Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights 这篇论文的研究背景非常有趣,它直接挑战了深度学习领域中一个根深蒂固的"常识",并针对目前大语言模型(LLM)极其热门的后训练(Post-training)阶段提出了全新的思考。
具体来说,论文的研究背景可以归结为以下四个方面:
1. 传统认知:高维空间优化是"大海捞针",随机猜测不可行
在机器学习中,寻找一个表现优异的模型权重,长期以来被认为是在高维参数空间里"大海捞针"(Needle in a haystack)。
正如深度学习先驱 Schmidhuber 在 2001 年所断言的:"随机猜测不能被视为一种合理的学习算法"。想象一下,如果要从零开始随机猜出一个拥有几十亿参数的大模型(比如 ChatGPT)的权重,其成功概率在数学上几乎为零。因此,整个深度学习界都极其依赖梯度下降(Gradient Descent)等结构化的、需要多步迭代优化的算法来一步步寻找最优解。
2. 现有后训练(Post-training)方法的成本与局限
当前大语言模型(LLMs)的训练范式是:先进行海量数据的预训练(Pretraining)得到基座模型,然后通过后训练(如SFT、RLHF)来激发其推理、编程等特定能力。目前最主流的后训练方法包括 PPO、DPO 以及最近很火的 GRPO 和进化策略(ES)。然而这些方法存在明显的痛点:
- 计算与时间成本高 :需要成百上千步的串行迭代更新(时间复杂度为 O(T)\mathcal{O}(T)O(T))。
- 系统复杂度高:比如 PPO 需要同时维护 Policy 模型、Reference 模型、Critic 模型和 Reward 模型,内存占用极大,且超参数极难调(容易训崩)。
3. 大模型时代的新现象:损失景观(Loss Landscape)到底变成了什么样?
随着模型参数规模的不断扩大,研究人员开始好奇:经过了如此庞大且多样化的数据预训练后,基座模型权重周围的"地形(损失景观)"究竟发生了什么根本性的变化?
既然模型已经"见多识广",那么为了让它精通某一项特定任务(比如解数学题),我们还需要像以前那样用梯度下降辛辛苦苦地跋涉很远吗?那些能解决特定任务的"好权重",到底是非常罕见,还是其实就埋伏在初始权重的附近?
4. 视角的转变:预训练模型不是一个"点",而是一个"分布"
传统观念里,预训练产生的是一个单一的参数向量(把预训练权重当成进一步微调的起点)。
但这篇论文的作者提出了一种全新的视角:我们应该把预训练的结果看作是一个"分布"(Distribution)。他们想探究:如果我们放弃复杂的梯度计算,仅仅在这个预训练权重附近"随机瞎猜"(加入微小的随机高斯噪声),能不能直接撞上好模型?
总结来说 作者怀疑,随着大语言模型规模的增长,预训练已经把模型带到了一个极其富饶的"风水宝地"。在这里,传统观念中"大海捞针"的困境已经不存在了。为了验证这个猜想,他们决定用最原始、最被学术界鄙视的随机盲猜 方法来试探大模型周围的权重空间,从而引出了这篇论文的核心发现------神经灌木丛(Neural Thickets)现象(即在预训练权重周围,密集地生长着各种各样的"任务专家")。
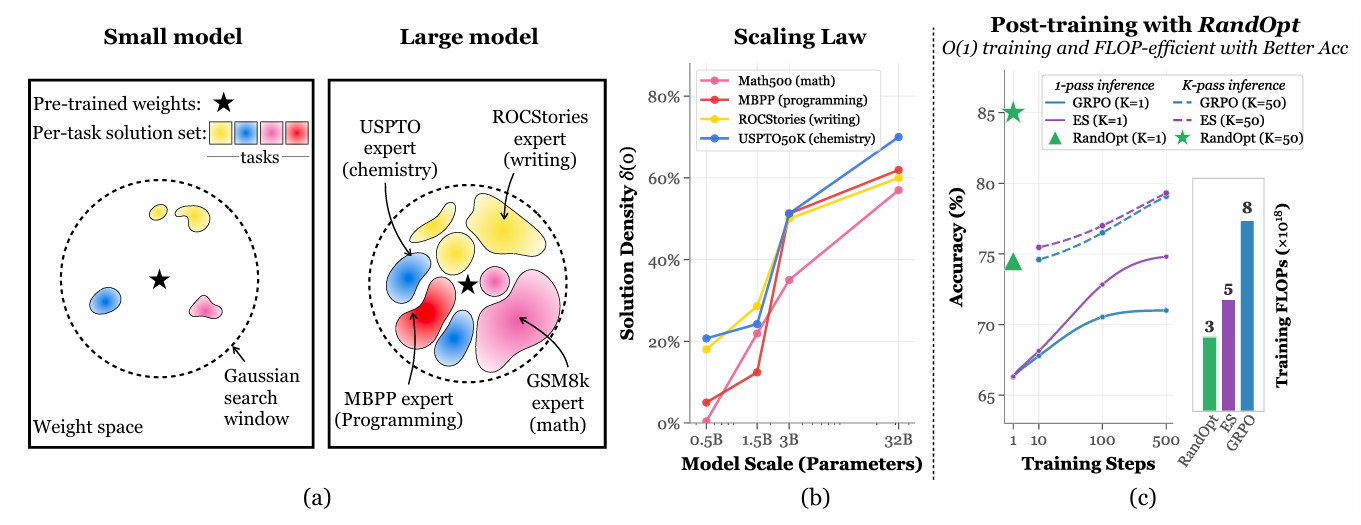
小模型(左)的大海捞针机制与大模型(右)的神经丛林机制示意图。大模型周围充满了代码专家、数学专家等特定任务的解决方案集。
下面总结了 RandOpt(Random Guessing & Ensembling)算法的核心思想和具体做法。
简单来说,RandOpt 的做法是暴力盲猜 + 优中选优 + 投票集成。它完全抛弃了传统的梯度下降(Gradient Descent)或强化学习(RL)微调,直接在预训练模型的权重周围随机撒网,然后把表现最好的几个模型组合起来使用。
RandOpt 的具体实施分为两个阶段:
阶段一:训练阶段(随机猜测与验证 / Random Guessing and Checking)
在这个阶段,模型不进行任何反向传播计算(No Backpropagation),纯粹依靠前向推理。
- 确定基座与噪声尺度:
以一个已经训练好的大模型权重 θ\thetaθ 为起点。定义一组噪声缩放因子集合 Σ={σ1,...,σM}\Sigma = \{\sigma_1, \dots, \sigma_M\}Σ={σ1,...,σM}。 - 随机生成 NNN 个变体模型:
通过设置 NNN 个不同的随机种子,生成 NNN 个标准高斯噪声向量 ϵ\epsilonϵ。然后按照公式 θi′=θ+σi⋅ϵ(si)\theta'_i = \theta + \sigma_i \cdot \epsilon(s_i)θi′=θ+σi⋅ϵ(si),在原始权重上直接加上这些微小的随机噪声,从而瞬间"变"出 NNN 个稍微有些不同的参数模型。 - 在训练集上打分(Check):
把这 NNN 个变体模型放在一个较小的训练集或验证集上(例如几百道数学题)进行评估,得到每个模型的准确率得分 viv_ivi。由于不需要梯度更新,这 NNN 个模型的评估可以完全并行进行。 - 筛选 Top-KKK:
根据得分,从这 NNN 个盲猜的模型中,选出表现最好的前 KKK 个模型保留下来(集合记为 Itop\mathcal{I}_{top}Itop),淘汰掉剩下的。
阶段二:推理阶段(模型集成 / Ensembling)
在面对新的测试数据 xxx 时,RandOpt 不依赖单一模型,而是让选出的 KKK 个"专家"共同决策。
- 并行推理:
让选出来的这 KKK 个最优模型分别对测试输入 xxx 生成预测答案。 - 多数投票(Majority Vote):
收集这 KKK 个模型的答案,采用"少数服从多数"的原则(Majority Voting),将出现次数最多的答案作为最终的输出 y^\hat{y}y^。
RandOpt 的衍生做法:蒸馏(Distillation)
作者也意识到,推理阶段要跑 KKK 个模型成本太高了。为了解决这个问题,他们提出了一个附加步骤:
- 用选出的 Top-KKK 模型在训练集上生成大量的推理轨迹和高质量答案。
- 过滤掉错误的答案,只保留难样本(hard samples)的正确回答。
- 用这些高质量的数据,对基础模型进行监督微调(SFT) ,将其浓缩(Distill)回一个单一模型中。
论文证明,这样做可以在推理时只用1个模型,且性能与包含 KKK 个模型的 RandOpt 集合相当。
为什么 RandOpt 会有效?(核心发现)
作者发现,经过充分预训练的大模型,其权重空间进入了一个名为 "Thicket(灌木丛)" 的状态。这意味着:
- 密度高: 在原始权重附近,密密麻麻地分布着大量能提升特定任务性能的"好权重"。
- 多样性强: 这些随机撞上的"好权重"往往是"偏科专家",有的擅长数学,有的擅长写代码,它们的能力是互补的。
总结:
RandOpt 的做法就是利用了大模型周围"好答案到处都是"的特性,用极高并发的随机扰动( NNN 次)去撞大运,找出不同领域的专家(Top-KKK),最后通过集成投票来互补长短。它的计算时间是 O(1)\mathcal{O}(1)O(1)(极短的挂钟时间),但在效果上却能与需要迭代成百上千步的 PPO、GRPO 等复杂强化学习微调算法相媲美。