文章目录
- [1. 作业概要](#1. 作业概要)
- [2. 准备阶段](#2. 准备阶段)
- [3. 数据收集](#3. 数据收集)
- [4. 数据预处理](#4. 数据预处理)
- [5. 模型训练](#5. 模型训练)
- [6. 模型评估](#6. 模型评估)
- [7. 改进模型](#7. 改进模型)
- [8. 更多优化策略](#8. 更多优化策略)
- [9. 结果对比](#9. 结果对比)
- [10. 最终结论](#10. 最终结论)
1. 作业概要
本次作业分为两个部分,第一部分是知识点讲解,让我们解释有关卷积神经网络的卷积核和损失函数。这些都是直接的概念解释,因此这里并不过多解释。可以参考这门课的相关知识,其中对第一个知识点说的很清楚。INT305卷积神经网络知识点。后一个知识点在INT301上比较清晰。INT301卷积神经网络知识点。
第二部分是要求我们使用卷积神经网络训练CIFAR-10数据集以进行图像识别。这个问题其实网上也会有很多相关的教程,这里老师也给出了一个可以使用的框架,用一个非常简单的CNN进行了一个训练并进行了简单的评估。我们需要做的主要是首先成功展现整个过程,然后开始进行评估,我们还需要使用自己的方法提升我们模型的分类能力或者是减少模型的大小,这些都可以从之前模型评估的结果得到启发,例如我们可以展示一些正确分类的结果和错误分类的结果从而得出一些思路。我们还可以比较不同方法得出的结果并尝试分析。最后我们可以尝试讨论一些整个过程中所得到的启发。
所以整体上来说这个作业的难度不是很大,因为我们已经对CNN很熟悉了,而且这里给出了框架,我们现在要做的更多就是优化就行。
下面我将解释对于这个第二部分我是怎么做的,我会详细讲述我每一步是怎么做的并附带对应的代码。
2. 准备阶段
为了进行CNN,我们需要安装 Pytorch,这是CNN所必需的库,为了方便我们选择先安装 Anaconda,这样我们可以预先装好一些其他必要的环境,并且我们的 Pytorch 安装也可以通过 Anaconda 来进行下载安装。
CPU 版 Pytorch 安装(包含 Anaconda 安装教学)
GPU 版 Pytorch 安装(包含 Anaconda 安装教学)
我使用的环境装了以下的库。
我这里的库仅供参考,没必要完全和我一致。主要要使用Pytorch、numpy、patplotlib、sklearn、seaborn这样的库就行了。
虽然前面的Pytorch教学我们介绍了如何检验安装Pytorch,但是这个地方我们还是可以测试一下,我们现在可以创建一个python文件尝试下列命令。
python
import torch
print(torch.cuda.is_available())如果结果为True,则证明可以使用CUDA加速的Pytorch,也就是GPU版的Pytorch。如果你先安装的CPU版,后安装的GPU版,你可以尝试重启核心等方式,否则你的CUDA可能依旧无法正常工作。如果结果连False都不是,那可能安装出现了更严重的问题。都可以尝试重新按照上面的教程进行安装从而尝试解决。
我的相关电脑配置如下,CPU 是 i7-14700KF,GPU 是 RTX4070 Ti SUPER,对于下列的代码大部分不到10分钟就能完成(使用GPU版CUDA加速的Pytorch),使用CUDA加速的Pytorch能让我们高效地完成类似的工作。
3. 数据收集
我们开展的流程依然是正常的机器学习的流程。我们由于现在是对一个公开的数据库CIFAR-10进行训练。所以我们不需要专门进行数据收集,只需要进行下载后就能立即使用了。
我们可以单独创建一个download文件专门先下载好,后面运行这些命令就不用专门再下载了(这里它会识别是否已下载,如果下载好了,其不会单独再进行额外下载),而且这样操作我们也能避免我们如果一起运行多个模块的命令,没有成功下载而导致的bug就可以被排除了。
python
from torchvision import datasets, transforms
# 指定保存目录(可任意改)
datasets.CIFAR10(root='./data', # 会生成 ./data/cifar-10-python.tar.gz
train=True, # 下训练集
download=True, # 关键:True 就自动下载
transform=transforms.ToTensor())
datasets.CIFAR10(root='./data',
train=False, # 下测试集
download=True,
transform=transforms.ToTensor())
print("CIFAR-10 下载并解压完成!")运行完毕后,下面终端会有CIFAR-10 下载并解压完成!的提示。当然我们也可以在这里项目文件夹下发现名为data的文件夹,其包含了我们下载的CIFAR-10数据集。
4. 数据预处理
一个优秀的机器学习结果需要我们对数据进行预处理。数据预处理中的标准化/归一化(Normalization)可以加速收敛、防止梯度爆炸、提高模型稳定性。我们还可以进行数据增强以减少过拟合、提升泛化能力。
这些在老师给出的示例代码中非常粗糙,但还是进行了这一步操作。
python
# 数据预处理
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])这里的预处理并不是对应数据真实的mean和std。
因此我们后续优化模型的第一个点就可以是正确的数据预处理。
对于这个操作网络上有很多的参考数据都是如下图所示。

我尝试了一下,它的计算过程如下面代码所示。
python
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 加载训练集(不进行归一化)
train_set = datasets.CIFAR10(root='./data', train=True, download=False,
transform=transforms.ToTensor())
train_loader = DataLoader(train_set, batch_size=64, shuffle=False, num_workers=2)
def compute_mean_std(loader):
mean = 0.0
std = 0.0
total_samples = 0
for images, _ in loader:
batch_samples = images.size(0) # 当前batch的样本数
images = images.view(batch_samples, images.size(1), -1) # 重塑为 [batch, channels, height*width]
mean += images.mean(2).sum(0) # 计算每个通道的空间均值,然后求和
std += images.std(2).sum(0) # 计算每个通道的空间标准差,然后求和
total_samples += batch_samples # 累计总样本数
mean /= total_samples # 计算平均均值
std /= total_samples # 计算平均标准差
return mean, std
if __name__ == '__main__':
mean, std = compute_mean_std(train_loader)
print(f"Mean: {mean}")
print(f"Std: {std}")但其实这里计算是错误的,因为std需要计算出mean才能计算,而这里一直在同时计算,这里std计算的mean不是真正的mean,而是局部mean,因此得出来的并非真正的std。
正确计算代码如下。
python
import torch
from torchvision import datasets, transforms
data_path = './data'
transform = transforms.Compose([
transforms.ToTensor()
])
train_dataset = datasets.CIFAR10(root=data_path, train=True, download=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=False)
mean = 0.0
std = 0.0
num_samples = 0
for images, _ in train_loader:
batch_samples = images.size(0)
images = images.view(batch_samples, images.size(1), -1)
mean += images.mean(2).sum(0)
num_samples += batch_samples
mean = mean / num_samples
for images, _ in train_loader:
batch_samples = images.size(0)
images = images.view(batch_samples, images.size(1), -1)
std += ((images - mean.unsqueeze(1)) ** 2).sum([0, 2])
std = torch.sqrt(std / (num_samples * images.size(2)))
print("Mean:", mean)
print("Std:", std)结果如下图所示。

因此正确的标准化需要使用的应该是这样的数据。
再加上我们刚刚说的数据增强,我们现在一个优秀的数据预处理可以如下所说。
python
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=(0.4914, 0.4822, 0.4465), std= (0.2470, 0.2435, 0.2616))
])5. 模型训练
我们现在先尝试原来模型的训练。
我这里建议将老师给出的代码像我们刚刚操作一样进行拆分,变成模块化的代码,我们将训练代码和后面评估阶段的代码分开来,会方便我们操作。
我们可以将训练得到的模型存储为多个结果,然后用相同的评估代码对这些结果分别进行评估。这样我们就不需要每次都跑一遍训练过程,因为训练过程所花费的时间是最多的。
我们神经网络的代码如下。
python
import torch.nn as nn
import torch.nn.functional as F
# define the CNN architecture
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 2 , padding=1, stride= 1) # (32 - 5+ 2(0) / 1) + 1 = 28
self.pool1 = nn.MaxPool2d(2, 2) # (28 - 2 + 2(0)/ 2) + 1 = 14
self.conv2 = nn.Conv2d(6, 16, 2, padding=1, stride= 1) # (14 - 5 + 2(0)/ 1) + 1 = 10
self.pool2 = nn.MaxPool2d(2, 2) # (10 - 2 + 2(0)/ 2) + 1 = 5
self.conv3 = nn.Conv2d(16, 32, 2)# (5 - 2 + 2(0)/ 1) + 1 = 4
self.pool3 = nn.MaxPool2d(2, 2)# (4 - 2 + 2(0)/ 2) + 1 = 2
self.fc1 = nn.Linear(32* 3**2, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# add sequence of convolutional and max pooling layers
x = self.pool1( F.relu(self.conv1(x)))
x= self.pool2( F.relu(self.conv2(x)))
x= self.pool3(F.relu(self.conv3(x)))
# Flatten it
x= torch.flatten(x, 1)
# x = x.view(x.size(0), -1)
x= F.relu(self.fc1(x))
x= F.relu(self.fc2(x))
x= self.fc3(x)
return x
# create a complete CNN
model = Net()
print(model)
# move tensors to GPU if CUDA is available
if train_on_gpu:
model.cuda()但其实这里的注释是有问题的,这里的卷积操作导致的规模变化计算是有问题的。
我这里以第一个卷积块为例。我们解释的时候可以说的清晰一点,不仅是这一步操作发生了什么,还要解释其的影响是什么。第一个卷积块采用2×2的核,单位步长和填充=1,将输入从32×32×3转换为33×33×6。这种有意的尺寸扩展增加了边缘特征的接受范围。随后的最大池化层(2×2核,步幅=2)将特征映射下采样到16×16×6,在保留显著特征的同时降低了空间维度。
我们的损失函数和优化器如下。
python
import torch.optim as optim
# specify loss function
criterion = nn.CrossEntropyLoss()
# specify optimizer
optimizer = optim.SGD(model.parameters(), lr= 0.0001, momentum= 0.9)具体训练过程如下。
python
# number of epochs to train the model
n_epochs = 35 # you may increase this number to train a final model
valid_loss_min = np.Inf # track change in validation loss
for epoch in range(1, n_epochs+1):
# keep track of training and validation loss
train_loss = 0.0
valid_loss = 0.0
###################
# train the model #
###################
model.train()
for data, target in train_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output, target)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# update training loss
train_loss += loss.item()*data.size(0)
######################
# validate the model #
######################
model.eval()
for data, target in valid_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output, target)
# update average validation loss
valid_loss += loss.item()*data.size(0)
# calculate average losses
train_loss = train_loss/len(train_loader.dataset)
valid_loss = valid_loss/len(valid_loader.dataset)
# print training/validation statistics
print('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(
epoch, train_loss, valid_loss))
# save model if validation loss has decreased
if valid_loss <= valid_loss_min:
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(
valid_loss_min,
valid_loss))
torch.save(model.state_dict(), 'model_cifar.pt')
valid_loss_min = valid_loss因此我们训练的代码应该是前面三个核心代码在一起,前面再添加数据导入和预处理,后面再为这个程序添加开始的入口。这里将Lab给出的代码稍微修改了一下就全部放了上来,具体代码如下。
python
import torch
import numpy as np
# check if CUDA is available
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:
print('CUDA is not available. Training on CPU ...')
else:
print('CUDA is available! Training on GPU ...')
from torchvision import datasets
from torchvision.transforms import transforms
from torch.utils.data.sampler import SubsetRandomSampler
number_of_workers = 0
batch_size= 20
valid_size= 0.2
# Converting Data into a Normalized Tensor format
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std= (0.5, 0.5, 0.5))
])
# Downloading training and testing Datasets
train_data= datasets.CIFAR10('data', train= True,
download= True, transform = transform)
test_data = datasets.CIFAR10('data', train = False,
download = True, transform= transform)
# Obtaining training Indices that we are going to use for Validation Set
num_train= len(train_data)
indices = list(range(num_train))
np.random.shuffle(indices)
split = int(np.floor(valid_size * num_train))
train_idx, valid_idx = indices[split:] , indices[:split]
# Defining samplers for training and validation Bathces
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
# Preparing Data Loader for all three sets (combining datasets and samplers)
train_loader = torch.utils.data.DataLoader(train_data, batch_size = batch_size ,
sampler= train_sampler , num_workers = number_of_workers)
valid_loader= torch.utils.data.DataLoader(train_data , batch_size= batch_size,
sampler = valid_sampler, num_workers = number_of_workers)
test_loader= torch.utils.data.DataLoader(test_data, batch_size= batch_size,
num_workers= number_of_workers)
# Spacify Image Classes
class_names =['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
# After preparing Data, we have to unnormalize it to visullize it.
# Lets create a helper function which will un-normalize all the images
import matplotlib.pyplot as plt
def imshow(img):
# Will take numpy array as input
img = img / 2 + 0.5 # Unnormalize image
plt.imshow(np.transpose(img, (1, 2, 0)))
# if __name__ == '__main__':
# dataiter = iter(train_loader)
# images, labels = next(dataiter)
# images = images.numpy()
#
# fig = plt.figure(figsize=(25, 4))
# for idx in range(20):
# ax = fig.add_subplot(2, 20 // 2, idx + 1, xticks=[], yticks=[])
# imshow(images[idx])
# ax.set_title(class_names[labels[idx]])
# plt.show()
import torch.nn as nn
import torch.nn.functional as F
# define the CNN architecture
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 2, padding=1, stride=1) # (32 - 5+ 2(0) / 1) + 1 = 28
self.pool1 = nn.MaxPool2d(2, 2) # (28 - 2 + 2(0)/ 2) + 1 = 14
self.conv2 = nn.Conv2d(6, 16, 2, padding=1, stride=1) # (14 - 5 + 2(0)/ 1) + 1 = 10
self.pool2 = nn.MaxPool2d(2, 2) # (10 - 2 + 2(0)/ 2) + 1 = 5
self.conv3 = nn.Conv2d(16, 32, 2) # (5 - 2 + 2(0)/ 1) + 1 = 4
self.pool3 = nn.MaxPool2d(2, 2) # (4 - 2 + 2(0)/ 2) + 1 = 2
self.fc1 = nn.Linear(32 * 3 ** 2, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# add sequence of convolutional and max pooling layers
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = self.pool3(F.relu(self.conv3(x)))
# Flatten it
x = torch.flatten(x, 1)
# x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# create a complete CNN
model = Net()
# print(model)
# move tensors to GPU if CUDA is available
if train_on_gpu:
model.cuda()
import torch.optim as optim
# specify loss function
criterion = nn.CrossEntropyLoss()
# specify optimizer
optimizer = optim.SGD(model.parameters(), lr= 0.0001, momentum= 0.9)
# number of epochs to train the model
n_epochs = 35 # you may increase this number to train a final model
valid_loss_min = np.inf # track change in validation loss
for epoch in range(1, n_epochs + 1):
# keep track of training and validation loss
train_loss = 0.0
valid_loss = 0.0
###################
# train the model #
###################
model.train()
for data, target in train_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output, target)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# update training loss
train_loss += loss.item() * data.size(0)
######################
# validate the model #
######################
model.eval()
for data, target in valid_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output, target)
# update average validation loss
valid_loss += loss.item() * data.size(0)
# calculate average losses
train_loss = train_loss / len(train_loader.dataset)
valid_loss = valid_loss / len(valid_loader.dataset)
# print training/validation statistics
print('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(
epoch, train_loss, valid_loss))
# save model if validation loss has decreased
if valid_loss <= valid_loss_min:
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(
valid_loss_min,
valid_loss))
torch.save(model.state_dict(), 'model_cifar.pt')
valid_loss_min = valid_loss
###################
# inference steps
###################
model.load_state_dict(torch.load('model_cifar.pt'))
# track test loss
test_loss = 0.0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
model.eval()
# iterate over test data
for data, target in test_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output, target)
# update test loss
test_loss += loss.item()*data.size(0)
# convert output probabilities to predicted class
_, pred = torch.max(output, 1)
# compare predictions to true label
correct_tensor = pred.eq(target.data.view_as(pred))
correct = np.squeeze(correct_tensor.numpy()) if not train_on_gpu else np.squeeze(correct_tensor.cpu().numpy())
# calculate test accuracy for each object class
for i in range(batch_size):
label = target.data[i]
class_correct[label] += correct[i].item()
class_total[label] += 1
# average test loss
test_loss = test_loss/len(test_loader.dataset)
print('Test Loss: {:.6f}\n'.format(test_loss))
for i in range(10):
if class_total[i] > 0:
print('Test Accuracy of %5s: %2d%% (%2d/%2d)' % (
class_names[i], 100 * class_correct[i] / class_total[i],
np.sum(class_correct[i]), np.sum(class_total[i])))
else:
print('Test Accuracy of %5s: N/A (no training examples)' % (classes[i]))
print('\nTest Accuracy (Overall): %2d%% (%2d/%2d)' % (
100. * np.sum(class_correct) / np.sum(class_total),
np.sum(class_correct), np.sum(class_total)))
if __name__ == '__main__':
# 获取一批测试图像
dataiter = iter(test_loader)
images, labels = next(dataiter)
# 不要转换为 NumPy,保持为 Tensor
# 如果 GPU 可用,则将模型输入移动到 CUDA
if train_on_gpu:
images = images.cuda()
labels = labels.cuda()
# 获取样本输出
output = model(images)
# 将输出概率转换为预测类别
_, preds_tensor = torch.max(output, 1)
if train_on_gpu:
preds = preds_tensor.cpu().numpy()
images_np = images.cpu().numpy()
else:
preds = preds_tensor.numpy()
images_np = images.numpy()
# 绘制批次中的图像以及预测和真实标签
fig = plt.figure(figsize=(25, 4))
for idx in np.arange(20):
ax = fig.add_subplot(2, 20 // 2, idx + 1, xticks=[], yticks=[])
imshow(images_np[idx])
ax.set_title("{} ({})".format(class_names[preds[idx]], class_names[labels[idx].item()]),
color=("green" if preds[idx] == labels[idx].item() else "red"))
plt.show()我们现在的训练当然是个很基础的CNN,我们可以先去下一步评估中看一下这次模型的结果如何,从而确定更明确的优化的点以设计出更好的CNN。
6. 模型评估
我们现在评估这个模型,刚刚的代码涵盖了这一部分,甚至其将一些正确的分类结果和错误的分类结果单独打印了出来。


当然最重要的混淆矩阵也要输出为热力图清晰地展示出来。
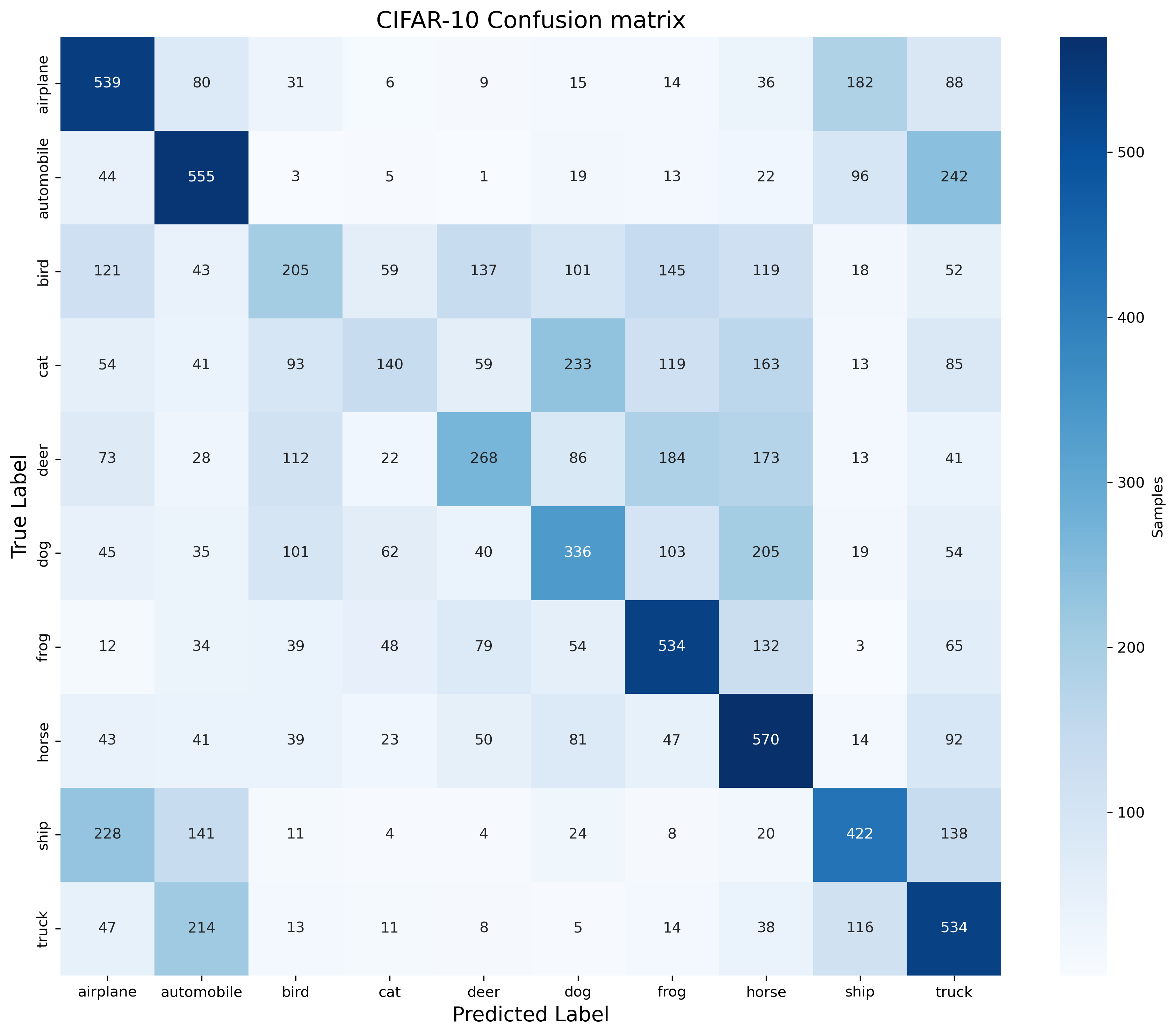
我们现在可以开始尝试分析这里的结果了。
我们可以从最容易的混淆矩阵开始,最基础的正确率等结果,都反应其实目前的模型只是稍微优于随机猜测10%的结果,并不能很好地对我们的图片进行分类。(这里准确率计算可以专门用代码去处理结算,当然也可以手动计算,结果当然是正确分类数/该类别总数1000。)
如下图所示,这种数据类的结果我认为这样比较清晰,如果愿意当然也可以做成可视化的表格,但是那样可能不如数字清晰。
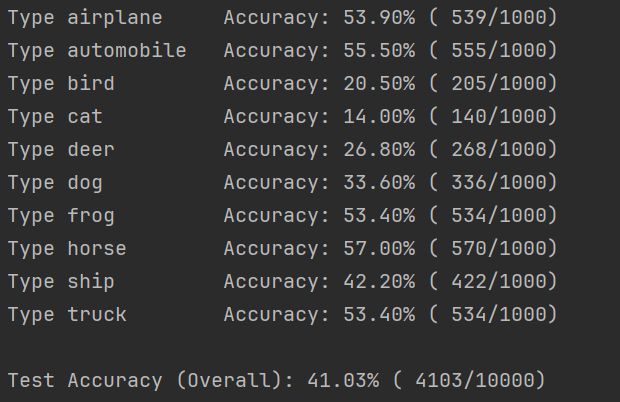
这个结果很明显非常糟糕,虽然比随机猜测的百分之10强,但是最高的正确率只有53.90%,而整体上的正确率只有41.03%,因此我们的模型还有很多进步空间,我们现在可以继续分析,尝试研究为什么这里的效果会这么差。
我们现在可以仔细观察这里的混淆矩阵结果,我们可以发现到一些对称性,比如飞机会被误认为是船,同样地,船会容易被误认为是飞机。这说明两者的确很接近,容易被混淆。同样的对称性还在汽车以及卡车之间出现。
有对称性存在的同时,这里也有非对称性。猫容易被误认为狗,但是后者容易被误认为马,而非猫。同样的非对称性还存在与鹿会被误认为青蛙和马二这两者并不会被误认为鹿。这说明应该有一个特征是狗独有的,而猫不会有,而猫和狗在某个特征上是一样的,包括马和狗也是有个共同特征。
我们还可以发现鸟类是非常难以被正确分类的,说明这个类别可能没有明显的特征以区分。
我们还可以将模型的置信度情况展示出来。相关的代码如下。
python
plt.figure(figsize=(10, 5))
plt.hist([all_correct_confidences, all_incorrect_confidences],
bins=20,
label=['Correct', 'Incorrect'],
alpha=0.7,
color=['green', 'red'])
plt.xlabel('Confidence value')
plt.ylabel('Frequency (Number of samples)')
plt.title(f'Correct vs Incorrect Confidence Distribution')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('confidence_distribution.png', dpi=300, bbox_inches='tight')
plt.show()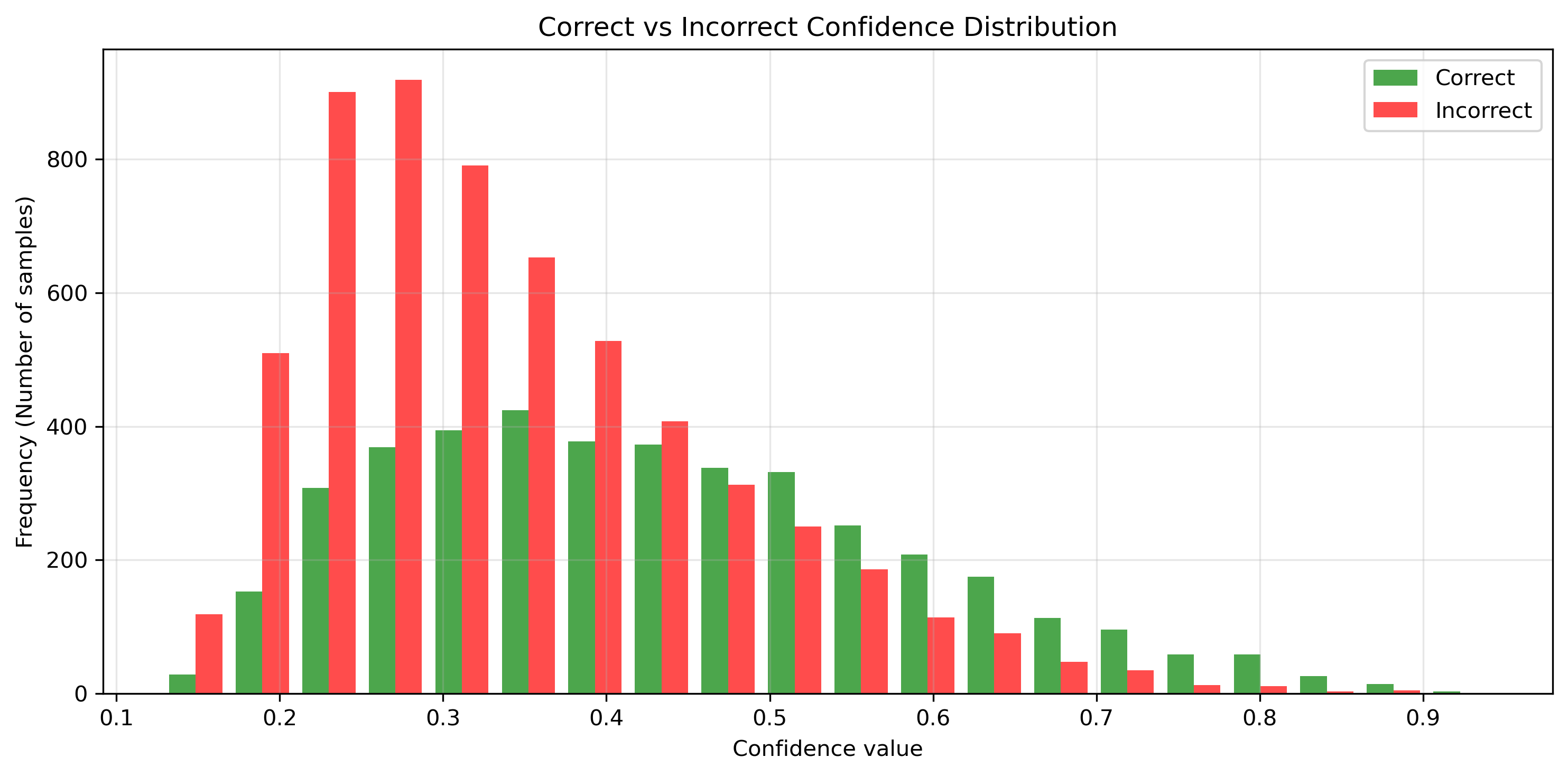
红色是错误的情况,绿色是正确的分类。我们可以发现,在低置信度区域,错误的分类比正确的结果更频繁,这意味着模型在不确定的情况下知道它是错误的。在高置信度区域,图片显示了更多正确场景的频率。但仍然存在错误的情况,这可以在前面我们展示的错误分类示例的图片中得到印证。高置信度的错误百分比为1.1%。然而,正确预测的平均置信度仅为0.431,这似乎表明该模型缺乏置信度。这些都说明了我们的模型实际效果很糟糕,我们需要改进我们的模型。
我们可以将数据库拿出来仔细分析,尝试用我们人工的方式去找到一些可能的有用的特征。就像我们是老师,我们提前教授给自己的学生以知识点从而通关考试。那么我们这个行为会影响这个模型的适用性吗,因为我们是观测我们这个数据集得出了我们认为一些有用的可以区分不同类别的特征,然后将这些提前教会给我们的模型,从而帮助我们模型在这样的数据集上获得更优秀的成绩。这一做法有点像泄题,但是其实并不会影响这里模型的适用性。因为这一做法和将训练数据直接拿给不同,因为我们的模型的目的实际上是真的学会这些类,我们得到的比如快速区分两个类之间的方式可能就来源于我们的现实生活,因此我们这一点是正确的,它理应有效,我们这里的做法是假设这个数据集真的涵盖到了现实生活的这个类别的各种样子。因此如果我们这个数据集是一个优秀的数据集,我们通过观察这个数据集得出的结论就应该和现实世界的结论一致,而且可以被适用于模型之上。回到我们前面,如果我们给模型的训练集和测试集一致,那它就变成基于实例的分类器(Instance-Based Classifiers),也就是它并没有真的靠特征去分别类别,而是靠自己的记忆去解决问题,所以对于除了训练集之外的数据就会变得效果很差,所以并非我们的初衷,因此我们的方法是可行的。
我们现在将数据集里的一些照片可以展示出来,这里因为也用打印出照片,所以项目的打印照片的方法都可以用一个共用的方法,这里不再重复(需要注意数据经过预处理,因此展现图片需要将数据还原,或者使用原来的数据)。

我们这里尝试用观察这里的照片找到一些特征或者发现帮助我们解决我们前面通过观察混淆矩阵所发现的一些对称性和非对称结果。
我们发现飞机、汽车、青蛙、马和卡车类都是只具有单一姿势,不像猫、狗类这样的姿势可能多种多样(坐着、站着、躺着等),这可能是它们很容易区分的原因。
我们还可以发现,大多数的飞机和船类都是蓝色背景,因此如果模型先识别到这一点就可以将类别锁定到这两类,然后再进行进一步的区分,这样可以帮助我们将这两类区分到别的类的错误的情况。因此我们可以使用更大的内核大小来提取全局背景等特征,而现在的通道数也可以提升以提取全局背景。同样的汽车和卡车类也是这样,我们可以先识别其的背景有道路,然后从而锁定到这两类。
而对于猫、狗类这样的不对称情况,我们观察发现猫缺乏独特的辨别特征,狗不具有猫的特征,但猫具有狗的特征。而鸟类也很难辨认,这是因为鸟类的背景和姿势都是多样的,因此难以用我们前面的那种方式去辨认,因此其的特征太多,而且没有特定的唯一特征,所以难以以某个具有鉴别性的特征来进行准确的预测。
所以我们现在的下一步是需要更大的卷积核来捕获全局上下文,还需要更多的通道来学习复杂类别的判别特征。
7. 改进模型
刚刚我们已经指出了我们可以优化的方向。
- 更正确的数据预处理,在数据预处理中我们说过原来的模型数据预处理是有问题的,我们现在可以使用正确的数据预处理去操作。
- 更大的卷积核,我们需要更大的卷积核去捕捉全局特征。
- 更大的通道数,现在的通道数当然也不支持提取全局背景,因此也需要扩大。
- 我们还可以增加我们的Batch size,以降低噪声以及提高训练速度。
- 我们还可以批归一化从而通过对每一层的输入进行标准化,加速训练并提高模型稳定性。
- 我们还可以换一个优化器,我们之前的模型是固定的0.0001学习率而且没有使用正则化以避免过拟合,所以现在可以使用自适应学习率优化器从而自适应梯度,快速收敛。
因此现在我们的代码如下。
python
import torch
import numpy as np
# check if CUDA is available
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:
print('CUDA is not available. Training on CPU ...')
else:
print('CUDA is available! Training on GPU ...')
from torchvision import datasets
from torchvision.transforms import transforms
from torch.utils.data.sampler import SubsetRandomSampler
number_of_workers = 0
batch_size= 128
valid_size= 0.2
# Converting Data into a Normalized Tensor format
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=(0.4914, 0.4822, 0.4465), std= (0.2470, 0.2435, 0.2616))
])
# Downloading training and testing Datasets
train_data= datasets.CIFAR10('data', train= True,
download= True, transform = transform)
test_data = datasets.CIFAR10('data', train = False,
download = True, transform= transform)
# Obtaining training Indices that we are going to use for Validation Set
num_train= len(train_data)
indices = list(range(num_train))
np.random.shuffle(indices)
split = int(np.floor(valid_size * num_train))
train_idx, valid_idx = indices[split:] , indices[:split]
# Defining samplers for training and validation Bathces
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
# Preparing Data Loader for all three sets (combining datasets and samplers)
train_loader = torch.utils.data.DataLoader(train_data, batch_size = batch_size ,
sampler= train_sampler , num_workers = number_of_workers)
valid_loader= torch.utils.data.DataLoader(train_data , batch_size= batch_size,
sampler = valid_sampler, num_workers = number_of_workers)
test_loader= torch.utils.data.DataLoader(test_data, batch_size= batch_size,
num_workers= number_of_workers)
# Spacify Image Classes
class_names =['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
# After preparing Data, we have to unnormalize it to visullize it.
# Lets create a helper function which will un-normalize all the images
import matplotlib.pyplot as plt
def imshow(img):
# Will take numpy array as input
img = img / 2 + 0.5 # Unnormalize image
plt.imshow(np.transpose(img, (1, 2, 0)))
# if __name__ == '__main__':
# dataiter = iter(train_loader)
# images, labels = next(dataiter)
# images = images.numpy()
#
# fig = plt.figure(figsize=(25, 4))
# for idx in range(20):
# ax = fig.add_subplot(2, 20 // 2, idx + 1, xticks=[], yticks=[])
# imshow(images[idx])
# ax.set_title(class_names[labels[idx]])
# plt.show()
import torch.nn as nn
import torch.nn.functional as F
# define the CNN architecture
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.net = nn.Sequential(
# first block
nn.Conv2d(3, 32, 3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
# second block
nn.Conv2d(32, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2),
# third block
nn.Conv2d(64, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2),
# fully connected layer
nn.Flatten(),
nn.Linear(128 * 4 * 4, 256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 10)
)
def forward(self, x):
return self.net(x)
# create a complete CNN
model = Net()
# print(model)
# move tensors to GPU if CUDA is available
if train_on_gpu:
model.cuda()
import torch.optim as optim
# specify loss function
criterion = nn.CrossEntropyLoss()
# specify optimizer
optimizer = optim.Adam(model.parameters(),
lr=0.001,
betas=(0.9, 0.999),
weight_decay=5e-4)
scheduler = optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=30)
# number of epochs to train the model
n_epochs = 35 # you may increase this number to train a final model
valid_loss_min = np.inf # track change in validation loss
for epoch in range(1, n_epochs + 1):
# keep track of training and validation loss
train_loss = 0.0
valid_loss = 0.0
###################
# train the model #
###################
model.train()
for data, target in train_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output, target)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# update training loss
train_loss += loss.item() * data.size(0)
######################
# validate the model #
######################
model.eval()
for data, target in valid_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output, target)
# update average validation loss
valid_loss += loss.item() * data.size(0)
# calculate average losses
train_loss = train_loss / len(train_loader.dataset)
valid_loss = valid_loss / len(valid_loader.dataset)
# print training/validation statistics
print('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(
epoch, train_loss, valid_loss))
# save model if validation loss has decreased
if valid_loss <= valid_loss_min:
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(
valid_loss_min,
valid_loss))
torch.save(model.state_dict(), 'model_cifar.pt')
valid_loss_min = valid_loss
###################
# inference steps
###################
model.load_state_dict(torch.load('model_cifar.pt'))
# track test loss
test_loss = 0.0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
model.eval()
# iterate over test data
for data, target in test_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output, target)
# update test loss
test_loss += loss.item()*data.size(0)
# convert output probabilities to predicted class
_, pred = torch.max(output, 1)
# compare predictions to true label
correct_tensor = pred.eq(target.data.view_as(pred))
correct = np.squeeze(correct_tensor.numpy()) if not train_on_gpu else np.squeeze(correct_tensor.cpu().numpy())
# calculate test accuracy for each object class
for i in range(batch_size):
label = target.data[i]
class_correct[label] += correct[i].item()
class_total[label] += 1
# average test loss
test_loss = test_loss/len(test_loader.dataset)
print('Test Loss: {:.6f}\n'.format(test_loss))
for i in range(10):
if class_total[i] > 0:
print('Test Accuracy of %5s: %2d%% (%2d/%2d)' % (
class_names[i], 100 * class_correct[i] / class_total[i],
np.sum(class_correct[i]), np.sum(class_total[i])))
else:
print('Test Accuracy of %5s: N/A (no training examples)' % (classes[i]))
print('\nTest Accuracy (Overall): %2d%% (%2d/%2d)' % (
100. * np.sum(class_correct) / np.sum(class_total),
np.sum(class_correct), np.sum(class_total)))
if __name__ == '__main__':
# 获取一批测试图像
dataiter = iter(test_loader)
images, labels = next(dataiter)
# 不要转换为 NumPy,保持为 Tensor
# 如果 GPU 可用,则将模型输入移动到 CUDA
if train_on_gpu:
images = images.cuda()
labels = labels.cuda()
# 获取样本输出
output = model(images)
# 将输出概率转换为预测类别
_, preds_tensor = torch.max(output, 1)
if train_on_gpu:
preds = preds_tensor.cpu().numpy()
images_np = images.cpu().numpy()
else:
preds = preds_tensor.numpy()
images_np = images.numpy()
# 绘制批次中的图像以及预测和真实标签
fig = plt.figure(figsize=(25, 4))
for idx in np.arange(20):
ax = fig.add_subplot(2, 20 // 2, idx + 1, xticks=[], yticks=[])
imshow(images_np[idx])
ax.set_title("{} ({})".format(class_names[preds[idx]], class_names[labels[idx].item()]),
color=("green" if preds[idx] == labels[idx].item() else "red"))
plt.show()
所以我们现在的网络整体框架如下。
plain
输入图像 (32×32×3)
↓
[卷积块 1] → (16×16×64)
↓
[卷积块 2] → (8×8×128)
↓
[卷积块 3] → (4×4×512)
↓
Flatten → 2048 维
↓
全连接层 → 256 维
↓
输出层 → 10 维 (CIFAR-10类别)8. 更多优化策略
我们之前都是使用的固定卷积核,我们之前提到的关于对称性的类别的先全局特征提取在细小特征提取的策略应该使用不一样大小的卷积核,因此我们可以使用基于Inception架构的多尺度特征提取模型,这个模型理论上也应该相较于最开始的模型更优秀,甚至可能比我们刚刚得到的优化模型优秀,因此我们下一步还需要使用实际的评估从而比较这些模型。
代码如下。
python
import torch
import numpy as np
import matplotlib.pyplot as plt
from torchvision import datasets, transforms
from torch.utils.data.sampler import SubsetRandomSampler
import torch.nn as nn
import torch.optim as optim
# check if CUDA is available
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:
print('CUDA is not available. Training on CPU ...')
else:
print('CUDA is available! Training on GPU ...')
# 设置超参数
number_of_workers = 0
batch_size = 128
valid_size = 0.2
n_epochs = 35
# 数据转换和增强
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=(0.4914, 0.4822, 0.4465), std=(0.2470, 0.2435, 0.2616))
])
# 下载数据集
train_data = datasets.CIFAR10('data', train=True,
download=True, transform=transform)
test_data = datasets.CIFAR10('data', train=False,
download=True, transform=transform)
# 划分训练集和验证集
num_train = len(train_data)
indices = list(range(num_train))
np.random.shuffle(indices)
split = int(np.floor(valid_size * num_train))
train_idx, valid_idx = indices[split:], indices[:split]
# 定义采样器
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,
sampler=train_sampler, num_workers=number_of_workers)
valid_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,
sampler=valid_sampler, num_workers=number_of_workers)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size,
num_workers=number_of_workers)
# 类别名称
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
# 可视化辅助函数
def imshow(img):
img = img / 2 + 0.5 # 反归一化
plt.imshow(np.transpose(img, (1, 2, 0)))
# 定义简化的Inception模块
class SimplifiedInception(nn.Module):
def __init__(self, in_channels):
super().__init__()
# 分支1: 1×1卷积
self.branch1 = nn.Sequential(
nn.Conv2d(in_channels, 32, kernel_size=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True)
)
# 分支2: 1×1降维 → 3×3卷积
self.branch2 = nn.Sequential(
nn.Conv2d(in_channels, 32, kernel_size=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
# 分支3: 3×3池化 → 1×1卷积
self.branch3 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels, 32, kernel_size=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
# 在通道维度上拼接
return torch.cat([branch1, branch2, branch3], dim=1)
# 输出通道数 = 32 + 64 + 32 = 128
# 定义完整的CNN网络
class InceptionCNN(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
# 第一层:普通卷积层 (3×3)
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
# 第二层:第一个Inception模块
self.inception1 = SimplifiedInception(in_channels=64) # 输出128通道
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 32x32 -> 16x16
# 第三层:第二个Inception模块
self.inception2 = SimplifiedInception(in_channels=128) # 输出128通道
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2) # 16x16 -> 8x8
# 第四层:第三个Inception模块
self.inception3 = SimplifiedInception(in_channels=128) # 输出128通道
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2) # 8x8 -> 4x4
# 全局平均池化 + 全连接层
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # 4x4 -> 1x1
self.fc = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(128, 256),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(256, num_classes)
)
# 初始化权重
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
# 输入: [B, 3, 32, 32]
x = self.conv1(x) # -> [B, 64, 32, 32]
x = self.inception1(x) # -> [B, 128, 32, 32]
x = self.pool1(x) # -> [B, 128, 16, 16]
x = self.inception2(x) # -> [B, 128, 16, 16]
x = self.pool2(x) # -> [B, 128, 8, 8]
x = self.inception3(x) # -> [B, 128, 8, 8]
x = self.pool3(x) # -> [B, 128, 4, 4]
x = self.avgpool(x) # -> [B, 128, 1, 1]
x = x.view(x.size(0), -1) # -> [B, 128]
x = self.fc(x) # -> [B, num_classes]
return x
# 创建模型
model = InceptionCNN(num_classes=10)
# 打印模型结构
print(model)
# 如果有GPU,将模型移到GPU
if train_on_gpu:
model.cuda()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),
lr=0.001,
betas=(0.9, 0.999),
weight_decay=5e-4)
# 学习率调度器
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=n_epochs)
# 训练模型
valid_loss_min = np.inf
train_losses = []
valid_losses = []
for epoch in range(1, n_epochs + 1):
# 训练阶段
model.train()
train_loss = 0.0
for data, target in train_loader:
if train_on_gpu:
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.item() * data.size(0)
# 验证阶段
model.eval()
valid_loss = 0.0
with torch.no_grad():
for data, target in valid_loader:
if train_on_gpu:
data, target = data.cuda(), target.cuda()
output = model(data)
loss = criterion(output, target)
valid_loss += loss.item() * data.size(0)
# 计算平均损失
train_loss = train_loss / len(train_loader.dataset)
valid_loss = valid_loss / len(valid_loader.dataset)
train_losses.append(train_loss)
valid_losses.append(valid_loss)
# 打印统计信息
print(f'Epoch: {epoch:2d} \tTraining Loss: {train_loss:.6f} \tValidation Loss: {valid_loss:.6f}')
# 更新学习率
scheduler.step()
# 保存最佳模型
if valid_loss <= valid_loss_min:
print(f'Validation loss decreased ({valid_loss_min:.6f} --> {valid_loss:.6f}). Saving model ...')
torch.save(model.state_dict(), 'inception_model_cifar.pt')
valid_loss_min = valid_loss
print('Training completed!')
# 测试模型
model.load_state_dict(torch.load('inception_model_cifar.pt'))
test_loss = 0.0
class_correct = [0] * 10
class_total = [0] * 10
model.eval()
with torch.no_grad():
for data, target in test_loader:
if train_on_gpu:
data, target = data.cuda(), target.cuda()
output = model(data)
loss = criterion(output, target)
test_loss += loss.item() * data.size(0)
_, pred = torch.max(output, 1)
correct_tensor = pred.eq(target.data.view_as(pred))
if train_on_gpu:
correct = correct_tensor.cpu().numpy()
else:
correct = correct_tensor.numpy()
# 统计每个类别的准确率
for i in range(len(target)):
label = target.data[i]
class_correct[label] += correct[i]
class_total[label] += 1
# 计算整体测试准确率
test_loss = test_loss / len(test_loader.dataset)
print(f'\nTest Loss: {test_loss:.6f}')
# 打印每个类别的准确率
for i in range(10):
if class_total[i] > 0:
print(f'Test Accuracy of {class_names[i]:>10s}: {100 * class_correct[i] / class_total[i]:2.0f}% '
f'({int(class_correct[i])}/{int(class_total[i])})')
# 计算整体准确率
total_correct = sum(class_correct)
total = sum(class_total)
print(f'\nOverall Test Accuracy: {100 * total_correct / total:2.0f}% ({int(total_correct)}/{int(total)})')
# 可视化部分测试结果
def visualize_predictions(model, test_loader, num_images=20):
model.eval()
dataiter = iter(test_loader)
images, labels = next(dataiter)
if train_on_gpu:
images = images.cuda()
with torch.no_grad():
output = model(images)
_, preds = torch.max(output, 1)
if train_on_gpu:
images = images.cpu()
preds = preds.cpu()
labels = labels.cpu()
images = images.numpy()
preds = preds.numpy()
labels = labels.numpy()
fig = plt.figure(figsize=(25, 4))
for idx in range(num_images):
ax = fig.add_subplot(2, num_images // 2, idx + 1, xticks=[], yticks=[])
imshow(images[idx])
ax.set_title(f"{class_names[preds[idx]]} ({class_names[labels[idx]]})",
color=("green" if preds[idx] == labels[idx] else "red"))
plt.show()
# 可视化预测结果
visualize_predictions(model, test_loader)
# 绘制训练损失曲线
plt.figure(figsize=(10, 5))
plt.plot(range(1, n_epochs + 1), train_losses, label='Training Loss')
plt.plot(range(1, n_epochs + 1), valid_losses, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss Over Epochs')
plt.legend()
plt.grid(True)
plt.show()
# 打印模型参数统计
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
total_params = count_parameters(model)
print(f'\nTotal Trainable Parameters: {total_params:,}')
print(f'Model Size: {total_params * 4 / (1024 ** 2):.2f} MB (assuming float32)')
# 保存完整模型(包含结构)
torch.save({
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'train_losses': train_losses,
'valid_losses': valid_losses,
'test_accuracy': 100 * total_correct / total
}, 'complete_inception_model.pth')
print('Model saved successfully!')这里有三个分支组成,第一个是 1×1 卷积层,第二个是 1×1 卷积层和 3×3 卷积层,第三个是 3×3 池化层和 1×1 卷积层。最后再拼接在一起。通过这样的方式我们可以尝试获取全局特征以及局部特征。
9. 结果对比
最后我们将这两个优化模型都进行一样的操作进行评估。
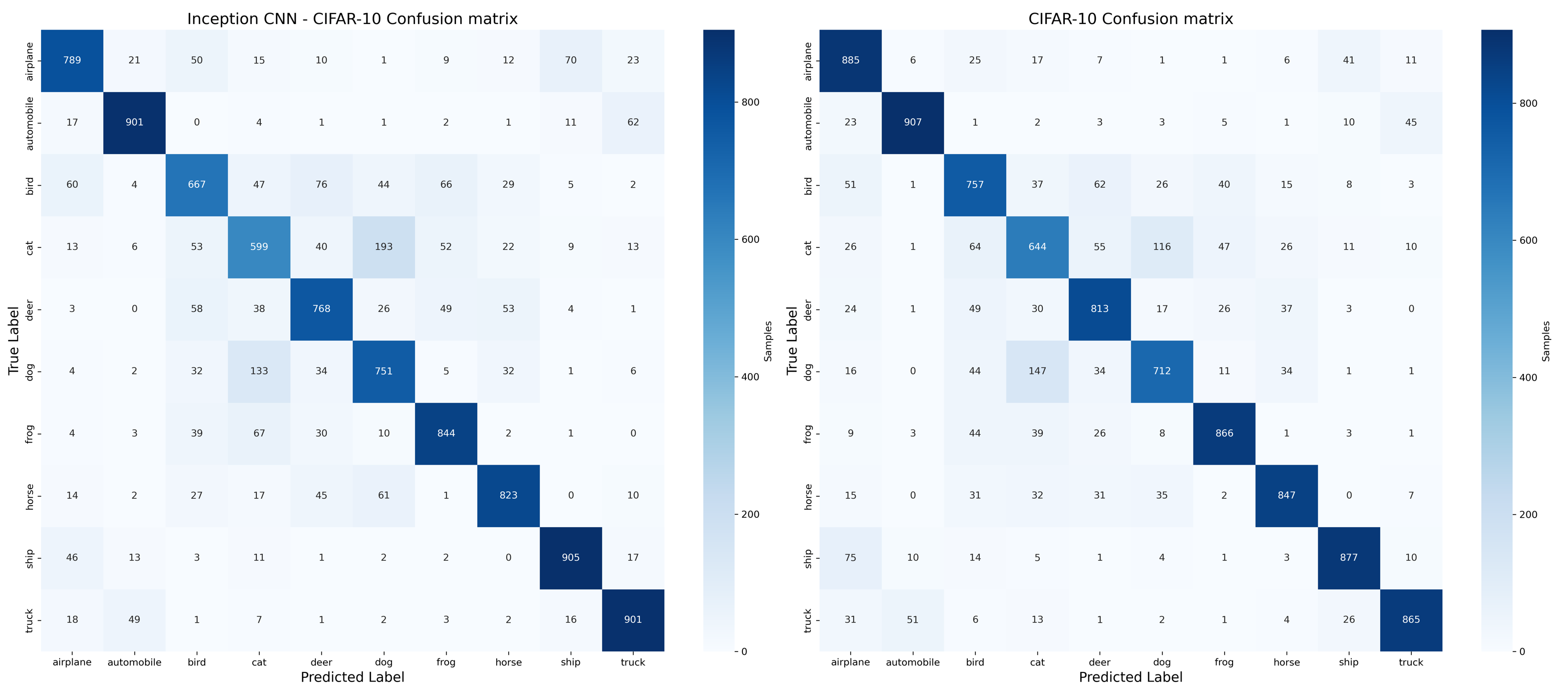
混淆矩阵的对比如下。
详细的数据如下。
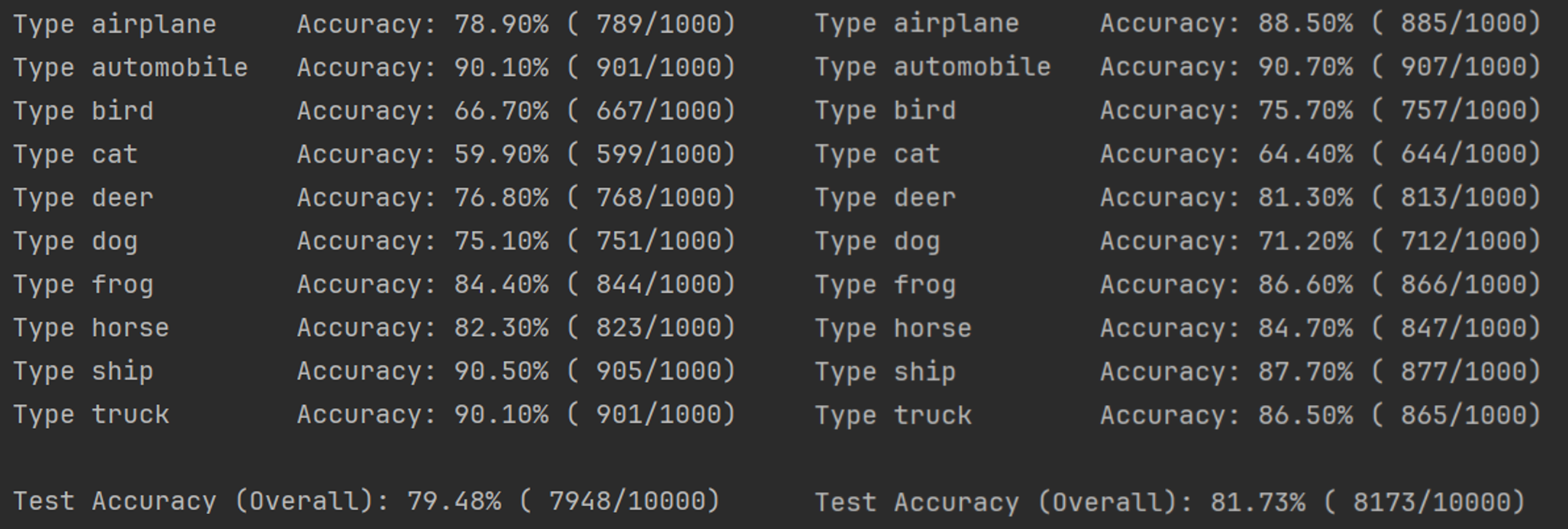
我们现在的准确率都得到了大量提升,前者是81.73%,后者是79.8%。
然而,通过新的混淆矩阵,我们可以发现它在船类和卡车类上具有明显更高的准确性,这在以前被认为是更容易分类的类别。这表明,我们通过不同大小的感受野捕捉整体背景特征以快速区分船只等类别的方法是有效的。这是Inception架构支持的多尺度特征表示的优点。然而,飞机类的精度大大降低,这本被我们认为是可以以这样的方式分类出来的。这可能表明我们之前认为的多尺度特征方法不适用于飞机类,飞机的关键特征可能在于局部特征,而非我们之前认为的那样。
此外,在别的类别中,新模型的表现也比之前的模型差。鸟和猫更容易被误解。这也符合我们之前的假设,因为它们差异化的关键在于具体的细节,而不适用于我们的多尺度特征方法。
10. 最终结论
我们在尝试了三个模型后我们对于多分类任务来说有了一个更清晰的认识。
考虑到CIFAR-10数据集的类别,更简单的固定内核架构可能会提供更好的准确性。但Inception设计的确可以帮助解决多尺度特征问题(例如船只和卡车这样的有环境信息和局部信息的类别)。
既然这两种方法都能解决部分类别的区分,那么应该还是会存在一种方法帮助我们解决猫的归类问题。而这种策略很有可能在其他类别的区分中表现不佳。
所以单一的特征提取策略无法为所有类别提供最佳服务,而对于多分类问题,我们可以先分析一些类别的共性。对于这些常见的类,我们可以使用分类策略来解决它们,对于其他属性,我们可以用其他策略来解决。由这些集合形成的大型分类器可能是解决多分类问题的最佳工具。
总之,对于多分类任务,类别越多,分类问题就越复杂,单一分类策略的局限性也就越明显。由于不同类别的特点,集成多种策略的分类器可能是一种潜在的优化方法。