HPA 在 K8s 里是怎么实现自动扩缩容的?
很多人第一次配 HPA(Horizontal Pod Autoscaler)的时候,心里想的都是同一句话:"流量大了自动加 Pod,流量小了自动减 Pod,这不就完美了吗?"
思路没错,但 HPA 并不是"看见忙了就扩、看见闲了就缩"这么简单。它背后其实是一条完整的链路:指标从哪来、谁来算、算完改谁、改完谁去真的拉起 Pod。把这条链路捋顺,你就知道 HPA 为什么有时反应慢、为什么会抖、为什么看着配对了却不扩。
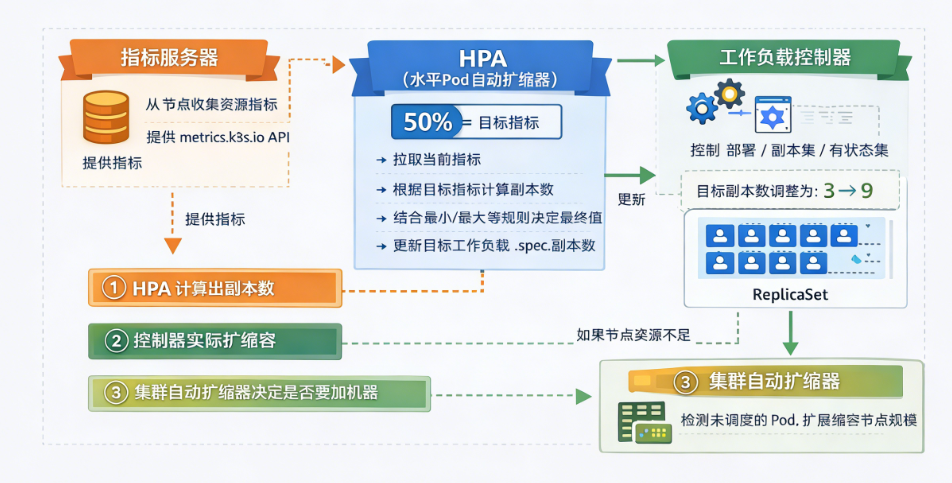
先讲清一件事:HPA 自己不会创建 Pod,它只会"改副本数"
这是很多人最容易误会的点。HPA 的工作更像"调度员",它做的是:
根据指标算出应该要几个副本,然后去修改 Deployment/StatefulSet 的 replicas。
真正负责创建/删除 Pod 的,是 Deployment、ReplicaSet、StatefulSet 这些控制器。
所以别把锅甩错人:你看到 Pod 没起来,有可能根本不是 HPA 的问题,而是调度、资源、镜像拉取等后续环节卡住了。
指标从哪里来?没有"温度计",HPA 怎么做决定?
HPA 扩不扩容,首先得有指标。常见的指标来源大体分两类:
资源类指标(最常用)
比如 CPU、内存。这类指标通常由 Metrics Server 提供:它去各节点采集 Pod 的资源使用情况,再以 metrics.k8s.io 的形式暴露给集群。
所以你遇到过那种情况吗:HPA 配了,但一直提示拿不到 metrics?大概率就是 Metrics Server 没装、没起来、或者权限/网络有问题。
自定义指标(更贴近业务)
比如 QPS、请求延迟、队列长度。这类一般要靠 Prometheus + Adapter(例如 Prometheus Adapter)把监控指标"翻译"成 HPA 可读的 API。
毕竟 CPU 高不高,有时候并不代表你真的扛不住;反过来请求延迟上来了,CPU 可能还挺低。你说该信哪个?这就是为什么很多生产环境更喜欢用业务指标。
谁在算?HPA Controller 才是"做决定的人"
在控制平面里,有一个专门的控制器负责 HPA(通常叫 HPA controller)。它会周期性做同一件事:
-
读 HPA 配置:目标是什么、指标用哪个、上下限是多少
-
取当前指标:从 Metrics API 或自定义指标 API 拉数据
-
计算"推荐副本数"
-
做一层限制:不能低于 minReplicas,不能超过 maxReplicas
-
把结果写回目标工作负载(比如 Deployment)的
spec.replicas
你可以把它理解成:它不是执行者,它是"算完告诉别人该扩到多少"的那个人。
它怎么算"该扩到多少"?核心公式其实很直白
最常见的是 CPU 利用率,例如"平均 CPU 使用率保持在 50%"。
HPA 的思路就是按比例去算:
期望副本数 = 当前副本数 ×(当前指标 ÷ 目标指标)
举个特别直观的例子:
现在有 4 个 Pod,平均 CPU 已经到 100%,目标是 50%。
那就意味着现有副本数不够,需要翻倍:
4 × (100% / 50%) = 8
HPA 会把副本数调到 8。
如果反过来,平均只有 25%,目标是 50%:
4 × (25% / 50%) = 2
它会建议缩到 2(当然前提是不会低于 minReplicas)。
看起来是不是挺"数学题"?没错,HPA 本质就是一个定期做数学题的控制器。
为什么 HPA 有时候反应慢?它不是笨,是在避免"抖动"
很多人期待 HPA 像汽车油门一样灵敏:流量一上来马上扩,流量一下去马上缩。可现实是:太灵敏反而容易抖。
HPA 之所以看起来"慢半拍",通常有几类原因:
-
指标采集有延迟:Metrics Server/监控系统不是毫秒级实时,采集和上报都需要时间。
-
HPA 本身按周期计算:它不是每个请求都算一次,而是隔一段时间算一次。
-
缩容更保守:扩容慢可能挂业务,缩容慢最多浪费点资源,所以默认策略往往对缩容更谨慎。
你可以这样理解:
HPA 允许扩容更积极,但通常会让缩容更稳一点,不然流量波动时一直扩缩,Pod 还没热起来就被缩掉,那不是更糟?
Pod 扩出来了但跑不起来?别忘了还有"节点够不够"的问题
还有一种常见现象:HPA 把 replicas 调大了,但新增 Pod 一直 Pending。
这时候 HPA 已经尽责了,它已经"下命令"了,问题出在:集群没资源接住新增 Pod。
这就引出另一个经常被混淆的概念:
-
HPA:扩的是 Pod 数量
-
Cluster Autoscaler(CA):扩的是节点数量
流程一般是这样的:
HPA 扩 Pod → 资源不够导致 Pending → CA 发现调度不上 → 扩节点 → Pod 才真正跑起来。
所以生产里常常是 HPA + CA 配合使用,一个管"要多少 Pod",一个管"要不要加机器"。
总结:HPA 的自动扩缩容机制,用一句话就能记住
HPA = 指标驱动的副本数调节器:
它定期读取指标 → 算出目标副本数 → 修改工作负载 replicas → 由工作负载控制器真正创建/删除 Pod。
指标来自 Metrics Server 或自定义指标系统;为避免抖动它会有周期和策略;节点不够时需要 CA 来补机器。
说到底,HPA 不是魔法,它只是在帮你把"凭经验扩缩容"这件事变成"按指标算出来"。你把指标链路和计算逻辑想明白,它的每一次扩缩行为其实都很合理。