检索增强生成(RAG)的基础流程是用户查询转换为向量嵌入,从向量数据库中取回相似文档,再将这些文档作为上下文送入大语言模型(LLM)生成答案。
基础 RAG 的准确性受制于查询质量,查询模糊、表述不当,或者用户对问题的抽象层次把握不准,检索结果就会出偏差,LLM 拿到的上下文也跟着失真。垃圾输入,垃圾输出,这个规律在 RAG 场景里同样成立。
所以有两类改进方向逐渐成型:查询转换(Query Translation)与查询分解(Query Decomposition)。前者在查询送入向量数据库之前对其进行变形和扩展,后者则把复杂查询拆解成更易处理的子问题。具体技术包括:并行查询检索(FAN-OUT 架构)、倒数排名融合(RRF)、HyDE(假设文档嵌入),以及基于思维链的低抽象分解和基于后退提示的高抽象分解。
查询转换
查询转换的核心思路是不依赖原始查询的单一表述,而是生成若干语义相近的变体,覆盖更多可能与文档匹配的角度。
以"RAG 如何改善 LLM 的响应效果?"为例,扩展后可以得到:
检索增强生成是如何工作的?
RAG 对大语言模型的优势
检索如何提升 LLM 的准确性这些变体并不改变查询的意图,而是换用不同的措辞和切入点,让向量搜索有机会命中文档库中表述各异的相关内容,从而提高召回率。
并行查询检索(Fan-Out 检索)
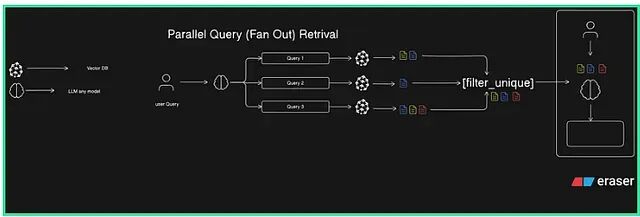
并行查询检索把上述思路落地为具体架构:LLM 基于原始输入生成多个查询变体,各变体同时发往向量数据库执行相似度搜索,检索结果汇总后去除重复文档,最终上下文再传入 LLM。
整个流程分六步完成:用户发送查询、LLM 生成备选查询、各查询并发执行相似度搜索、合并检索结果、过滤重复文档、将最终上下文传递给 LLM。不同措辞在嵌入空间中的分布位置不同,命中的文档集合也会有所差异,并行执行正是在利用这一特性。
倒数排名融合(RRF)

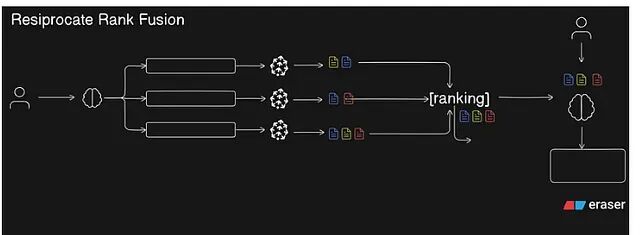
多路查询的结果合并,不能简单拼接了事。各路检索返回的文档存在重叠,排名也不尽相同,直接合并会导致高质量文档被低质量文档淹没。
倒数排名融合(RRF)解决的正是这个问题。它不看原始相似度分数,而是根据文档在每路结果中的排名位置计算分数,公式如下:
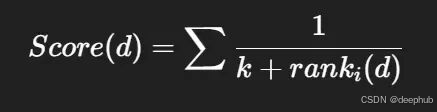
其中:

排名越靠前,得分越高;在多路结果中反复出现且名次稳定的文档,累计分数也更高。经过 RRF 重排后,最终上下文的质量比简单合并要可靠得多。
HyDE(假设文档嵌入)
HyDE 的逻辑与前两种技术不同,它绕开了"查询表述不准确"这个根源性问题。
直接对用户查询做嵌入,得到的向量反映的是问题的语义;向量数据库里存的是答案文档,两者在嵌入空间中的距离未必近。HyDE 的做法是:先让 LLM 针对用户查询生成一段假设性的答案或文档,再对这段生成文本做嵌入,用于相似度搜索。
生成文本在风格和内容上更接近真实文档,检索准确率往往随之提升。不过需要注意的是这里依赖 LLM 的生成质量,参数量偏小的模型生成的假设文档可能失真,反而干扰检索。
查询分解
有些查询本身就包含多个子问题,单次检索无法覆盖全部所需信息。把这类查询原封不动地送入向量数据库,检索结果往往是残缺的。
查询分解把复杂查询拆解为若干粒度更细的子查询,分别检索,再合并结果。拆解的方向取决于查询的抽象层次------查询可以向上推至更高的概念层,也可以向下细化为具体的执行步骤。
高抽象分解(后退提示)
后退提示(Step-Back Prompting)先退一步,提出一个比原始查询更高层次的问题,再基于这个高层问题检索到的上下文来回答具体问题。
以"RAG 如何提升 LLM 的性能?"为例,后退查询可以是:
没有外部知识的 LLM 存在哪些局限性?先建立认知框架,再回答具体问题,检索到的上下文在概念层面会更完整。
低抽象分解(思维链检索)
思维链检索把查询拆解为若干有顺序依赖的子步骤,前一步的检索结果作为后一步的输入,逐步推进。
以"RAG 是如何工作的?它与微调有何不同?"为例,分解过程如下:
步骤 1------理解 RAG 的概念
什么是检索增强生成?步骤 2------检索 RAG 工作原理的详细信息
RAG 是如何工作的?步骤 3------检索微调的相关信息
LLM 中的微调是什么?步骤 4------对比两个概念
RAG 与微调有何区别?每个子步骤独立命中一批相关文档,前序步骤积累的理解指导后续步骤的检索方向,最终由 LLM 整合所有步骤的上下文,生成完整答案。
这种顺序推理结构在处理跨概念的比较类问题时尤为有效------原始查询包含的概念跨度越大,单次检索的信噪比就越低,分步处理带来的收益也越明显。
总结
查询转换和查询分解并不是非此即彼的选择。实际系统里,两者往往配合使用:Fan-Out 扩展查询覆盖面,RRF 保证合并结果的排名质量,复杂问题再交给分解流程逐步处理。至于哪种组合适合当前场景,取决于查询的典型复杂度、向量库的规模,以及系统对延迟的容忍程度------这些判断没有通用答案,需要在具体环境里测量。
https://avoid.overfit.cn/post/f84e72a8354746249b17ab498cf99483
by Samarth Acharya