目录
1.考虑这样一个问题:它要找出n个数字构成的一个数组中两个最接近数的距离(两个数x和y之间的距离定义为|x-y|)。
b.将该算法的效率类型和蛮力算法的效率类型进行比较(参见习题1.2中的第9题)。
2.假设A={a₁,......,aₙ}和B={b₁,...,bₘ}是两个数字集合。考虑一下对它们求交集的问题,也就是说,集合C中的所有数字都是既属于A又属于B的。
3.考虑一下求n个数字构成的数组中最大元素和最小元素的问题。
b.比较以下三种算法的效率:(i)蛮力算法,(ii)基于预排序的算法,(iii)分治算法(参见习题5.1的第2题)。
[4.请估计一下,如果用合并排序做预排序,用折半查找做查找,要做多少次查找才能使得对一个由 10³个元素构成的数组所做的预排序是有意义的(我们可以假设,所要查找的都是数组中的元素)。如果是一个由10⁶个元素构成的数组呢?](#4.请估计一下,如果用合并排序做预排序,用折半查找做查找,要做多少次查找才能使得对一个由 10³个元素构成的数组所做的预排序是有意义的(我们可以假设,所要查找的都是数组中的元素)。如果是一个由10⁶个元素构成的数组呢?)
5.是排序还是不排序?为下面的每个问题设计一个较为高效的算法,然后确定该算法的效率类型。
a.给定n张电话账单和m张用来付电话费的支票(n≥m)。假设支票上写着电话号码,请确定哪些账单还没付费(为了简单起见,我们可以假设,一张支票只付一张特定的账单,并且一次性全部付清)。
b.我们有一份档案,里面有n个学生的记录,指出了每个学生的学号、姓名、家庭地址和生日。美国有50个州,求出来自每一个州的学生的数量。
6.给定一个集合,里面包含n≥3个在笛卡儿平面上的点,用简单多边形把它们连接起来,也就是一条穿过所有点的最短路径,并且它的线段(多边形的边)不能相互交叉(除了公共顶点上的两条相邻边)。例如,
[8. 我们在实数域上有n个开区间(a₁,b₁), (a₂,b₂)···, (aₙ,bₙ)(开区间(a,b)是由严格位于端点a和b之间的所有点构成的,即(a,b)={x|a](#8. 我们在实数域上有n个开区间(a₁,b₁), (a₂,b₂)···, (aₙ,bₙ)(开区间(a,b)是由严格位于端点a和b之间的所有点构成的,即(a,b)={x|a)
[9.数字填空 给定n个不同的整数以及一个包含 n个空格的序列,每个空格之间事先给定有不等(>或<)符号。请设计一个算法,将n个整数填入这 n个空格中并满足不等号的约束。例如,数4,6,3,1,8可以填在这样的5个空格中:](#9.数字填空 给定n个不同的整数以及一个包含 n个空格的序列,每个空格之间事先给定有不等(>或<)符号。请设计一个算法,将n个整数填入这 n个空格中并满足不等号的约束。例如,数4,6,3,1,8可以填在这样的5个空格中:)
[a.对于笛卡儿平面上的一个点(xi,yi),如果存在另一个点(xj,yj),使得 编辑 并且yi≤yj,,而且两个不等式中的一个至少严格成立,那么我们就说点(x,y,)是点(x₁,y₁)的先导。现在,给定一个含n个点的集合,如果其中一个点不被其他任何点先导,那么我们就说这个点是这个集合的最大点(maximum)。例如,如下图所示,所有的最大点已经被圈出来。](#a.对于笛卡儿平面上的一个点(xi,yi),如果存在另一个点(xj,yj),使得 编辑 并且yi≤yj,,而且两个不等式中的一个至少严格成立,那么我们就说点(x,y,)是点(x₁,y₁)的先导。现在,给定一个含n个点的集合,如果其中一个点不被其他任何点先导,那么我们就说这个点是这个集合的最大点(maximum)。例如,如下图所示,所有的最大点已经被圈出来。)
[a.为这个问题设计一个高效的算法:在一个类似英语辞典的大文件中找出变位词的所有集合(Ben00)。例如, eat, ate和 tea 属于同一个变位词集合。](#a.为这个问题设计一个高效的算法:在一个类似英语辞典的大文件中找出变位词的所有集合([Ben00])。例如, eat, ate和 tea 属于同一个变位词集合。)
1.考虑这样一个问题:它要找出n个数字构成的一个数组中两个最接近数的距离(两个数x和y之间的距离定义为|x-y|)。
a.设计一个基于预排序的算法来解该问题并确定它的效率类型。
对数组进行升序 / 降序排序
函数 closestPair(arr[], n):
排序 arr
minDist = 无穷大
对于 i 从 0 到 n-2:
dist = |arr[i+1] - arr[i]|
如果 dist < minDist:
minDist = dist
返回 minDist效率为Θ (n log n)
b.将该算法的效率类型和蛮力算法的效率类型进行比较(参见习题1.2中的第9题)。
预排序算法远优于蛮力算法,当 n 很大时差距极明显。其中蛮力算法是Θ(n^2)
2.假设A={a₁,......,aₙ}和B={b₁,...,bₘ}是两个数字集合。考虑一下对它们求交集的问题,也就是说,集合C中的所有数字都是既属于A又属于B的。
a.设计一个蛮力算法来解该问题并确定它的效率类型。
-
遍历集合 A 中的每一个元素 a
-
对每个 a,遍历集合 B 中的每一个元素 b
-
如果
a == b,就把它加入交集 C -
最后去重(集合要求无重复)
function intersection_brute(A, B):
C = empty set
for a in A:
for b in B:
if a == b:
add a to C
return C
效率为Θ(nm)
b.设计一个基于预排序的算法来解该问题并确定它的效率类型。
- 把 A 排序:O(n log n)
- 把 B 排序:O(m log m)
- 双指针法线性扫描求交集 :O(n + m)
-
i 指向 A 开头,j 指向 B 开头
-
相等则加入结果,同时 i++、j++
-
不等则移动较小值的指针
function intersection_sorted(A, B):
sort(A)
sort(B)
i = 0, j = 0
C = empty set
while i < n and j < m:
if A[i] == B[j]:
add A[i] to C
i++, j++
elif A[i] < B[j]:
i++
else:
j++
return C
-
效率为Θ(nlogn+mlogm)
3.考虑一下求n个数字构成的数组中最大元素和最小元素的问题。
a.设计一个基于预排序的算法来解该问题并确定它的效率类型。
-
将数组从小到大排序
-
排序后,第一个元素就是最小值
-
排序后,最后一个元素就是最大值
function findMinMaxSort(arr[], n):
sort(arr) // 排序
min = arr[0] // 最小
max = arr[n-1] // 最大
return (min, max)
效率为Θ (n log n)
b.比较以下三种算法的效率:(i)蛮力算法,(ii)基于预排序的算法,(iii)分治算法(参见习题5.1的第2题)。
(i) 蛮力算法(一次遍历)
- 遍历数组一遍,同时更新 min 和 max
- 比较次数:约 2n 次
- 时间复杂度:O (n)
(ii) 预排序算法
- 先排序,再取首尾
- 时间复杂度:O (n log n)
(iii) 分治算法
- 把数组分成两半,分别求 min/max,再合并
- 比较次数:约 1.5n 次
- 时间复杂度:O (n)
4.请估计一下,如果用合并排序做预排序,用折半查找做查找,要做多少次查找才能使得对一个由 10³个元素构成的数组所做的预排序是有意义的(我们可以假设,所要查找的都是数组中的元素)。如果是一个由10⁶个元素构成的数组呢?

注意这里的n/2是平均情况,实际上是(n+1)/2
设需要进行k次查找,则(排序代价+k*查找代价)/k<=蛮力查找代价,此时是有意义的
化简为
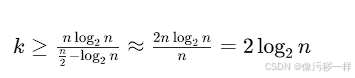
n=1000时,
- 计算 log_2 1000≈10
- 计算临界值:k≥2×10=20
n=1000000时,
- 计算 log_2 1000000≈20
- 计算临界值:k≥2×20=40
因此20和40是至少的查找次数
5.是排序还是不排序?为下面的每个问题设计一个较为高效的算法,然后确定该算法的效率类型。
a.给定n张电话账单和m张用来付电话费的支票(n≥m)。假设支票上写着电话号码,请确定哪些账单还没付费(为了简单起见,我们可以假设,一张支票只付一张特定的账单,并且一次性全部付清)。
- 把支票的号码排序(O(m log m))
- 遍历每一张账单 :
- 对账单号做折半查找,看是否在支票里
- 找不到 → 未付费
- 输出所有未付费账单
效率为Θ(mlogm)
b.我们有一份档案,里面有n个学生的记录,指出了每个学生的学号、姓名、家庭地址和生日。美国有50个州,求出来自每一个州的学生的数量。
不需要排序,
- 创建大小为 50 的数组 / 计数器(对应 50 个州)
- 遍历所有 n 个学生
- 读取学生的州
- 对应州的计数器 +1
- 遍历结束,直接输出 50 个州的计数
6.给定一个集合,里面包含n≥3个在笛卡儿平面上的点,用简单多边形把它们连接起来,也就是一条穿过所有点的最短路径,并且它的线段(多边形的边)不能相互交叉(除了公共顶点上的两条相邻边)。例如,
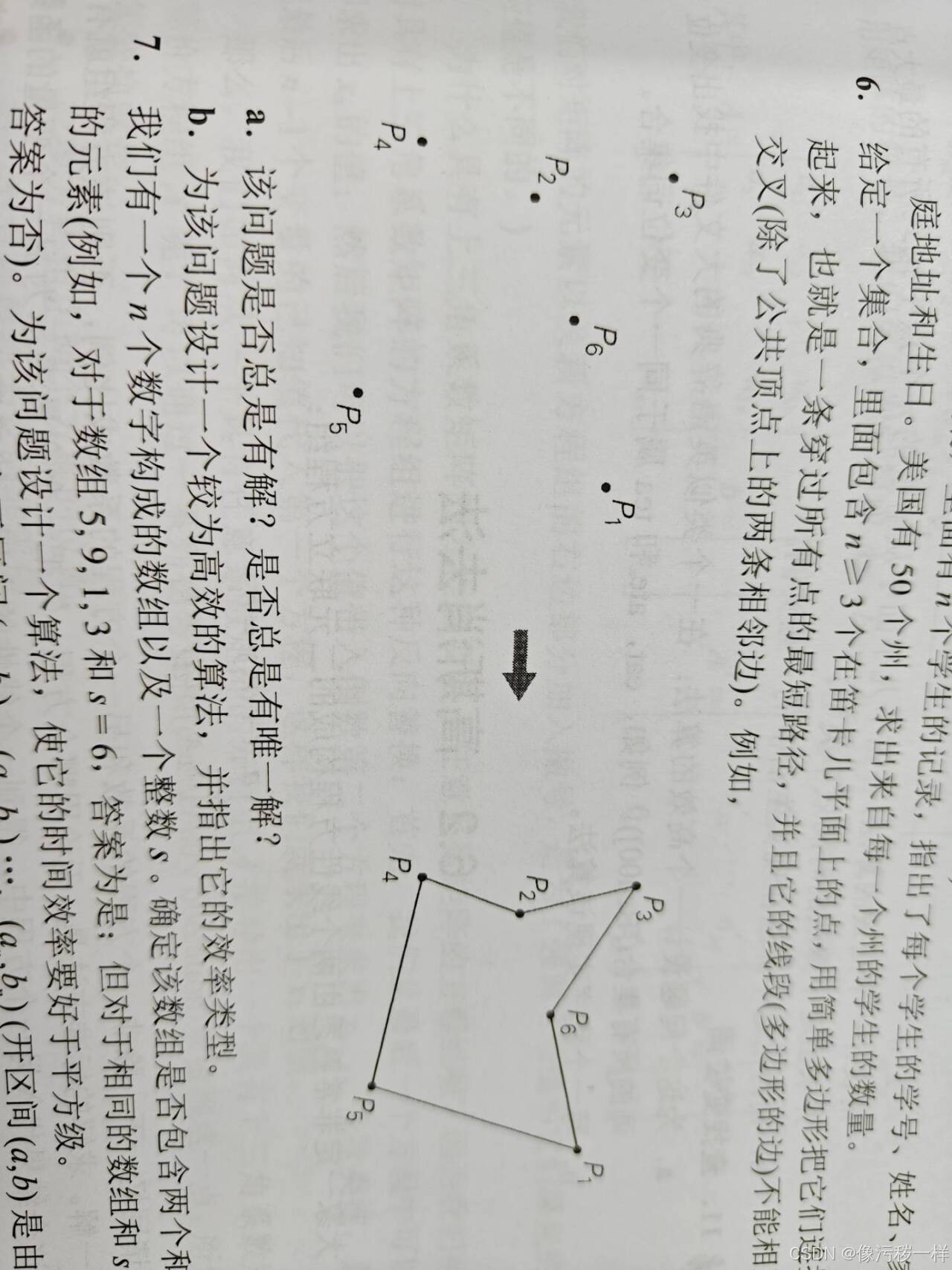
a.该问题是否总是有解?是否总是有唯一解?
总是有解
对于任意 n≥3 且无三点共线的平面点集,我们总能构造出一个简单多边形(不自交、边不交叉)将所有点连接起来。例如:
- 选取一个极点(比如 y 坐标最小的点);
- 将其余点按极角围绕该极点排序;
- 按顺序依次连接,最后回到起点,即可得到一个简单多边形。
但不总是有唯一解
- 若点集是正多边形顶点,则存在多个等长的简单多边形(旋转 / 反射后得到);
- 若点集是一般位置,也可能存在不同的连接顺序,得到不同长度的简单多边形。
b.为该问题设计一个较为高效的算法,并指出它的效率类型。
-
选取极点 :从点集中选取 y 坐标最小(若有多个则选 x 最小)的点作为基准点 p0。
-
极角排序 :将剩余 n−1 个点按相对于 p0 的极角从小到大排序(极角相同则按到 p0 的距离排序)。
-
构造多边形:按排序后的顺序依次连接 p0→p1→p2→⋯→pn−1→p0,得到一个简单多边形。
function simplePolygon(P):
p0 = 点集中 y 最小的点(若并列则 x 最小)
对 P \ {p0} 按极角(相对于 p0)升序排序
按顺序连接 p0 → p1 → ... → p_{n-1} → p0
返回该多边形
效率为Θ(nlogn),选取极点是nlogn的操作
7.我们有一个n个数字构成的数组以及一个整数s。确定该数组是否包含两个和为s的元素(例如,对于数组5,9,1,3和s=6,答案为是;但对于相同的数组和s=7,答案为否)。为该问题设计一个算法,使它的时间效率要好于平方级。
- 对数组进行排序(O(n log n))
- 用两个指针 :
- 左指针
left指向开头(最小数) - 右指针
right指向末尾(最大数)
- 左指针
- 循环判断 :
- 若
arr[left] + arr[right] == s→ 找到,返回真 - 若
arr[left] + arr[right] < s→ 左指针右移(需要更大) - 若
arr[left] + arr[right] > s→ 右指针左移(需要更小)
- 若
- 若指针相遇还没找到 → 返回假
效率为Θ(n log n)由于平方
8. 我们在实数域上有n个开区间(a₁,b₁), (a₂,b₂)···, (aₙ,bₙ)(开区间(a,b)是由严格位于端点a和b之间的所有点构成的,即(a,b)={x|a<x<b})。求包含共同点的区间的最大数量。例如, 对于区间(1,4), (0,3), (-1.5,2), (3.6,5)来说, 这个数量是3。为这个问题设计一个算法,要求效率要好于平方级。
每个区间 (a, b) 拆成两个点:
- 左端点
a,标记为 起点 - 右端点
b,标记为 终点
对所有端点进行排序,如果坐标相同:终点排在起点前面(开区间严格不包含端点)
线性扫描一遍,计算最大重叠数
- 遇到起点 → 当前重叠数 +1
- 遇到终点 → 当前重叠数 -1
- 记录扫描过程中的最大值
效率为Θ(n log n)
9.数字填空 给定n个不同的整数以及一个包含 n个空格的序列,每个空格之间事先给定有不等(>或<)符号。请设计一个算法,将n个整数填入这 n个空格中并满足不等号的约束。例如,数4,6,3,1,8可以填在这样的5个空格中:
1<8>3<4<6
先排序,然后准备两个指针
- 左指针 L :指向最小数(开头)
- 右指针 R :指向最大数(结尾)
从头到尾扫描不等号序列:
- 遇到
<→ 填 左指针 L 的数,L++ - 遇到
>→ 填 右指针 R 的数,R-- - 最后剩一个空格,把剩下的数字填进去
10.最大点寻找
a.对于笛卡儿平面上的一个点(xi,yi),如果存在另一个点(xj,yj),使得 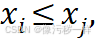 并且yi≤yj,,而且两个不等式中的一个至少严格成立,那么我们就说点(x,y,)是点(x₁,y₁)的先导。现在,给定一个含n个点的集合,如果其中一个点不被其他任何点先导,那么我们就说这个点是这个集合的最大点(maximum)。例如,如下图所示,所有的最大点已经被圈出来。
并且yi≤yj,,而且两个不等式中的一个至少严格成立,那么我们就说点(x,y,)是点(x₁,y₁)的先导。现在,给定一个含n个点的集合,如果其中一个点不被其他任何点先导,那么我们就说这个点是这个集合的最大点(maximum)。例如,如下图所示,所有的最大点已经被圈出来。
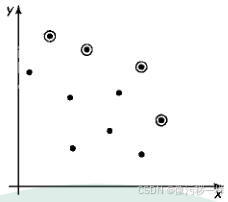
请设计一个高效的算法,在笛卡儿平面中从给定的n个点中找到所有的最大点并求出这个算法的时间效率类型。
- 排序 :将 n 个点按 x 坐标降序排列;x 相同则按 y 降序。
- 初始化 :
current_max_y = -∞。 - 遍历 :依次检查每个点:
- 如果该点的 y > current_max_y ⇒ 标记为最大点 ,并更新
current_max_y = y。
- 如果该点的 y > current_max_y ⇒ 标记为最大点 ,并更新
- 返回所有最大点。
因为
- 按 x 从大到小走 → 后面的点 x 一定更小。
- 所以后面的点不可能成为前面点的先导。
- 只要一个点的 y 比之前所有点都大 → 没人能支配它 → 是最大点。
b.请给出这个算法在现实生活中的一些实例。
豆包给的
- 商品性价比筛选 x = 价格低,y = 性能高 → 最大点 =最值得买的商品。
- 投资风险 / 收益 x = 收益,y = 安全性 → 最大点 =最优投资组合。
- 招聘候选人 x = 能力,y = 经验 → 最大点 =最优秀候选人。
- 城市宜居性排名 x = 收入,y = 环境 → 最大点 =最宜居城市。
- 数据包传输 / 性能优化 x = 速度,y = 稳定性 → 最大点 =最优方案。
11.查找变位词
a.为这个问题设计一个高效的算法:在一个类似英语辞典的大文件中找出变位词的所有集合(Ben00)。例如, eat, ate和 tea 属于同一个变位词集合。
-
创建一个Map
- 键(key) :单词按字母排序后的字符串
- 值(value) :具有该键的原始单词列表
-
遍历文件中的每一个单词
- 把单词的字母从小到大排序,生成 key
- 将原单词加入哈希表中对应 key 的列表里
-
遍历结束后
- 哈希表中每个键对应的列表 ,就是一个变位词集合
效率为Θ(n × L log L)
代码实现:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_WORDS 1000 // 最多单词数
#define MAX_LEN 100 // 单词最大长度
// 哈希表节点:key=排序后的字符串,value=单词链表
typedef struct Node {
char key[MAX_LEN];
char words[MAX_WORDS][MAX_LEN];
int count;
struct Node* next;
} Node;
#define HASH_SIZE 1000 // 哈希表大小
Node* hashTable[HASH_SIZE] = {NULL};
// 字符串排序(给单词字母排序,生成 key)
void sortStr(char* str) {
int len = strlen(str);
for (int i = 0; i < len-1; i++) {
for (int j = i+1; j < len; j++) {
if (str[i] > str[j]) {
char temp = str[i];
str[i] = str[j];
str[j] = temp;
}
}
}
}
// 哈希函数
unsigned int hash(char* key) {
unsigned int val = 0;
for (int i = 0; key[i]; i++)
val += key[i];
return val % HASH_SIZE;
}
// 把单词插入哈希表
void insert(char* word) {
char key[MAX_LEN];
strcpy(key, word);
sortStr(key); // 排序生成 key
int idx = hash(key);
Node* p = hashTable[idx];
// 找是否已有 key
while (p != NULL && strcmp(p->key, key) != 0)
p = p->next;
if (p != NULL) {
// 已有分组,加入单词
strcpy(p->words[p->count++], word);
} else {
// 新建分组
Node* newNode = (Node*)malloc(sizeof(Node));
strcpy(newNode->key, key);
strcpy(newNode->words[0], word);
newNode->count = 1;
newNode->next = hashTable[idx];
hashTable[idx] = newNode;
}
}
// 输出所有变位词分组
void printAnagrams() {
printf("\n==== 变位词集合 ====\n");
for (int i = 0; i < HASH_SIZE; i++) {
Node* p = hashTable[i];
while (p != NULL) {
if (p->count >= 1) {
for (int j = 0; j < p->count; j++)
printf("%s ", p->words[j]);
printf("\n");
}
p = p->next;
}
}
}
int main() {
// 测试单词
char words[][MAX_LEN] = {
"eat", "tea", "ate",
"cat", "act",
"hello", "world",
"listen", "silent"
};
int n = sizeof(words) / sizeof(words[0]);
// 插入哈希表
for (int i = 0; i < n; i++)
insert(words[i]);
// 输出结果
printAnagrams();
return 0;
}