load_weights() 函数实现了按需回退机制,当共享参数可用时直接使用,否则回退到传统加载方式。
八、 总结与展望
8.1 行业应用案例与性能实测
openYuanrong 的开源,标志着分布式计算进入了一个全新的阶段。它通过深度整合 GPU 硬件特性,构建了以内存为中心的多级缓存体系和 D2D 高速传输机制,系统性地解决了 AI 推理中的性能与容量瓶颈。openYuanrong 已经在华为内部多个核心产品中得到了广泛应用。在 MetaERP 这种超大规模的企业级应用中,openYuanrong 支撑了海量并发的数据处理需求,实现了资源的按需分配,显著降低了基础设施成本。小艺助手则利用 openYuanrong 的毫秒级冷启动和 GPU 多级缓存技术,确保在面对突发流量时依然能够保持极低的响应延迟。
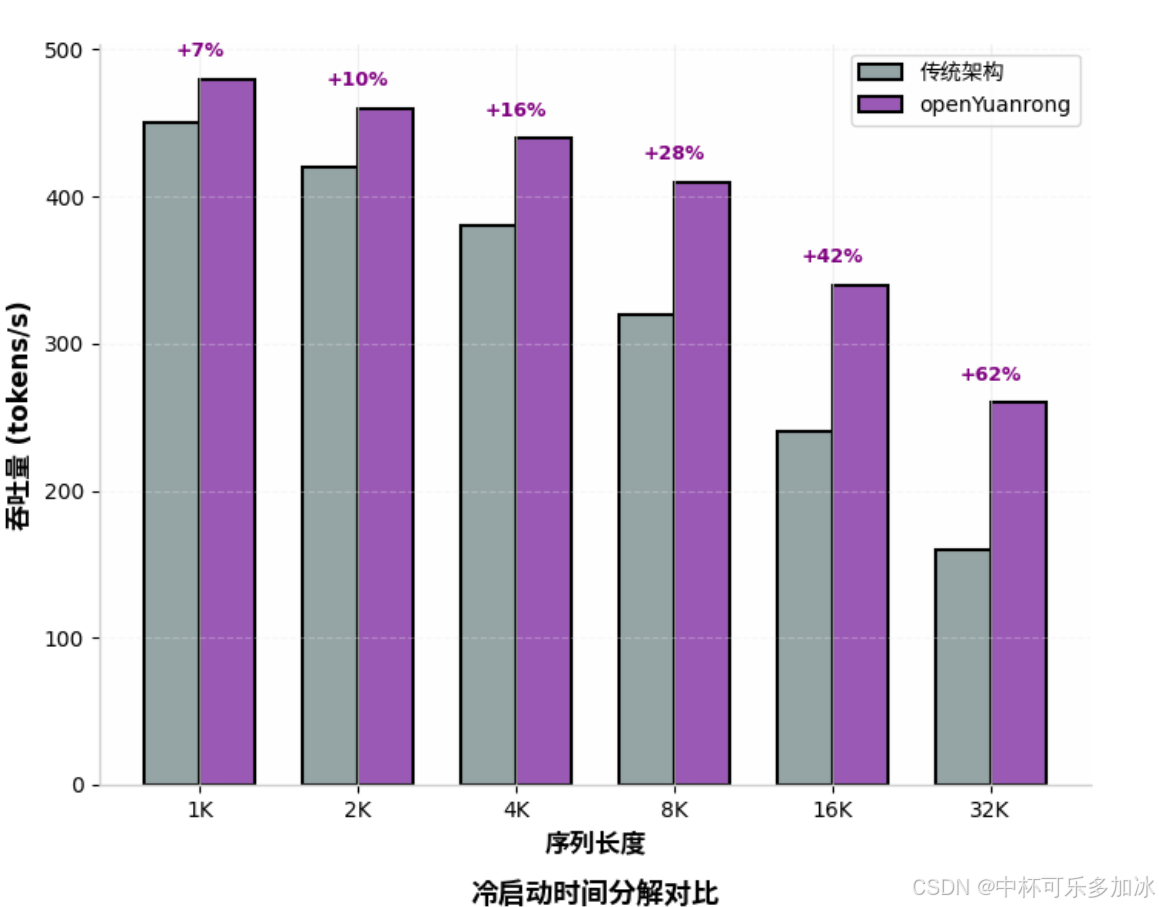
在 Qwen3-32B 模型、8 并发负载下,8K 序列长度的吞吐量提升了 169.4% ,首字延迟(TTFT)降低了 66.5%。
总结来说,openYuanrong 极大地提高了缓存命中率,且 KV Cache 的加载耗时在总耗时中的占比被成功压缩到了 5% 以内,几乎实现了"透明"的数据流转。
8.2 未来演进方向与技术展望
对于开发者而言,openYuanrong 不仅仅是一个工具,更是一种全新的分布式编程范式。它让我们能够真正专注于业务逻辑,而将复杂的底层优化、资源调度和数据流转交给"分布式内核"。随着社区的不断壮大,openYuanrong 将继续在超节点深度优化、更广泛的生态兼容以及智能化调度等方向演进,成为未来智算时代不可或缺的基础设施。此外,在华为云 Serverless 数据库场景中,数据系统被用于构建高性能的分布式缓存层,极大地提升了查询性能。
展望未来,openYuanrong 将进一步深化与异构硬件的协同,探索基于 CXL 等新一代互联技术的内存池化方案,为大模型时代的算力爆发提供更加坚实的底座。