文章目录
-
- [一、 全景对比:十维度速查表](#一、 全景对比:十维度速查表)
- [二、 核心思想与操作维度解析](#二、 核心思想与操作维度解析)
- [三、 实战选择决策树](#三、 实战选择决策树)
- 结论与精髓
归一化是机器学习和深度学习中最基础、最实用,却也最让人困惑的技术之一。从简单的数据缩放,到 Transformer 模型的核心组件,不同的归一化方法在算法本质、适用场景和实战效果上存在显著差异。本文将通过一张全景对比表和十大核心维度,为你彻底厘清七种主流归一化方法的脉络,并提供可立即上手的决策地图。
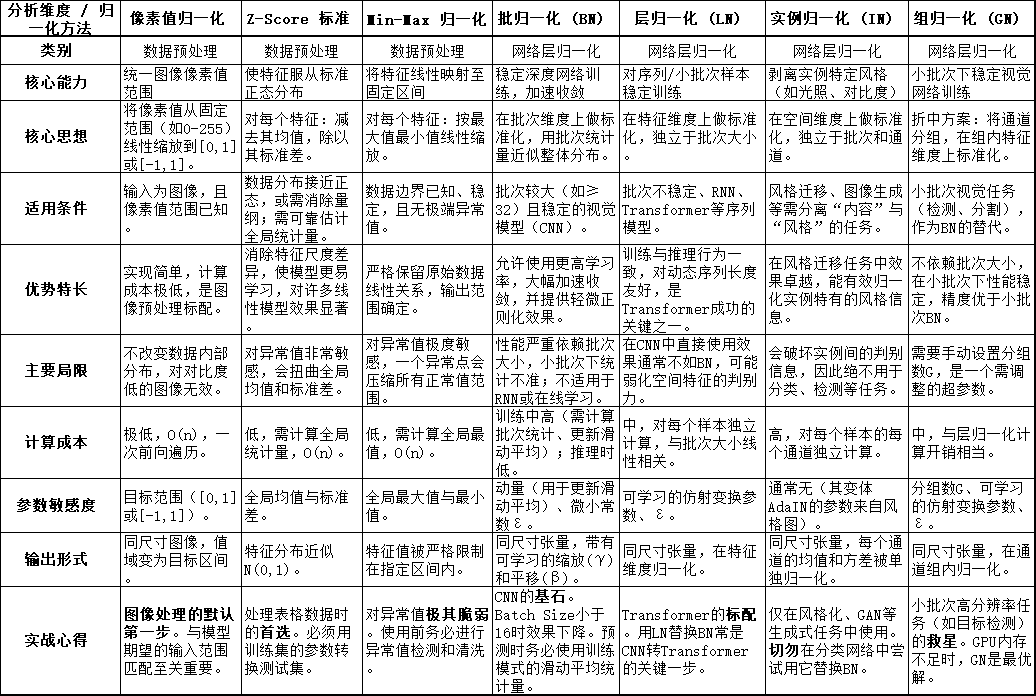
一、 全景对比:十维度速查表
下表从十个关键维度,对七种主流方法进行了系统性对比,是本文的核心导航图。
二、 核心思想与操作维度解析
理解不同归一化方法最本质的视角,是观察其在张量的哪个(些)维度上进行标准化 。对于一个形状为 [N, C, H, W] 的 4D 张量(分别代表:批次、通道、高、宽):
- **批归一化 (BN)**:在 N 维度上计算统计量。它聚合了一个批次内所有样本的同一特征图。
- **层归一化 (LN)**:在 C, H, W 维度上计算统计量。它聚合了单个样本的所有特征。
- **实例归一化 (IN)**:在 H, W 维度上计算统计量。它聚合了单个样本、单个通道的空间位置。
- **组归一化 (GN)**:在 (部分 C), H, W 维度上计算统计量。它将通道分组,在组内进行聚合。
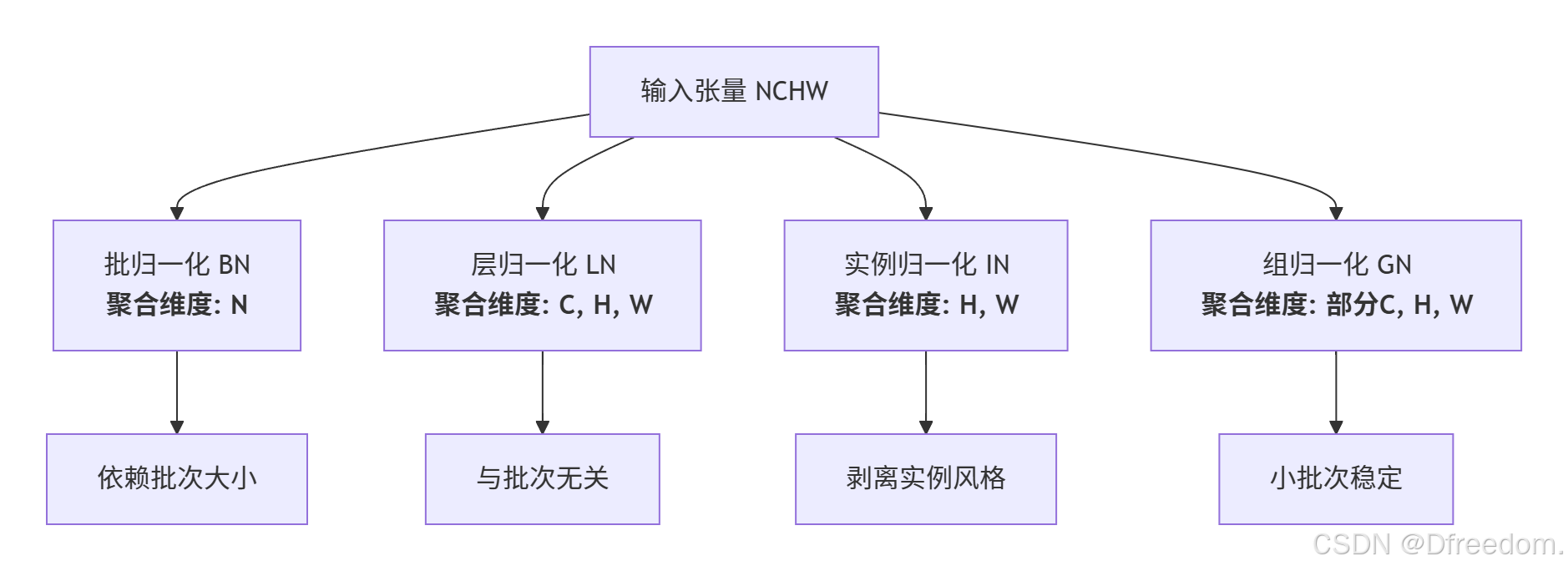
(像素值、Z-Score、Min-Max 为数据预处理方法,不涉及此张量维度操作。)
三、 实战选择决策树
面对具体任务,遵循以下决策路径,可以快速锁定最适合的归一化方法。
开始 → 任务阶段是什么?
├─ 数据预处理阶段
│ └─ 数据形态与需求是?
│ ├─ 图像数据 → **像素值归一化**
│ └─ 表格/向量数据
│ └─ 数据分布与特征是?
│ ├─ 分布近似正态/需标准化 → **Z-Score标准化**
│ └─ 边界清晰/需固定范围 → **Min-Max归一化**
└─ 网络训练阶段(层归一化)
└─ 模型架构与场景是?
├─ CNN等视觉网络
│ └─ 训练批次大小如何?
│ ├─ 批次大且稳定(如>=32) → **批归一化 (BN)**
│ └─ 批次小或变化(如<16) → **组归一化 (GN)**
├─ RNN/Transformer等序列模型 → **层归一化 (LN)**
└─ 风格迁移/图像生成任务 → **实例归一化 (IN/AdaIN)**结论与精髓
选择正确的归一化方法,不是死记硬背公式,而是理解其操作维度的物理意义:
- 在批次(N) 上归一化(BN),意味着相信"同一批次的数据是整体分布的抽样"。这在大批次下有效,是 CNN 的假设。
- 在特征(C,H,W) 上归一化(LN),意味着"每个样本自身就应该被标准化"。这与批次无关,是序列模型的假设。
- 在空间(H,W) 上归一化(IN),意味着"每个样本、每个通道的风格信息应被单独移除"。这是艺术创作的假设。
记住以下黄金法则:
- 数据预处理:图像用像素归一化,表格数据用 Z-Score(首选)或 Min-Max。
- 网络层:大 Batch CNN 用 BN;小 Batch 视觉任务用 GN;所有序列模型(Transformer, RNN)用 LN;风格迁移用 IN。