本文介绍下使用Sharding-JDBC实现水平分表
Sharding-JDBC是轻量级的 java 框架,是增强版的 JDBC 驱动,使用Sharding-JDBC可以简化对分库分表之后数据相关操作。下面分别介绍下水平分表的方法。
1、准备好数据库和数据表
先创建一个course_db数据库,然后创建2张表course_1和course_2,两张表的数据结构一样,使用下面的sql完成建表。
sql
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for course_1
-- ----------------------------
DROP TABLE IF EXISTS `course_1`;
CREATE TABLE `course_1` (
`cid` bigint NOT NULL,
`cname` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`user_id` bigint NOT NULL,
`cstatus` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;建好course_1后,将上面的SQL表名改成course_2,完成course_2的创建。
2、创建springboot工程
使用springboot脚手架创建一个maven工程,项目使用jdk1.8和Springboot 2.2.1.Release版本
2.1 pom.xml引入依赖
XML
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>重点说下这2个依赖
1、sharding-jdbc-spring-boot-starter:Sharding-JDBC的核心依赖;2、druid-spring-boot-starter:数据库连接池,如果使用springboot内置的HikariCP连接池,则不用引入该依赖。注意:使用的连接池不同,application里的配置需做相应的调整,本文使用阿里的druid。
2.2 配置application.properties
这是实现Sharding-JDBC管理分库分表的核心操作
可以选择使用yaml,yaml配置可参考官网:https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/yaml-config/
bash
# shardingjdbc 分片策略
# 配置数据源,给数据源起名称
spring.shardingsphere.datasource.names=m1
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#配置数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://192.168.56.10:3309/course_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root
#指定 course 表分布情况,配置表在哪个数据库里面,表名称都是什么 m1.course_1 ,m1.course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$->{1..2}
# 指定 course 表里面主键 cid 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 指定分片策略 约定 cid 值偶数添加到 course_1 表,如果 cid 是奇数添加到 course_2表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# 打开 sql 输出日志
spring.shardingsphere.props.sql.show=true上面主要配置以下信息:
数据源、表分布情况、主键生成策略、主键名、表的分片策略、sql输出(生产环境建议关闭)
这里重点说下:
1、表的分片策略,约定 cid 值为偶数则添加到 course_1 表,为奇数添加到 course_2表,通过表达式来实现:course_$->{cid % 2 + 1},如果想id为奇数存到_1表,偶数存到_2表,则表表达式后面的+1去掉;
2、当主键生成策略使用雪花算法SNOWFLAKE时,数据库表的id最好声明为bigint,实体类中id的类型需声明为Long,要不然将不会使用雪花算法生成id。
2.3 编写测试代码
在单元测试中,编写方法验证上面的水平分表是否生效
java
@SpringBootTest
class ShardingjdbcdemoApplicationTests {
@Resource
private CourseMapper courseMapper;
//1、测试水平分表
//添加课程的方法
@Test
public void addCourse() {
for(int i=1;i<=10;i++) {
Course course = new Course();
course.setCname("java"+i);
course.setUserId(100L);
course.setCstatus("Normal");
courseMapper.insert(course);
}
}
//查询课程的方法
@Test
public void findCourse() {
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.eq("cid",1240359224765054976L);
Course course = courseMapper.selectOne(wrapper);
System.out.println(course);
}
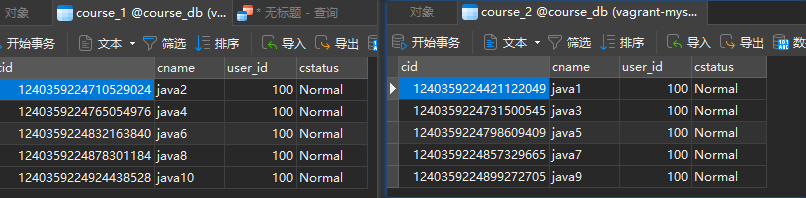
}执行单元测试,会发现:
1、添加操作中,当cid为奇数时,数据存到course_2表,为偶数时,存在到course_1表;
2、查询操作中,cid为偶数,则查询course_1表。
可通过查看IDEA控制台打印出来的信息,重点关注Logic SQL和Actual SQL,其中Actual SQL是实际执行的库和表。
3、拓展:数据库连接池比较
| 连接池 | 核心优点 | 核心缺点 | 适用场景 |
|---|---|---|---|
| HikariCP | 1. 性能极致(速度最快、内存占用最低)2. 代码轻量(约 130KB)3. 自动超时回收、低延迟4. Spring Boot 2.x+ 默认内置 | 1. 监控功能弱(无可视化)2. 扩展功能少(仅核心连接池能力) | 绝大多数生产环境、追求高性能 / 低资源占用的场景(微服务、高并发) |
| Druid(阿里) | 1. 监控能力极强(SQL 监控、慢查询、连接池状态)2. 自带防 SQL 注入、加密配置3. 扩展功能丰富(过滤器、统计)4. 国内文档 / 社区支持好 | 1. 性能略逊于 HikariCP2. 配置项多、相对重 | 国内企业项目、需要精细化监控 / 安全管控的场景(电商、金融) |
| Tomcat JDBC Pool | 1. Tomcat 内置、无需额外依赖2. 稳定、轻量3. 支持高可用配置 | 1. 性能不如 HikariCP2. 监控 / 扩展能力弱 | Tomcat 容器内的简单项目、中小流量场景 |
| C3P0 | 1. 老牌稳定、兼容性好2. 支持配置持久化3. 自动重连机制完善 | 1. 性能差(高并发下卡顿)2. 代码老旧、维护少3. 内存泄漏风险 | 老项目维护、低并发场景(不推荐新项目使用) |
| DBCP2(Apache) | 1. 开源成熟、配置灵活2. 支持多种连接验证方式 | 1. 性能一般2. 监控能力弱3. 高并发下稳定性不如 HikariCP | 老项目(如基于 Spring Boot 1.x 的项目)、非核心业务 |