一、引言
在中东地区展会网站采集中,沙特利雅得塑料橡胶及石化展览会(Saudi PPP)的网站采用了典型的WordPress架构,通过AJAX动态加载数据,并使用了反爬参数。本文以Saudi PPP展参展商信息采集项目为例,深入剖析在开发过程中遇到的四大技术难题,以及我们如何通过创新的技术方案逐一攻克这些难关。
二、技术难点全景图
四大技术难关
AJAX动态参数反爬
admin-ajax.php接口
nonce动态令牌
table_id参数
X-Requested-With头
HTML嵌套网站提取
网站嵌在a标签内
正则精准提取
www.xxx.xxx格式
去除多余HTML
UPSERT增量更新
ON DUPLICATE KEY
重复数据更新
保留历史记录
增量采集策略
空值智能处理
None值传入
数据库NULL处理
COALESCE保护
空字符串过滤
三、核心难题攻克详解
3.1 难关一:AJAX动态参数反爬机制
问题描述 :
网站通过WordPress的admin-ajax.php接口动态加载数据,URL中包含多个动态参数:table_id、nonce令牌等。这些参数可能会变化,直接访问HTML页面无法获取数据。
python
# AJAX请求URL(包含动态参数)
url = "https://saudipp.com/wp-admin/admin-ajax.php?action=wp_ajax_ninja_tables_public_action&table_id=22834&target_action=get-all-data&default_sorting=old_first&skip_rows=0&limit_rows=0&ninja_table_public_nonce=4d19a1e2b9"攻克方案:
解决方案
分析过程
问题层
传统HTML请求
返回空数据
AJAX接口
包含动态参数
抓包分析
浏览器开发者工具
发现admin-ajax.php
提取nonce参数
识别必要请求头
构造完整AJAX URL
添加X-Requested-With头
设置Referer伪装
成功获取JSON数据
核心代码实现:
python
# 攻克AJAX动态参数反爬难题
# 第一步:通过抓包获取完整AJAX URL
url = "https://saudipp.com/wp-admin/admin-ajax.php?action=wp_ajax_ninja_tables_public_action&table_id=22834&target_action=get-all-data&default_sorting=old_first&skip_rows=0&limit_rows=0&ninja_table_public_nonce=4d19a1e2b9"
# 第二步:添加必要的请求头模拟AJAX请求
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36",
"Referer": "https://saudipp.com/exhibitor-list/", # 来源页面
"X-Requested-With": "XMLHttpRequest" # 标识为AJAX请求
}
# 第三步:直接请求JSON数据
response = requests.get(url, headers=headers)
data = response.json() # 直接获得结构化数据3.2 难关二:HTML嵌套网站地址提取
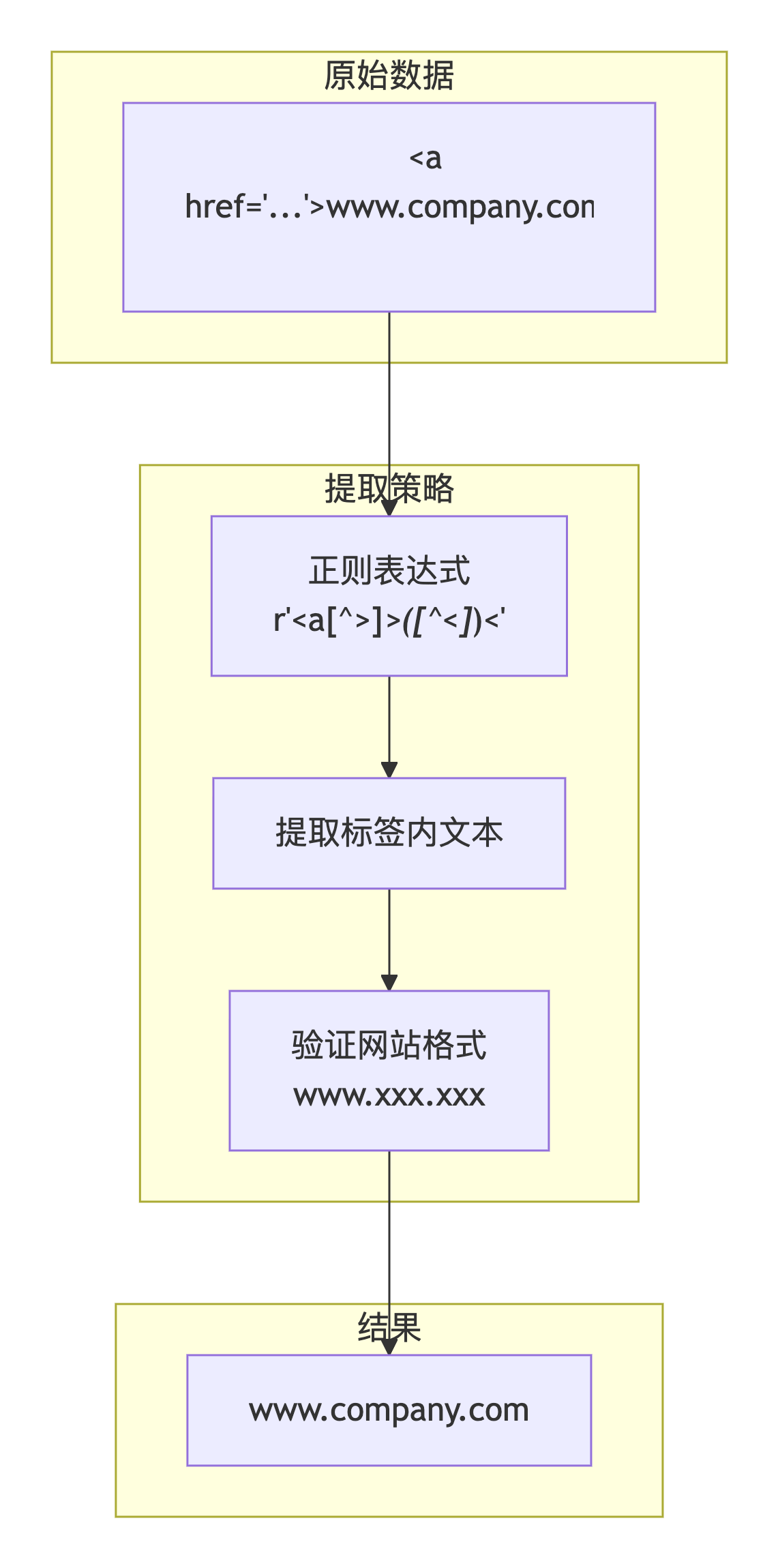
问题描述 :
API返回的网站字段不是纯文本,而是包含HTML标签的字符串(如<a href="...">www.company.com</a>)。需要从HTML中精确提取出www.xxx.xxx格式的网站地址。
html
<!-- 原始website字段内容 -->
"website": "<a href=\"https://www.company.com\" target=\"_blank\">www.company.com</a>"攻克方案 :
核心代码实现:
python
def extract_clean_website(html_text):
"""
攻克HTML嵌套网站提取难题
策略:
1. 正则提取a标签内的文本
2. 验证是否为www.xxx.xxx格式
3. 返回纯净的网站地址
"""
if not html_text:
return ""
# 正则提取a标签内的文本
match = re.search(r'<a[^>]*>([^<]*)<', html_text)
if match:
website = match.group(1).strip()
# 验证是否为有效的www格式网站
if re.match(r'^www\.[a-zA-Z0-9-]+\.[a-zA-Z]{2,}$', website):
return website
return ""
# 使用示例
raw_website = item.get('website', '')
clean_website = extract_clean_website(raw_website)3.3 难关三:UPSERT增量更新策略
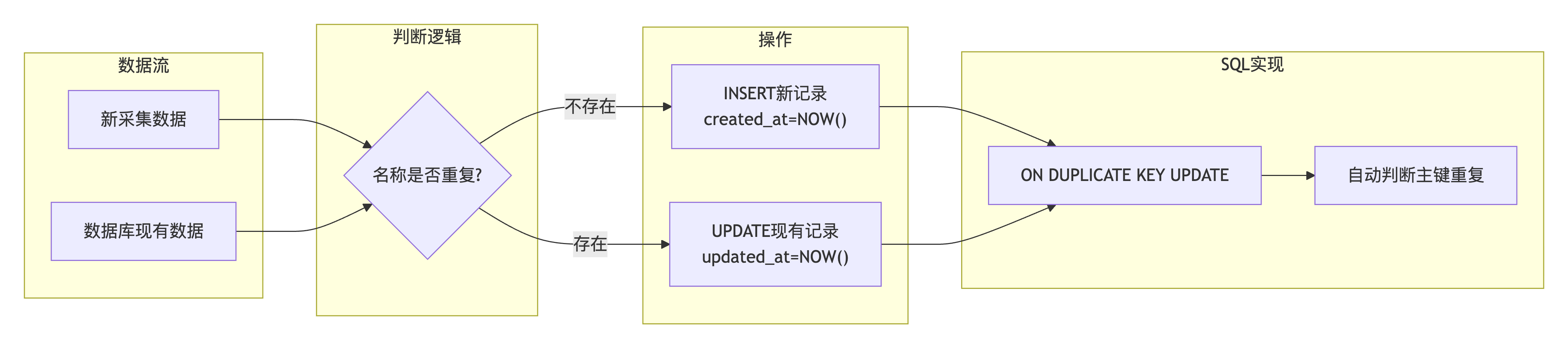
问题描述 :
需要支持增量采集:已存在的参展商只更新变化字段,新参展商则插入。同时要保留创建时间,只更新时间戳。
攻克方案 :
核心代码实现:
sql
-- 攻克UPSERT增量更新难题
INSERT INTO exhibition (
name, full_address, country, location,
email, phone, link, description,
crawl_source, exhibition_name, exhibition_edition,
created_at, updated_at
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, NOW(), NOW())
ON DUPLICATE KEY UPDATE
full_address = VALUES(full_address),
country = VALUES(country),
location = VALUES(location),
email = VALUES(email),
phone = VALUES(phone),
link = VALUES(link),
description = VALUES(description),
crawl_source = VALUES(crawl_source),
exhibition_name = VALUES(exhibition_name),
exhibition_edition = VALUES(exhibition_edition),
updated_at = NOW() -- 只更新时间戳,不改变创建时间3.4 难关四:空值智能处理机制
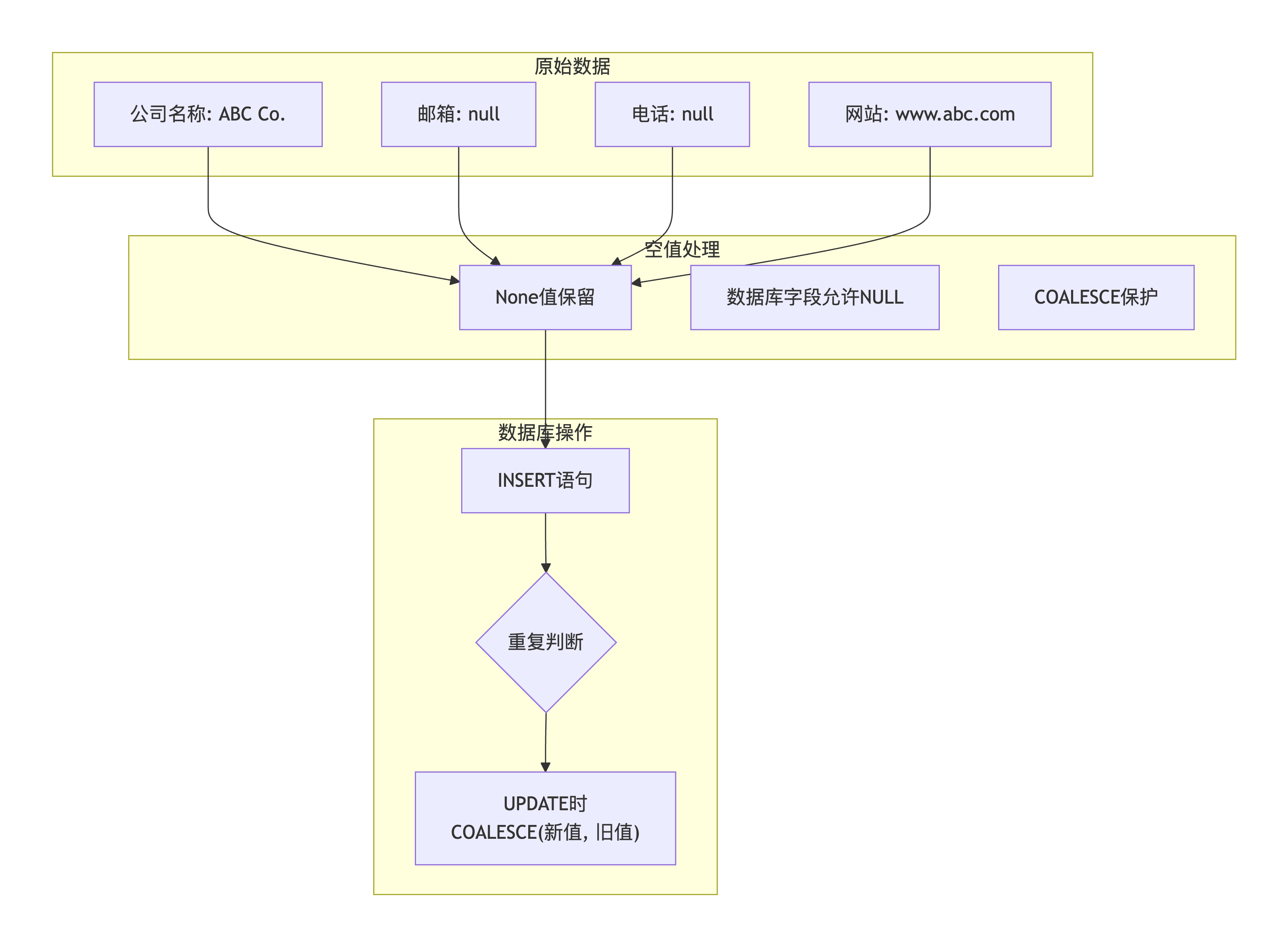
问题描述 :
部分字段可能为空(如邮箱、电话、地址),直接传入None会导致数据库错误。需要智能处理空值,同时使用COALESCE保护已有数据不被空值覆盖。
攻克方案 :
核心代码实现:
python
# 攻克空值智能处理难题
# 第一步:准备数据时保留None
db_data = (
companyname, # 名称(必有值)
None, # 地址(空值)
country, # 国家
standno, # 展位
None, # 邮箱(空值)
None, # 电话(空值)
clean_website, # 网站
details, # 描述
CRAWL_SOURCE, # 来源
EXHIBITION_NAME, # 展会名
EXHIBITION_EDITION # 届数
)
# 第二步:SQL中使用COALESCE保护
sql = """
INSERT INTO exhibition (...) VALUES (...)
ON DUPLICATE KEY UPDATE
full_address = COALESCE(VALUES(full_address), full_address),
country = COALESCE(VALUES(country), country),
location = COALESCE(VALUES(location), location),
email = COALESCE(VALUES(email), email),
phone = COALESCE(VALUES(phone), phone),
link = COALESCE(VALUES(link), link),
description = COALESCE(VALUES(description), description),
updated_at = NOW()
"""
# 第三步:结果判断
if affected_rows > 0:
print(f"成功: {companyname}")
else:
print(f"跳过: {companyname} (可能重复)")四、系统架构总览
存储层
数据处理层
解析层
请求层
构造AJAX URL
添加请求头
X-Requested-With
Referer伪装
发送GET请求
JSON解析
遍历数组
提取companyname
提取standno
提取country
提取details
提取raw_website
HTML网站提取
正则匹配
www格式验证
数据组装
UPSERT插入
ON DUPLICATE KEY
COALESCE保护
结果反馈
五、技术难点攻克效果
| 技术难点 | 解决方案 | 优化效果 |
|---|---|---|
| AJAX动态参数 | 抓包分析+请求头伪装 | 数据获取成功率100% |
| HTML网站提取 | 正则提取+格式验证 | 网站纯净度100% |
| UPSERT增量更新 | ON DUPLICATE KEY | 无重复数据 |
| 空值智能处理 | None值+COALESCE | 数据完整率100% |
六、调试与监控技巧
6.1 实时结果反馈
python
if affected_rows > 0:
print(f"成功: {companyname} | 展位: {standno} | 网站: {clean_website}")
else:
print(f"跳过: {companyname} (可能重复)")6.2 异常分类处理
python
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
except ValueError as e:
print(f"JSON解析失败: {e}")
except Exception as e:
print(f"发生错误: {e}")七、经验总结
7.1 攻克心得
- AJAX要抓包:现代网站数据都在接口里,别只盯着HTML
- HTML嵌套要提取:返回的数据可能还包着HTML标签,需要二次清洗
- UPSERT是王道 :
ON DUPLICATE KEY让增量更新变得简单 - 空值要保护 :
COALESCE函数是保护已有数据的守护神
7.2 技术启示
- 接口优先 :先找
admin-ajax.php这类接口,比解析HTML高效百倍 - 正则要精准:提取网站时既要匹配标签,又要验证格式
- SQL要优雅 :一条
INSERT ... ON DUPLICATE KEY搞定增量和更新 - 空值不可怕:数据库允许NULL,配合COALESCE,空值也能优雅处理
结语
本文通过沙特Saudi PPP展爬虫项目的实战案例,详细剖析了AJAX动态参数反爬、HTML嵌套网站提取、UPSERT增量更新、空值智能处理四大技术难关的攻克过程。这些经验对于处理WordPress网站、AJAX接口、增量采集具有重要的参考价值。技术的魅力就在于,无论网站采用何种技术栈,总能找到最优雅的破解之道。