原教程适用于基础算法薄弱者(附上教程链接):https://github.com/datawhalechina/base-llm
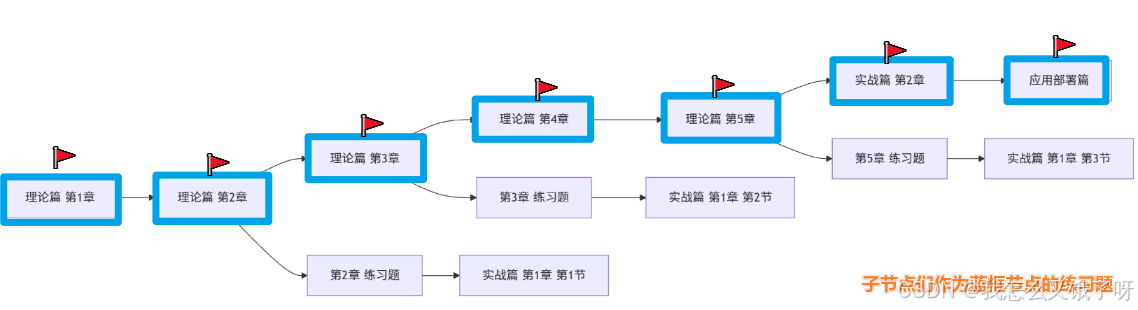
学习安排如下图所示:

学习顺序为蓝色节点,本节学习文本表示与词向量
分词 的任务,是把连续的文本序列切分成具有独立语义的基本单元(即"词"或"词元")。对于英文等天然有空格作为分隔符的语言,分词相对简单。但对于中文、日文、泰文等语言,文本是连续的字符流,词之间没有明确的边界。例如,对于开哥的"给阿姨倒一杯卡布奇诺",计算机需要依据算法将其正确地切分为 ["给", "阿姨", "倒", "一杯", "卡布奇诺"]
一、问题意识:为什么需要分布式表示?
在NLP的早期实践中,我们面临一个核心矛盾:计算机理解的是数字,人类使用的是符号。
One-Hot编码的维度灾难: 假设词汇表大小为 ∣V∣=100,000 (中文常见规模),每个词被表示为: vi=0,0,...,1,...,0∈R∣V∣
核心缺陷:
-
稀疏性:有效信息密度极低,存储与计算效率差
-
语义鸿沟:任意两个词的向量正交,vi⋅vj=0 (当 i≠j ),无法表达语义关联
-
组合爆炸:无法处理未登录词
二、中文分词工程实践常用到的分词技术
分词的必要性与挑战
中文NLP的首要障碍:中文没有天然的分隔符。英文"Natural Language Processing"天然有空格,而"自然语言处理"需要算法切分。
分词歧义:
-
"南京市长江大桥" → 南京/市/长江/大桥 或 南京市/长江/大桥
-
"研究生命" → 研究/生命 或 研究生/命
**jieba**是目前流行的 Python 中文分词库之一,对初学者较为友好,可以使用如下 pip 命令安装。
python
#安装jieba库
pip install jieba
#验证是否安装成功
pip show jieba
#Gensim库安装,后续训练数据集需要用到,一块安装了
pip install gensim

基于DAG的最短路径分词
构建DAG: 对于句子 S=c1c2...cn ,构建图 G=(V,E) ,其中边 (i,j) 存在当且仅当子串 ci+1...cj 在词典中。
动态规划求解: 设 dpi 为从位置 i 到句末的最大概率对数:
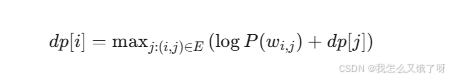
python
import jieba
from collections import defaultdict
# 基础分词
text = "自然语言处理是人工智能的核心技术之一"
words = jieba.lcut(text)
print(words)
# ['自然语言', '处理', '是', '人工智能', '的', '核心', '技术', '之一']
# 查看DAG构建过程(源码级理解)
def build_dag(sentence, word_freq):
"""手动实现DAG构建逻辑"""
DAG = defaultdict(list)
N = len(sentence)
for k in range(N):
i = k
frag = sentence[k]
while i < N and frag in word_freq:
if word_freq[frag]:
DAG[k].append(i)
i += 1
frag = sentence[k:i+1]
if not DAG[k]:
DAG[k].append(k)
return DAG
# 自定义词典干预
jieba.add_word('大语言模型', freq=1000, tag='n')
jieba.load_userdict('custom_dict.txt') # 批量加载
HMM新词发现
模型定义:
-
隐状态集合 S={B,M,E,S} (Begin, Middle, End, Single)
-
观测序列 O=c1c2...cn (字符序列)
-
目标:求最优状态序列 Q∗=argmaxQP(Q∣O)
python
import jieba.posseg as pseg
# HMM模式(适合未登录词较多的场景)
text = "李华考上了清华大学"
words = pseg.cut(text, HMM=True)
for word, flag in words:
print(f"{word}: {flag}")
# 李华: nr(人名) 考上: v 了: ul 清华大学: nt(机构名)
python
# 并行分词(多核加速)
jieba.enable_parallel(4)
# 预加载词典(避免运行时IO)
jieba.initialize() # 手动触发词典加载
# Tokenizer复用(减少对象创建开销)
tokenizer = jieba.Tokenizer(dictionary=None)
tokenizer.add_word('领域术语')从离散到连续:词向量的数学本质
词嵌入是将词汇映射到低维连续向量空间的函数:
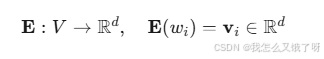
其中 d≪∣V∣ (通常 d∈50,300 ),且要求:
-
语义相似性保持:sim(Wi,Wj) ≈ Vi⋅Vj
-
语义关系类比:Vking − Vman + Vwoman ≈ Vqueen
矩阵分解视角:从LSA到Word2Vec
LSA(潜在语义分析)

从NNLM到Word2Vec
在NNLM基础上做了两个关键简化:
| 组件 | NNLM | Word2Vec |
|---|---|---|
| 隐藏层 | 非线性tanh | 直接去除 |
| 上下文 | 前n-1词 | 对称窗口 |
| 输出层 | 全连接+softmax | 分层Softmax/负采样 |
| 预测目标 | 概率分布 | 二分类(中心词-上下文词对) |
三、 Gensim 工程实战
python
from gensim.models import Word2Vec
import jieba
from collections import deque
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# ==================== 数据预处理 ====================
class SentenceIterator:
"""内存友好的句子迭代器(适合大规模语料)"""
def __init__(self, filepath):
self.filepath = filepath
def __iter__(self):
with open(self.filepath, 'r', encoding='utf-8') as f:
for line in f:
# Jieba分词 + 过滤单字词和停用词
words = [
w for w in jieba.lcut(line.strip())
if len(w) > 1 and w not in stop_words
]
if len(words) > 3: # 过滤过短句子
yield words
# ==================== 模型训练 ====================
def train_word2vec(corpus_path, model_path):
sentences = SentenceIterator(corpus_path)
model = Word2Vec(
sentences=sentences,
vector_size=256, # 嵌入维度(经验:100-300)
window=5, # 上下文窗口大小
min_count=5, # 低频词过滤阈值
workers=8, # 并行线程数
sg=1, # 1=Skip-gram, 0=CBOW
negative=15, # 负采样数
ns_exponent=0.75, # 负采样分布指数
sample=1e-5, # 高频词降采样
epochs=10, # 迭代轮数
compute_loss=True # 记录训练损失
)
model.save(model_path)
return model
# ==================== 模型评估 ====================
def evaluate_model(model):
# 1. 相似词查询
similar_words = model.wv.most_similar('人工智能', topn=10)
print("相似词:", similar_words)
# 2. 类比推理: 国王 - 男人 + 女人 = 女王
result = model.wv.most_similar(
positive=['女人', '国王'],
negative=['男人'],
topn=1
)
print("类比结果:", result)
# 3. 词向量运算
vec = model.wv['深度学习'] - model.wv['神经网络'] + model.wv['图像']
similar = model.wv.most_similar([vec], topn=5)
print("向量运算结果:", similar)
# 4. 计算词对相似度
similarity = model.wv.similarity('自然语言处理', 'NLP')
print(f"相似度: {similarity:.4f}")从静态到动态:一词多义问题
Word2Vec的局限在于静态向量:每个词只有单一表示,无法区分"bank"(银行/河岸)的不同含义。
| 方法 | 核心思想 | 代表模型 |
|---|---|---|
| 基于主题 | 主题分布影响词向量 | LDA2Vec |
| 基于上下文 | 动态调整词向量 | ELMo, BERT |
| 基于子词 | 字符级组合 | FastText |
技术选型矩阵
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 资源受限(移动端) | Word2Vec + 量化 | 轻量、快速 |
| 多语言/形态丰富 | FastText | 子词信息、OOV处理 |
| 一词多义敏感 | ELMo/BERT | 上下文动态表示 |
| 领域适配 | 预训练+微调 | 迁移学习 |
| 实时推理 | ONNX/TensorRT加速 | 工程部署 |
与前期知识的连接
-
ANN基础:Word2Vec的投影层+隐藏层就是浅层神经网络,理解反向传播有助于调参
-
优化理论 :负采样本质是噪声对比估计,属于自监督学习的早期实践
-
RNN/LSTM:为理解ELMo的双向语言模型铺垫
-
Transformer:BERT的架构基础,将在后续笔记详述
核心认知
-
表示学习即压缩 :从 ∣V∣ 维稀疏向量到 d 维稠密向量,本质是有损压缩保留语义信息
-
自监督的雏形:Word2Vec利用"上下文预测"构造监督信号,无需人工标注,这是现代大模型预训练的思想源头
-
局部 vs 全局:Word2Vec是局部上下文窗口,LSA是全局共现统计,GloVe(未展开)试图融合两者
推荐延伸阅读与练习
论文精读:
1 "Efficient Estimation of Word Representations in Vector Space" (2013)
2 "Distributed Representations of Words and Phrases and their Compositionality" (2013) ------ 负采样与分层Softmax
3 "Enriching Word Vectors with Subword Information" (2016) ------ FastText