LLM 推理与训练的底层原理
今天我们将按照三大篇章来搞懂大模型推理过程与SFT时发生了什么事情:
- 第一章:前向传播 (Forward Pass) ------ 从输入到输出的流转;
- 第二章:训练数据的构造与 Mask Label (训练特有);
- 第三章:Loss 计算的底层原理 (训练特有);
- 第四章:反向传播 (Backpropagation) ------ 梯度下降的灵魂 (训练特有);
- 第五章:优化器 (Optimizer) ------ 模型权重的更新机器;
- 第六章:防止灾难性遗忘与 KL散度 (高级正则化);
- 第七章:全参数微调的工程现实 ------ 突破显存墙 (Memory Wall)
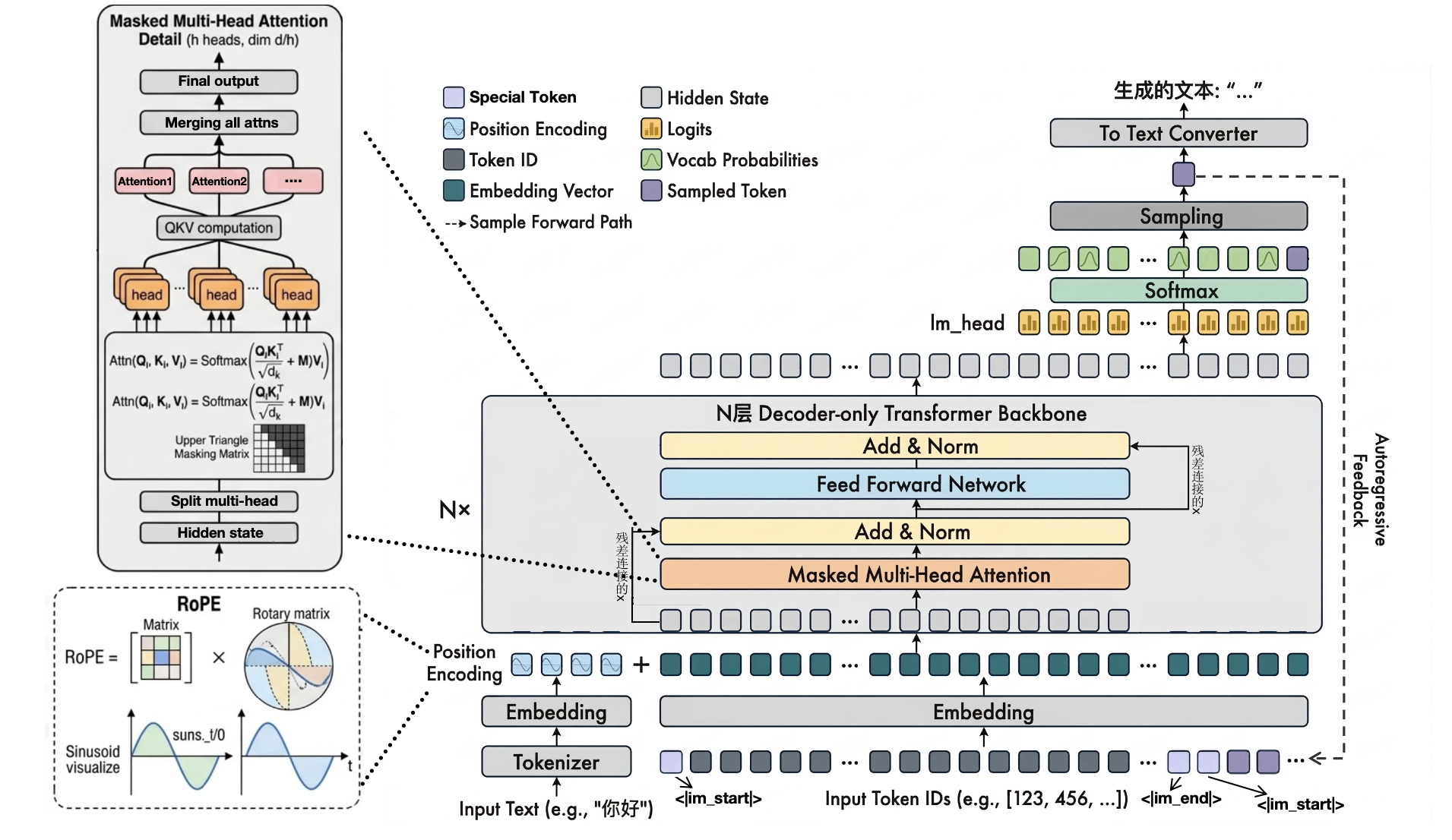 图1.LLM架构图
图1.LLM架构图
这是一张非常经典的LLM推理/SFT架构图,花了很多时间画的,推荐大家认真阅读。
前置学习1: Transformer原理
前置学习2: 大模型前沿注意力机制优化
前置学习3: 大模型主流框架系列
第一部分:前向传播 (Forward Pass) ------ 从输入到输出的流转
前向传播是模型推理(Inference)和训练(Training)共有的第一步。我们先走通数据在模型中的流转路径。
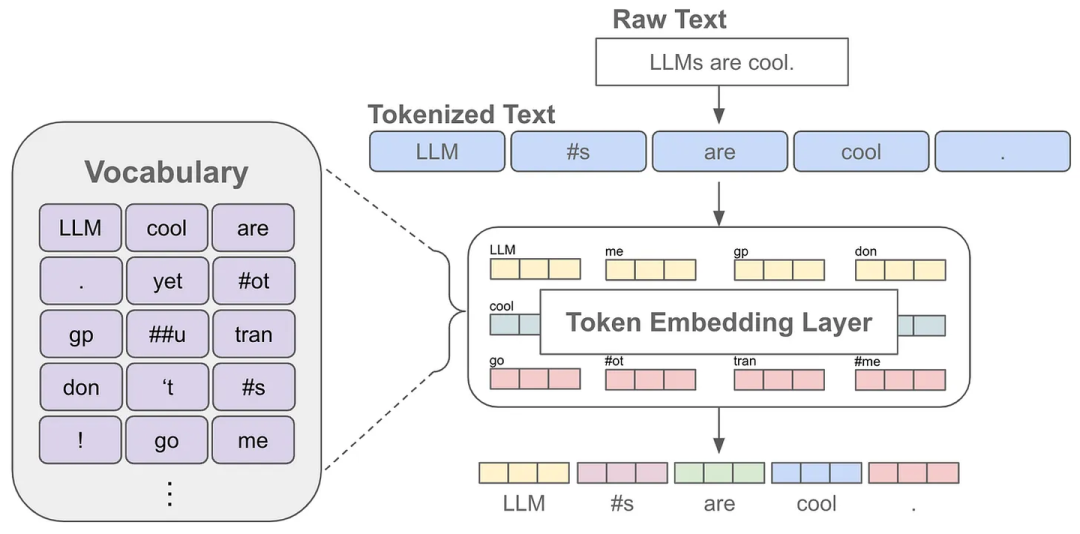
图2.Tokenizer & Embedding
1. Tokenizer 与 特殊字符 (Special Tokens)
如图2所示 ,输入文本(Input Text)首先经过 Tokenizer(分词器),转换为 Token ID。例如:输入为 "你好啊",输出为 [102, 111],102代表"你好",111代表"啊"。这层转换是通过分词词表 (Vocabulary) 映射得到的。
- 底层原理:大模型无法直接理解中文字符或英文字母,必须将其映射为字典库(Vocabulary)中的整数索引(Token IDs)。目前主流采用 BPE(Byte-Pair Encoding)或 SentencePiece 算法,通过统计语料库中最高频的字节组合来构建词表。
- 特殊Token的作用 :图1中标出了
<|im_start|>和<|im_end|>。在指令微调(Instruction Tuning)中,这些特殊Token极为关键。它们被用来界定 System Prompt、User Query 和 Assistant Response 的边界(即 ChatML 格式)。这让模型在自回归生成时,知道什么时候该停止(遇到<|im_end|>)。
2. 词嵌入 (Embedding)
将离散的 Token IDs(如 [123, 456, ...])映射为连续的稠密向量(Embedding Vectors)。
- 公式 : E i n p u t = X ⋅ W E E_{input} = X \cdot W_E Einput=X⋅WE。其中 X X X 是前置步骤分词器分词得到的 Token IDs, W E ∈ R V × d m o d e l W_E \in \mathbb{R}^{V \times d_{model}} WE∈RV×dmodel 是嵌入矩阵( V V V 为词表大小, d m o d e l d_{model} dmodel 为模型隐藏层维度)。
- 物理意义 :将冰冷的单词ID表示为更高维度的特征,可以充分挖掘语义信息。在高维空间中,语义相近的词,其 Embedding 向量在空间上的夹角更小(余弦相似度更高)。
3. 位置编码 (Position Encoding - RoPE)
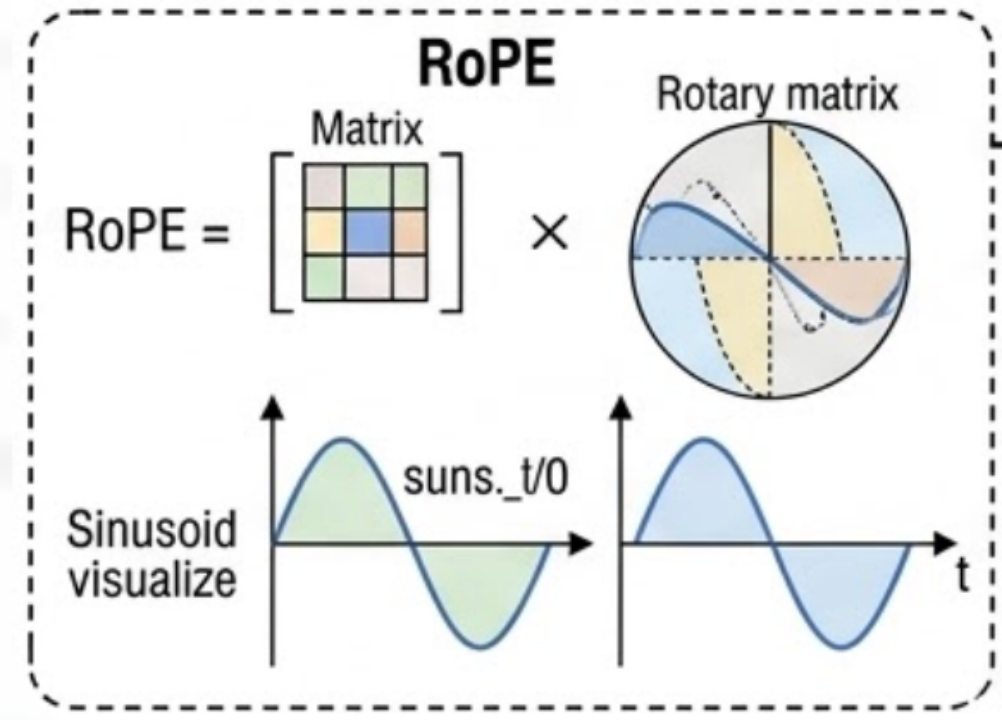
图3.旋转位置编码
-
为什么需要位置编码?:Transformer 的自注意力机制本质上是集合运算,没有捕捉词序的能力。打乱句子顺序,Attention 的结果(如果不加 Mask)是一样的。
-
阶段一:传统的位置编码算法 : Google 在最初的《Attention Is All You Need》论文中提出的做法:假设词向量的维度是 d d d(比如 512 维),对于句子中第 p o s pos pos 个位置的词,它的位置向量 p p p 里面的每一个元素(索引为 i i i)都是用三角函数算出来的:对于偶数维度(第 0, 2, 4... 维): P E ( p o s , 2 i ) = sin ( p o s 10000 2 i / d ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d}}\right) PE(pos,2i)=sin(100002i/dpos)对于奇数维度(第 1, 3, 5... 维): P E ( p o s , 2 i + 1 ) = cos ( p o s 10000 2 i / d ) PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d}}\right) PE(pos,2i+1)=cos(100002i/dpos)
结合奇偶维度的位置编码,最终可以组合成最终位置编码信息PE。但是该策略在后续计算Attention( Q K ˙ T Q \dot K^T QK˙T)时,点积结果无法直接获取两个不同词之间的位置相对信息,因此在训练时模型需要理解该相对位置信息,模型训练效果不好。因此出现了第二阶段的将位置编码修改为随机参数,训练过程中可更新该部分参数。
-
阶段二:可学习的位置编码矩阵 :这是后来 GPT 系列和 BERT 采用的做法。这种方式更"暴力"也更简单:不写死公式,直接让模型自己学。它在模型的参数里初始化一个巨大的位置矩阵(Embedding Table) 。假设你设定的句子最长是 1024 个词,向量维度是 512,那么就直接创建一个 1024 × 512 1024 \times 512 1024×512 的矩阵。第 1 个位置的 p 1 p_1 p1,就是去查这个矩阵的第 1 行;第 2 个位置的 p 2 p_2 p2,就是矩阵的第 2 行。一开始,这个矩阵里的数字全是随机的。随着模型在海量语料上做梯度下降训练,模型会自己把最合适的"位置信息"更新到这个矩阵里。
但是该方法明显不是最优的解法,训练时需要更新的参数又大量增加,训练时难以收敛!
-
阶段三:RoPE旋转位置编码 :不同于传统的绝对位置编码(直接加上一个正弦波向量),RoPE 通过绝对位置的旋转操作来实现相对位置的表达 。
对于第 m m m 个位置的词向量(其在Q中的位置就是 q m q_m qm),我们将其划分为多个二维子空间,在每个二维平面上旋转一个角度 m θ i m\theta_i mθi。
1.假设在计算 Attention 时,我们有一个第m个位置的词对应的 Query 向量 q q q 和一个第n个词对应的 Key 向量 k k k。为了推导方便,我们只看它俩在某个二维子空间(比如第 1、2 维)的值: q = ( q 1 q 2 ) , k = ( k 1 k 2 ) q = \begin{pmatrix} q_1 \\ q_2 \end{pmatrix}, \quad k = \begin{pmatrix} k_1 \\ k_2 \end{pmatrix} q=(q1q2),k=(k1k2)2. 对 q q q 和 k k k 分别进行 RoPE 旋转,Query 处于第 m m m 个位置,旋转 m θ m\theta mθ;Key 处于第 n n n 个位置,旋转 n θ n\theta nθ。Query 旋转后的结果 q m q_m qm: q m = ( cos m θ − sin m θ sin m θ cos m θ ) ( q 1 q 2 ) = ( q 1 cos m θ − q 2 sin m θ q 1 sin m θ + q 2 cos m θ ) q_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} q_1 \\ q_2 \end{pmatrix} = \begin{pmatrix} q_1 \cos m\theta - q_2 \sin m\theta \\ q_1 \sin m\theta + q_2 \cos m\theta \end{pmatrix} qm=(cosmθsinmθ−sinmθcosmθ)(q1q2)=(q1cosmθ−q2sinmθq1sinmθ+q2cosmθ)Key 旋转后的结果 k n k_n kn: k n = ( cos n θ − sin n θ sin n θ cos n θ ) ( k 1 k 2 ) = ( k 1 cos n θ − k 2 sin n θ k 1 sin n θ + k 2 cos n θ ) k_n = \begin{pmatrix} \cos n\theta & -\sin n\theta \\ \sin n\theta & \cos n\theta \end{pmatrix} \begin{pmatrix} k_1 \\ k_2 \end{pmatrix} = \begin{pmatrix} k_1 \cos n\theta - k_2 \sin n\theta \\ k_1 \sin n\theta + k_2 \cos n\theta \end{pmatrix} kn=(cosnθsinnθ−sinnθcosnθ)(k1k2)=(k1cosnθ−k2sinnθk1sinnθ+k2cosnθ)
-
计算内积 q m ⋅ k n q_m \cdot k_n qm⋅kn 并展开Attention 的核心是算内积。我们将上面两个展开后的向量相乘求和: q m ⋅ k n = ( q 1 cos m θ − q 2 sin m θ ) ( k 1 cos n θ − k 2 sin n θ ) + ( q 1 sin m θ + q 2 cos m θ ) ( k 1 sin n θ + k 2 cos n θ ) q_m \cdot k_n = (q_1 \cos m\theta - q_2 \sin m\theta)(k_1 \cos n\theta - k_2 \sin n\theta) + (q_1 \sin m\theta + q_2 \cos m\theta)(k_1 \sin n\theta + k_2 \cos n\theta) qm⋅kn=(q1cosmθ−q2sinmθ)(k1cosnθ−k2sinnθ)+(q1sinmθ+q2cosmθ)(k1sinnθ+k2cosnθ)
-
展开后结合三角函数差角公式,内积的最终结果为: q m ⋅ k n = ( q 1 k 1 + q 2 k 2 ) cos ( ( m − n ) θ ) + ( q 1 k 2 − q 2 k 1 ) sin ( ( m − n ) θ ) q_m \cdot k_n = (q_1 k_1 + q_2 k_2)\cos((m-n)\theta) + (q_1 k_2 - q_2 k_1)\sin((m-n)\theta) qm⋅kn=(q1k1+q2k2)cos((m−n)θ)+(q1k2−q2k1)sin((m−n)θ)
在等号的最右边, m m m 和 n n n 这两个绝对位置的变量,完全以 ( m − n ) (m-n) (m−n) 的形式绑定在了一起。这意味着,无论 q q q 在第 10 个词还是第 100 个词, k k k 在第 12 个词还是第 102 个词,只要它们的相对距离 ( m − n ) = − 2 (m-n) = -2 (m−n)=−2,它们算出来的 Attention 内积结果是一模一样的。
巧妙之处 :当计算 Attention 中的内积 q m ⋅ k n q_m \cdot k_n qm⋅kn 时,通过三角函数展开,内积的结果只依赖于相对位置 ( m − n ) (m - n) (m−n),这极大地增强了模型对文本相对距离的感知能力。 -
4. N层 Decoder-only Transformer Backbone
输入注入位置信息后,进入图4所示 的 N 层堆叠的 Transformer Block。每一层包含以下核心组件:
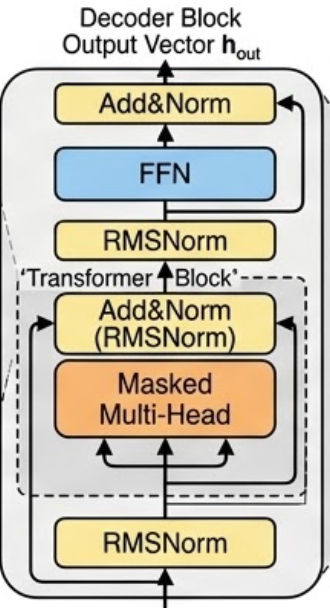
图4.Decoder-only 块结构图
A. 掩码多头注意力 (Masked Multi-Head Attention)
这是 LLM 的心脏。如图5所示 :
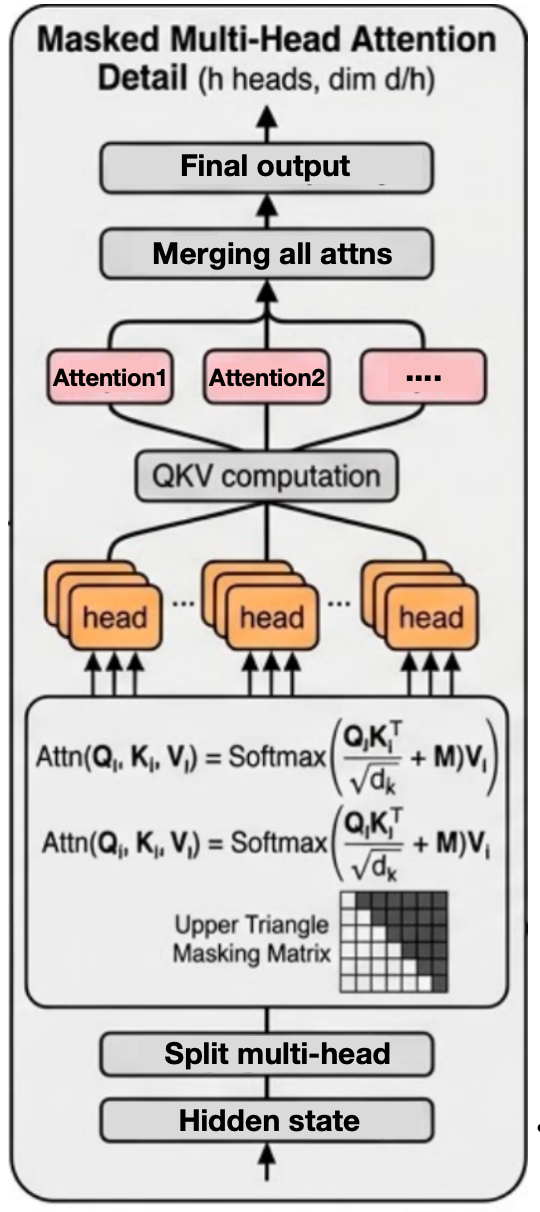
图5.多头注意力结构图
- QKV 计算 :输入特征 X X X 分别乘以三个权重矩阵 W Q , W K , W V W_Q, W_K, W_V WQ,WK,WV,得到查询(Query)、键(Key)和值(Value)。
- 多头切分 (Split Multi-head) :将高维的 Q, K, V 切分为 h h h 个头,每个头维度为 d k = d m o d e l / h d_k = d_{model} / h dk=dmodel/h。这使得模型能在不同的表示子空间(比如有的头关注语法,有的头关注主谓宾)并行计算注意力。(这里还可以参考我之前写的另一篇博客,介绍了优化版的 分组查询多头注意力机制)
- 核心注意力公式 :
Attn ( Q , K , V ) = Softmax ( Q K T d k + M ) V \text{Attn}(Q, K, V) = \text{Softmax}\left(\frac{Q K^T}{\sqrt{d_k}} + M\right)V Attn(Q,K,V)=Softmax(dk QKT+M)V- Q K T Q K^T QKT:计算词与词之间的相关性打分。
- 1 d k \frac{1}{\sqrt{d_k}} dk 1:缩放因子。防止内积过大导致 Softmax 进入梯度饱和区(后文反向传播会详述)。
- M M M (Upper Triangle Masking Matrix) :如图5的黑白网格所示 。在解码器中,我们必须保证"因果性(Causality)",即第 t t t 个 Token 只能看到 1 1 1 到 t t t 的 Token,不能看到 t + 1 t+1 t+1 之后的。矩阵 M M M 将右上角(未来信息)的值设为 − ∞ -\infty −∞。这样在过 Softmax 后,未来的概率权重就变成了 0 0 0。
B. 残差连接 (Residual Connection) 与 层归一化 (Add & Norm)
- 如图1中标注的"残差连接的"箭头所示 。公式: X o u t = Norm ( X i n + SubLayer ( X i n ) ) X_{out} = \text{Norm}(X_{in} + \text{SubLayer}(X_{in})) Xout=Norm(Xin+SubLayer(Xin))
- 底层原理 :随着网络加深(如 LLaMA 有 32 层或 80 层),前向信号会衰减,反向传播时梯度会连乘导致"梯度消失"。残差连接 X i n X_{in} Xin 提供了一条信息高速公路,使得梯度可以直接跨层回传。RMSNorm(现代LLM常用,省略了均值计算,只做方差归一化)则保证了特征在每一层的数值分布稳定。
C. 前馈神经网络 (Feed Forward Network - FFN)
Attention 负责统筹全局上下文(词与词的交互),而 FFN 负责对每个位置的词向量进行非线性特征变换(相当于对每个词的内在含义进行深度加工)。通常采用先升维(通常是 4 倍)再降维的结构,并配合激活函数 (如 SwiGLU)。
F F N ( x ) = R e L U ( x W _ 1 + b _ 1 ) W _ 2 + b _ 2 FFN(x) = ReLU(xW\_1 + b\_1)W\_2 + b\_2 FFN(x)=ReLU(xW_1+b_1)W_2+b_2
激活函数的发展史
第一阶段:早期的 S 型函数(古典时期)
早期神经网络主要模仿生物神经元的"激活"与"抑制"状态,因此偏爱将输出压缩到特定范围内的函数。
4.3.1. Sigmoid
- 计算公式: f ( x ) = 1 1 + e − x f(x) = \frac{1}{1 + e^{-x}} f(x)=1+e−x1
- 背景与因果: 最早被广泛使用的激活函数,将输入映射到 ( 0 , 1 ) (0, 1) (0,1) 区间,非常适合解释为"概率"或生物神经元的"发射率"。
- 致命缺陷(导致了它的淘汰): 梯度消失(Vanishing Gradient) 。当输入 x x x 非常大或非常小的时候,函数的导数趋近于 0 0 0。在多层网络反向传播时,梯度连乘会导致底层网络几乎无法更新权重。此外,它的输出不以 0 0 0 为中心,且包含耗时的指数运算。
4.3.2. Tanh (双曲正切)
- 计算公式: f ( x ) = e x − e − x e x + e − x f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} f(x)=ex+e−xex−e−x
- 背景与因果: 为了解决 Sigmoid 输出不以 0 0 0 为中心的问题,Tanh 被提出。它将输出映射到 ( − 1 , 1 ) (-1, 1) (−1,1)。
- 结果: 虽然收敛速度比 Sigmoid 快,但依然没有解决梯度消失的核心问题。
第二阶段:线性整流(深度学习的破局者)
为了解决深层网络无法训练(梯度消失)的问题,研究人员放弃了复杂的 S 型曲线,转向了极其简单的分段线性函数。
4.3.3. ReLU (Rectified Linear Unit)
- 计算公式: f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)
- 背景与因果: 深度学习爆发的最大功臣之一。当 x > 0 x > 0 x>0 时,梯度恒为 1 1 1,彻底解决了正区间内的梯度消失问题 。同时,它只需要判断是否大于 0 0 0,计算速度极快,且带来了网络的"稀疏性"(一部分神经元输出为 0 0 0)。
- 引入的新问题: 神经元死亡(Dying ReLU) 。如果输入 x < 0 x < 0 x<0,梯度直接变为 0 0 0。一旦某个神经元在训练中陷入负区间,它的权重就再也不会更新,相当于"死"了。
第三阶段:修补 ReLU 的缺陷(平稳过渡期)
为了解决"神经元死亡"问题,研究者们在 ReLU 的负区间做了各种微调。
4.3.4. Leaky ReLU & PReLU
- 计算公式: f ( x ) = max ( α x , x ) f(x) = \max(\alpha x, x) f(x)=max(αx,x)
- 背景与因果: 既然 ReLU 在负半轴梯度为 0 0 0 会导致神经元死亡,那么给负半轴一个微小的斜率 α \alpha α(例如 0.01 0.01 0.01)就能解决这个问题。如果 α \alpha α 作为一个可学习的参数让网络自己优化,这就是 PReLU (Parametric ReLU)。
- 结果: 虽然理论上比 ReLU 更好,但在实际应用中,性能提升往往不够稳定,因此并没有完全取代 ReLU。
第四阶段:平滑与非单调(Transformer 时代的宠儿)
随着网络结构的演进(尤其是 Transformer 的出现),人们发现 ReLU 在 0 0 0 点处不可导(有一个尖锐的折角),这在极其深层的复杂网络中可能不够平滑。研究者开始寻找兼具 ReLU 优点(无上限)和 Sigmoid 优点(平滑)的函数。
4.3.5. GELU (Gaussian Error Linear Unit)
- 计算公式: f ( x ) = x ⋅ Φ ( x ) f(x) = x \cdot \Phi(x) f(x)=x⋅Φ(x)
(其中 Φ ( x ) \Phi(x) Φ(x) 是标准正态分布的累积分布函数。常使用近似公式: f ( x ) ≈ 0.5 x ( 1 + tanh ( 2 π ( x + 0.044715 x 3 ) ) ) f(x) \approx 0.5x \left(1 + \tanh\left(\sqrt{\frac{2}{\pi}} (x + 0.044715x^3)\right)\right) f(x)≈0.5x(1+tanh(π2 (x+0.044715x3)))) - 背景与因果: 引入了随机正则化的思想。它在 0 0 0 附近是平滑的,并且允许少量的负值(非单调性)。这种平滑性和非单调性使得它在复杂的注意力机制和损失地形中表现极佳。
- 结果: 成为 BERT、GPT-2、ViT 等经典大模型的标配。
4.3.6. Swish (SiLU - Sigmoid Linear Unit)
- 计算公式: f ( x ) = x ⋅ σ ( β x ) = x 1 + e − β x f(x) = x \cdot \sigma(\beta x) = \frac{x}{1 + e^{-\beta x}} f(x)=x⋅σ(βx)=1+e−βxx
- 背景与因果: 谷歌通过架构搜索自动发现的激活函数。它的形状和 GELU 非常相似(平滑、非单调),在深层 CNN 和早期的语言模型中表现优异。
第五阶段:门控机制与组合进化(现代大语言模型的标配)
到了百亿、千亿参数的大语言模型(LLM)时代,单纯的激活函数已经不够用了,研究者开始将激活函数与网络结构(门控机制)融合,以获得更强的表达能力。
4.3.7. GLU (Gated Linear Unit) 及其变体
- 基础概念: GLU 并不是一个单一的函数,而是一个网络层结构。它将输入分裂成两部分,一部分经过线性变换,另一部分经过激活函数后充当"门控"(Gate),两者逐元素相乘。
公式: GLU ( x , W , V , b , c ) = ( x W + b ) ⊗ σ ( x V + c ) \text{GLU}(x, W, V, b, c) = (xW + b) \otimes \sigma(xV + c) GLU(x,W,V,b,c)=(xW+b)⊗σ(xV+c) - 背景与因果: 门控机制允许网络动态地控制哪些信息可以通过,极大地增强了前馈神经网络(FFN)的表达能力。
4.3.8. SwiGLU (Swish-Gated Linear Unit)
- 计算公式: SwiGLU ( x , W , V ) = ( x W ) ⊗ Swish ( x V ) \text{SwiGLU}(x, W, V) = (xW) \otimes \text{Swish}(xV) SwiGLU(x,W,V)=(xW)⊗Swish(xV)
(其中 ⊗ \otimes ⊗ 表示逐元素相乘,通常会省略偏置项,并搭配一个额外的权重矩阵 W 2 W_2 W2 来投影回原来的维度) - 背景与因果: 研究者(如 Noam Shazeer)发现,如果在 GLU 结构中,把作为门控激活函数的 Sigmoid 替换成表现更好的 Swish,能取得极其惊艳的实证效果。它在保持计算效率的同时,显著提升了模型的收敛速度和最终性能。
- 结果: 统治了当今的开源大模型界。LLaMA 系列、PaLM、Grok、Qwen 等目前顶流的大语言模型,几乎全部采用了 SwiGLU 作为 Transformer 中 FFN 层的激活结构。
总结:演进的激活函数因果链
- Sigmoid/Tanh → 导致梯度消失 \xrightarrow{\text{导致梯度消失}} 导致梯度消失 ReLU
点评:简单粗暴,解决深层训练问题 - ReLU → 导致神经元死亡 \xrightarrow{\text{导致神经元死亡}} 导致神经元死亡 Leaky ReLU
点评:修补ReLU缺陷 - ReLU/Leaky ReLU → 折角不平滑,表达能力受限 \xrightarrow{\text{折角不平滑,表达能力受限}} 折角不平滑,表达能力受限 GELU/Swish
点评:平滑、非单调,称霸早期 Transformer - Swish → 结合门控机制提升参数利用率 \xrightarrow{\text{结合门控机制提升参数利用率}} 结合门控机制提升参数利用率 SwiGLU
点评:成为现代大语言模型的绝对标配
5. 输出层 (lm_head 与 Softmax)
经过 N 层特征提取后,我们得到了包含极度丰富的上下文语义的 Hidden States。
- lm_head :如LLM架构图右侧所示 ,这是一个线性分类层,将 d m o d e l d_{model} dmodel 维的向量投影回字典大小 V V V 维。输出的结果称为 Logits(未归一化的得分)。
- Softmax :将 Logits 转化为合法的概率分布(Vocab Probabilities)。
P ( y i ) = e l o g i t i ∑ j = 1 V e l o g i t j P(y_i) = \frac{e^{logit_i}}{\sum_{j=1}^{V} e^{logit_j}} P(yi)=∑j=1Velogitjelogiti
推理与训练的分野在此产生:- 推理时(Inference) :如架构图右侧的 Sampling,我们会根据这些概率,通过 Argmax 或 Top-p/Top-k 采样出一个具体的 Token ID(更详细的采样算法请见我的另一篇文章 LLM 推理时的温度值、top_p、top_k等采样算法原理),然后通过"Autoregressive Feedback"(自回归反馈虚线)将这个新 Token 喂回输入端,生成下一个词。
- 训练时(Training) :我们不需要采样 (训练时只需要计算 交叉熵loss: -log(logitslabel 左移一位) ),也不需要自回归地跑 N 遍。我们使用 教师强制(Teacher Forcing) 机制实现并行化。
第二部分:训练数据的构造与 Mask Label (训练特有)
在全参数有监督微调(Supervised Fine-Tuning, SFT)阶段,我们需要让模型学习人类的对话模式。
1. Causal Language Modeling (CLM) 与 Shifted Right
LLM 的训练目标极其简单:预测下一个词(Next Token Prediction) 。
假设有一条训练数据:
- Input : "你好" (
[Prompt]) - Target : "我是AI" (
[Answer])
在输入模型时,我们将它们拼接:<|im_start|>user:你好<|im_end|><|im_start|>assistant:我是AI<|im_end|>
经过前向传播,模型在每一个 Token 的位置都会输出一个针对下一个 Token 的概率分布。因此,在计算 Loss 时,标签(Labels)实际上是输入(Inputs)向左平移(Shifted Left)一个位置 。
即:模型根据 "你",预测 "好";根据 "你"+"好",预测 [<|im_end|>],以此类推。画个图直观感受下:
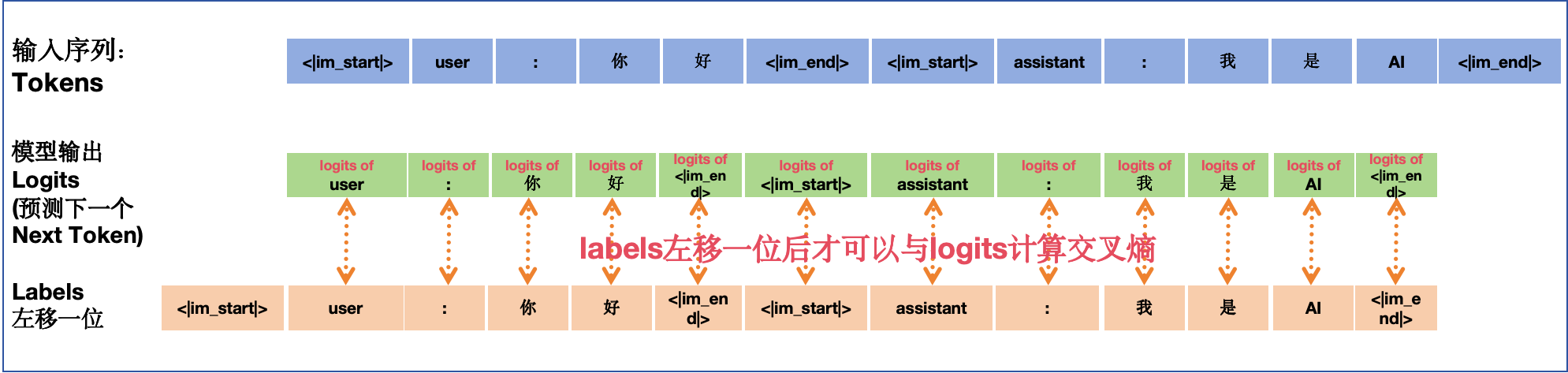
2. Label Masking (Loss 掩码) ------ SFT 的关键
在 SFT 阶段,我们希望模型学习的是"如何回答问题",而不是"如何背诵用户的问题"。因此,我们不应该对用户Prompt部分计算损失。
-
具体做法 :在深度学习框架(如 PyTorch)的交叉熵损失函数中,有一个参数叫做
ignore_index(默认通常是 -100)。 -
我们将构造好的整句输入模型,得到所有位置的 Logits。
-
我们在构造 Labels 列表时,将属于 Prompt 部分的 Label ID 替换为
-100。- Inputs:
[<|im_start|>, user, :, 你, 好, <|im_end|>, <|im_start|>, assistant, :, 我, 是, AI, <|im_end|>] - Labels:
[-100, -100, -100, -100,-100,-100,-100, assistant, :, 我, 是, AI, <|im_end|>]
显然模型需要预测的只有
assistant:我是AI<|im_end|>即可,因此前面的部分都不计算loss。 - Inputs:
-
底层意义 :当计算 Loss 时,遇到
-100的位置,Loss 直接计为 0,并且在反向传播时,这些位置不会产生梯度,因此不会更新模型参数。这样,模型就把所有精力(参数更新的动力)放在了拟合[Answer]部分上。同时,对于 Batch 训练时因长度不同而填充的[PAD]token,同样使用-100进行 Mask。
第三部分:Loss 计算的底层原理 (训练特有)
1. 核心基石:交叉熵损失 (Cross-Entropy Loss)
大模型全参数微调的主力 Loss 永远是交叉熵。
-
公式 :对于单个样本的一个序列,其交叉熵损失为:
L C E = − 1 N ∑ i = 1 N ∑ c = 1 V y i , c log ( y ^ i , c ) \mathcal{L}{CE} = - \frac{1}{N} \sum{i=1}^{N} \sum_{c=1}^{V} y_{i,c} \log(\hat{y}_{i,c}) LCE=−N1i=1∑Nc=1∑Vyi,clog(y^i,c)- N N N: 回答部分的序列长度(未被 Mask 的 Token 数量)。
- V V V: 词表大小(Vocab Size,比如 32000 或 100000+)。
- y i , c y_{i,c} yi,c: 真实标签(Ground Truth)。它是一个 One-hot 向量。比如真实下一个词是"我"(假设其在词表索引为 5),那么只有 y i , 5 = 1 y_{i,5} = 1 yi,5=1,其余为 0。
- y ^ i , c \hat{y}_{i,c} y^i,c: 也就是架构图中"Vocab Probabilities",模型预测的每个词的概率。
-
简化版公式(由于 y y y 是 One-hot) :
我们只需要看真实标签那个位置模型给出的概率:
L C E = − 1 N ∑ i = 1 N log P ( 真实词 i ∣ 前置上下文 < i ) \mathcal{L}{CE} = - \frac{1}{N} \sum{i=1}^{N} \log P(\text{真实词}i | \text{前置上下文}{<i}) LCE=−N1i=1∑NlogP(真实词i∣前置上下文<i) -
为什么用交叉熵?最大似然估计(MLE)视角
从统计学角度看,我们希望最大化训练集中所有真实序列出现的概率(极大似然估计):
Maximize ∏ i = 1 N P ( x i ∣ x < i ) \text{Maximize} \prod_{i=1}^{N} P(x_i | x_{<i}) Maximizei=1∏NP(xi∣x<i)连乘在计算机中容易导致数值下溢,所以两边取对数(Log),变成连加。最大化似然等价于最小化负对数似然(Negative Log-Likelihood, NLL),这在数学上推导出来的结果,完美等价于交叉熵!
总结
- 交叉熵只关注概率最大的那个token是预期的token即可,并不追求其他非目标token的概率准确性! 简单说,只要logits中最大概率那个词是目标token(假设是 "我"),且该token的概率最大化(假设是0.9)就好了,其他token概率和为0.1(比如其他token还有 "是"和 "AI"),那么他俩的概率分布不再被关注,可以是0.05, 0.05, 也可以是0.01, 0.09。
- 交叉熵会驱使模型输出logits中对应label token的概率越大越好(训练自信),可能会导致模型变得死板,容易过拟合,泛化能力差
2. 进阶 Loss 选择与变种
虽然交叉熵是绝对主力,但在某些微调场景(尤其是避免模型生成重复废话、有毒内容,或者解决类别极度不平衡时),会引入其他 Loss:
A. 标签平滑 (Label Smoothing Loss)
- 应用场景:如果模型在训练集上过度自信(Overconfident),即对真实标签给出 0.999 的概率,这会导致模型变得死板,容易过拟合,泛化能力差。
- 底层原理 :不给真实标签 100% 的目标,而是分一点点"同情分"给词表中的其他所有词。
将 One-hot 标签 y y y 修改为软标签 y L S y^{LS} yLS:
y c L S = { 1 − α + α V , if c = target α V , if c ≠ target y^{LS}_c = \begin{cases} 1 - \alpha + \frac{\alpha}{V}, & \text{if } c = \text{target} \\ \frac{\alpha}{V}, & \text{if } c \neq \text{target} \end{cases} ycLS={1−α+Vα,Vα,if c=targetif c=target
其中 α \alpha α 是平滑参数(通常设为 0.1),V是词表大小。这样算出的 Cross Entropy 会迫使模型保留一些探索性。 - loss计算公式 :
L LS = − ( 1 − α ) log p y − ∑ c = 1 V α V log p c \mathcal{L}{\text{LS}} = -(1-\alpha) \log p_y - \sum{c=1}^{V} \frac{\alpha}{V} \log p_c LLS=−(1−α)logpy−c=1∑VVαlogpc
其中 p y p_y py 是模型对真实类别的预测概率, p c p_c pc 是模型对非真实类别的预测概率。此时其他token的概率值也会对loss产生影响,因此进一步影响梯度,会反向更新模型参数。
B. 非似然训练损失 (Unlikelihood Training Loss)
- 应用场景 :大模型经常出现"复读机"现象。如果我们明确知道哪些词是不应该生成的(比如重复生成的短语,或者负面/有害回答)。
- 公式 :对于负面集合 C n e g C_{neg} Cneg 中的词:
L U L = − ∑ c ∈ C n e g log ( 1 − y ^ c ) \mathcal{L}{UL} = - \sum{c \in C_{neg}} \log(1 - \hat{y}_{c}) LUL=−c∈Cneg∑log(1−y^c)
即:我们要最大化"不 生成该词的概率",很显然, y c y_c yc越大则loss越大。这可以作为辅助 Loss 加在标准交叉熵之上。
C. Focal Loss (多用于检测领域,但在长尾词语预测中也有探索)
- 底层原理 :大模型词表极大,有些词(如"的"、"了")出现频率极高,模型很容易预测;有些生僻词很难预测。Focal Loss 旨在让模型降低对简单样本的关注度,专注于难样本(Hard examples)。
L F o c a l = − ( 1 − y ^ t a r g e t ) γ log ( y ^ t a r g e t ) \mathcal{L}{Focal} = - (1 - \hat{y}{target})^\gamma \log(\hat{y}_{target}) LFocal=−(1−y^target)γlog(y^target)
如果预测概率 y ^ \hat{y} y^ 已经很高(简单样本), ( 1 − y ^ ) γ (1-\hat{y})^\gamma (1−y^)γ 就会接近 0,从而降低其对总 Loss 的贡献。
第四部分:反向传播 (Backpropagation) ------ 梯度下降的灵魂 (训练特有)
在推理时,数据如长河般从左流向右(从底流向顶),结束。在训练时,当我们在最顶端计算出 Loss 后,真正的魔法才刚刚开始。这就是误差的反向传播。它是微调与推理最核心的区别,也是为什么训练显存消耗是推理的 3-4 倍以上的根本原因。
1. 反向传播的数学基石:链式法则 (Chain Rule)
反向传播的目标是:计算出 Loss 对模型中每一个权重矩阵(如 W Q , W K , W V W_Q, W_K, W_V WQ,WK,WV、FFN、llm_head 等的权重)的 偏导数(梯度 ∂ L ∂ W \frac{\partial \mathcal{L}}{\partial W} ∂W∂L),从而告诉这些权重,它们应该朝哪个方向微调,才能让 Loss 下降。
2. 根据logits计算梯度值 (极其优雅的数学结果)
让我们看看反向传播是如何跨出第一步的。如LLM架构图1右侧的 Softmax 和 lm_head ,假设输出 Logits 为 z 1 , z 2 , . . . , z V z_1, z_2, ..., z_V z1,z2,...,zV。
交叉熵 Loss 对第 i i i 个 Logit z i z_i zi 的偏导数是多少?
- 经过复杂的数学推导(Softmax 的导数结合对数的导数),最终的结果极其简洁:
∂ L ∂ z i = y ^ i − y i \frac{\partial \mathcal{L}}{\partial z_i} = \hat{y}_i - y_i ∂zi∂L=y^i−yi - 详细解读 :这个公式美得令人窒息。
- y ^ i \hat{y}_i y^i 是模型预测概率(0 到 1 之间)。
- y i y_i yi 是真实标签(0 或 1)。
- 如果目标词是"AI"( y A I = 1 y_{AI} = 1 yAI=1),模型预测概率是 0.2,那么梯度就是 0.2 − 1 = − 0.8 0.2 - 1 = -0.8 0.2−1=−0.8。负号意味着需要增加这个 Logit 的值。
- 对于非目标词( y o t h e r = 0 y_{other} = 0 yother=0),模型如果给出了 0.1 的概率,梯度就是 0.1 − 0 = + 0.1 0.1 - 0 = +0.1 0.1−0=+0.1。正号意味着需要减小这个 Logit 的值。
- 计算极其高效:不需要复杂的矩阵求逆,只需要一次减法操作!
3. 梯度在 Transformer Backbone 中的逆流
拿到对 Logits 的梯度后,这股梯度之流开始从上往下(或者说从图的右侧向左侧)穿越整个 "N层 Decoder-only Transformer Backbone"。
- 穿越线性层 (
lm_head) : z = W h e a d ⋅ h + b z = W_{head} \cdot h + b z=Whead⋅h+b。通过链式法则,可以求出对权重 W h e a d W_{head} Whead 的梯度,以及继续向下传给上一层隐状态 h h h 的梯度。 - 穿越 Add & Norm (LayerNorm / RMSNorm) :由于前向传播做了归一化(涉及到方差计算),这里的反向求导非常繁杂。(这也是为什么训练时必须在显存中保存前向传播时的 Activation(激活值),如果不保存前向的 h h h,反向传播的公式就无法计算!这是导致训练显存爆炸的核心元凶)。
- 穿越多头注意力 (Masked Multi-Head Attention) :
如架构图左上角的详细展开图 ,梯度要穿过那个核心公式 S o f t m a x ( Q K T d k + M ) V Softmax(\frac{QK^T}{\sqrt{d_k}} + M)V Softmax(dk QKT+M)V。- 这里揭示了为什么要除以 d k \sqrt{d_k} dk 。如果不除,内积 Q K T QK^T QKT 的方差会随着维度 d k d_k dk 变大而极大。方差变大意味着输入给 Softmax 的数值会非常大(比如出现 100, 200 这样的值)。
- 梯度消失危机 :Softmax 对于极大值的区域非常平缓(极端的赢者通吃)。在这段平缓区,其导数(梯度)趋近于 0。一旦 Softmax 的梯度变成 0,根据链式法则,整个网络下面所有层的梯度都会变成 0,模型参数将停止更新!所以 1 d k \frac{1}{\sqrt{d_k}} dk 1 保护了反向传播的稳定性。
第五部分:优化器 (Optimizer) ------ 模型权重的更新机器
拿到了所有参数的梯度 ∇ L ( W ) \nabla \mathcal{L}(W) ∇L(W) 后,如何去更新原来的权重 W W W?单纯的 W n e w = W o l d − Learning_Rate × ∇ L ( W ) W_{new} = W_{old} - \text{Learning\_Rate} \times \nabla \mathcal{L}(W) Wnew=Wold−Learning_Rate×∇L(W) (标准的 SGD)在十亿/百亿参数的 LLM 中极其低效且容易陷入局部最优或鞍点。
在 LLM 的全参数微调中,AdamW 优化器是绝对的霸主。它的底层原理结合了动量(Momentum)和自适应学习率。
1. AdamW 的底层数学公式
Adam 优化器在内部维护了两个与模型参数同样大小的"状态矩阵"(Optimizer States),这也是训练显存消耗的另一大头。
步骤 1:计算动量(一阶矩,First Moment)
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t mt=β1mt−1+(1−β1)gt
( g t g_t gt 是当前的梯度, β 1 \beta_1 β1 通常取 0.9)。
- 物理意义 :当前梯度的方向可能因为数据 Batch 的噪声而剧烈抖动。 m t m_t mt 类似于物理中的惯性。如果过去一直往某个方向走,当前由于噪声给了一个反方向的梯度, m t m_t mt 可以中和这种突变,保持整体的前进方向平滑。
步骤 2:计算自适应学习率(二阶矩,Second Moment / RMSprop)
v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 vt=β2vt−1+(1−β2)gt2
( β 2 \beta_2 β2 通常取 0.999, g t 2 g_t^2 gt2 是梯度的平方)。
- 物理意义 :它记录了历史梯度的幅度。在更新时,我们会除以 v t \sqrt{v_t} vt 。这意味着,对于那些过去梯度一直很大(更新很猛烈)的参数,我们会降低它的学习率,防止走过头;对于过去一直梯度很小的参数,我们会增大它的学习率,帮它加速。
步骤 3:偏差校正 (Bias Correction)
由于 m m m 和 v v v 初始值为 0,在训练初期它们会严重偏向 0,需要放大:
m ^ t = m t 1 − β 1 t \hat{m}_t = \frac{m_t}{1 - \beta_1^t} m^t=1−β1tmt, v ^ t = v t 1 − β 2 t \hat{v}_t = \frac{v_t}{1 - \beta_2^t} v^t=1−β2tvt
步骤 4:权重更新与 Weight Decay (权重衰减 - The "W" in AdamW)
W t = W t − 1 − η m ^ t v ^ t + ϵ − η λ W t − 1 W_t = W_{t-1} - \eta \frac{\hat{m}_t}{\sqrt{\hat{v}t} + \epsilon} - \eta \lambda W{t-1} Wt=Wt−1−ηv^t +ϵm^t−ηλWt−1
( η \eta η 是学习率, λ \lambda λ 是 Weight Decay 系数)。
- 细节差异 :传统的 L2 正则化是把惩罚项加在 Loss 里,这在 Adam 这种带自适应分母的优化器中会导致惩罚效果变形。AdamW 解耦了权重衰减 ,直接在最后一步对 W t − 1 W_{t-1} Wt−1 按比例缩小一点点( − η λ W t − 1 -\eta \lambda W_{t-1} −ηλWt−1),这被证明能极大地提升大模型的泛化能力。
2. 学习率调度 (Learning Rate Scheduler)
在微调 LLM 时,学习率 η \eta η 不是固定的。通常采用 Warmup + Cosine Decay 策略。
- Warmup(预热):训练刚开始时,模型参数面对新的数据分布,梯度巨大。如果直接用最大的学习率,会把原来预训练好的漂亮参数(如架构图中的 Embedding 和 Attention 权重)直接"炸毁"。所以前几个 Step,学习率从 0 慢慢爬升到最大值。
- Cosine Decay(余弦衰退):随后,学习率按照余弦曲线平缓下降,直到训练结束趋近于 0,帮助模型在全局最优点附近精细收敛。
第六部分:防止灾难性遗忘与 KL散度 (高级正则化)
在全参数微调时,尤其是如果你只用某一垂直领域的语料(比如纯医疗问答,或特定角色的对话)去 Fine-tune 一个通用大模型(如 LLaMA-2-7B),模型极度容易发生灾难性遗忘(Catastrophic Forgetting) 和 参数漂移:即模型学会了当医生,却忘记了怎么用标准的中文说话,甚至丧失了原本的逻辑推理能力。
"KL散度防止参数大规模偏移",这是 RLHF(基于人类反馈的强化学习)和一些高级 SFT 变体中的核心底层思想。
1. KL 散度 (Kullback-Leibler Divergence) 的底层数学
KL 散度是信息论中用来衡量两个概率分布之间差异的非对称指标。
D K L ( P ∣ ∣ Q ) = ∑ x P ( x ) log ( P ( x ) Q ( x ) ) D_{KL}(P || Q) = \sum_{x} P(x) \log \left( \frac{P(x)}{Q(x)} \right) DKL(P∣∣Q)=x∑P(x)log(Q(x)P(x))
2. 在 RLHF / PPO 中的具体应用 (作为惩罚项)
在 RLHF 阶段(紧接在 SFT 之后),我们训练一个 Reward Model 来给模型的输出打分。然后用 PPO(Proximal Policy Optimization)算法来微调 LLM 最大化这个分数。
- 问题:如果只一味最大化 Reward,模型会找到 Reward 模型的漏洞(Reward Hacking),输出一些人类看不懂但得分极高的乱码。
- 解决方案:引入 KL 惩罚 。
在训练时,我们会同时在内存中加载两个模型 :- Actor Model ( P θ P_{\theta} Pθ):正在被微调更新的模型。
- Reference Model ( P r e f P_{ref} Pref):微调开始前冻结(Frozen)的原始模型。
- 当对于同一个输入 x x x(如"如何治疗感冒"),Actor 模型准备输出一个回答序列 y y y 时,我们不仅计算 Reward 打分 r ( x , y ) r(x, y) r(x,y),还会计算当前模型分布与原始模型分布的 KL 散度:
Reward t o t a l = r ( x , y ) − β log P θ ( y ∣ x ) P r e f ( y ∣ x ) \text{Reward}{total} = r(x, y) - \beta \log \frac{P{\theta}(y | x)}{P_{ref}(y | x)} Rewardtotal=r(x,y)−βlogPref(y∣x)Pθ(y∣x) - 底层原理解释 : log P θ P r e f \log \frac{P_{\theta}}{P_{ref}} logPrefPθ 实际上是逐 Token 估算的 KL 散度。如果 Actor 模型为了迎合高分,使得输出某个词的概率 P θ P_{\theta} Pθ 远远偏离了原始模型 P r e f P_{ref} Pref 的概率,惩罚项就会变得极大,将总 Reward 拉低。
- 结论 :通过这种机制,反向传播在更新架构图中的 Q , K , V Q,K,V Q,K,V 权重时,就被加上了一副"枷锁"。这副枷锁强迫微调后的模型在提升特定任务表现的同时,尽量保持其行为分布在原始预训练模型周围不发生严重偏移,从而保住了通用能力。
3. DPO (直接偏好优化) 中的隐式 KL 散度
目前的最新趋势是用 DPO 替代 PPO 算法,因为它不需要在内存里多放一个庞大的 Reward Model。有趣的是,DPO 算法的底层公式推导,本质上是将带有 KL 散度约束的强化学习目标函数,在数学上等价转换成了一个纯分类 Loss。即它通过给定的好答案 y w y_w yw 和坏答案 y l y_l yl,结合 Reference Model 的先验概率,隐式地完成了 KL 约束,防止参数过度偏移。
第七部分:全参数微调的工程现实 ------ 突破显存墙 (Memory Wall)
假设你要全参数微调一个 7B (70亿参数) 的 LLaMA 模型。如果你觉得显存只存模型参数(7B × \times × 2 Byte (FP16精度) ≈ \approx ≈ 14GB),那就大错特错了。
1. 训练时的显存灾难:
正如前面反向传播和优化器部分提到的,全参数微调时,显存中需要容纳:
- 模型参数 (Weights): FP16 精度下占 14GB。
- 优化器状态 (Optimizer States) : AdamW 需要存 m t m_t mt (一阶动量) 和 v t v_t vt(二阶学习率)。并且为了保证更新精度,通常在内部转为 FP32(4 Byte)计算。所以优化器状态需要 7 B × 2 × 4 Byte = 56GB 7B \times 2 \times 4 \text{ Byte} = \textbf{56GB} 7B×2×4 Byte=56GB。
- 梯度 (Gradients) : FP32下,又需要 28GB \textbf{28GB} 28GB。
- 激活值 (Activations): 如架构图中,N层 Transformer 中的前馈网络和 Attention 产生的中间结果(Hidden States)。根据 Batch Size 和 Sequence Length,这部分可能占用数十甚至上百GB!
总计:微调一个 7B 模型,在不加任何优化的全参数设置下,轻易需要 100GB+ 显存,一张 80GB 的 A100 都跑不起来!
2. 解决方案 A:ZeRO 显存冗余消除技术 (DeepSpeed / FSDP)
如何在多张 GPU 上做全参数微调?
- 数据并行 (Data Parallel, DP) 的缺陷:每个 GPU 都拷贝了一份完整的 100GB 状态,极度浪费。
- ZeRO 的底层原理 :
- ZeRO-1 :将 56GB 的优化器状态切块,分散到不同 GPU 上。
- ZeRO-2 :不仅切优化器状态,把 28GB 的梯度也分散开来。
- ZeRO-3 :极致切割。连 模型参数(Weights) 本身也切开。每张卡只保留自己负责的一小部分。前向传播(如架构图流转)走到某一层的 Multi-Head Attention 时,GPU 会通过网络通讯(All-Gather)临时从其他卡上把这一层的参数"借"过来组装完整,算完后立刻丢弃(释放显存),再算下一层。
- 通过 ZeRO 技术,我们才能用几张显卡拼凑起全参数微调所需的庞大内存池。
3. 解决方案 B:梯度检查点 (Gradient Checkpointing / Activation Recomputation)
解决上面提到的第4点(激活值占用巨大)。
- 底层原理 :我们不在前向传播时保存所有 N 层 Transformer 的激活值了,而是只每隔几层保存一个"检查点"(比如只存第1、5、10层的中间状态)。
- 代价与收益:当反向传播(Backprop)需要用到第 3 层的激活值时怎么办?它从第 1 层的检查点**重新进行一次前向计算(Recompute)**推导出来。
- 本质:用计算时间换取显存空间。它能将激活值显存占用降低几倍到十几倍,使得大 Batch Size 长文本的微调成为可能。
4. 数据精度:混合精度训练 (Mixed Precision - BF16)
现代 LLM 微调几乎全都采用 Bfloat16 (Brain Floating Point)。
传统的 FP16 指数位较少,在反向传播计算梯度时(比如越靠近底层的 Embedding 层,梯度通过几十层衰减后可能非常小),容易发生数值下溢(Underflow)变为 0。
Bfloat16 牺牲了尾数精度(有效数字变少了),但指数位与 FP32 完全一致,这意味着它的动态范围极广,几乎完全杜绝了梯度下溢问题,是全参数大模型训练的最佳拍档。
总结
回顾LLM架构图 :
从 Input Text 进入 Tokenizer,化作词向量融入 RoPE,历经 Masked Multi-Head Attention 的语义融会贯通与 FFN 的非线性升华,最终由 lm_head 投影出星辰般的 Vocab Probabilities。
而当我们走向**全参数微调(Training)**时:
我们引入了 Teacher Forcing 和 Shifted Right,对用户的 Prompt 施加 -100 的 Mask Label,只对输出目标计算交叉熵 Cross-Entropy Loss。随后,Loss 的误差信号通过微积分的链式法则化作 Gradients,如逆流般穿透数十层 Transformer 结构。在底层,AdamW 优化器如同精密的齿轮,通过动量与 RMSprop 计算出精确的参数步长;KL 散度作为规则的锁链防止模型走火入魔;而底层的 ZeRO 和 Gradient Checkpointing 技术则在物理层面突破了硅基显存的极限。
这一切复杂的数学与工程交织,才最终成就了将一个原始的大模型雕琢成一个具备专业领域知识和完美对话逻辑的超级AI的壮举。