大家好!今天我们将深入探讨进程地址空间的相关知识,同时也会解答之前文章中遗留的一些问题。相信通过这篇文章的学习,大家一定能有所收获!
历史问题引入
在前面文章中我们介绍了fork函数,有如下的形式:
cpp
pid_t id = fork();
if (id == 0)
...
else if (id > 0)
...通过不同的返回值去让父子进程执行不同的函数体,但是我们有想过一些问题吗:
我们前面文章中讲过在return的时候会进行写入,在这里发生了写时拷贝,导致id的值不一样,但是对于id来讲它就只是一个变量啊,它既等于0,又大于0了?
其实我们还是不能理解这是为什么,对写时拷贝也不理解。
接下来我们将通过对于进程地址空间的讲解,就能够理解它了。
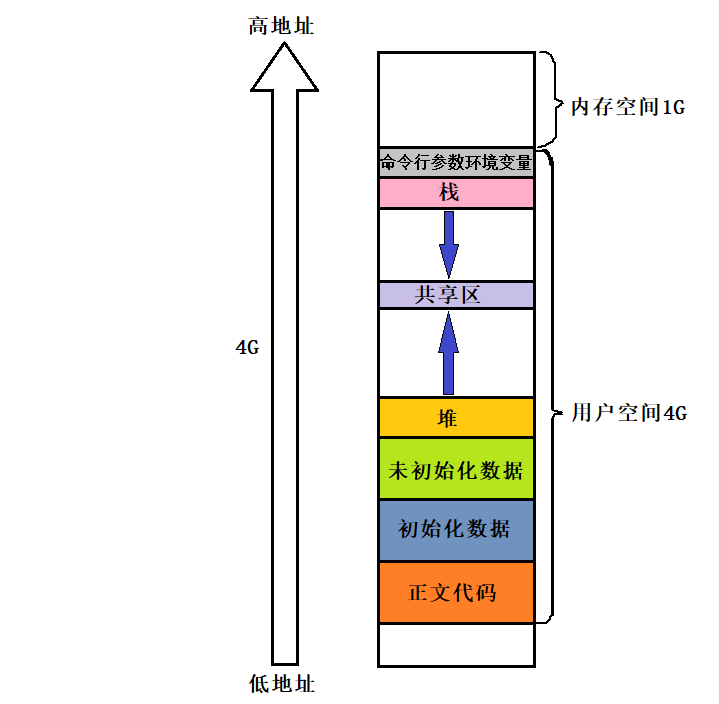
C/C++的内存整体布局
在学习C/C++时,讲解变量类型时通常会提到不同变量存储在不同内存区域。
栈区向下生长,堆区向上生长
- 局部变量具有临时性,存储在栈区
- 通过malloc和new申请的动态内存空间在堆区分配
- 全局变量可被所有函数访问,存储在全局变量区
cpp
#include <stdio.h>
#include <stdlib.h>
int g_val_1;
int g_val_2 = 100;
int main()
{
printf("code addr: %p\n", main);
const char* str = "hello c";
printf("read only string addr: %p\n", str);
printf("init global value addr: %p\n", &g_val_2);
printf("uninit global value addr: %p\n", &g_val_1);
char* mem = (char*)malloc(100);
printf("heap addr: %p\n", mem);
printf("stack addr: %p\n", &str);
return 0;
}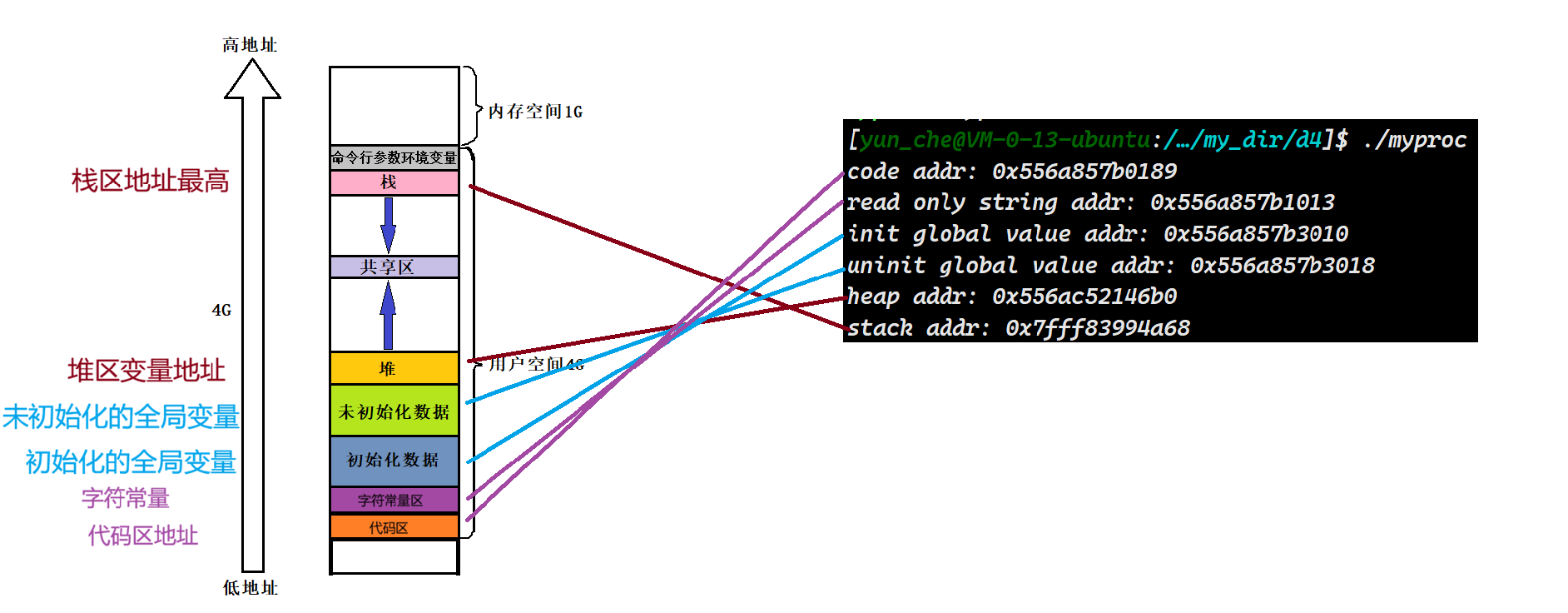
通过上面的代码我们可以看到,根据打印出来的不同地址我们就可以发现不同的变量是存储在不同的区域的
cpp
#include <stdio.h>
#include <stdlib.h>
int g_val_1;
int g_val_2 = 100;
int main()
{
printf("code addr: %p\n", main);
const char* str = "hello c";
printf("read only string addr: %p\n", str);
printf("init global value addr: %p\n", &g_val_2);
printf("uninit global value addr: %p\n", &g_val_1);
char* mem = (char*)malloc(100);
printf("heap addr: %p\n", mem);
printf("stack addr: %p\n", &str);
int a;
int b;
int c;
printf("stack addr: %p\n", &a);
printf("stack addr: %p\n", &b);
printf("stack addr: %p\n", &c);
return 0;
}我们再次加入了几个局部变量,看看是否栈区是向下生长的:
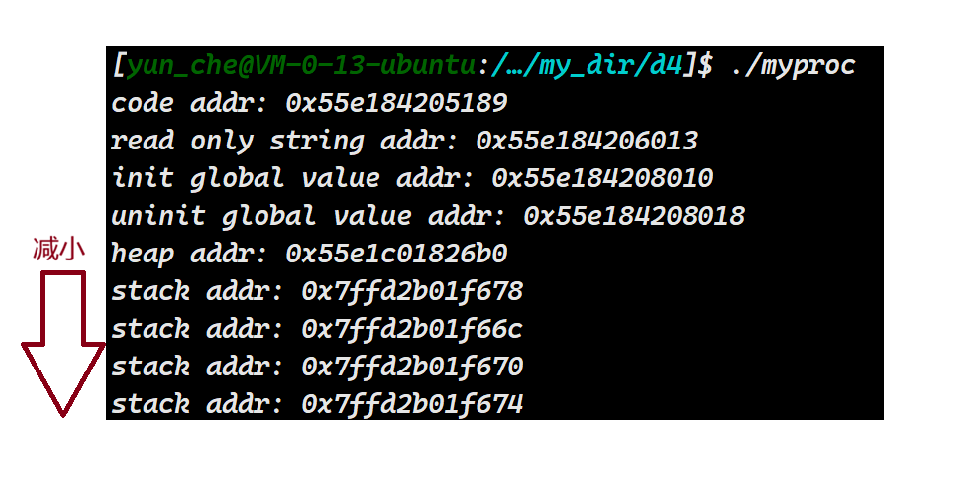
可以发现,我们的栈区是向下生长的~
cpp
#include <stdio.h>
#include <stdlib.h>
int g_val_1;
int g_val_2 = 100;
int main()
{
printf("code addr: %p\n", main);
const char* str = "hello c";
printf("read only string addr: %p\n", str);
printf("init global value addr: %p\n", &g_val_2);
printf("uninit global value addr: %p\n", &g_val_1);
char* mem1 = (char*)malloc(100);
char* mem2 = (char*)malloc(100);
char* mem3 = (char*)malloc(100);
printf("heap addr: %p\n", mem1);
printf("heap addr: %p\n", mem2);
printf("heap addr: %p\n", mem3);
printf("stack addr: %p\n", &str);
int a;
int b;
int c;
printf("stack addr: %p\n", &a);
printf("stack addr: %p\n", &b);
printf("stack addr: %p\n", &c);
return 0;
}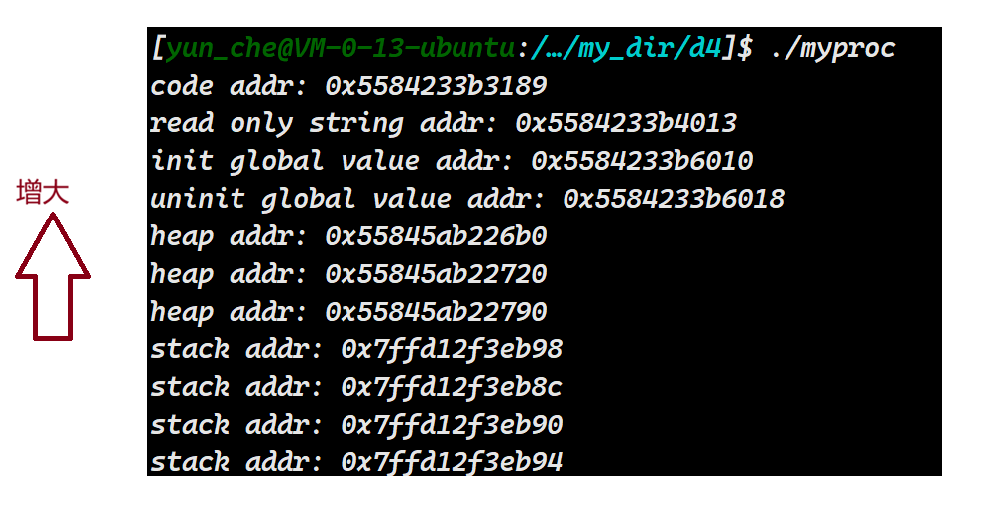
随着堆空间申请内存,地址就开始上升,可以发现,堆是向上生长的~
cpp
#include <stdio.h>
#include <stdlib.h>
int g_val_1;
int g_val_2 = 100;
int main()
{
printf("code addr: %p\n", main);
const char* str = "hello c";
printf("read only string addr: %p\n", str);
printf("init global value addr: %p\n", &g_val_2);
printf("uninit global value addr: %p\n", &g_val_1);
char* mem1 = (char*)malloc(100);
char* mem2 = (char*)malloc(100);
char* mem3 = (char*)malloc(100);
printf("heap addr: %p\n", mem1);
printf("heap addr: %p\n", mem2);
printf("heap addr: %p\n", mem3);
printf("stack addr: %p\n", &str);
static int a;
int b;
int c;
printf("a = stack addr: %p\n", &a);
printf("stack addr: %p\n", &b);
printf("stack addr: %p\n", &c);
return 0;
}我们来尝试一下,将a改成static修饰的局部变量,它的地址将变为什么:
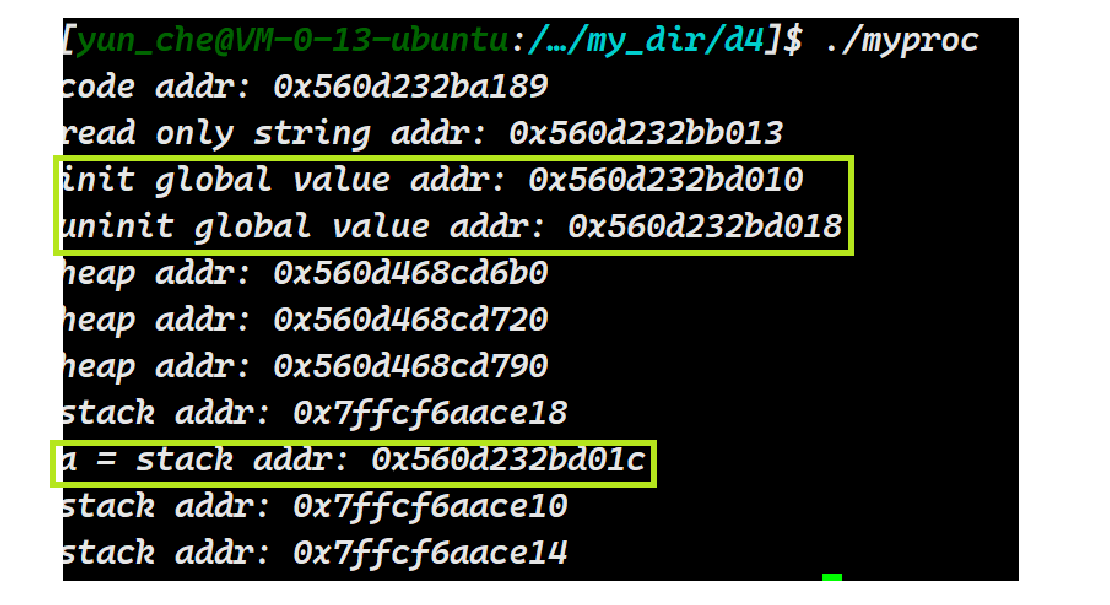
可以发现加入static 后,a变量的地址就变到跟全局变量挨着了,这也就是为什么我们函数结束,static修饰的局部变量生命周期还存在~
但是问题来了,这个东西就是内存吗?
其实不是,这个是进程地址空间
虚拟地址 && 线性地址
前面我们再次复习了一下不同变量的存储在不同分区,那么那个东西就是我们的内存吗?
其实不是的,那个只是虚拟的地址空间
通过下面这个代码就可以看出来了:
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int g_val = 100;
int main()
{
pid_t id = fork();
if (id == 0)
{
// 子进程
int cnt = 5;
while(1)
{
printf("I am child, pid: %d, ppid: %d, g_val: %d, &g_val: %p\n",
getpid(), getppid(), g_val, &g_val);
if (cnt) cnt--;
else{
g_val = 200;
printf("子进程change g_val: 100->200\n");
cnt--;
}
sleep(1);
}
}
else{
// 父进程
while(1)
{
printf("I am parent, pid: %d, ppid: %d, g_val: %d, &g_val: %p\n",
getpid(), getppid(), g_val, &g_val);
sleep(1);
}
}
return 0;
}我们通过子进程将g_val的值进行改变
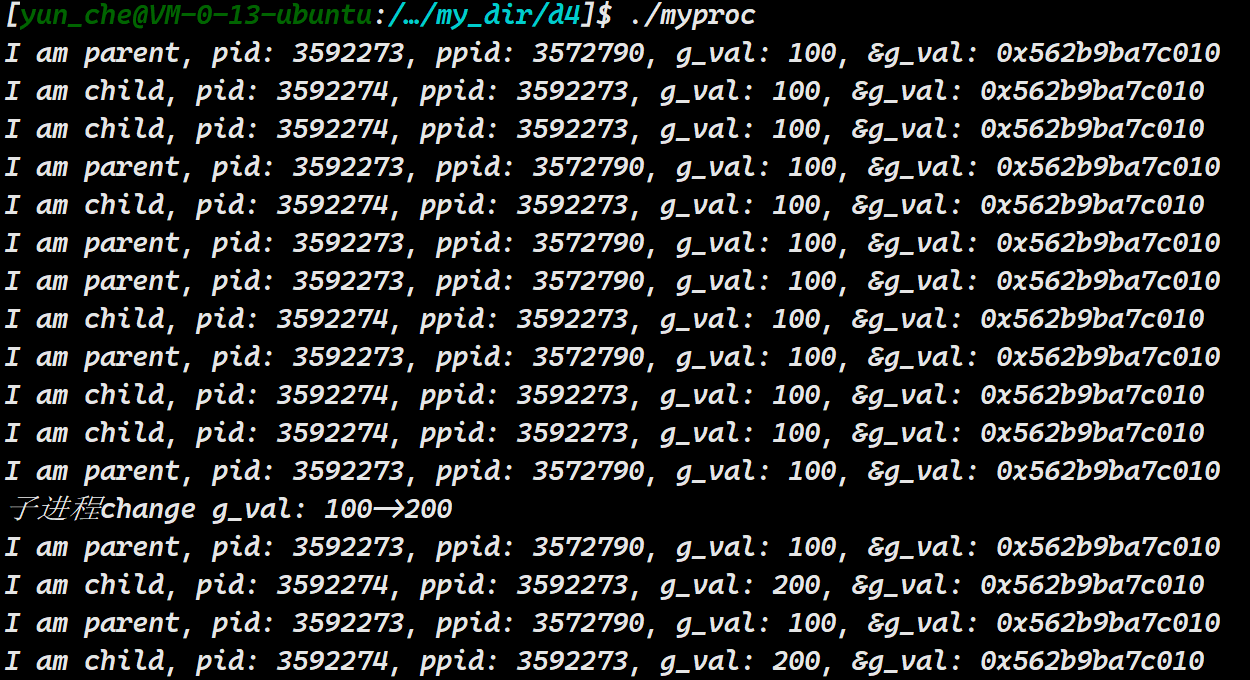
通过打印的结果,当子进程将g_val的值改变以后,后面打印父子进程打印的值却不一样
可能就会想我们之前讲过写时拷贝啊,两个已经被拷贝了,所以打印的值不一样是正常的,但是我们仔细观察,它们的地址还是一样的啊!!!
一个物理地址能够存储不同的值??怎么可能呢!所以这个地址绝对不可能是真正的内存地址
结论:如果变量的地址是物理地址,不可能存在上面的现象!!这个地址绝对不是物理地址
这个地址叫做:****++线性地址 或者 虚拟地址++
所以我们平时写的C/C++用的指针,指针里面的地址,全部都不是物理地址!
进程地址空间,问题解答
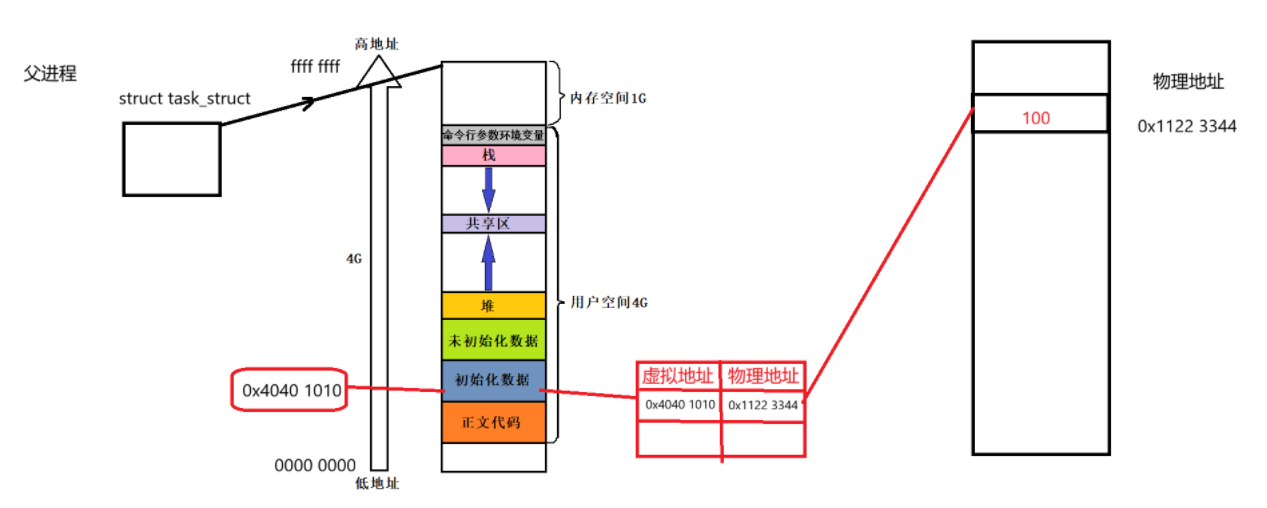
系统在创建进程时,不仅会为其建立PCB(进程控制块)这样的内核数据结构,还会为每个进程分配一个独立的进程地址空间结构体。父进程的PCB中会通过指针来引用这个地址空间结构。
进程的虚拟地址空间按照从0x00000000到0xFFFFFFFF的线性方式排列。
此外,系统还会为每个进程维护一个页表结构 。页表采用键值对(key-value)的形式存储,主要用于记录虚拟地址到物理地址的映射关系。
内存空间分配完成后,系统会为其分配物理地址。通过建立虚拟地址与物理地址的映射关系,处理器可以根据页表将虚拟地址转换为物理地址,从而访问存储在物理内存中的数据。
此时,父进程创建子进程时会复制一份相同的进程地址空间和页表。
初始阶段,子进程会完全继承父进程的页表映射关系。但当子进程需要修改变量值时,系统会触发写时拷贝机制:首先通过虚拟地址找到对应的物理地址,若检测到需要修改数据,则会在内存中重新分配空间,建立新的虚拟地址到物理地址的映射关系。
这样,父子进程在查询变量地址时,虽然看到的虚拟地址相同,但实际映射的物理地址已经发生变化,从而导致了变量值的差异。
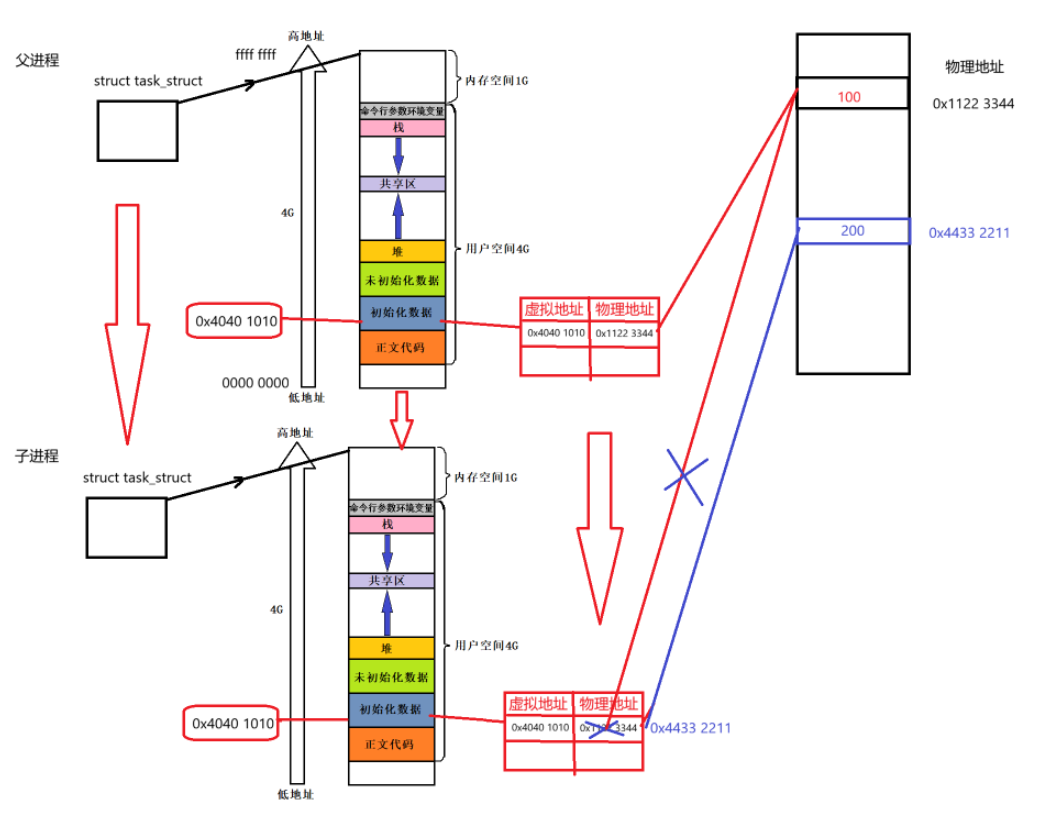
至此,父子进程就实现了代码,数据共享,改变数据的时候写时拷贝,重新开辟空间,但是在这个过程中,左侧的虚拟地址是0感知的,不关心,不会影响它~
细节 - 进程地址空间本质
地址空间解析
1. 地址空间概念
1.1 地址空间定义
地址空间是指地址总线通过排列组合形成的地址范围,表示为0, 2\^32。
1.2 地址空间区域划分
区域划分实质上是通过定义起始(start)和结束(end)地址来划定内存范围,超出该范围的访问将被视为非法。
2. 32位系统的地址空间特性
在32位计算机架构中,32位的地址和数据总线意味着:
- 每条总线只能传输0或1信号
- 地址组合总数可达2^32种
- 由此决定的最大内存容量为4GB(2^32 × 1byte)
3. 进程地址空间本质
- 表示进程可访问的内存范围
- 必须包含多个区域划分,每个区域通过线性地址的start和end界定
- 作为内核数据结构对象,与PCB类似,需要由操作系统统一管理
cpp
struct mm_struct
{
long code_start;
long code_end;
long readonly_start;
long readonly_end;
long init_start;
long init_end;
long uninit_start;
long uninit_end;
long heap_start;
long heap_end;
long stack_start;
long stack_end;
......
};在范围内,连续的空间中,每一个最小单位都可以有地址,这个地址可以被使用
4.为什么要有进程地址空间?
-
为进程提供统一的内存访问视图
-
通过虚拟地址到物理地址的转换机制实现内存访问控制。该转换过程可进行地址合法性校验,当检测到异常访问时立即拦截请求,防止非法操作触及物理内存,从而确保内存安全。
-
++通过页表的存在我们就可以完成进程管理和内存管理进行解耦合!++
每个进程都维护着一个task_struct结构体,其中包含指向进程地址空间的mm_struct* mm指针。当进程被CPU调度切换时,这个地址空间信息会随进程上下文一起保存,确保恢复时能够正确访问。对于页表管理,CPU通过cr3寄存器存储当前页表的物理地址。在进程切换时,cr3寄存器的值会被保存在对应的硬件上下文中,待进程恢复执行时即可重新加载正确的页表信息。
要确定进程访问的物理地址权限,系统在页表 中维护了一个权限位图(rw) 。通过检查该位图中的读写标志位,就能判断当前内存操作是否合法。这种机制有效防止了非法访问行为的发生。它确保了C/C++语言中不同变量操作权限的合理分配
页表 中维护了一个标志位 ,用于判断对应的代码和数据是否已加载到内存 。在查询页表时,首先需要检查该标志位。若发现标志位为0(表示未加载到内存),则会触发操作系统的缺页中断。
因此,进程创建时首先会初始化内核数据结构 ,随后才加载对应的可执行程序。在此过程中,只需创建进程地址空间和相应的页表即可。
通过页表机制,我们实现了进程管理与内存管理的有效解耦。
结尾
这篇文章深入浅出地讲解了进程地址空间的相关知识,相信大家都能从中获益。希望大家能全面掌握进程地址空间、页表、虚拟内存和物理内存这些核心概念,真正理解它们的原理与关联。
点赞 + 收藏 + 关注!!!❤️❤️❤️
