📊 机器学习启航:从数据直觉到模型构建的第一块基石
前言 :
很多人一听到"机器学习",脑海中浮现的往往是复杂的数学公式、晦涩的神经网络图,或者是科幻电影里觉醒的机器人。但如果你刚学完机器学习的基础章节,你会发现,它的核心其实非常朴素:教计算机像人类一样,从经验(数据)中学习规律,而不是死记硬背规则。
本文是"机器学习实战四部曲"的第一篇。我们将基于课程思维导图的核心脉络,剥离掉那些让人头大的理论外壳,用最直白的中文和直观的代码,带你走进机器学习的真实世界,理解它到底在做什么,以及我们该如何迈出第一步。
文章目录
- [📊 机器学习启航:从数据直觉到模型构建的第一块基石](#📊 机器学习启航:从数据直觉到模型构建的第一块基石)
-
- [🌱 一、什么是机器学习?告别"硬编码"时代](#🌱 一、什么是机器学习?告别“硬编码”时代)
- [🗺️ 二、机器学习的三大门派:监督、无监督与强化](#🗺️ 二、机器学习的三大门派:监督、无监督与强化)
-
- [1. 监督学习 (Supervised Learning) ------ "有老师带着学"](#1. 监督学习 (Supervised Learning) —— “有老师带着学”)
- [2. 无监督学习 (Unsupervised Learning) ------ "自学成才"](#2. 无监督学习 (Unsupervised Learning) —— “自学成才”)
- [3. 强化学习 (Reinforcement Learning) ------ "在试错中成长"](#3. 强化学习 (Reinforcement Learning) —— “在试错中成长”)
- [📊 三大门派核心对比一览表](#📊 三大门派核心对比一览表)
- [🛠️ 三、核心代表深度解析:线性回归 (Linear Regression)](#🛠️ 三、核心代表深度解析:线性回归 (Linear Regression))
-
- [1. 核心原理:寻找最佳拟合线](#1. 核心原理:寻找最佳拟合线)
- [2. 灵魂拷问:如何定义"最好"?------ 损失函数 (Loss Function)](#2. 灵魂拷问:如何定义“最好”?—— 损失函数 (Loss Function))
- [3. 求解方法:梯度下降 (Gradient Descent)](#3. 求解方法:梯度下降 (Gradient Descent))
- [4. 线性回归的"三大假设"与局限性](#4. 线性回归的“三大假设”与局限性)
- [5. 代码实战:不仅会调包,更要懂过程](#5. 代码实战:不仅会调包,更要懂过程)
- [🛠️ 四、实战演练:用 Python 体验"线性回归"](#🛠️ 四、实战演练:用 Python 体验“线性回归”)
-
- [1. 准备数据](#1. 准备数据)
- [2. 选择并训练模型](#2. 选择并训练模型)
- [3. 进行预测与可视化](#3. 进行预测与可视化)
- [⚙️ 五、机器学习的标准工作流](#⚙️ 五、机器学习的标准工作流)
- [🔮 下一篇预告:数据的艺术](#🔮 下一篇预告:数据的艺术)
🌱 一、什么是机器学习?告别"硬编码"时代
在传统编程中,我们是如何解决问题的?
比如,我们要写一个程序来识别垃圾邮件。传统的做法是:程序员需要绞尽脑汁列出所有规则------"如果邮件包含'中奖'两个字,标记为垃圾"、"如果发件人不在通讯录,标记为可疑"......
这种写法有两个致命弱点:
- 规则永远写不完:骗子的手段层出不穷,你今天加了规则,明天他们就能绕过。
- 维护成本极高:每出现一种新套路,你就得修改代码。
机器学习(Machine Learning) 彻底颠覆了这个逻辑。
我们不再告诉计算机"怎么做"(规则),而是给它看"做过什么"(数据)。
- 输入:成千上万封已经标记好"是垃圾"或"不是垃圾"的邮件。
- 过程:算法自动在这些数据中寻找模式(比如:发现包含"中奖"且带有感叹号的邮件,99% 都是垃圾邮件)。
- 输出 :一个模型(Model)。这个模型本质上就是一套数学参数,它能对新来的邮件做出判断。
一句话总结 :传统编程是
规则 + 数据 = 答案;机器学习是数据 + 答案 = 规则(模型)。
🗺️ 二、机器学习的三大门派:监督、无监督与强化
根据我们给计算机提供的"教材"不同,机器学习主要分为三大流派。这也是我们后续几篇博客将深入探讨的核心地图。
1. 监督学习 (Supervised Learning) ------ "有老师带着学"
这是目前应用最广泛、最成熟的领域。
- 特点 :我们的训练数据既有输入(特征) ,也有对应的正确答案(标签)。
- 场景 :
- 回归 (Regression) :预测连续数值。比如:根据房屋面积、地段预测房价。
- 分类 (Classification) :预测离散类别。比如:根据肿瘤大小预测是良性 还是恶性。
- 核心逻辑:模型不断猜测,然后对比正确答案,计算误差,再调整自己,直到误差最小。
2. 无监督学习 (Unsupervised Learning) ------ "自学成才"
- 特点 :数据只有输入 ,没有标签。计算机需要自己去发现数据内部的结构。
- 场景 :
- 聚类 (Clustering):把相似的东西分堆。比如:电商根据用户的购买习惯,自动将用户分成"价格敏感型"、"品质追求型"等群体,而无需人工定义这些群体。
- 降维 (Dimensionality Reduction):在保留核心信息的前提下,压缩数据复杂度,方便可视化或加速计算。
- 核心逻辑:寻找数据中的共性,"物以类聚,人以群分"。
3. 强化学习 (Reinforcement Learning) ------ "在试错中成长"
- 特点:没有现成的数据集。智能体(Agent)通过与环境交互,做对了给奖励,做错了给惩罚。
- 场景:AlphaGo 下围棋、机器人学走路、自动驾驶决策。
- 核心逻辑:最大化累积奖励。这部分通常较难,我们在本系列基础篇中会略作提及,重点放在前两者。
📊 三大门派核心对比一览表
为了让你更直观地理解这三者的区别,我整理了下面这张对比表:
| 维度 | 监督学习 (Supervised) | 无监督学习 (Unsupervised) | 强化学习 (Reinforcement) |
|---|---|---|---|
| 核心比喻 | 有老师辅导(给题也给答案) | 自学成才(只给题,没答案) | 游戏闯关(做对加分,做错扣分) |
| 数据要求 | 需要带标签的数据(Input + Label) | 只需要无标签数据(Input only) | 不需要静态数据集,需要环境交互 |
| 主要任务 | 回归 (预测数值)分类 (判断类别) | 聚类 (分组)降维 (压缩数据)关联规则 | 决策优化路径规划策略控制 |
| 典型算法 | 线性回归、逻辑回归支持向量机 (SVM)随机森林 | K-Means 聚类主成分分析 (PCA)Apriori | Q-LearningDeep Q-Network (DQN)Policy Gradient |
| 应用场景 | 房价预测、垃圾邮件过滤疾病诊断、信用评分 | 用户画像分群、新闻推荐异常检测、数据可视化 | 围棋 AI、机器人控制自动驾驶、股票交易策略 |
| 优点 | 目标明确,评估简单技术成熟,落地广泛 | 无需昂贵的人工标注能发现人类未知的模式 | 能解决长序列决策问题具备自我进化能力 |
| 缺点 | 依赖大量高质量标注数据无法处理未见过的新类别 | 结果难以量化评估聚类含义需人工解读 | 训练极慢,不稳定模拟环境构建困难 |
🛠️ 三、核心代表深度解析:线性回归 (Linear Regression)
在监督学习的回归任务中,线性回归 是绝对的"Hello World",也是理解所有复杂模型的基石。它不仅仅是画一条直线,更蕴含了机器学习的核心思想:通过最小化误差来寻找最佳参数。
1. 核心原理:寻找最佳拟合线
线性回归的目标是找到一个线性方程,能够最好地描述特征(X)与目标值(y)之间的关系。
-
一元线性回归公式 :
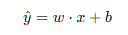
- y:预测值
- x:输入特征(如房屋面积)
- w (Weight/系数):斜率,表示特征对结果的影响程度(如:面积每增加1平米,房价涨多少)。
- b (Bias/截距):当特征为0时的基础值。
-
多元线性回归公式 (当有多个特征时):
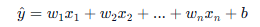
2. 灵魂拷问:如何定义"最好"?------ 损失函数 (Loss Function)
计算机不知道哪条线是"最好"的,我们需要一个数学指标来告诉它。这个指标就是损失函数 。
在线性回归中,最常用的是 均方误差 (MSE, Mean Squared Error)。
- 直观理解 :计算每个样本的真实值 与预测值之间的距离(残差),将其平方后求平均。
- 公式 :
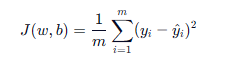
- m:样本数量
- y_i:真实值
- \hat{y}_i:预测值(括号里右边的y_i)
- 为什么要平方?
- 消除负号(距离不能为负)。
- 放大较大误差的影响(让模型更关注那些偏离很远的点)。
我们的目标 :找到一组 w 和 b,使得 J(w, b) 最小。
3. 求解方法:梯度下降 (Gradient Descent)
如何找到让损失最小的 w 和 b?想象你站在山上(损失函数的曲面),想要走到山谷最低点(最小误差):
- 看脚下:计算当前位置的坡度(梯度/导数)。
- 迈一步:沿着坡度最陡的方向向下走一步。
- 重复:不断重复,直到走到平地(收敛)。
- 学习率 (Learning Rate) :决定你每一步迈多大。
- 太大:可能直接跨过谷底,甚至越跑越高(不收敛)。
- 太小:下山速度极慢,耗时太久。
💡 专家视角 :
虽然
scikit-learn内部使用的是更高效的数学解法(正规方程或SVD),但理解梯度下降对于后续学习深度学习(神经网络全靠它训练)至关重要!
4. 线性回归的"三大假设"与局限性
线性回归虽好,但不是万能的。它建立在几个严格的假设之上,如果数据违背了这些假设,模型就会失效:
| 假设 | 含义 | 违背后果 |
|---|---|---|
| 线性关系 | 特征与目标之间必须是直线关系 | 如果数据是曲线(如抛物线),拟合效果会极差(欠拟合) |
| 独立性 | 样本之间相互独立 | 时间序列数据通常不满足,需特殊处理 |
| 同方差性 | 误差的波动幅度在整个数据范围内应保持一致 | 如果误差随数值增大而增大,预测置信度会降低 |
| 无多重共线性 | 特征之间不应高度相关 | 比如"房间数"和"总面积"高度相关,会导致模型不稳定,权重难以解释 |
5. 代码实战:不仅会调包,更要懂过程
让我们用代码完整复现上述逻辑,不仅调用模型,还要观察它的损失变化 和参数学习过程。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 1. 构造带有噪声的模拟数据 (模拟真实世界的不完美)
np.random.seed(42)
X = 2 * np.random.rand(100, 1) # 100个样本,1个特征
y = 4 + 3 * X + np.random.randn(100, 1) # 真实规律: y = 4 + 3x + 噪声
# 2. 初始化并训练模型
model = LinearRegression()
model.fit(X, y)
# 3. 获取学到的参数
w_learned = model.coef_[0][0]
b_learned = model.intercept_[0]
print(f"真实参数: w=3.00, b=4.00")
print(f"模型学到: w={w_learned:.2f}, b={b_learned:.2f}")
# 4. 进行预测
X_new = np.array([[0], [2]])
y_pred = model.predict(X_new)
# 5. 评估模型
y_train_pred = model.predict(X)
mse = mean_squared_error(y, y_train_pred)
r2 = r2_score(y, y_train_pred)
print(f"均方误差 (MSE): {mse:.4f}")
print(f"R² 得分 (拟合优度): {r2:.4f} (越接近1越好)")
# 6. 可视化:展示拟合线与残差
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='blue', alpha=0.6, label='样本数据')
plt.plot(X, model.predict(X), color='red', linewidth=2, label=f'拟合线: y={w_learned:.2f}x+{b_learned:.2f}')
# 绘制前10个样本的残差线 (直观展示误差)
for i in range(10):
plt.plot([X[i][0], X[i][0]], [y[i][0], model.predict(X)[i][0]], 'g--', alpha=0.5)
plt.title('线性回归:拟合线与残差示意图', fontsize=14)
plt.xlabel('特征 X')
plt.ylabel('目标 y')
plt.legend()
plt.grid(True, linestyle=':', alpha=0.6)
plt.show()🖼️ 运行结果解读:
- 参数接近真实值 :你会发现学到的 w w w 非常接近 3, b b b 非常接近 4,证明模型成功从噪声中提取了规律。
- 绿色虚线 :图中绿色的短虚线代表了残差(真实值与预测值的距离)。我们的目标就是让这些绿色线的长度平方和最小。
- R² 得分:如果得分为 0.75 左右,说明模型解释了约 75% 的数据波动,对于含噪声数据来说是不错的表现。
🛠️ 四、实战演练:用 Python 体验"线性回归"
光说不练假把式。让我们通过最简单的线性回归(Linear Regression) ,亲手构建第一个监督学习模型。
任务:假设我们有一组数据,记录了房屋的面积 x 和价格 y )。我们要训练一个模型,让它学会根据面积预测价格。
1. 准备数据
在现实中,数据往往杂乱无章。但在机器学习中,我们通常将其整理为特征矩阵 x 和目标向量 y 。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 设置绘图风格,让图片更好看
plt.style.use('seaborn-v0_8-whitegrid')
# 支持中文显示 (视运行环境而定,若乱码可注释掉或替换字体)
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 1. 构造模拟数据
# 假设房价 = 面积 * 0.5 + 随机波动
# X 是特征(面积),必须是二维数组 [[面积1], [面积2], ...]
X = np.array([[50], [60], [70], [80], [90], [100]])
# y 是标签(价格),一维数组即可
y = np.array([30, 36, 41, 48, 53, 60])
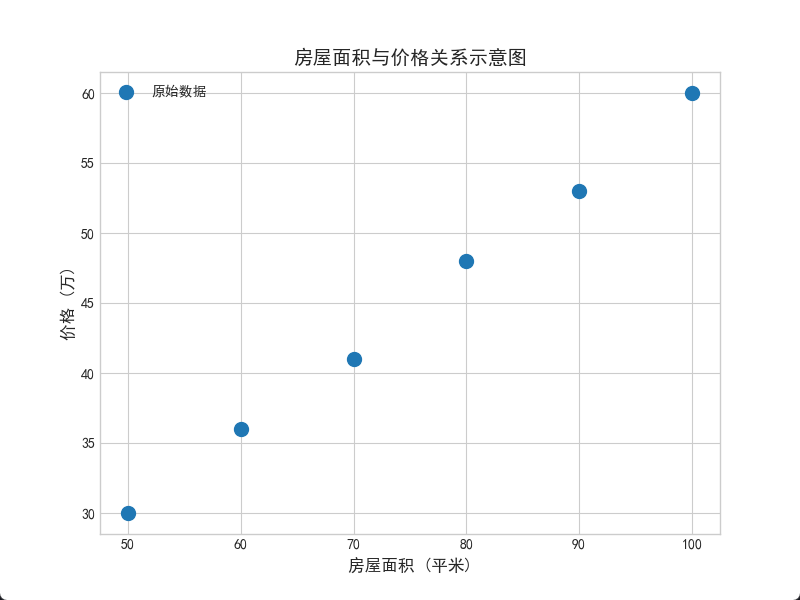
# 画个图看看数据长什么样
plt.figure(figsize=(8, 6))
plt.scatter(X, y, color='#1f77b4', s=100, label='原始数据', zorder=3)
plt.xlabel('房屋面积 (平米)', fontsize=12)
plt.ylabel('价格 (万)', fontsize=12)
plt.title('房屋面积与价格关系示意图', fontsize=14, fontweight='bold')
plt.legend()
plt.show()🖼️ 代码运行结果图示 1:原始数据分布
(下图展示了我们输入的 6 组数据点,可以看到它们大致呈一条直线上升的趋势)
2. 选择并训练模型
在 scikit-learn(Python 最著名的机器学习库)中,训练模型通常只需要三行代码:
- 实例化:选择一个算法。
- 拟合 (fit):让模型去学习数据中的规律。
- 预测 (predict):用学好的规律去猜新数据。
python
# 2. 初始化模型
# 这里我们选择最简单的线性回归模型
model = LinearRegression()
# 3. 训练模型 (Fit)
# 这一步就是机器学习的核心:算法在计算最佳的斜率(w)和截距(b)
# 使得直线 y = wx + b 尽可能贴近所有的蓝点
model.fit(X, y)
print("模型训练完成!")
print(f"学到的公式大致为:价格 = {model.coef_[0]:.2f} * 面积 + {model.intercept_:.2f}")控制台输出结果:
text
模型训练完成!
学到的公式大致为:价格 = 0.59 * 面积 + -0.10
解读:模型通过分析数据,发现面积每增加 1 平米,价格大约上涨 0.59 万。这就是它"学"到的规律。
3. 进行预测与可视化
现在,假如有一套 120 平米的房子,模型觉得它值多少钱?我们将把预测结果画出来。
python
# 4. 预测新数据
new_house_area = np.array([[120]])
predicted_price = model.predict(new_house_area)
print(f"预测 120 平米的房子价格为:{predicted_price[0]:.2f} 万")
# 5. 绘制最终结果图
plt.figure(figsize=(10, 6))
# 绘制原始训练数据
plt.scatter(X, y, color='#1f77b4', s=100, label='训练数据', zorder=3)
# 绘制模型拟合出的红线
# 为了线画得长一点,我们生成一组从 40 到 130 的连续数据
X_line = np.linspace(40, 130, 100).reshape(-1, 1)
y_line = model.predict(X_line)
plt.plot(X_line, y_line, color='#d62728', linewidth=2, label='模型拟合线 (规律)', zorder=2)
# 绘制我们对 120 平米的预测点 (绿色星星)
plt.scatter(new_house_area, predicted_price, color='#2ca02c', s=200, marker='*', edgecolors='black', label=f'预测点 (120㎡: {predicted_price[0]:.2f}万)', zorder=4)
# 添加标注和装饰
plt.xlabel('房屋面积 (平米)', fontsize=12)
plt.ylabel('价格 (万)', fontsize=12)
plt.title('机器学习实战:线性回归预测房价', fontsize=14, fontweight='bold')
plt.legend(fontsize=10)
plt.grid(True, linestyle='--', alpha=0.6)
# 显示图表
plt.show()🖼️ 代码运行结果图示 2:模型拟合与预测
(运行上述代码后,你将看到如下效果的图片)
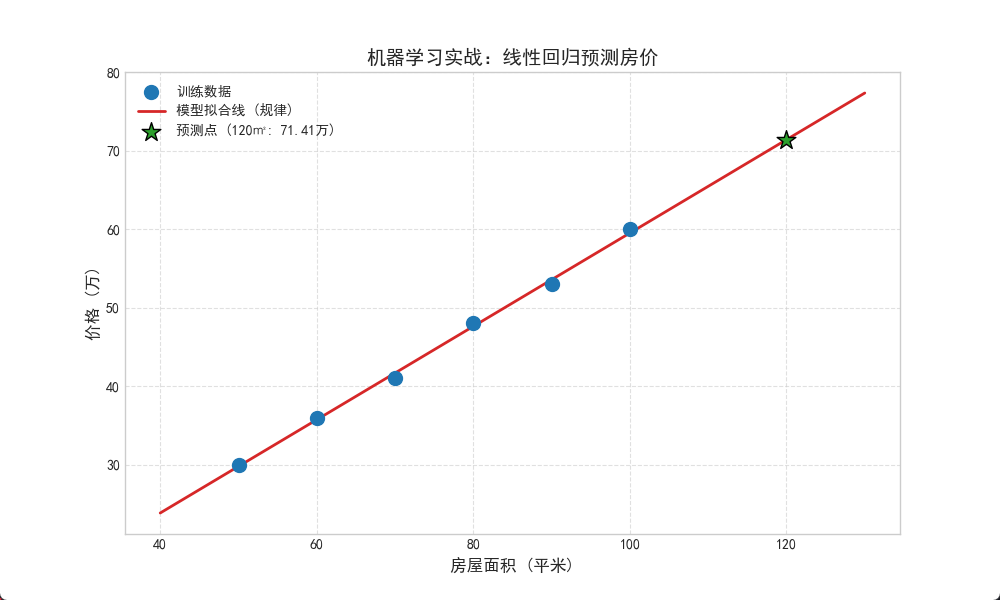
看着那条红色的线穿过蓝色的点,并精准地延伸指向绿色的星星,这就是机器学习的魅力:从有限的已知,推导未知的未来。
⚙️ 五、机器学习的标准工作流
通过上面的小例子,我们可以总结出机器学习项目的标准"五步走"流程。这也是我们后续三篇博客将反复强化的框架:
-
数据收集与预处理 (Data Preparation)
- 数据是燃料。如果数据脏乱差(缺失值、异常值、格式不统一),模型再高级也跑不起来(Garbage In, Garbage Out)。
- 关键点:清洗、归一化、特征选择。
-
模型选择 (Model Selection)
- 根据问题类型(是预测数值还是分类?)选择合适的算法。
- 关键点:不要盲目追求复杂模型,简单有效往往最好。
-
模型训练 (Training)
- 将数据喂给算法,让它调整内部参数,最小化误差。
- 关键点:划分训练集和测试集,防止"死记硬背"。
-
模型评估 (Evaluation)
- 模型好不好,不能光看训练时的表现,要用没见过的数据(测试集)来考考它。
- 关键点:准确率、召回率、均方误差等指标。
-
模型部署与应用 (Deployment)
- 将训练好的模型保存下来,集成到实际软件中,服务真实用户。
🔮 下一篇预告:数据的艺术
在第一篇中,我们建立了宏观认知,并跑通了第一个模型。但你可能会问:
- 如果数据里有缺失值怎么办?
- 为什么有时候模型在训练集表现完美,一到实际应用就垮掉(过拟合)?
- 如何把文字、图片这些非数字信息变成机器能懂的数字?
这些问题,都指向了机器学习中最耗时、也最关键的一环------数据预处理与特征工程 。
在第二篇博客中,我们将深入数据的"后厨",学习如何清洗脏数据、如何处理不平衡样本,以及如何提取出真正有价值的特征。毕竟,在机器学习界流传着一句话:"数据和特征决定了模型的上限,而算法只是在逼近这个上限。"
准备好了吗?让我们从"调参侠"进阶为"数据炼金术师"。