题目一
首先先看数组
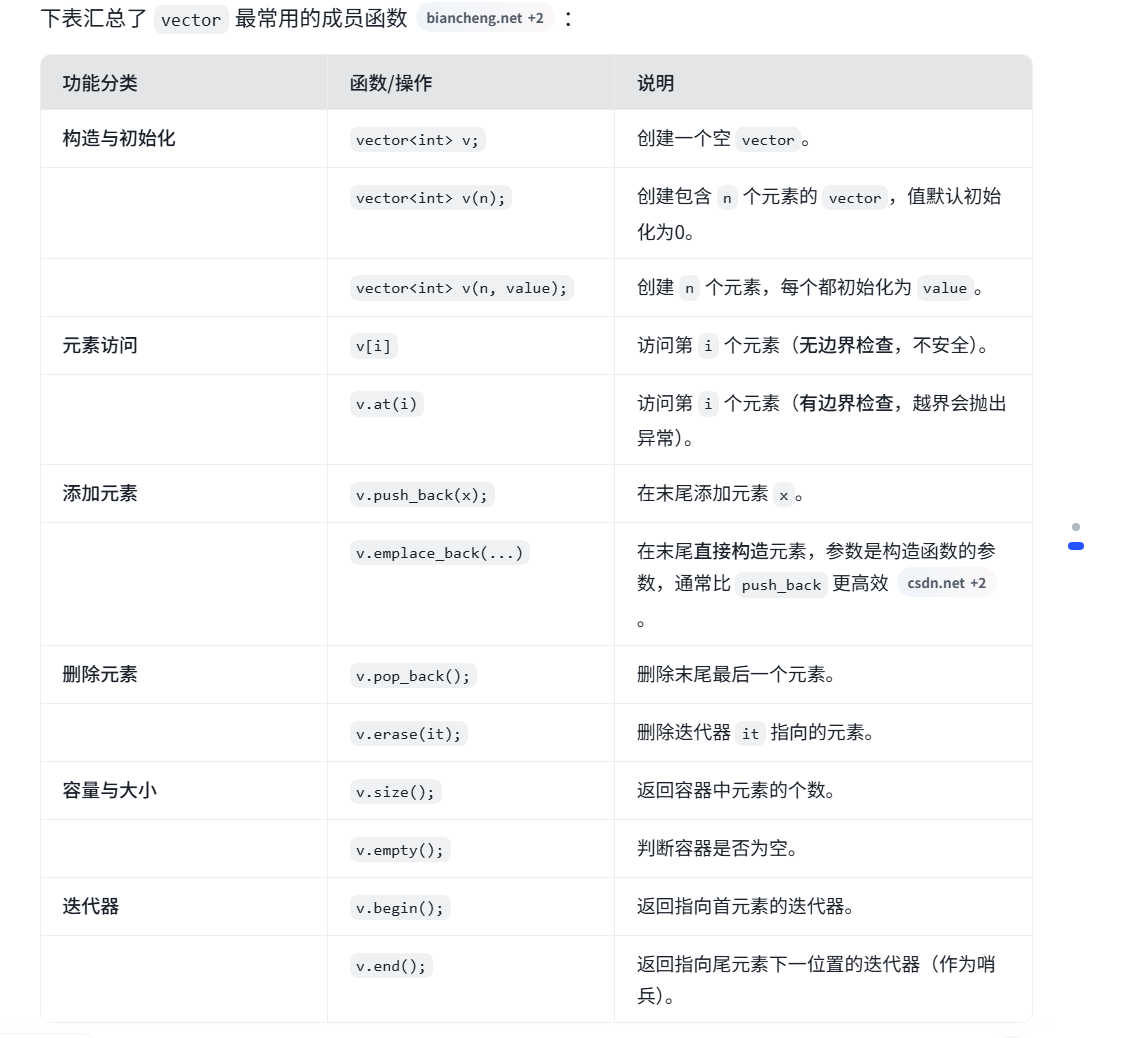
一、 std::vector :动态数组容器
vector 是 C++ 标准模板库(STL)中最常用的容器之一,本质上是一个可以动态改变大小的数组biancheng.net+1。
1. 核心特点
- 动态性:可以在运行时动态地增加或减少元素,自动管理内存biancheng.net+1。
- 连续内存 :元素在内存中连续存储,支持随机访问(通过下标访问元素效率高,O(1)时间复杂度)biancheng.net。
- 类型安全 :声明时需指定元素类型,如
vector<int>存整数,vector<string>存字符串cnblogs.com+1。
2. 常用操作一览
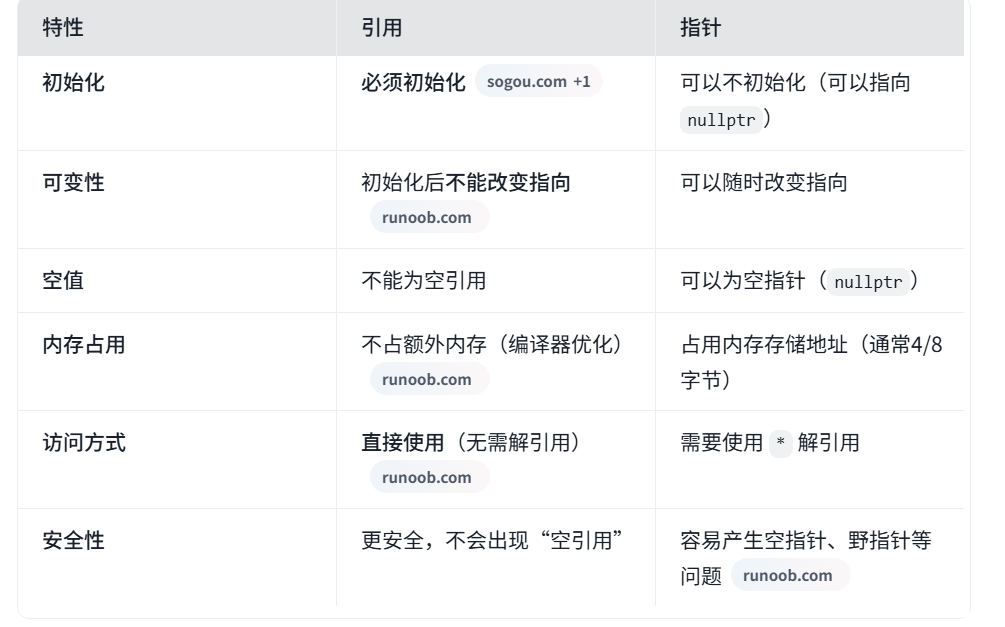
、 & 符号:引用的奥秘
& 在 C++ 中有两个截然不同的用途,初学者容易混淆。
1. 在声明 中:定义引用
这是你之前代码 vector<int>& nums 中的用法。引用是某个变量的别名(别名)
- 语法 :
类型 &引用名 = 变量名; - 核心特性 :
-
必须初始化:定义引用时必须立即指向一个有效变量
-
不能为空:不存在"空引用"。
-
一旦绑定,无法改变:引用初始化后,就不能再让它引用其他变量
-
操作即操作原变量 :对引用的任何操作,都直接作用于它所引用的那个变量
cppint a = 10; int &ref = a; // ref是a的引用,即别名 ref = 20; // 通过引用修改,a的值变为20 cout << a; // 输出 202. 在表达式中:取地址运算
这是C语言遗留的用法,用于获取变量的内存地址。
-
cpp
int a = 10;
int *ptr = &a; // ptr是一个指针,存储了变量a的地址3. 关键对比:引用 vs 指针
给定一个整数数组
nums和一个整数目标值target,请你在该数组中找出 和为目标值target的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9 输出:[0,1] 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
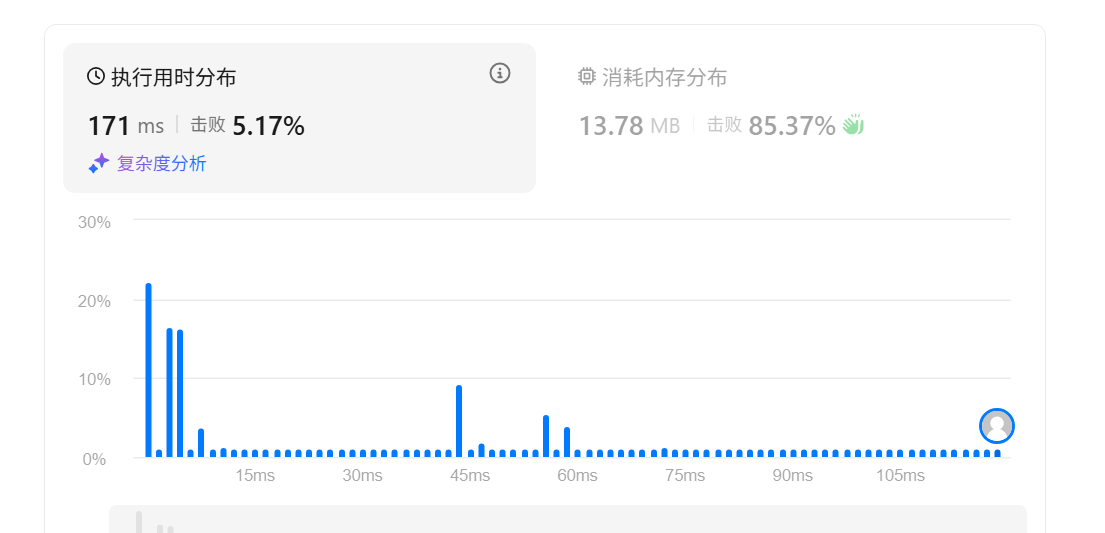
一 使用暴力法
cpp
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
for(int i = 0; i < nums.size(); i++)
{
for(int n = 0; n < nums.size(); n++)
{
if(i != n)
{
if(nums[i] + nums[n] == target)
{
return {i, n};
}
}
}
}
return {};
}
};
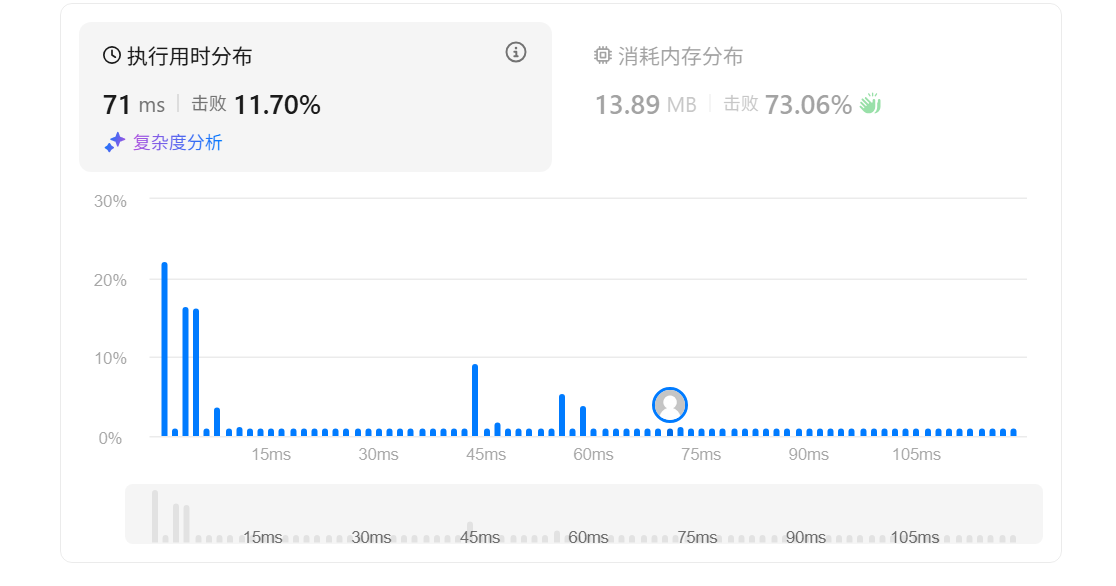
反思:把nums.size()赋值后再循环会减少时执行间
cpp
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
int n = nums.size();
for (int i = 0; i < n; ++i) {
for (int j = i + 1; j < n; ++j) {
if (nums[i] + nums[j] == target) {
return {i, j};
}
}
}
return {};
}
};
二 哈希表
第一部分:算法思想("查字典"逻辑)
哪怕换了语言,核心思想是不变的:不要每次都回头找,而是记下来直接查。
想象你在玩拼图,手里拿着一块拼图编号是 num,你需要找另一块编号为 target - num 的拼图。
- 暴力法:把地上的拼图从头到尾翻一遍,看有没有能配对的。累死你。
- 哈希表法 :你手边有个小本本(哈希表)。
- 捡起一块新拼图
num。 - 先查小本本:"小本本里有没有写着
target - num的记录?" - 如果有 -> 恭喜,配对成功!
- 如果没有 -> 把这块拼图记在小本本上(记录它的值和位置),然后捡下一块。
- 捡起一块新拼图
核心优化:查小本本(哈希表)的速度极快,几乎不花时间。
第二部分:C++ 核心知识(unordered_map)
在 C++ 里,这个"小本本"叫做 unordered_map。这是做这道题必须要会的容器。
1. 头文件
使用它之前,必须包含头文件:
#include <unordered_map>2. 定义与结构
unordered_map<int, int> map;这里有两个 int,是什么意思?
- 第一个
int(Key) :对应我们题目里的数字。因为我们需要通过"数值"来查找,所以数值做 Key。 - 第二个
int(Value) :对应我们题目里的下标。因为题目最后要求返回下标,所以把下标存起来。
3. 关键操作(划重点)
- 存数据:
cpp
map[数值] = 下标;
// 比如:map[7] = 1; 表示数字7在下标1出现过。- 查数据 :
这是 C++ 最大的坑点。你不能直接问map[7],因为如果7不存在,C++ 会自动创建 一个7,这会干扰我们的判断。
必须使用.find()函数:
cpp
// 查找 key 为 complement 的元素
if (map.find(complement) != map.end()) {
// 找到了!
}这里的逻辑是:.find() 返回一个指针(迭代器)。如果这个指针指向了 .end()(末尾),说明没找到;如果没指向末尾,说明找到了。
第三部分:完整代码与逐行解析
cpp
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
// 第一步:构建那个"小本本"
// Key存数值,Value存下标
unordered_map<int, int> map;
// 第二步:遍历数组
// 这里的 i 就是当前元素的下标
for (int i = 0; i < nums.size(); i++) {
int num = nums[i]; // 当前手里的数字
int complement = target - num; // 我要找的那个"另一半"
// 第三步:查小本本
// map.find(complement) 查找键
// 如果不等于 map.end(),说明之前有人把自己记下来了,正好是我要找的
if (map.find(complement) != map.end()) {
// 找到了!
// map[complement] 是之前那个"另一半"的下标
// i 是我自己的下标
return { map[complement], i };
}
// 第四步:没找到,把自己记在小本本上
// 等以后有人来找 target - num 时,就能找到我了
// 这一步必须是"先查后存",防止自己匹配自己
map[num] = i;
}
// 兜底返回,虽然题目说一定有解,不写这行编译器可能会报错
return {};
}
};题目二 字母异位词分组
字符串就是动态数组

哈希表相关知识
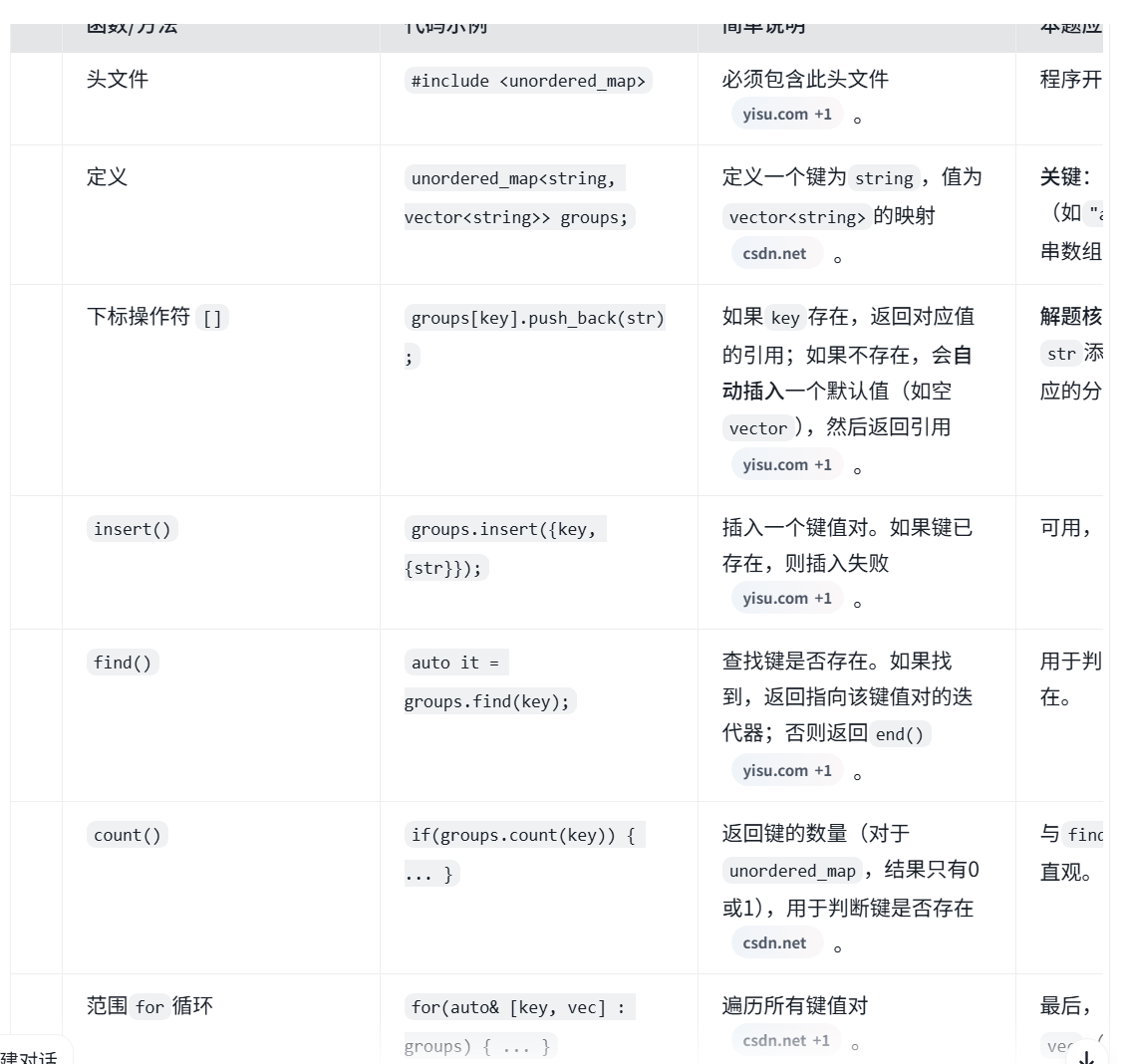
auto类型
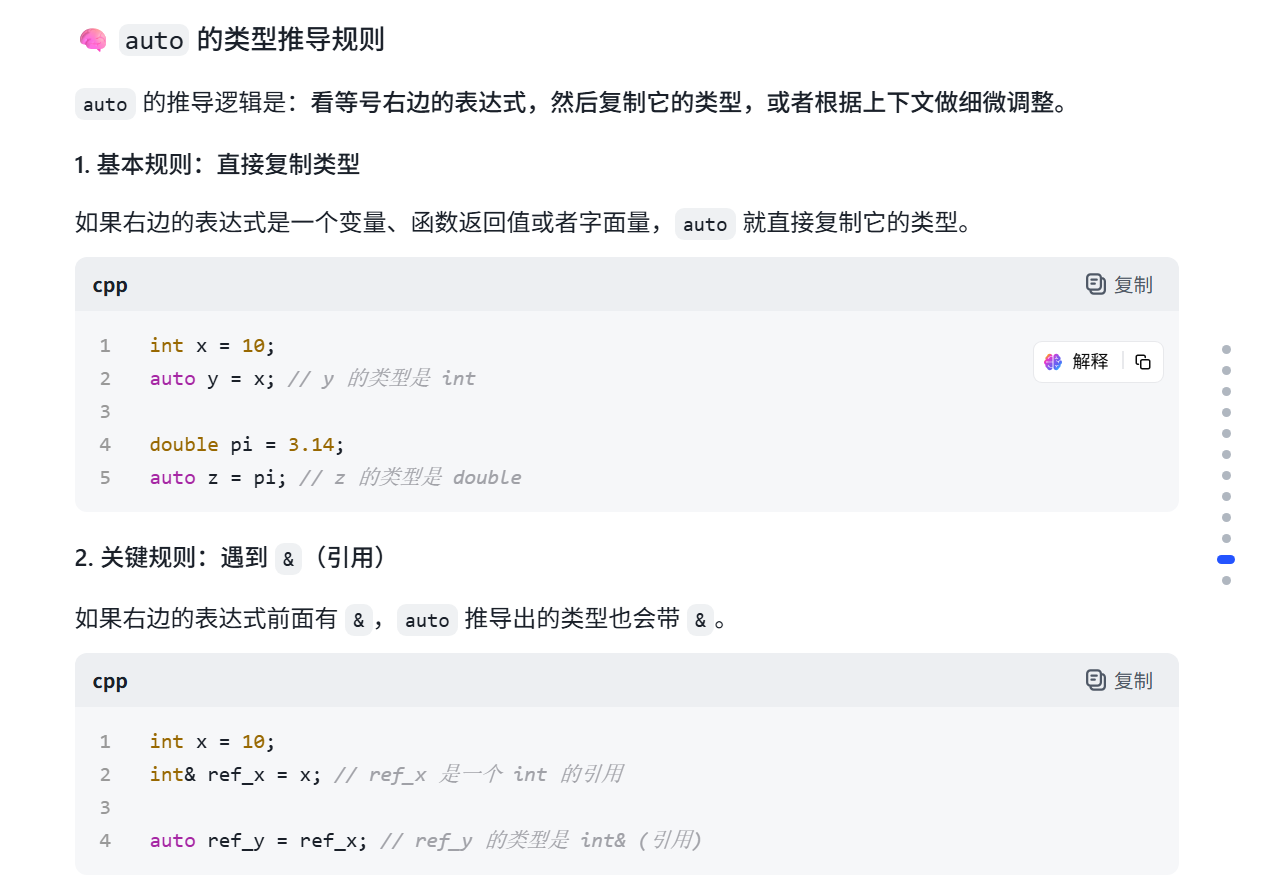
新的for循环
1. for (string& str : strs) vs for (int i = 0; i < n; i++)
这是最明显的变化,也是现代 C++ 的一大亮点。
-
你的写法(传统):
for (int i = 0; i < n; i++) { string s = strs[i]; // ... }
* 原理 :通过一个索引 i 来遍历数组 strs。你需要手动管理索引 i 的初始化、判断和递增。
* 优点 :非常直观,容易理解。
* 缺点 :代码稍长,容易出错(比如 i 越界)。
-
新写法(范围
for循环):for (string& str : strs) { // ... }
* 原理 :这是 C++11 引入的"范围 for 循环"。它会自动遍历 strs 中的每一个元素,并把每个元素依次赋值给 str。
* string& str :这里的 & 是引用 。意思是 str 不是 strs 中元素的副本,而是直接指向 strs 中的那个元素本身。这样做的好处是效率高 ,因为避免了不必要的拷贝。
* 优点 :代码简洁、安全、不易出错。你无需关心数组的长度和索引。
* 注意 :如果不需要修改 strs 中的元素,也可以用 const string& str,这样更安全。
总结 :for (auto& str : strs) 是现代 C++ 中遍历容器(如 vector、array)的标准写法,强烈推荐使用。
题目三
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
示例 1
输入: strs = "eat", "tea", "tan", "ate", "nat", "bat"
输出:\["bat","nat","tan","ate","eat","tea"]
解释:
- 在 strs 中没有字符串可以通过重新排列来形成
"bat"。 - 字符串
"nat"和"tan"是字母异位词,因为它们可以重新排列以形成彼此。 - 字符串
"ate","eat"和"tea"是字母异位词,因为它们可以重新排列以形成彼此。
cpp
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
int n = strs.size();
unordered_map<string, vector<string>> map;
for(int i = 0; i < n; i++ )
{
string s = strs[i];
string a = s;
sort(a.begin(),a.end());
map[a].push_back(s);
}
vector<vector<string>> result;
for (auto it = map.begin(); it != map.end(); ++it)
{
result.push_back(it -> second);
}
return result;
}
};逻辑不难,主要是对于哈希图的使用,以及sort函数,先把字符统一化并存储,最后放在一起输出
最长连续序列

第一次写完
cpp
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int> map(nums.begin(), nums.end());
for(int i = 0; i < n; i++)
{
int num = nums[i];
int a = 0;
if(!map.count(num - 1))
{
while(map.count(num))
{
a++;
num++;
if(a > max)
max = a;
}
}
}
return max;
}
};在第80个案例后出错

set会自动帮我筛选掉重复元素,所有不能循环数组而是循环map
cpp
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int> map(nums.begin(), nums.end());
int max = 0;
for(int num : map)
{
int a = 0;
if(!map.count(num - 1))
{
while(map.count(num))
{
a++;
num++;
if(a > max)
max = a;
}
}
}
return max;
}
};题目一二一 买股票的最佳时间
贪心算法

给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
暴力时间过了
cpp
class Solution {
public:
int maxProfit(vector<int>& prices) {
int max = 0;
for (int i = 0; i < prices.size(); ++i)
{
for (int j = i; j < prices.size(); ++j)
{
if ((prices[j] > prices[i]) && (max < prices[j] - prices [i]))
{
max = prices[j] - prices [i];
}
}
}
return max;
}
};本质是找低点,找到低点就算赚的钱,
cpp
class Solution {
public:
int maxProfit(vector<int>& prices) {
if (prices.empty()) return 0;
int minPrice = prices[0];
int maxProfit = 0;
for (int i = 1; i < prices.size(); ++i) {
if (prices[i] < minPrice) {
minPrice = prices[i]; // 更新历史最低价
} else {
maxProfit = max(maxProfit, prices[i] - minPrice);
}
}
return maxProfit;
}
};题目五十五 跳跃游戏
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:nums = [2,3,1,1,4]
输出:true
解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。示例 2:
输入:nums = [3,2,1,0,4]
输出:false
解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。
cpp
class Solution {
public:
bool canJump(vector<int>& nums) {
int max = nums[0];
for(int i = 0; i < nums.size() - 1 ; i++)
{
if(nums[i] > max)
max = nums[i];
if(max == 0)
return false;
max--;
}
return true;
}
};贪心算法只需要计算每次能走的步数max即可
题目四十五 跳跃游戏 II
给定一个长度为 n 的 0 索引 整数数组 nums。初始位置在下标 0。
每个元素 nums[i] 表示从索引 i 向后跳转的最大长度。换句话说,如果你在索引 i 处,你可以跳转到任意 (i + j) 处:
0 <= j <= nums[i]且i + j < n
返回到达 n - 1 的最小跳跃次数。测试用例保证可以到达 n - 1。
示例 1:
输入: nums = [2,3,1,1,4]
输出: 2示例 2:
输入: nums = [2,3,0,1,4]
输出: 2
cs
class Solution {
public:
int jump(vector<int>& nums) {
if(nums.size() == 1)
return 0;
int n = 1;
int i = 0;
while(nums[i] < nums.size() - i - 1)
{
int max = 0;
int a = nums[i] + i;
for(int j = i + 1; j <= a; j++)
{
if(max < j + nums[j])
{
i = j;
max = j + nums[j];
}
}
n++;
}
return n;
}
};关键点是这个j + nums【j】就是找到max步长里面步长最大的就行
题目763
给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。例如,字符串 "ababcc" 能够被分为 ["abab", "cc"],但类似 ["aba", "bcc"] 或 ["ab", "ab", "cc"] 的划分是非法的。
注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s 。
返回一个表示每个字符串片段的长度的列表。
示例 1:
输入:s = "ababcbacadefegdehijhklij"
输出:[9,7,8]
解释:
划分结果为 "ababcbaca"、"defegde"、"hijhklij" 。
每个字母最多出现在一个片段中。
像 "ababcbacadefegde", "hijhklij" 这样的划分是错误的,因为划分的片段数较少。
cpp
class Solution {
public:
vector<int> partitionLabels(string s) {
int last[26];
int length = s.size();
for (int i = 0; i < length; i++) {
last[s[i] - 'a'] = i;
}
vector<int> partition;
int start = 0, end = 0;
for (int i = 0; i < length; i++) {
end = max(end, last[s[i] - 'a']);
if (i == end) {
partition.push_back(end - start + 1);
start = end + 1;
}
}
return partition;
}
};首先这道题做了很久,因为纠缠于暴力,但其实这题并不难,有的时候没思路不能硬做
这题的关键是找到对应字母的最大end,然后使用max来取最大值,最后通过push增加
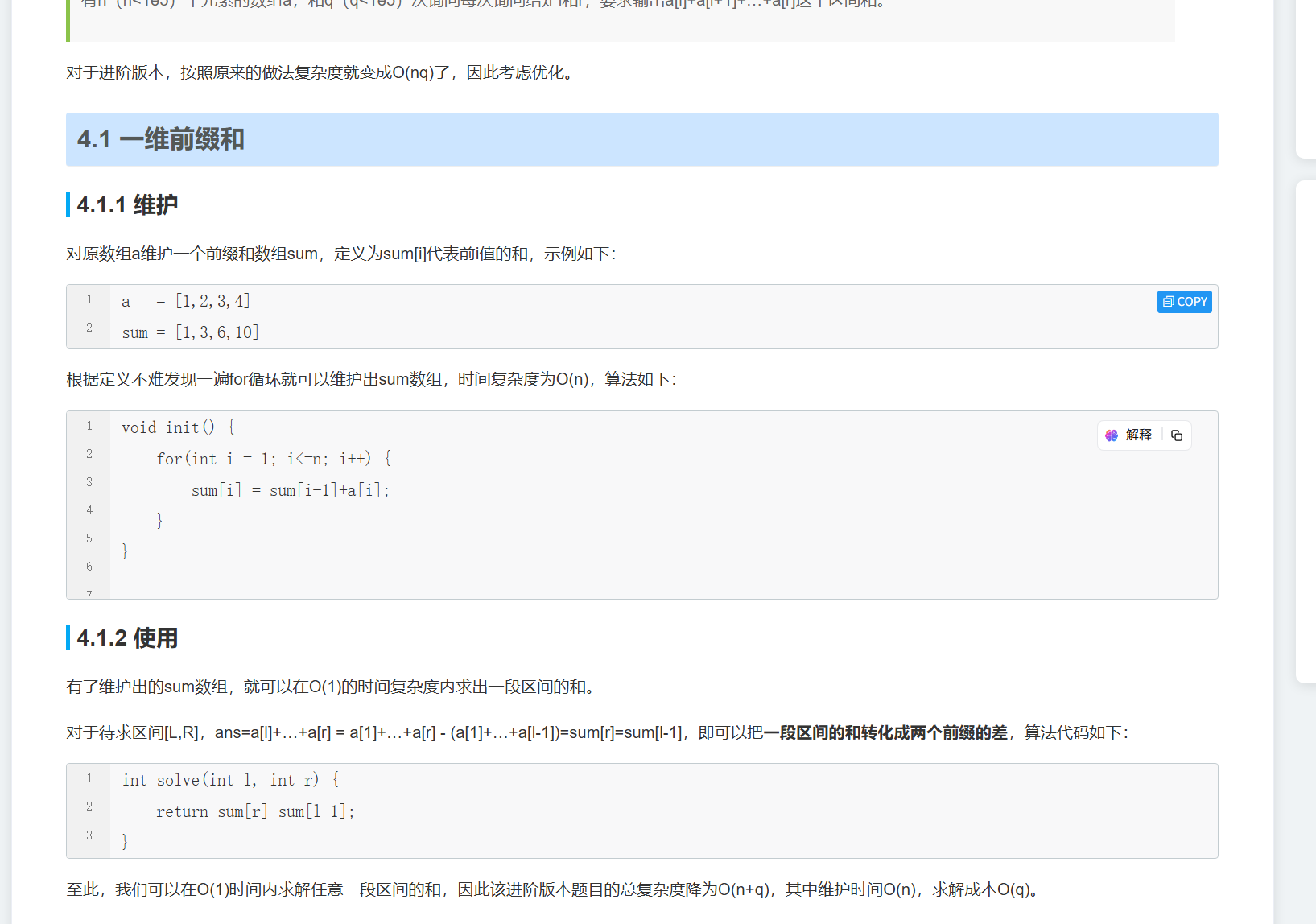
基本位运算有 6 种:按位与、按位或、按位异或、按位取反(不常考)、左移和右移,下面将首先介绍5种常考的运算的定义,接着介绍有助于我们做题的相关性质与一些结论:
知识点题单-位运算
常考位运算的定义
- 与、或、异或运算
- 这三种运算都是两数间运算,将两个整数作为二进制数,对每一位逐一运算。
- 与运算(
&):对应位都为 1 时结果为 1,如3 & 5 = 1(011 & 101 = 001)。 - 或运算(
|):对应位有一个为 1 时结果为 1,如3 | 5 = 7(011 | 101 = 111)。 - 异或运算(
^):对应位不同时结果为 1,如3 ^ 5 = 6(011 ^ 101 = 110),异或运算的逆运算是它本身,即a ^ b ^ b = a。
- 左移和右移运算
num << i表示将num的二进制表示向左移动i位,右侧补 0。如1 << 2 = 4(0001左移 2 位变为0100)。num >> i表示将num的二进制表示向右移动i位,正数左侧补 0,负数左侧补 1(符号位不变)。如4 >> 1 = 2(0100右移 1 位变为0010)。- 移位运算中,右操作数为负值或大于等于左操作数的位数时,行为未定义,如
int类型变量a,a << -1和a << 32都是未定义的。
知识点题单-滑动窗口
算法步骤
- 初始化:将窗口的起点设置为数组的第一个元素,然后根据具体问题来初始化窗口。(如果题目是定长窗口的题型,比如给定是长度为k的窗口,那直接取1,k作为初始窗口即可)
- 枚举右指针:对于每一次枚举,让右指针右移一次,同时维护对应信息(比如窗口和)。
- 调整左指针:在初始窗口的基础上,每次右指针右移一次,此时一旦窗口满足条件,就不断右移窗口的左指针,同时维护对应信息(比如窗口和),直到窗口内的元素不再满足题目条件。(对于定长窗口题型,左指针一定只右移一次)
- 重复第2步和第3步,直到窗口的右指针超过数组的最后一个元素,统计结果。
算法复杂度证明
由于该算法的左右指针都只会右移,因此从1不断右移移动到n,最多移动2n次,且每次指针移动,都保证对于维护的信息是O(1)更新,因此总复杂度是O(n)。
题型分类
从滑动窗口的类型上区分,主要有定长窗口和不定长窗口两种,二者的区别主要在于:
- 对于定长窗口,随着右指针右移一次,左指针一定只右移一次;
- 对于不定长窗口,随着右指针右移一次,左指针可能右移多次,需要在满足题意的情况下尽可能的右移;
下面分别举例并且给出模板。
定长窗口场景举例
考虑这样一个题目背景,给定一个整数数组 nums 和一个整数 k,找到一个连续的子数组,其长度为 k,并且其平均值最大。输出最大平均值。(k<len(nums)<1e5)
输入
6 4
1 12 -5 -6 50 3
输出
12.75
解释: 最大平均值的子数组是 [12, -5, -6, 50],平均值为 12.75。3. 无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。注意 "bca" 和 "cab" 也是正确答案。示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
cpp
class Solution {
public:
int lengthOfLongestSubstring(string s) {
vector<int> S(128, -1);
int l =0;
int r = 0;
int Max = 0;
while (r < s.size())
{
if(S[s[r]] >= l)
l = S[s[r]] + 1;
S[s[r]] = r;
Max = max(Max , r - l + 1);
r++;
}
return Max;
}
};注意边界问题

438 找到字符串中所有字母异位词
给定两个字符串 s 和 p,找到 s中所有 p的 异位词的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
示例 1:
输入: s = "cbaebabacd", p = "abc"
输出: [0,6]
解释:
起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。示例 2:
输入: s = "abab", p = "ab"
输出: [0,1,2]
解释:
起始索引等于 0 的子串是 "ab", 它是 "ab" 的异位词。
起始索引等于 1 的子串是 "ba", 它是 "ab" 的异位词。
起始索引等于 2 的子串是 "ab", 它是 "ab" 的异位词
cpp
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
if (s.size() < p.size()) return {};
vector<int> need(26, 0), have(26, 0);
for (char c : p) need[c - 'a']++;
vector<int> v;
int l = 0;
for(int i = 0; i< p.size(); i++)
{
char c = s[i];
have[c - 'a']++;
}
for(int r = p.size() ; r <= s.size(); r++)
{
if(need == have)
v.push_back(l);
if(r != s.size())
have[s[r] - 'a']++;
have[s[l] - 'a']--;
l++;
}
return v;
}
};刚开始想使用sort排序,后面感觉不太合适,主要能想到使用数组-a这种就行
知识点题单-二分
二分查找
二分查找,其实就是把查找区间长度从n不断收敛到1的过程,每次区间长度都会收敛一半。
以在一个升序数组a中查找一个数tar为例。每次考察待查找区间的中间元素amid,如果amid<tar,那么只需到右侧进一步查找;如果amid>tar,那么只需到左侧进一步查找,如果amid=tar,那么根据题意决定是要结束还是进一步收敛区间。
下面分别以"查得到"和"查不到"举具体的例子:
查得到
a=1,2,3,4,5,tar=2
经过三轮,L和mid和R聚合到一起,此时已经判断得出是否查找成功。
查不到
a=1,3,4,5,6,tar=2
在找不到的例子中,可以发现出现了R<L的情况,这肯定是不合理的,因此数组中找不到tar,二分查找的结束条件也就是L<=R
时间复杂度
由于每次查找,都会使得查找区间缩减为原来的一半,即如果查找区间为1024,只需要10次查找即可得到结果。
即不论查找是否成功,该算法的查找次数一定是O(logn)级别,因此时间复杂度为O(logn)。
模板
关于二分查找的模板有很多种,多为区分不同情况来使用不同的模板,个人感觉很容易用错。这里只推荐下面这一种,只有这一套模板,完全不需要担心用错或者记错,相关细节都标注在算法代码中。
cpp
int search(int tar) {
int l=0, r=n - 1, mid, ans = -1;//四个固定变量,其中ans先赋值为非法值
while(l<=r) {// 模板内固定写法,不需要变
mid = (l+r)/2;// 模板内固定写法,不需要变
if(a[mid] == tar) ans = mid;// 找到答案后更新答案,根据具体题目决定是return,还是更改L或R后继续查找
else if(a[mid] < tar) L = mid+1;// 在L=mid+1或R=mid-1中根据题意选一个,并根据题目自行决定是否需要记录ans
else R = mid-1;// 在L=mid+1或R=mid-1中根据题意选一个,并根据题目自行决定是否需要记录ans
}
return ans;
}35. 搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
示例 1:
输入: nums = [1,3,5,6], target = 5
输出: 2示例 2:
输入: nums = [1,3,5,6], target = 2
输出: 1示例 3:
输入: nums = [1,3,5,6], target = 7
输出: 4
cpp
class Solution {
public:
int searchInsert(vector<int>& nums, int target) {
int l = 0;
int r = nums.size() - 1;
int mid = 0;
while(r >= l)
{
mid = (l + r) / 2;
if(nums[mid] == target)
return mid;
else if(nums[mid] > target)
r = mid - 1;
else
l = mid + 1;
}
if(nums[mid] > target)
return mid;
else
return mid + 1;
}
};标准二分查找,注意numsmid > target的时候不是mid-1
74. 搜索二维矩阵
给你一个满足下述两条属性的 m x n 整数矩阵:
- 每行中的整数从左到右按非严格递增顺序排列。
- 每行的第一个整数大于前一行的最后一个整数。
给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则,返回 false 。
示例 1:
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3
输出:true
cpp
class Solution {
public:
bool searchMatrix(vector<vector<int>>& matrix, int target) {
int l = 0;
int mid,a,b;
int n = matrix[0].size();
int r = n * matrix.size() - 1;
while(r >= l)
{
mid = (r + l) / 2;
a = (mid) / n;
b = (mid) % n;
if(matrix[a][b] == target)
return true;
else if(matrix[a][b] > target)
r = mid - 1;
else
l = mid + 1;
}
return false;
}
};除和取余要使用列而不是行
34. 在排序数组中查找元素的第一个和最后一个位置
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]示例 2:
输入:nums = [5,7,7,8,8,10], target = 6
输出:[-1,-1]示例 3:
输入:nums = [], target = 0
输出:[-1,-1]
cpp
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
int l = 0;
int r = nums.size() - 1;
int mid;
int first = -1;
int end = -1;
while(l <= r)
{
mid = (l + r) / 2;
if(nums[mid] == target)
{
first = mid;
r = mid - 1;
}
else if(nums[mid] > target)
r = mid - 1;
else
l = mid + 1;
}
l = 0;
r = nums.size() - 1;
while(l <= r)
{
mid = (l + r) / 2;
if(nums[mid] == target)
{
end = mid;
l = mid + 1;
}
else if(nums[mid] > target)
r = mid - 1;
else
l = mid + 1;
}
int v[] = {first, end};
return {v[0], v[1]};
}
};这道题很夸张,想了会都没思路,最后还是看题解,两次二分,一次找首一次找尾,我看还有找到一个tar然后再扩写的
33. 搜索旋转排序数组
整数数组 nums 按升序排列,数组中的值 互不相同 。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 向左旋转 ,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 下标 3 上向左旋转后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [4,5,6,7,0,1,2], target = 0
输出:4
cpp
class Solution {
public:
int search(vector<int>& nums, int target) {
int l = 0;
int r = nums.size() - 1;
int mid;
while (l <= r) {
mid = l + (r - l) / 2;
if (nums[mid] == target) return mid;
if (nums[l] <= nums[mid]) {
if (nums[l] <= target && target < nums[mid]) {
r = mid - 1;
} else {
l = mid + 1;
}
} else {
if (nums[mid] < target && target <= nums[r]) {
l = mid + 1;
} else {
r = mid - 1;
}
}
}
return -1;
}
};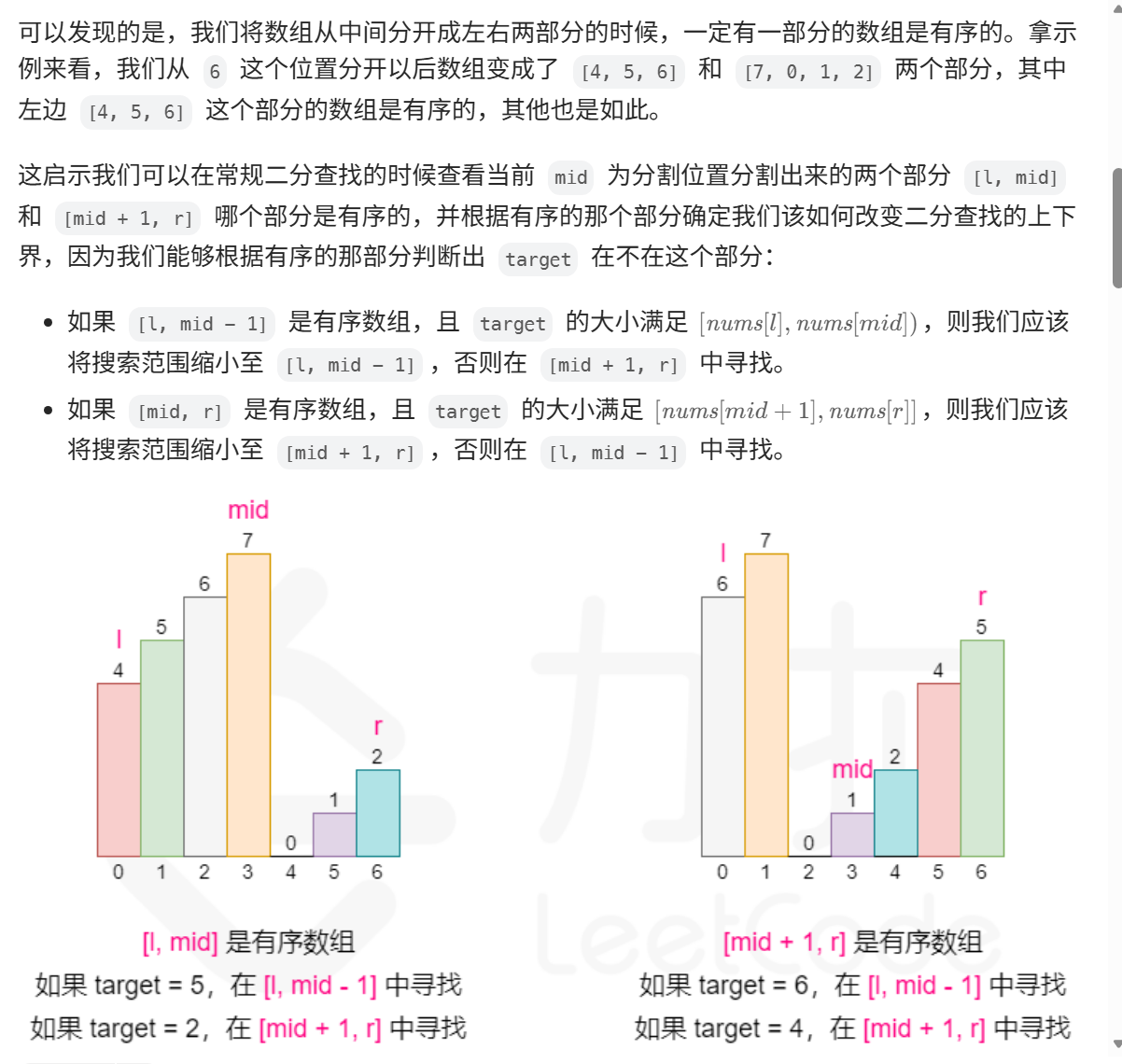
开始寻找mid左右两边那边合法(必有一边是按顺序排的),然后从合法的那边裁剪
153. 寻找旋转排序数组中的最小值
已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums = [0,1,2,4,5,6,7] 在变化后可能得到:
- 若旋转
4次,则可以得到[4,5,6,7,0,1,2] - 若旋转
7次,则可以得到[0,1,2,4,5,6,7]
注意,数组 [a[0], a[1], a[2], ..., a[n-1]] 旋转一次 的结果为数组 [a[n-1], a[0], a[1], a[2], ..., a[n-2]] 。
给你一个元素值 互不相同 的数组 nums ,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [3,4,5,1,2]
输出:1
解释:原数组为 [1,2,3,4,5] ,旋转 3 次得到输入数组。
cpp
class Solution {
public:
int findMin(vector<int>& nums) {
int low = 0, high = nums.size() - 1;
int x = nums[high];
while (low < high) { // 注意这里没有=了,=的时候直接退出循环得到答案
int mid = (low + high) / 2;
if (nums[mid] < x)
high = mid; //这里不是常规的 mid-1 是因为此时的mid有可能就是我们要找的m
else
low = mid + 1; //这里和常规一样是 mid+1 是因为此时的mid不可能是m
}
return nums[low];
}
};更具旋转方式可以看出找到关键最右端数字,因为只要比他大或小就能锁定mid到底在哪,再最小值之左还是右,最后调整mid范围,给出最小值
知识点题单-差分
三、应用场景
差分十分适合多次区间操作,然后单点查询的场景。
又是也会结合前缀和,进行区间操作+离线区间查询的场景



知识点题单-前缀和
应用场景
- 需要高效的区间查询场景(包括区间和,区间乘积,区间异或等)
- 需要前缀、后缀等维护的情况