本篇文章介绍如何定义线程模型,以及如何在GPU上利用并行计算方式实现矩阵相加
大部分代码利用了之前代码中的部分完整代码如下:
#include "../common/common.h"
#include <stdio.h>
//***********矩阵初始化函数 */
void initialData(float *ip,int size)
{
time_t t;
srand((unsigned)time(&t));
printf("Matrix is :");
for (int i=0;i<size;i++)
{
ip[i]=(float)(rand() & 0xFF) / 10.0f;
printf("%.2f,",ip[i]);
}
printf("\n");
return;
}
//***********GPU加法函数 */
__global__ void sumArraryOnGPU(float *A, float *B, float *C, const int N)
{
int i = threadIdx.x;
if (i < N)
{
C[i] = A[i] + B[i];
}
}
//***********主函数 */
int main(int argc, char **argv)
{
//***********GPU检测 */
int nDeviceNumber = 0;
cudaError_t error = ErrorCheck(cudaGetDeviceCount(&nDeviceNumber), __FILE__, __LINE__);
if (error != cudaSuccess || nDeviceNumber == 0)
{
printf("No CUDA campatable GPU found!\n");
return -1;
}
int dev = 0;
error = ErrorCheck(cudaSetDevice(dev), __FILE__, __LINE__);
if (error != cudaSuccess)
{
printf("fail to set GPU 0 for computing\n");
return -1;
}
else
{
printf("successfully allocate memory for GPU\n");
}
//***********内存分配 */
int nElem = 16;
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
if (NULL != h_A && NULL != h_B && NULL != gpuRef)
{
printf("allocate memory successfully\n");
}
else
{
printf("fail to allocate memory\n");
return -1;
}
initialData(h_A, nElem);
initialData(h_B, nElem);
memset(gpuRef, 0, nBytes);
//***********显存分配 */
float *d_A, *d_B, *d_C;
cudaMalloc((float **)&d_A, nBytes);
cudaMalloc((float **)&d_B, nBytes);
cudaMalloc((float **)&d_C, nBytes);
if (d_A == NULL || d_B == NULL || d_C == NULL)
{
printf("fail to allocate memory for GPU\n");
free(h_A);
free(h_B);
free(gpuRef);
return -1;
}
else
{
printf("successfully allocate memory for GPU\n");
}
//***********拷贝数据,主机到设备 */
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_C, gpuRef, nBytes, cudaMemcpyHostToDevice);
//***********线程模型定义 */
dim3 block(nElem);
dim3 grid(1);
sumArraryOnGPU<<<grid,block>>>(d_A,d_B,d_C,nElem);
cudaMemcpy(gpuRef,d_C,nBytes,cudaMemcpyDeviceToHost);
for (int i=0;i<nElem;i++)
{
printf("idx=%d,matrix_A:%.2f,matrix_B:%.2f,result=%.2f\n",i+1,h_A[i],h_B[i],gpuRef[i]);
}
free(h_A);
free(h_B);
free(gpuRef);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
cudaDeviceReset();
return 0;
}第一部分,仍然是定义CPU上的初始化矩阵函数
//***********矩阵初始化函数 */
void initialData(float *ip,int size)
{
time_t t;//获取系统当前时间
srand((unsigned)time(&t));//设置随机数字种子
printf("Matrix is :");
for (int i=0;i<size;i++)
{
ip[i]=(float)(rand() & 0xFF) / 10.0f;//给数组赋初值,取低8位
printf("%.2f,",ip[i]);
}
printf("\n");
return;
}第二部分,定义设备代码(或者kernel函数)
//***********GPU加法函数 */
//设备代码和主机代码最大的区别:主机代码实现矩阵加法需要通过双循环遍历每个元素进行相加
//设备代码只需要定义一次加法,然后后续设计线程模型,让多个线程同时执行即可
__global__ void sumArraryOnGPU(float *A, float *B, float *C, const int N)
{
int i = threadIdx.x;
if (i < N)
{
C[i] = A[i] + B[i];
}
}第三部分,GPU设备检测
//***********GPU检测 */
int nDeviceNumber = 0;
cudaError_t error = ErrorCheck(cudaGetDeviceCount(&nDeviceNumber), __FILE__, __LINE__);
//利用CUDA运行时库检测是否有可用
if (error != cudaSuccess || nDeviceNumber == 0)
{
printf("No CUDA campatable GPU found!\n");
return -1;
}
//用默认设别编号,给编号为0的设备分配显存
int dev = 0;
error = ErrorCheck(cudaSetDevice(dev), __FILE__, __LINE__);
if (error != cudaSuccess)
{
printf("fail to set GPU 0 for computing\n");
return -1;
}
else
{
printf("successfully allocate memory for GPU\n");
}第三部分,主机内存分配
//***********内存分配 */
int nElem = 16;
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
if (NULL != h_A && NULL != h_B && NULL != gpuRef)
{
printf("allocate memory successfully\n");
}
else
{
printf("fail to allocate memory\n");
return -1;
}
//先分配内存,然后对内存上指定范围的数据进行初始化
initialData(h_A, nElem);
initialData(h_B, nElem);
memset(gpuRef, 0, nBytes);第四部分,显存分配
//***********显存分配 */
float *d_A, *d_B, *d_C;
//调用cudaMalloc分配显存,传参类型必须是指向指针的指针
//因为只传d_A本身无法改变其上面的值
cudaMalloc((float **)&d_A, nBytes);
cudaMalloc((float **)&d_B, nBytes);
cudaMalloc((float **)&d_C, nBytes);
if (d_A == NULL || d_B == NULL || d_C == NULL)
{
printf("fail to allocate memory for GPU\n");
free(h_A);
free(h_B);
free(gpuRef);
return -1;
}
else
{
printf("successfully allocate memory for GPU\n");
}第五部分:数据拷贝
//***********拷贝数据,主机到设备 */
//把定义并分配好数据的矩阵,从主机拷贝到设备上
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_C, gpuRef, nBytes, cudaMemcpyHostToDevice);
//***********线程模型定义 */
//一个graid含有1个block,一个block含有nElem个Thread
dim3 block(nElem);
dim3 grid(1);
//用1个grid上的1个block中的nElem个Thread同时执行kernel函数
sumArraryOnGPU<<<grid,block>>>(d_A,d_B,d_C,nElem);
//将运行结果拷贝回主机上
cudaMemcpy(gpuRef,d_C,nBytes,cudaMemcpyDeviceToHost);第六部分:释放内存:
//在主机上显示计算结果
for (int i=0;i<nElem;i++)
{
printf("idx=%d,matrix_A:%.2f,matrix_B:%.2f,result=%.2f\n",i+1,h_A[i],h_B[i],gpuRef[i]);
}
free(h_A);
free(h_B);
free(gpuRef);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
cudaDeviceReset();
return 0;
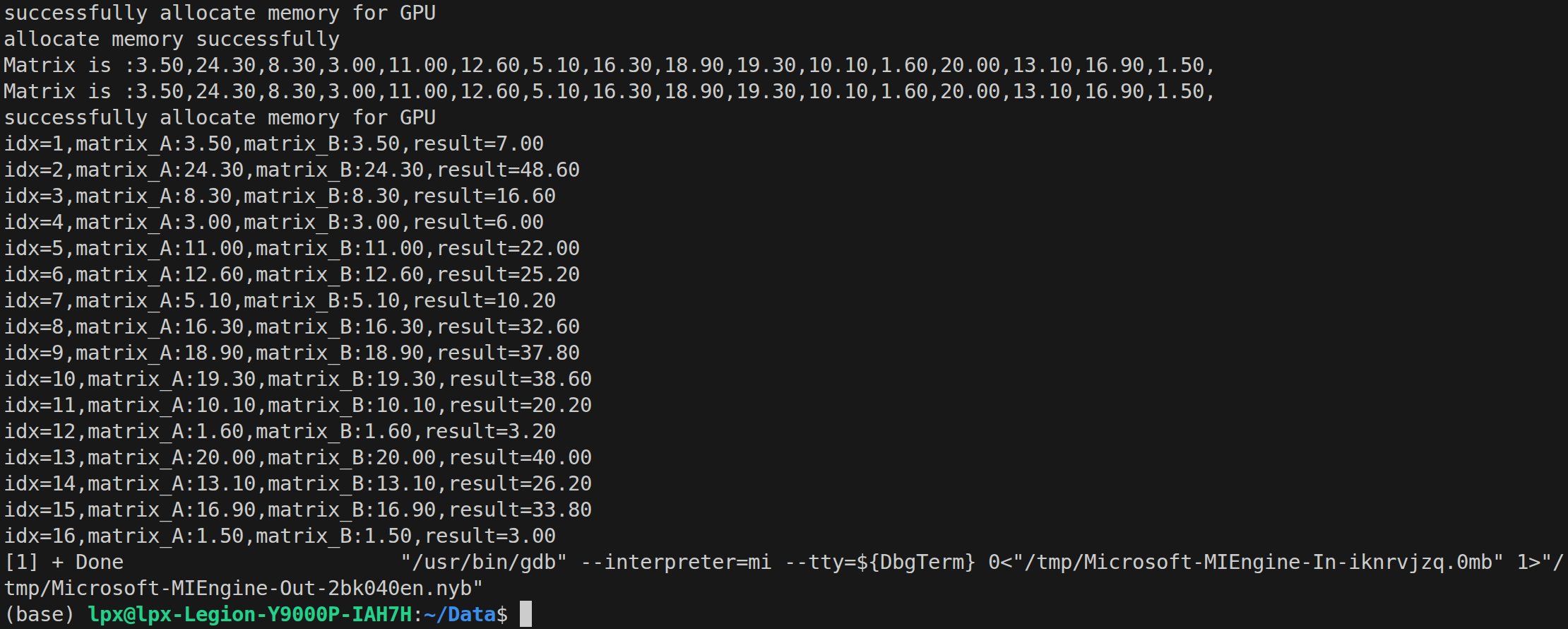
}查看执行结果: