鱼眼镜头优势
鱼眼镜头的核心优点集中在超广视角、独特视觉效果、实用拍摄优势三个维度,既适配专业创作的艺术表达,也能解决常规镜头无法应对的拍摄难题,是视角最广的镜头类型,对角线鱼眼视角可达 120°~180°,圆形鱼眼甚至能达到 220° 左右,远超广角 /
超广角镜头(常规超广角多为 100° 以内)。
1 KD 参数矫正
如下所示俯视图,对会议室的某一部分,如图所示对会议室门口做AI算法分析,需要将走进来的人记录,录像,一般我们想到的是标定算法,使用kd参数来做标定,计算kd 需要标定,下面介绍标定算法。

普通k,d参数标定
以下是广角原图

如下图对图像进行KD参数标定以后矫正图像,使用标定
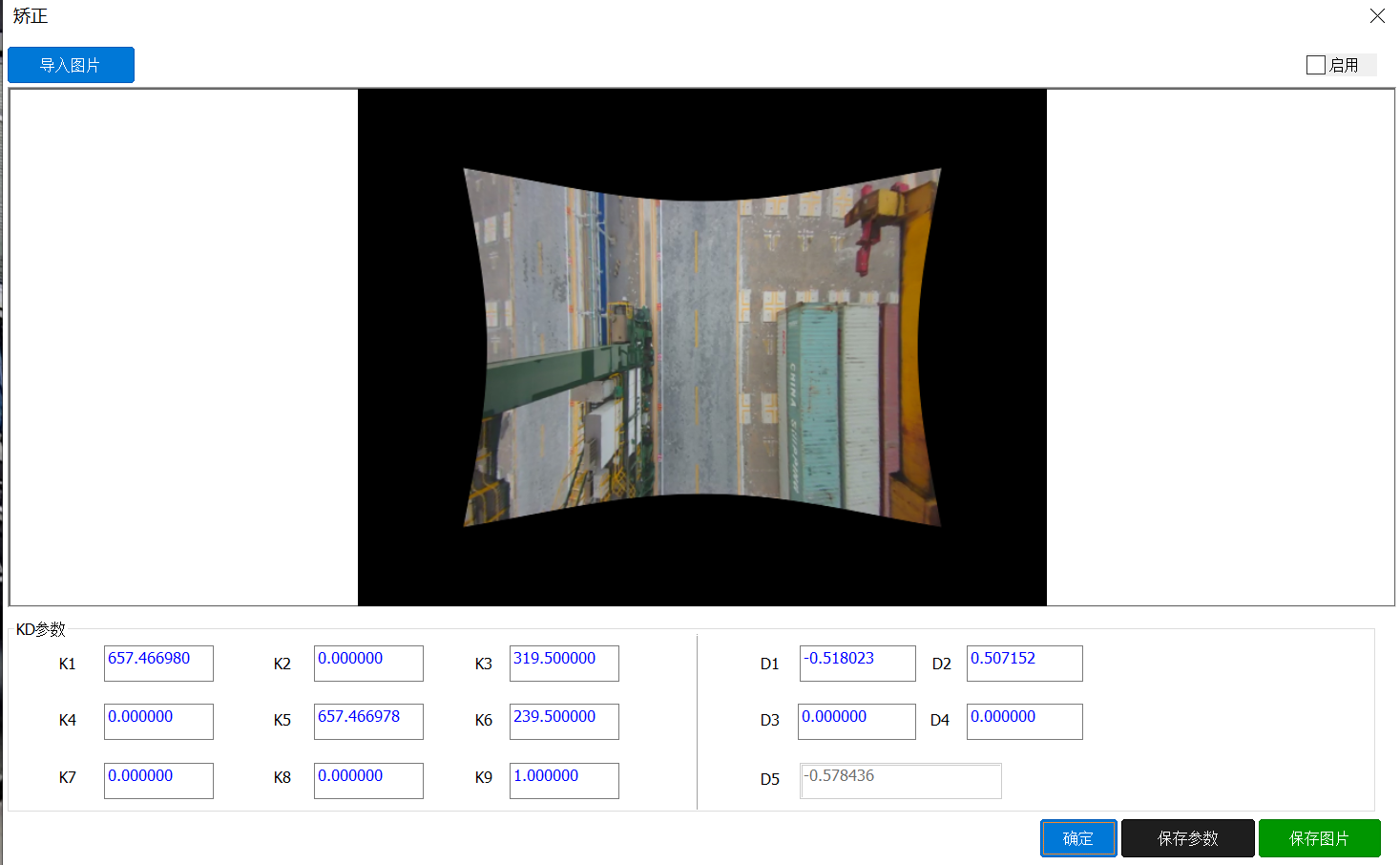
如下图所示,鱼眼图像使用kd矫正,问题很多:
1 明显矫正还没有到位 ,反复调整kd,非常耗时耗力
2 倾斜无法修复
3 无法改变视角

python 示例
py
import cv2
import numpy as np
def fisheye_correction(image_path, K, D, balance=1.0, dim2=None, dim3=None):
"""
鱼眼相机畸变矫正(KD参数)
:param image_path: 待矫正图片路径
:param K: 相机内参矩阵 (3x3)
:param D: 畸变参数 (1x4, 对应k1,k2,k3,k4)
:param balance: 矫正后图像裁剪比例(0-1,1保留更多像素)
:param dim2: 图像尺寸(宽,高),默认自动读取
:param dim3: 输出图像尺寸,默认和输入一致
:return: 矫正后的图像
"""
# 读取原始图像
img = cv2.imread(image_path)
if img is None:
raise ValueError("图片读取失败,请检查路径是否正确!")
# 获取图像尺寸
dim1 = img.shape[:2][::-1] # 原始尺寸 (宽, 高)
if not dim2:
dim2 = dim1
if not dim3:
dim3 = dim1
# 计算矫正后的相机内参矩阵(平衡裁剪比例)
scaled_K = K * dim1[0] / dim2[0] # 缩放内参到图像尺寸
scaled_K[2][2] = 1.0 # 确保最后一位为1
# 计算新的相机内参矩阵(调整视场角)
new_K = cv2.fisheye.estimateNewCameraMatrixForUndistortRectify(
scaled_K, D, dim3, np.eye(3), balance=balance
)
# 计算畸变矫正的映射表(核心步骤)
map1, map2 = cv2.fisheye.initUndistortRectifyMap(
scaled_K, D, np.eye(3), new_K, dim3, cv2.CV_16SC2
)
# 应用映射表完成矫正
corrected_img = cv2.remap(
img, map1, map2, interpolation=cv2.INTER_LINEAR, borderMode=cv2.BORDER_CONSTANT
)
return corrected_img
# ---------------------- 示例:运行矫正 ----------------------
if __name__ == "__main__":
# **************************
# 关键参数(需替换为你的相机标定结果)
# **************************
# 相机内参矩阵 K (3x3),示例值(需根据实际标定修改)
K = np.array([
[800.0, 0.0, 640.0], # fx, 0, cx
[0.0, 800.0, 360.0], # 0, fy, cy
[0.0, 0.0, 1.0] # 0, 0, 1
])
# 鱼眼畸变参数 D (1x4),对应k1,k2,k3,k4(示例值,需替换)
D = np.array([[-0.28340811, 0.07395907, -0.00019359, 0.00011042]])
# 待矫正图片路径(替换为你的图片路径)
img_path = "fisheye_image.jpg"
try:
# 执行矫正
corrected_img = fisheye_correction(img_path, K, D, balance=1.0)
# 显示原始图和矫正图
original_img = cv2.imread(img_path)
cv2.imshow("Original Fisheye Image", original_img)
cv2.imshow("Corrected Image", corrected_img)
# 保存矫正后的图片
cv2.imwrite("corrected_image.jpg", corrected_img)
# 等待按键后关闭窗口
cv2.waitKey(0)
cv2.destroyAllWindows()
except Exception as e:
print(f"矫正失败:{e}")下面我们使用c++来做
c
#include <opencv2/opencv.hpp>
#include <opencv2/fisheye.hpp>
#include <iostream>
/**
* @brief 鱼眼相机畸变矫正(KD参数)
* @param image_path 待矫正图片路径
* @param K 相机内参矩阵 (3x3)
* @param D 畸变参数 (1x4, 对应k1,k2,k3,k4)
* @param balance 矫正后图像裁剪比例(0-1,1保留更多像素)
* @param dim2 图像尺寸(宽,高),默认自动读取
* @param dim3 输出图像尺寸,默认和输入一致
* @return 矫正后的图像
*/
cv::Mat fisheyeCorrection(const std::string& image_path,
const cv::Mat& K,
const cv::Mat& D,
double balance = 1.0,
cv::Size dim2 = cv::Size(),
cv::Size dim3 = cv::Size())
{
// 读取原始图像
cv::Mat img = cv::imread(image_path);
if (img.empty())
{
throw std::runtime_error("图片读取失败,请检查路径是否正确!");
}
// 获取图像尺寸
cv::Size dim1 = img.size(); // 原始尺寸 (宽, 高)
if (dim2.empty()) dim2 = dim1;
if (dim3.empty()) dim3 = dim1;
// 计算矫正后的相机内参矩阵(平衡裁剪比例)
cv::Mat scaled_K = K.clone();
// 缩放内参到图像尺寸
scaled_K.at<double>(0, 0) *= dim1.width / dim2.width;
scaled_K.at<double>(1, 1) *= dim1.height / dim2.height;
scaled_K.at<double>(0, 2) *= dim1.width / dim2.width;
scaled_K.at<double>(1, 2) *= dim1.height / dim2.height;
scaled_K.at<double>(2, 2) = 1.0; // 确保最后一位为1
// 计算新的相机内参矩阵(调整视场角)
cv::Mat new_K;
cv::fisheye::estimateNewCameraMatrixForUndistortRectify(
scaled_K, D, dim3, cv::Mat::eye(3, 3, CV_64F), new_K, balance
);
// 计算畸变矫正的映射表(核心步骤)
cv::Mat map1, map2;
cv::fisheye::initUndistortRectifyMap(
scaled_K, D, cv::Mat::eye(3, 3, CV_64F), new_K, dim3,
CV_16SC2, map1, map2
);
// 应用映射表完成矫正
cv::Mat corrected_img;
cv::remap(
img, corrected_img, map1, map2,
cv::INTER_LINEAR, cv::BORDER_CONSTANT
);
return corrected_img;
}
int main()
{
try
{
// **************************
// 关键参数(需替换为你的相机标定结果)
// **************************
// 相机内参矩阵 K (3x3),示例值(需根据实际标定修改)
cv::Mat K = (cv::Mat_<double>(3, 3) <<
800.0, 0.0, 640.0, // fx, 0, cx
0.0, 800.0, 360.0, // 0, fy, cy
0.0, 0.0, 1.0); // 0, 0, 1
// 鱼眼畸变参数 D (1x4),对应k1,k2,k3,k4(示例值,需替换)
cv::Mat D = (cv::Mat_<double>(1, 4) << -0.28340811, 0.07395907, -0.00019359, 0.00011042);
// 待矫正图片路径(替换为你的图片路径)
std::string img_path = "fisheye_image.jpg";
// 执行矫正
cv::Mat corrected_img = fisheyeCorrection(img_path, K, D, 1.0);
// 显示原始图和矫正图
cv::Mat original_img = cv::imread(img_path);
cv::imshow("Original Fisheye Image", original_img);
cv::imshow("Corrected Image", corrected_img);
// 保存矫正后的图片
cv::imwrite("corrected_image.jpg", corrected_img);
// 等待按键后关闭窗口
cv::waitKey(0);
cv::destroyAllWindows();
}
catch (const std::exception& e)
{
std::cerr << "矫正失败:" << e.what() << std::endl;
return -1;
}
return 0;
}kd内外参矫正的问题
我来说kd矫正的问题:
1 边缘像素拉深严重 ,尤其是鱼眼图像
2 经纬度同时矫正 ,实际上纬度需要弧度,不然无法拼接,也就是我们只需要经度矫正
KD 参数矫正在鱼眼相机属纯径向畸变模型,核心只对鱼眼镜头的桶形径向畸变做矫正,完全未考虑其他畸变类型,而实际硬件中镜头畸变是复合的,不同的角度,俯仰,z轴旋转,kd参数矫正是不合适的。
AI计算
我们需要对以下红色标定的地方进行AI算法,也就是进入会议室的门口,进行人的侦测,如何做?
如果使用kd矫正,图像也是颠倒的,写个算法倒过来,图像
图像处理
使用元镜像的鱼眼矫正,上海元镜像的鱼眼矫正是一个非常专业的工具,不需要标定算法,直接在三维空间做处理,改变俯仰关系,改变视图视角,直接变换到站在图像中心,把镜头中心切换到人的位置去看周围,事实上,所有的图像像素信息都包含着复杂的空间关系,我们通过计算可以将空间变换成我们需要的样子
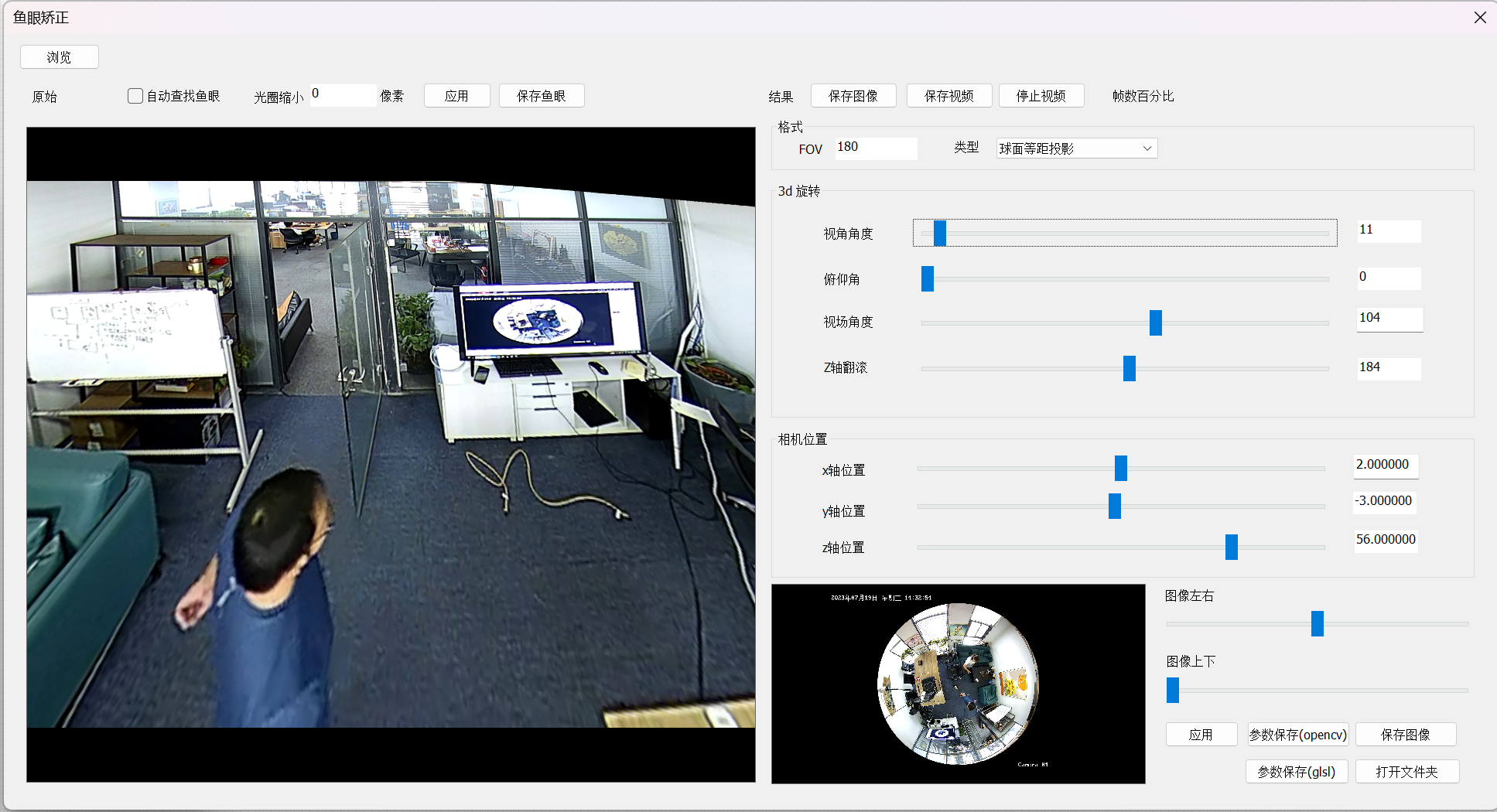
网格调整,属于APAP算法,使用三次样条插值算法

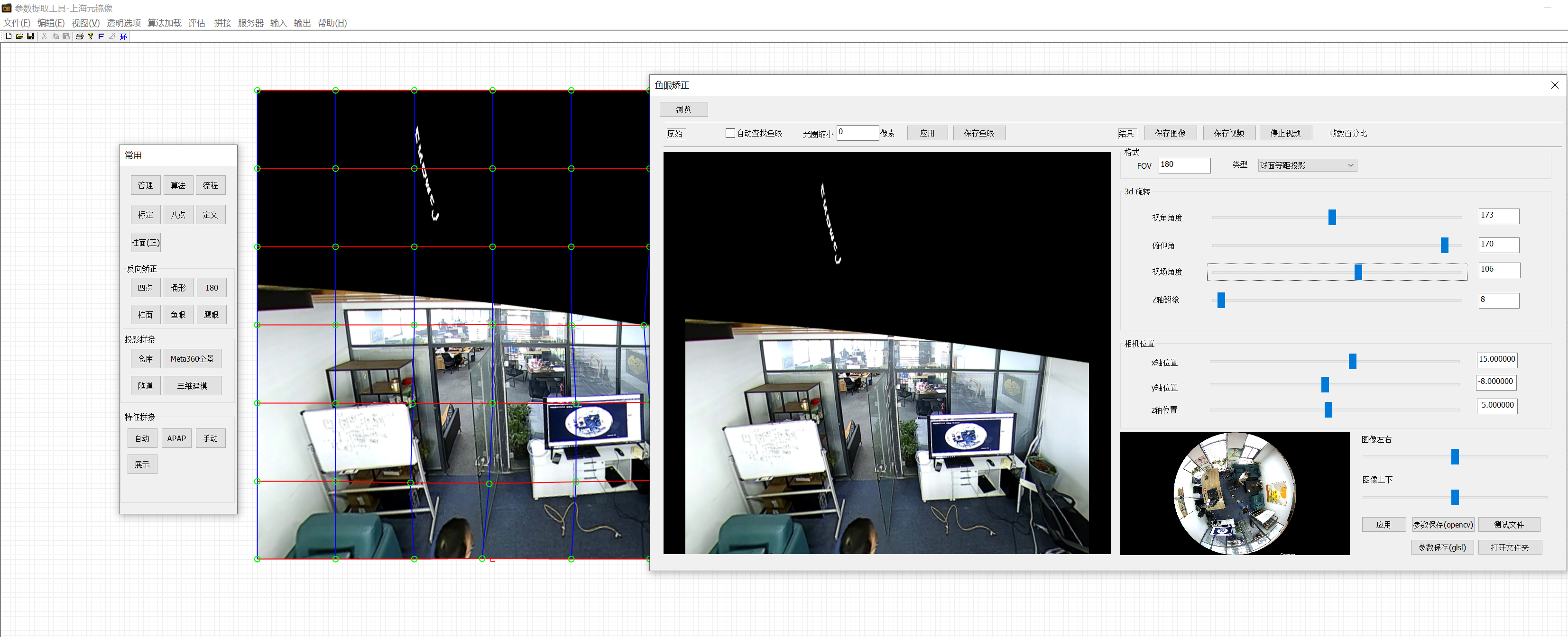
效果结果图

现在以图像中人的位置视角去看门,这样就可以提供给AI分析的比较还原的视频图像。
拼接
目的:将两个鱼眼图像拼接,同时做AI,如果鱼眼直接做AI,需要做两个,需要做reid算法,如何做呢,我们首先拼接两个图像,使用上海元镜像的矫正工具。
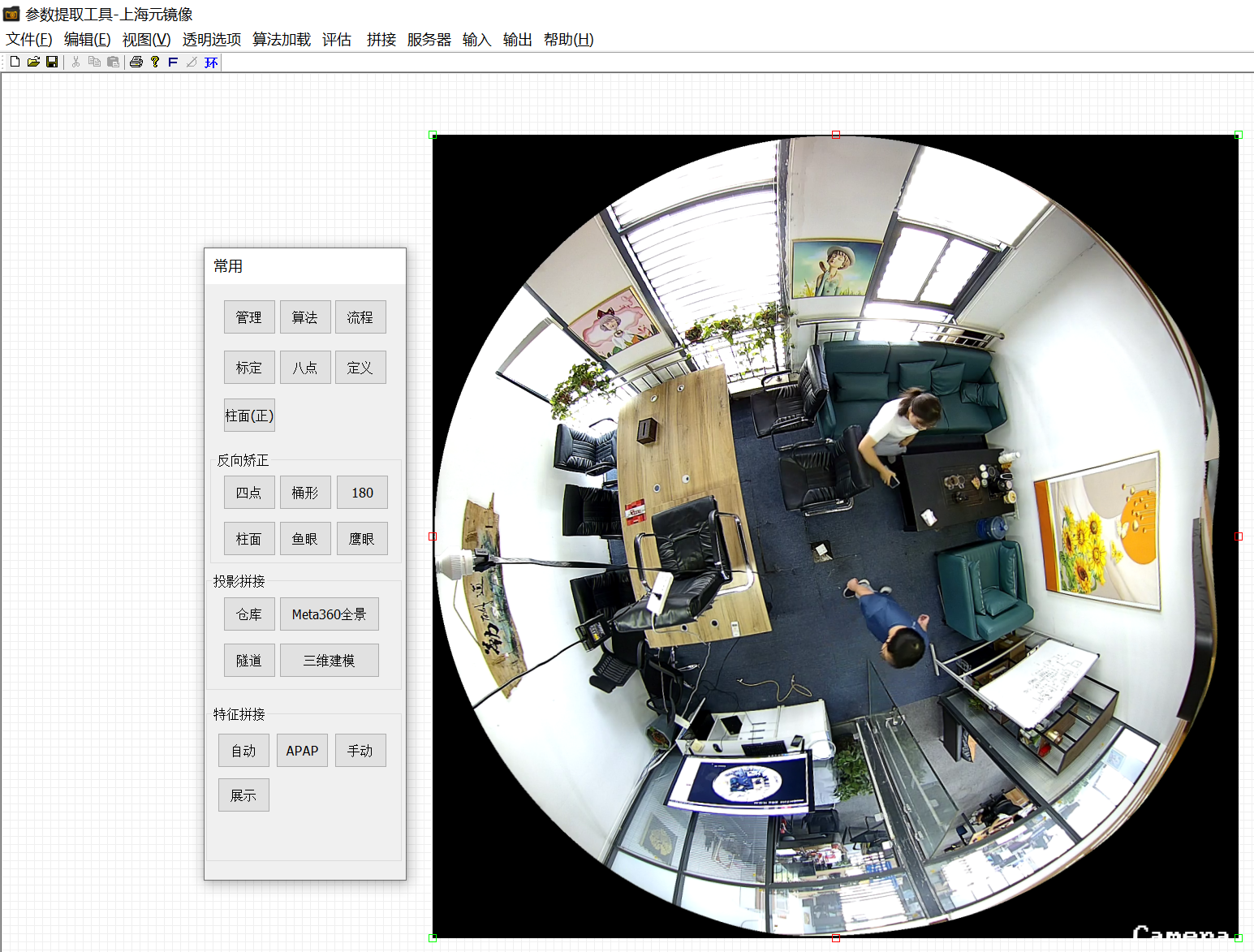

等距矫正
使用鱼眼矫正中的等距矫正进行图像变换
等距性: 仅经度方向保持等间隔、无拉伸,纬度方向从赤道向两极逐渐拉伸(北极/南极点拉伸为一条线)
弧度优先:所有三角函数计算(arctan2/arcsin)均需用弧度
等距鱼眼的核心投影公式(无畸变,像素距离与视场角线性相关)
1 计算鱼眼像素到主点的归一化极坐标
Δu=u−u0,Δv=v−v0
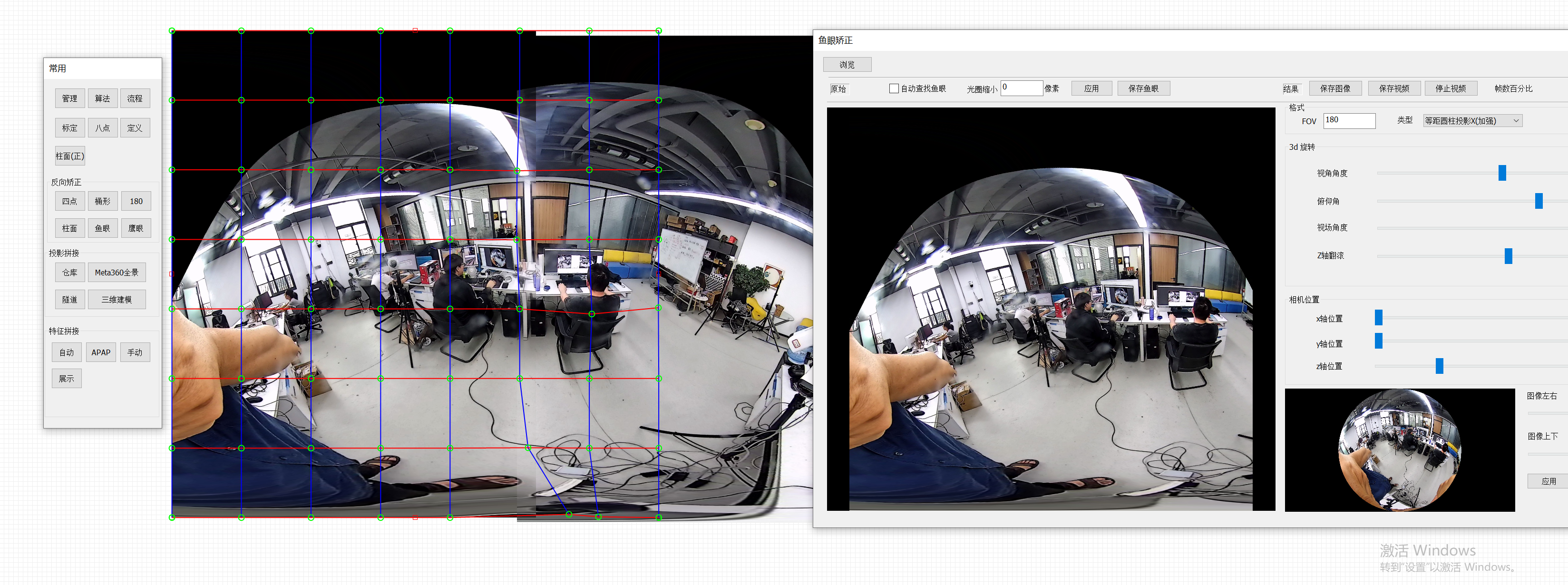
再使用apap算法,进行两个图像的拼接
两个图像完全融合在一起,图像不正确,纬度没有矫正,使用元镜像工具继续矫正,我初略进行矫正,没有花时间,就是简单拖拉两下,只是示意。同时镜头上的水汽等等我都没有计较,各位不必在意

AI目标检测
目标检测:识别并定位图像或视频中的物体,用边界框指定它们的位置。YOLO(You Only Look Once)是一种流行的单阶段物体检测算法,以其速度和准确性而闻名。与两阶段检测器不同,YOLO 一次性处理整个图像,使实时检测成为可能。这种方法通过提供高效可靠的物体检测功能,彻底改变了自动驾驶、监控和机器人等应用。 目标跟踪:在视频的多个帧中跟踪已识别的对象。SORT(简单在线实时跟踪)算法被广泛用于此目的,因为它通过预测对象的运动并实时更新其位置来有效地跟踪对象。结合使用 YOLO 进行检测和 SORT 进行跟踪可以持续监控和分析对象,确保在整个视频序列中进行准确且一致的跟踪。
跟踪
我们将使用 YOLOv8m、OpenCV 和 SORT 进行对象检测来计算通过视频中特定区域的人员数量,以确保准确性和效率。
-
创建掩码 我们只想识别特定区域的人员。为此,我们将使用工具创建一个蒙版。其中像素为黑色 (0) 或白色 (255)。在 RGB 图像中,这意味着蒙版仅使用两个值: 白色(255, 255, 255)表示感兴趣的区域,算法将在此进行处理。 黑色(0, 0, 0)表示要忽略或排除在处理之外的区域。
-
- 定义区域 我们将在视频中定义两个区域:一个区域用于计数下行的汽车数量,另一个区域用于计数上行的汽车数量。
-
当在指定区域内识别出汽车时,我们会将该区域的颜色更改为绿色,表示检测到。
-
构建布局
-
编写代码
cv2:执行图像和视频处理
cvzone:与 OpenCV 协同工作
numpy:处理数值运算
YOLO:应用物体检测
sort:用于跟踪检测到的对象(SORT)库。
py
import cv2
import numpy as np
from ultralytics import YOLO
import cvzone
from sort import Sort
import os
# ===================== 配置参数(集中管理,便于修改) =====================
# 视频/掩码文件路径
VIDEO_PATH = 'traffic.mp4'
MASK_PATH = 'mask.png'
# 目标检测配置
TARGET_CLASSES = ['car'] # 需计数的目标类别
CONFIDENCE_THRESHOLD = 0.3 # 置信度阈值
YOLO_MODEL = 'yolov8m.pt'
DEVICE = '0' if cv2.cuda.getCudaEnabledDeviceCount() > 0 else 'cpu' # 自动选择GPU/CPU
# 视频尺寸配置
WIDTH = 1280
HEIGHT = 720
# 车道线坐标配置(左/右车道线)
LANE_LEFT = {
'x1': 256, 'x2': 500, 'y': 472,
'color': (0, 0, 255), # 初始红色
'trigger_color': (0, 255, 0) # 触发后绿色
}
LANE_RIGHT = {
'x1': 672, 'x2': 904, 'y': 472,
'color': (0, 0, 255),
'trigger_color': (0, 255, 0)
}
# SORT跟踪器配置(优化跟踪稳定性)
SORT_PARAMS = {
'max_age': 20,
'min_hits': 3, # 新增:最少命中次数才跟踪,减少误检
'iou_threshold': 0.3 # 新增:IOU阈值,提升跟踪准确性
}
# 计数文本样式配置
TEXT_STYLE = {
'scale': 2,
'thickness': 2,
'offset': 20,
'border': 2,
'colorR': (140, 57, 31),
'colorB': (140, 57, 31)
}
# ===================== 初始化核心组件 =====================
def init_components():
"""初始化模型、跟踪器、视频流、掩码"""
# 加载YOLO模型(指定设备,提升推理速度)
model = YOLO(YOLO_MODEL)
model.to(DEVICE)
# 初始化SORT跟踪器(修正参数)
tracker = Sort(**SORT_PARAMS)
# 加载视频流并检查
cap = cv2.VideoCapture(VIDEO_PATH)
if not cap.isOpened():
raise FileNotFoundError(f"无法打开视频文件:{VIDEO_PATH}")
# 加载掩码(处理文件不存在的情况)
mask = None
if os.path.exists(MASK_PATH):
mask = cv2.imread(MASK_PATH)
mask = cv2.resize(mask, (WIDTH, HEIGHT))
else:
print(f"警告:掩码文件 {MASK_PATH} 不存在,将使用完整帧检测")
return model, tracker, cap, mask
# ===================== 核心计数逻辑 =====================
def main():
# 初始化组件
try:
model, tracker, cap, mask = init_components()
except Exception as e:
print(f"初始化失败:{e}")
return
# 初始化计数列表(存储已计数的目标ID)
counted_left_ids = []
counted_right_ids = []
# 逐帧处理视频
while True:
ret, frame = cap.read()
if not ret:
print("视频读取完毕或失败")
break
# 调整帧尺寸
frame = cv2.resize(frame, (WIDTH, HEIGHT))
# 应用掩码(仅检测掩码区域内的目标)
frame_process = cv2.bitwise_and(frame, mask) if mask is not None else frame
# ===================== 目标检测 =====================
detections = []
results = model(frame_process, stream=True, verbose=False) # 关闭冗余输出
for result in results:
for box in result.boxes:
# 获取类别和置信度
cls_idx = int(box.cls[0])
cls_name = model.names[cls_idx] # 直接从模型获取类别名,避免手动列表
conf = float(box.conf[0])
# 过滤非目标类别和低置信度
if cls_name not in TARGET_CLASSES or conf < CONFIDENCE_THRESHOLD:
continue
# 转换为整数坐标
x1, y1, x2, y2 = map(int, box.xyxy[0])
# 边界检查(避免坐标超出图像范围)
x1, y1 = max(0, x1), max(0, y1)
x2, y2 = min(WIDTH-1, x2), min(HEIGHT-1, y2)
detections.append([x1, y1, x2, y2, conf])
# ===================== 目标跟踪 =====================
tracked_objs = tracker.update(np.array(detections))
# 初始化当前帧车道线颜色(每次重置,避免永久变绿)
lane_left_color = LANE_LEFT['color']
lane_right_color = LANE_RIGHT['color']
# 处理跟踪结果并计数
for obj in tracked_objs:
x1, y1, x2, y2, obj_id = map(int, obj)
# 计算目标中心坐标
center_x = (x1 + x2) // 2
center_y = (y1 + y2) // 2
# ===================== 左车道计数 =====================
if (LANE_LEFT['y'] - 10 < center_y < LANE_LEFT['y'] + 10 and
LANE_LEFT['x1'] < center_x < LANE_LEFT['x2']):
if obj_id not in counted_left_ids:
counted_left_ids.append(obj_id)
lane_left_color = LANE_LEFT['trigger_color'] # 仅当前帧变绿
# ===================== 右车道计数 =====================
if (LANE_RIGHT['y'] - 10 < center_y < LANE_RIGHT['y'] + 10 and
LANE_RIGHT['x1'] < center_x < LANE_RIGHT['x2']):
if obj_id not in counted_right_ids:
counted_right_ids.append(obj_id)
lane_right_color = LANE_RIGHT['trigger_color'] # 仅当前帧变绿
# 绘制目标框和ID
cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 255), 2)
# 调整ID文本位置(避免超出图像顶部)
id_text_pos = (max(0, x1), max(30, y1 - 10))
cvzone.putTextRect(frame, f'ID: {obj_id}', id_text_pos, 1, 1)
# ===================== 绘制可视化元素 =====================
# 绘制车道线(使用当前帧的颜色)
cv2.line(frame, (LANE_LEFT['x1'], LANE_LEFT['y']),
(LANE_LEFT['x2'], LANE_LEFT['y']), lane_left_color, 3)
cv2.line(frame, (LANE_RIGHT['x1'], LANE_RIGHT['y']),
(LANE_RIGHT['x2'], LANE_RIGHT['y']), lane_right_color, 3)
# 绘制计数文本
cvzone.putTextRect(frame, f'Left Lane: {len(counted_left_ids)}',
(50, 50), **TEXT_STYLE)
cvzone.putTextRect(frame, f'Right Lane: {len(counted_right_ids)}',
(WIDTH - 350, 50), **TEXT_STYLE)
# ===================== 显示与退出 =====================
cv2.imshow('Vehicle Counting (YOLOv8 + SORT)', frame)
# 按q退出(增加延迟,适配不同帧率)
if cv2.waitKey(1) & 0xFF == ord('q'):
print("用户手动退出")
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
print(f"最终计数:左车道 {len(counted_left_ids)} 辆,右车道 {len(counted_right_ids)} 辆")
# ===================== 执行主程序 =====================
if __name__ == '__main__':
main()使用c++
c
#include <iostream>
#include <vector>
#include <string>
#include <unordered_set>
#include <opencv2/opencv.hpp>
#include <opencv2/cudaimgproc.hpp>
#include <opencv2/cudaarithm.hpp>
// -------------------------- SORT 跟踪器 C++ 实现(核心简化版) --------------------------
// 注:完整SORT需包含Kalman滤波,此处为简化版,可替换为完整SORT代码
struct TrackedObject {
int id;
cv::Rect2d bbox;
int age = 0;
int hits = 0;
bool active = true;
};
class SortTracker {
private:
int max_age;
int min_hits;
float iou_threshold;
int next_id = 1;
std::vector<TrackedObject> tracks;
// 计算IOU
float iou(const cv::Rect2d& a, const cv::Rect2d& b) {
float x1 = std::max(a.x, b.x);
float y1 = std::max(a.y, b.y);
float x2 = std::min(a.x + a.width, b.x + b.width);
float y2 = std::min(a.y + a.height, b.y + b.height);
float inter = std::max(0.0f, x2 - x1) * std::max(0.0f, y2 - y1);
float union_ = a.area() + b.area() - inter;
return union_ > 0 ? inter / union_ : 0;
}
public:
SortTracker(int max_age_ = 20, int min_hits_ = 3, float iou_thresh_ = 0.3)
: max_age(max_age_), min_hits(min_hits_), iou_threshold(iou_thresh_) {}
std::vector<cv::Vec<float, 5>> update(const std::vector<cv::Vec<float, 5>>& detections) {
// 简化版跟踪逻辑(完整版需Kalman预测+匈牙利匹配)
std::vector<cv::Vec<float, 5>> result;
for (const auto& det : detections) {
cv::Rect2d bbox(det[0], det[1], det[2]-det[0], det[3]-det[1]);
float conf = det[4];
// 匹配已有跟踪
int best_idx = -1;
float best_iou = 0;
for (int i = 0; i < tracks.size(); ++i) {
if (!tracks[i].active) continue;
float current_iou = iou(bbox, tracks[i].bbox);
if (current_iou > best_iou && current_iou > iou_threshold) {
best_iou = current_iou;
best_idx = i;
}
}
if (best_idx >= 0) {
// 更新已有跟踪
tracks[best_idx].bbox = bbox;
tracks[best_idx].age = 0;
tracks[best_idx].hits++;
if (tracks[best_idx].hits >= min_hits) {
result.push_back({
bbox.x, bbox.y, bbox.x+bbox.width, bbox.y+bbox.height,
(float)tracks[best_idx].id
});
}
} else {
// 新建跟踪
TrackedObject new_track;
new_track.id = next_id++;
new_track.bbox = bbox;
new_track.hits = 1;
tracks.push_back(new_track);
if (new_track.hits >= min_hits) {
result.push_back({
bbox.x, bbox.y, bbox.x+bbox.width, bbox.y+bbox.height,
(float)new_track.id
});
}
}
}
// 清理过期跟踪
for (auto& track : tracks) {
if (!track.active) continue;
track.age++;
if (track.age > max_age) {
track.active = false;
}
}
return result;
}
};
// -------------------------- 配置参数(对应Python版) --------------------------
struct LaneConfig {
int x1, x2, y;
cv::Scalar color;
cv::Scalar trigger_color;
};
struct Config {
// 路径配置
std::string VIDEO_PATH = "traffic.mp4";
std::string MASK_PATH = "mask.png";
std::string YOLO_MODEL_PATH = "yolov8m.pt";
// 检测配置
std::vector<std::string> TARGET_CLASSES = {"car"};
float CONFIDENCE_THRESHOLD = 0.3f;
bool USE_GPU = cv::cuda::getCudaEnabledDeviceCount() > 0;
// 视频尺寸
int WIDTH = 1280;
int HEIGHT = 720;
// 车道配置
LaneConfig LANE_LEFT = {256, 500, 472, cv::Scalar(0,0,255), cv::Scalar(0,255,0)};
LaneConfig LANE_RIGHT = {672, 904, 472, cv::Scalar(0,0,255), cv::Scalar(0,255,0)};
// SORT参数
int SORT_MAX_AGE = 20;
int SORT_MIN_HITS = 3;
float SORT_IOU_THRESH = 0.3f;
// 文本样式
int TEXT_SCALE = 2;
int TEXT_THICKNESS = 2;
cv::Scalar TEXT_BG_COLOR = cv::Scalar(140, 57, 31);
} cfg;
// -------------------------- YOLOv8 推理封装(简化版) --------------------------
// 注:完整实现需集成Ultralytics YOLOv8 C++ API或ONNX Runtime
// 此处为模拟接口,实际需替换为真实推理代码
std::vector<cv::Vec<float, 5>> detect_yolov8(const cv::Mat& frame, const Config& cfg) {
std::vector<cv::Vec<float, 5>> detections;
// 【替换提示】此处替换为真实YOLOv8推理代码:
// 1. 加载YOLOv8模型(ONNX/TensorRT)
// 2. 预处理帧(归一化、resize、转张量)
// 3. 推理得到检测框
// 4. 过滤目标类别和低置信度
// 模拟检测结果(仅作示例)
static int mock_count = 0;
if (mock_count % 5 == 0) {
// 格式:x1, y1, x2, y2, conf
detections.push_back({300, 400, 380, 480, 0.8f}); // 左车道车辆
detections.push_back({700, 400, 780, 480, 0.9f}); // 右车道车辆
}
mock_count++;
return detections;
}
// -------------------------- 初始化组件 --------------------------
bool init_components(cv::VideoCapture& cap, cv::Mat& mask, SortTracker& tracker) {
// 加载视频
cap.open(cfg.VIDEO_PATH);
if (!cap.isOpened()) {
std::cerr << "无法打开视频文件:" << cfg.VIDEO_PATH << std::endl;
return false;
}
// 加载掩码
if (cv::utils::fs::exists(cfg.MASK_PATH)) {
mask = cv::imread(cfg.MASK_PATH);
cv::resize(mask, mask, cv::Size(cfg.WIDTH, cfg.HEIGHT));
} else {
std::cout << "警告:掩码文件不存在,使用完整帧检测" << std::endl;
}
// 初始化SORT跟踪器
tracker = SortTracker(cfg.SORT_MAX_AGE, cfg.SORT_MIN_HITS, cfg.SORT_IOU_THRESH);
return true;
}
// -------------------------- 主函数 --------------------------
int main() {
// 初始化组件
cv::VideoCapture cap;
cv::Mat mask;
SortTracker tracker;
if (!init_components(cap, mask, tracker)) {
return -1;
}
// 已计数ID集合(去重)
std::unordered_set<int> counted_left_ids;
std::unordered_set<int> counted_right_ids;
// 逐帧处理
cv::Mat frame, frame_process;
while (true) {
// 读取帧
if (!cap.read(frame)) {
std::cout << "视频读取完毕或失败" << std::endl;
break;
}
// 调整尺寸
cv::resize(frame, frame, cv::Size(cfg.WIDTH, cfg.HEIGHT));
// 应用掩码
if (!mask.empty()) {
cv::bitwise_and(frame, mask, frame_process);
} else {
frame_process = frame.clone();
}
// -------------------------- 目标检测 --------------------------
std::vector<cv::Vec<float, 5>> detections = detect_yolov8(frame_process, cfg);
// -------------------------- 目标跟踪 --------------------------
std::vector<cv::Vec<float, 5>> tracked_objs = tracker.update(detections);
// 初始化车道线颜色
cv::Scalar lane_left_color = cfg.LANE_LEFT.color;
cv::Scalar lane_right_color = cfg.LANE_RIGHT.color;
// -------------------------- 计数逻辑 --------------------------
for (const auto& obj : tracked_objs) {
// 解析跟踪结果:x1,y1,x2,y2,id
int x1 = static_cast<int>(obj[0]);
int y1 = static_cast<int>(obj[1]);
int x2 = static_cast<int>(obj[2]);
int y2 = static_cast<int>(obj[3]);
int obj_id = static_cast<int>(obj[4]);
// 计算中心坐标
int center_x = (x1 + x2) / 2;
int center_y = (y1 + y2) / 2;
// 左车道计数
if (abs(center_y - cfg.LANE_LEFT.y) < 10 &&
center_x > cfg.LANE_LEFT.x1 && center_x < cfg.LANE_LEFT.x2) {
if (counted_left_ids.find(obj_id) == counted_left_ids.end()) {
counted_left_ids.insert(obj_id);
lane_left_color = cfg.LANE_LEFT.trigger_color;
}
}
// 右车道计数
if (abs(center_y - cfg.LANE_RIGHT.y) < 10 &&
center_x > cfg.LANE_RIGHT.x1 && center_x < cfg.LANE_RIGHT.x2) {
if (counted_right_ids.find(obj_id) == counted_right_ids.end()) {
counted_right_ids.insert(obj_id);
lane_right_color = cfg.LANE_RIGHT.trigger_color;
}
}
// 绘制检测框和ID
cv::rectangle(frame, cv::Point(x1, y1), cv::Point(x2, y2), cv::Scalar(255,0,255), 2);
std::string id_text = "ID: " + std::to_string(obj_id);
cv::Point id_pos = cv::Point(std::max(0, x1), std::max(30, y1 - 10));
cv::putText(frame, id_text, id_pos, cv::FONT_HERSHEY_SIMPLEX, 1, cv::Scalar(255,255,255), 2);
}
// -------------------------- 可视化 --------------------------
// 绘制车道线
cv::line(frame,
cv::Point(cfg.LANE_LEFT.x1, cfg.LANE_LEFT.y),
cv::Point(cfg.LANE_LEFT.x2, cfg.LANE_LEFT.y),
lane_left_color, 3);
cv::line(frame,
cv::Point(cfg.LANE_RIGHT.x1, cfg.LANE_RIGHT.y),
cv::Point(cfg.LANE_RIGHT.x2, cfg.LANE_RIGHT.y),
lane_right_color, 3);
// 绘制计数文本(带背景框)
std::string left_text = "Left Lane: " + std::to_string(counted_left_ids.size());
std::string right_text = "Right Lane: " + std::to_string(counted_right_ids.size());
// 左计数文本
cv::Size left_text_size = cv::getTextSize(left_text, cv::FONT_HERSHEY_SIMPLEX, cfg.TEXT_SCALE, cfg.TEXT_THICKNESS, nullptr);
cv::rectangle(frame,
cv::Point(50 - 10, 50 - left_text_size.height - 10),
cv::Point(50 + left_text_size.width + 10, 50 + 10),
cfg.TEXT_BG_COLOR, -1);
cv::putText(frame, left_text, cv::Point(50, 50),
cv::FONT_HERSHEY_SIMPLEX, cfg.TEXT_SCALE, cv::Scalar(255,255,255), cfg.TEXT_THICKNESS);
// 右计数文本
cv::Size right_text_size = cv::getTextSize(right_text, cv::FONT_HERSHEY_SIMPLEX, cfg.TEXT_SCALE, cfg.TEXT_THICKNESS, nullptr);
int right_x = cfg.WIDTH - 350;
cv::rectangle(frame,
cv::Point(right_x - 10, 50 - right_text_size.height - 10),
cv::Point(right_x + right_text_size.width + 10, 50 + 10),
cfg.TEXT_BG_COLOR, -1);
cv::putText(frame, right_text, cv::Point(right_x, 50),
cv::FONT_HERSHEY_SIMPLEX, cfg.TEXT_SCALE, cv::Scalar(255,255,255), cfg.TEXT_THICKNESS);
// 显示帧
cv::imshow("Vehicle Counting (YOLOv8 + SORT)", frame);
// 按Q退出
if (cv::waitKey(1) == 'q') {
std::cout << "用户手动退出" << std::endl;
break;
}
}
// 释放资源
cap.release();
cv::destroyAllWindows();
// 输出最终计数
std::cout << "最终计数:左车道 " << counted_left_ids.size()
<< " 辆,右车道 " << counted_right_ids.size() << " 辆" << std::endl;
return 0;
}三维投影以及输出
三维投影