
上文已经简述过Series,本文开始讲述由多个Series复合而成的DataFrame,其实很多内容异曲同工。
Pandas库series数据结构![]() https://jslhyh32.blog.csdn.net/article/details/159003155?spm=1001.2014.3001.5502
https://jslhyh32.blog.csdn.net/article/details/159003155?spm=1001.2014.3001.5502
一.创建
前面已经提到,DataFrame由Series复合组成,因此可以通过Series来创建DataFrame:
python
s1=pd.Series([1,2,3])
s2=pd.Series([4,5,6])
df=pd.DataFrame({"第一列":s1,"第二列":s2})#通过Series来创建DataFrame打印来看看内容和类型:
python
print(df)
print(type(df))#打印一下类型
print(type(df["第一列"]))#Series类型整体是一个DataFrame,每一列是一个Series:

同样可以用字典的写法,甚至有点像JSON:
python
#字典来创建
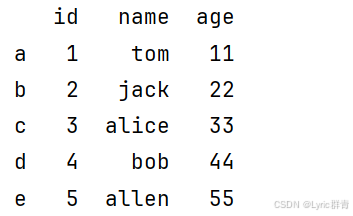
df1=pd.DataFrame({
"id":[1,2,3,4,5],
"name":["tom","jack","alice","bob","allen"],
"age":[11,22,33,44,55],
},index=['a','b','c','d','e'],columns=["id","name","age"])index是记录号也即索引,columns是表头名,需要注意columns中的值必须要和前面的字典中的key值相同,否则数据会不匹配,导致data变成NAN:
二.属性
DataFrame中有多列数据,每列数据类型可能都不尽相同:
python
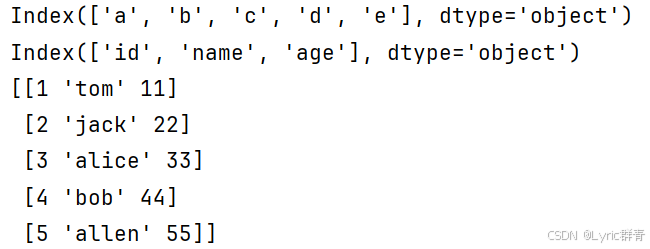
print(df1.dtypes)先给出各列的类型,再返回这些类型组成的Series的类型。实际上类型名是字符串,因此最后一个一般来说肯定是object:

依次打印行索引、列标签、数据:
python
print(df1.index)#行索引
print(df1.columns)#列标签
print(df1.values)#值二维的数据肯定有转置:
python
print(df1.T)#转置,行列标签也会变化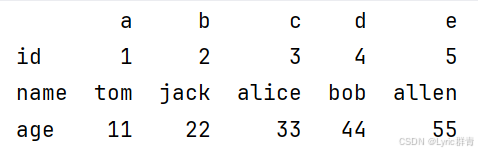
和Series一样,可以通过显式索引和隐式索引来获取某一行元素,实际上就是一个记录的全部内容:
python
print(df1.loc['d'])
print(df1.iloc[3])
从几何上来看上述可以理解为获取了某一行,也可以按照切片的写法获取某一列的元素,同样是显式和隐式:
python
print(df1.loc[:,"id"])#列
print(df1.iloc[:,0])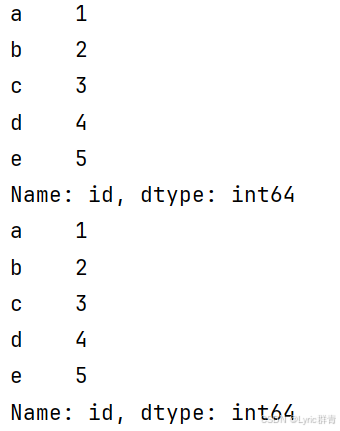
同样也支持获取单个元素,同样是显式和隐式,但需要列名和索引两个参数:
python
print(df1.at['b',"name"])
print(df1.iat[1,1])#单个元素获取
三.获取元素
两种方式获取一列,有点像C++的STL容器的情况,指针和面向对象属性两种写法:
python
print(df1["id"])
print(df1.id)也可以获取多列,组成了一个子集的DataFrame:
python
print(df1[['id','name']])同样支持bool类型的判断语句:
python
print(df1[(df1["id"]>3)&(df1.age<55)])保留下来符合条件的记录:
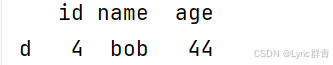
四.方法
很多都和Series异曲同工,只不过 变成了二维的情况,isin来判断对应元素是否在列表参数中:
python
print(df1.isin(['jack',22]))#查看jack和22是否在数据里面
#这种方式无需判断是在第几列返回也是布尔值:

判断单个数据是不是缺失值,同样返回布尔值:
python
print(df1.isna())#判断是否有缺失值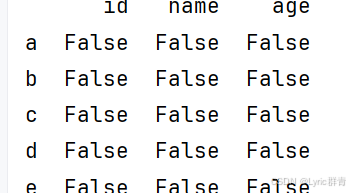
还有加和,和ndarray同理:
python
print(df1.sum())#字符串的相加是直接拼凑组合在一起,没有统计意义
print(df1.age.sum())#因此只是处理单独一列
统计学的平均值、方差什么的依旧同理,这里不一一赘述:
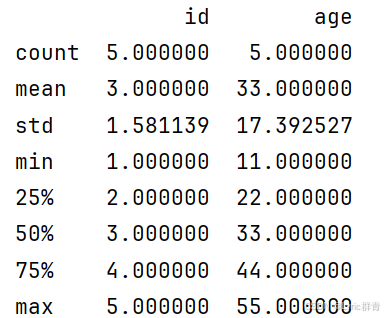
python
print(df1.describe())#返回数字类型列每个Series单独处理,只能处理数字型的:
以及同样的计数、去重:
python
print(df1.value_counts())#统计的是完全一样的记录的个数
print(df1.drop_duplicates())#去重
print(df1.duplicated())#判重
print(df1.duplicated(subset=['age']))#指定列是不是有重复随机采样,填数字为数字个,否则返回一个:
python
print(df1.sample())#随机采样
替换对应数值:
python
print(df1.replace(11,66))累加和累计最大值,默认axis=0即按列方向进行计算,可以将axis=1变为行方向,但注意元素类型必须合法:
python
print(df1.cumsum())
print(df1.cummax())#将axis=1可以按行进行计算按值排序,默认升序可以改为降序:
python
print(df1.sort_index(ascending=False))#默认升序改为降序按某列或者某几列进行排序:
python
print(df1.sort_values(by="name"))
print(df1.sort_values(by=["age","name"],ascending=[False,True]))返回某列最大的几个数:
python
print(df1.nlargest(3,"age"))
#返回最大的几个数