风格迁移的核心原理源于卷积神经网络(CNN)对图像特征的提取能力:通过算法分离图像的内容特征 与风格特征,再将两者重新组合,生成兼具原始内容与艺术风格的全新图像。
从技术落地来看,借助 OpenCV 的 DNN 深度神经网络模块,搭配预训练好的风格迁移模型,就能快速实现这一效果。
核心技术原理
-
图像预处理(Blob 构建): 深度学习模型对输入图像有严格的格式要求,OpenCV 的
dnn.blobFromImage函数就是专门用于将普通图像转换为模型可识别的四维张量(Blob),完成缩放、减均值、通道调整等预处理操作。 -
预训练模型加载: 风格迁移的深度学习模型已经由科研人员训练完成,我们直接加载
.t7格式的 Torch 预训练模型即可。本文使用的是梵高《星空》专属的风格迁移模型,模型文件体积小、推理速度快,非常适合入门学习。 -
**前向推理与结果重构:**将预处理后的图像输入模型,通过前向传播得到风格化后的输出张量,再将张量重构为可视化的图像格式,完成最终效果展示。
前期准备
准备两个核心文件:
-
输入图像:任意格式的图片(JPG/PNG/WebP 均可)
-
预训练模型 :
starry_night.t7(梵高星空风格迁移预训练模型,网络上可免费下载)
完整代码解析
导入相关库和读取图像
python
import cv2
# 读取输入图像
image = cv2.imread(r"C:\Users\LEGION\Desktop\OIP-C.webp")
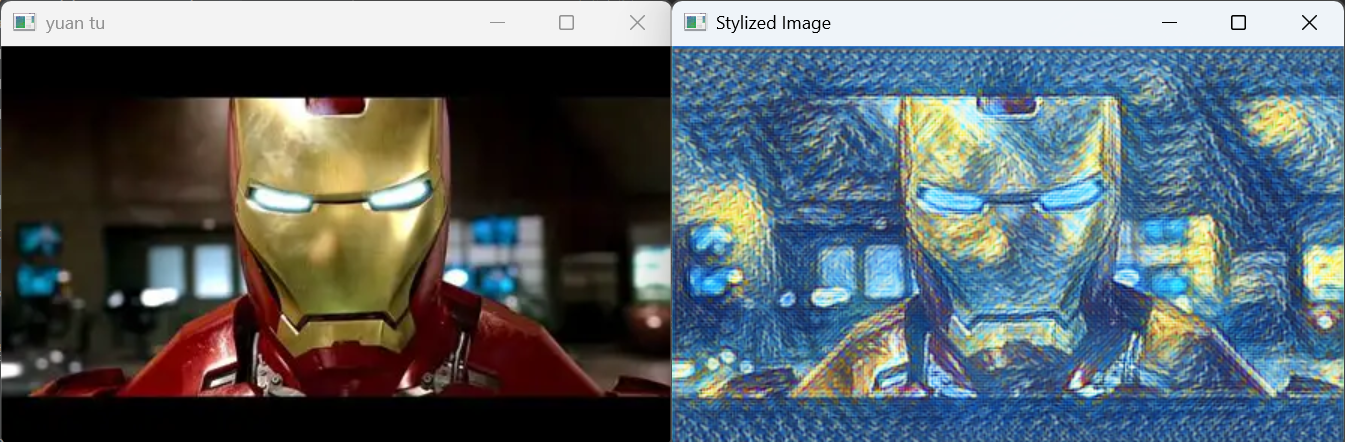
# 显示输入图像
cv2.imshow('yuan tu', image)
cv2.waitKey(0)图像预处理(核心步骤)
python
# ----------------图片预处理----------------
(h, w) = image.shape[:2] # 获取图像尺寸
# 函数cv2.dnn.blobFromImage:实现图像预处理,从原始图像构建一个符合人工神经网络输入格式的四维模块。
blob = cv2.dnn.blobFromImage(image, scalefactor=1, size=(w, h), mean=(0, 0, 0), swapRB=False, crop=False)image.shape返回图像的 (高度,宽度,通道数),image.shape[:2]只提取前两个值(h, w),用于后续指定预处理后的图像大小,保证风格迁移后图像尺寸与原图一致。
cv2.dnn.blobFromImage()函数
| 参数名 | 作用 | 本文配置说明 |
|---|---|---|
| image | 输入的原始图像 | 我们读取的照片变量 |
| scalefactor | 像素值缩放因子 | 设为 1,表示不缩放像素值 |
| size | 输出 Blob 的尺寸 | 设为原图 (w, h),保持尺寸一致 |
| mean | 通道减均值 | 设为 (0,0,0),不进行减均值操作 |
| swapRB | 是否交换 R/B 通道 | 设为 False,本模型无需交换通道 |
| crop | 是否居中裁剪 | 设为 False,不裁剪图像 |
swapRB:表示在必要时交换通道的R通道和B通道。一般情况下使用的是RGB通道,而OpenCV通常采用的是BGR通道。因此可以根据需要交换第1个和第3个通道。该值默认为 False。
返回值 Blob :四维张量,格式为NCHW,分别代表:
-
N:Batch Size(批次大小,本文为 1,单张图像);
-
C:通道数(彩色图像为 3);
-
H:图像高度;
-
W:图像宽度。
预训练模型加载与前向推理
python
# ----------------加载模型----------------
net = cv2.dnn.readNet(r"C:\Users\LEGION\Desktop\starry_night.t7") # 得到一个pytorch训练之后的星空模型
net.setInput(blob)
# 对输入图像进行前向传播,得到输出结果
out = net.forward()模型加载cv2.dnn.readNet()
-
作用:加载预训练的深度学习模型,支持 Caffe、TensorFlow、Torch、DarkNet 等多种框架的模型格式;
-
本文加载的
starry_night.t7是 Torch 框架训练的梵高星空风格迁移模型,OpenCV 可直接识别并加载; -
返回值
net:神经网络模型对象,后续用于输入数据和推理。
- 模型推理
-
net.setInput(blob):将预处理后的 Blob 张量设置为模型的输入; -
out = net.forward():执行前向传播,这是风格迁移的核心计算过程,模型会自动提取原图的内容特征,融合《星空》的风格特征,输出风格化后的张量。
加载模型net=cv2.dnn.readNet( model\[, config\[, framework] ])
各参数的含义如下:
model:神经网络的实际结构和功能,它定义了数据如何通过网络流动,如何进行训练,如何进行推理。
config:一组参数和设置,帮助控制模型的行为,包括网络架构、训练过程、优化器等内容。
framework:DNN框架,可省略。DNN模块会自动推断框架种类。
net:返回值,返回网络模型对象。
支持的模型格式有Torch,TensorFlow,Caffe,DarkNet. ONNX和Intel OpenVINO
model参数 | config参数 | framework参数 | 函数名称
*.caffemodel | *.prototxt | caffe | readNetFromCaffe
*.pd | *.pbxtxt | tensorflow | readNetFromTensorFlow
*.t7 | *.net | torch | readNetFromTorch
*.weight | *.cfg | darknet | readNetFromDarknet
*.bin | *.xml | dldt | readNetFromModelOptimizer
*.onnx | | onnx | readNetFromONNX
输出结果重构与可视化
模型输出的是四维张量,无法直接显示为图像,我们需要对其进行形状调整、归一化、维度转置等操作:
python
# 将输出结果转换为合适的格式
# out是四维的:B*C*H*W
# =========输出处理=========
# 重塑形状(忽略第1维),4维变3维
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
# 对输入的数组(或图像)进行归一化处理,使其数值范围在指定的范围内
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
# 转置输出结果的维度
result = out_new.transpose(1, 2, 0)
# 显示转换后的图像
cv2.imshow('Stylized Image', result)
cv2.waitKey(0)
cv2.destroyAllWindows()维度重塑
模型输出out是四维格式BCHW,其中 B=1(单张图像),我们用reshape函数忽略第一维,将其转换为三维格式CHW(通道、高度、宽度),这是图像数据的标准三维结构。
像素值归一化
cv2.normalize()函数将输出张量的像素值归一化到[0,1]区间。因为模型推理后的像素值范围不固定,直接显示会出现黑屏、花屏等问题,归一化后才能正常可视化。
维度转置
OpenCV 的图像格式是HWC(高度、宽度、通道),而模型输出是CHW,因此通过transpose(1,2,0)将维度顺序调整为HWC,匹配 OpenCV 的图像显示规则。
运行结果