论文信息
论文题目: Learning to Retrieve In-Context Examples for Large Language Models - EACL 2024
论文作者: Liang Wang, Nan Yang, Furu Wei - MSR
论文链接: https://aclanthology.org/2024.eacl-long.105/
论文关键词: In-Context Learning (ICL), Large Language Models (LLMs), Prompt Retrieval
研究背景与动机
随着大语言模型(LLM)的规模增长,模型展现出了 In-Context Learning (上下文学习) 的能力,即无需更新模型参数,仅通过在 Prompt 中加入少量示例(Few-shot examples),就能让模型学会处理新任务。
然而,研究发现 LLM 对这些示例极其"挑剔":
- 敏感性(Sensitivity): 即便选择语义相似的例子,如果顺序不同、逻辑步长不一或格式略有差异,LLM 的准确率可能会从 90% 跌落到 50%。
- 任务失配(Mismatch): 传统的检索器(如 BM25)是基于关键词匹配的,而 LLM 真正需要的是能启发其推理逻辑的例子。"看起来像"的例子不等于"好用"的例子。
在 LLM-R 出现之前,学术界主要使用以下两种方式选择示例,但各有利弊:
- 无监督检索(如 BM25, SimCSE):
- 优点:速度快,无需训练。
- 缺点:只看语义表面相似度,完全不理解 LLM 的"口味"。
- 有监督检索(基于人工标注):
- 优点:目标明确。
- 缺点:人工标注极其昂贵且难以规模化;更重要的是,人工认为"好"的例子,LLM 并不一定觉得好用。
研究背景中的核心矛盾在于:缺乏一种低成本、高精度且能与特定 LLM 偏好对齐的检索训练方案。
以往的研究尝试直接用 LLM 作为检索器,但面临以下挑战:
- 推理开销(Inference Cost):LLM 无法在海量候选库中进行实时检索。
- 黑盒属性:LLM 的偏好是隐性的,难以直接提取并转化为可高效运行的检索参数。
在这样的背景下,本文的作者想到:
既然 LLM 本身就是"最终用户",那为什么不直接利用 LLM 的反馈(似然概率)来反向训练一个"懂它"的检索器呢?
于是论文提出 LLM-R(Retriever) 框架试图打破"通用检索"的局限,转向 "面向生成任务的定制化检索" 。它通过将 LLM 产生的隐性偏好( log P \log P logP)转化为显性的奖励信号,解决了检索器与生成器之间"认知不对称"的顽疾。
LLM-R
LLM-R 的核心目标是训练一个稠密检索器 R \mathcal{R} R,使其能够从候选库 C \mathcal{C} C 中为输入查询 x x x 检索出最能提升大语言模型 M \mathcal{M} M 性能的 k k k 个示例。
LLM-R(LLM Retriever) 框架包含四个阶段:
- Training data generation
- Reward Modeling
- Training LLM Retrievers with Knowledge Distillation
- Evaluation of LLM Retrievers
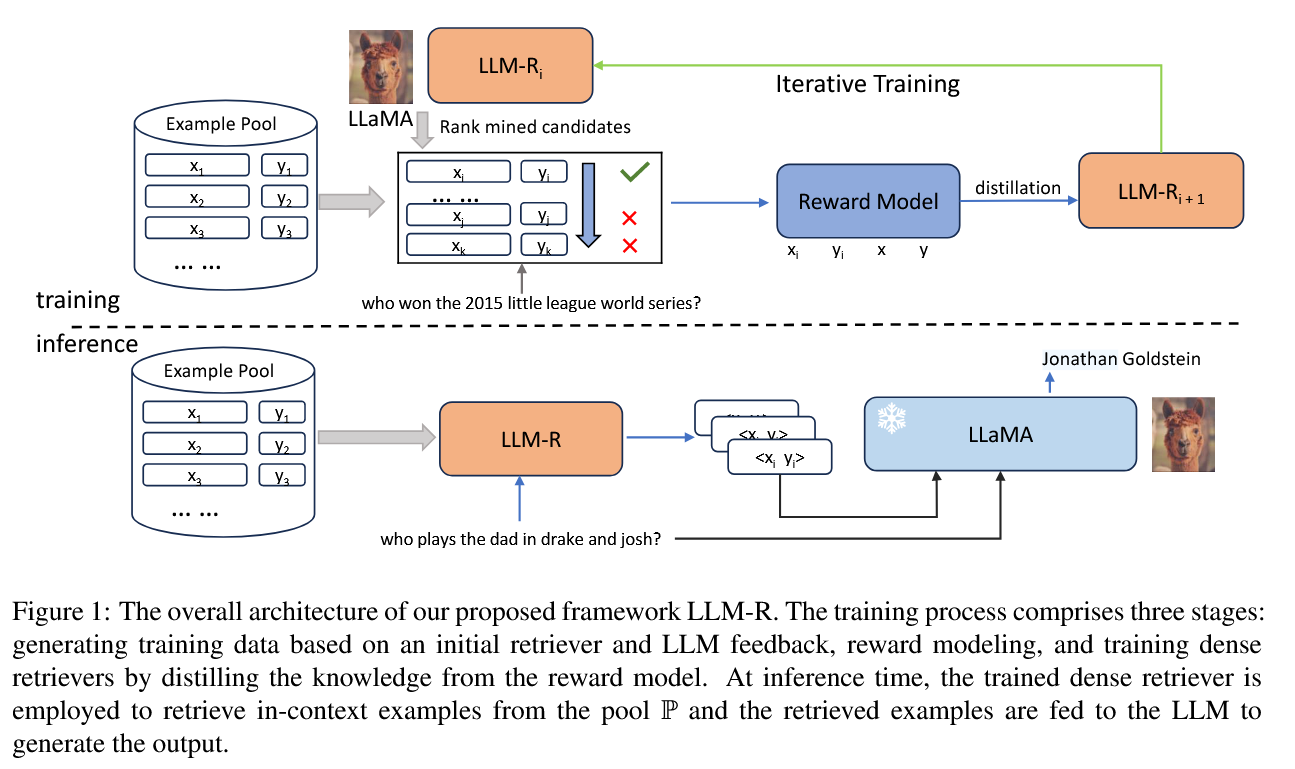
阶段一:Training Data Generation
这一阶段的目的是通过 LLM 反馈 得到 符合 LLM 生成偏好的标签数据:
- 初始检索: 给定训练查询 x x x,利用基础检索器(如 BM25)从示例库中召回 n n n 个候选示例 { d 1 , d 2 , ... , d n } \{d_1, d_2, \dots, d_n\} {d1,d2,...,dn}。
- 获取 LLM 反馈分数: 将每个示例 d i = ( x i , y i ) d_i = (x_i, y_i) di=(xi,yi) 与 x x x 拼接,输入至 LLM M \mathcal{M} M,计算目标输出 y y y 的对数似然概率 (Log-likelihood) 作为奖励信号 r i r_i ri:
r i = log P M ( y ∣ x , d i ) r_i = \log P_{\mathcal{M}}(y | x, d_i) ri=logPM(y∣x,di)
由此,我们获得了一组带有 LLM 偏好标注的数据对 { ( x , d i , r i ) } i = 1 n \{(x, d_i, r_i)\}_{i=1}^n {(x,di,ri)}i=1n。
注意:为了模拟 test 场景, 这里的候选实例中不包含标准答案 ( x , y ) (x,y) (x,y).
阶段二:Reward Modeling
本阶段的目标是 训练一个交叉编码器 f C E f_{CE} fCE 来模拟 LLM 的偏好。交叉编码器能够捕捉查询与示例之间的细粒度交互。
- 打分机制: f C E f_{CE} fCE 输入拼接后的序列 ( x , d i ) (x, d_i) (x,di),输出一个标量分数 s i = f C E ( x , d i ) s_i = f_{CE}(x, d_i) si=fCE(x,di)。
- 训练目标:使用对比学习损失(Contrastive Loss),将排序问题转化为多分类问题。对于正样本 d + d^+ d+( r r r 值最高的示例)和负样本集 { d j − } \{d_j^-\} {dj−}:
L R M = − log exp ( s + / τ ) exp ( s + / τ ) + ∑ j = 1 m exp ( s j − / τ ) \mathcal{L}{RM} = - \log \frac{\exp(s^+ / \tau)}{\exp(s^+ / \tau) + \sum{j=1}^{m} \exp(s_j^- / \tau)} LRM=−logexp(s+/τ)+∑j=1mexp(sj−/τ)exp(s+/τ)
其中 τ \tau τ 是调节分布平滑度的温度系数。
为什么选择 交叉编码器?(交叉编码器和双编码器的区别)
-
Bi-encoder (双编码器): 它的 Query(问题)和 Document(示例/文档)是独立编码的。它们像两辆并行的车,互不干扰,直到最后才在"终点"计算一个简单的余弦相似度(点积)。
-
Cross-encoder (交叉编码器): 它要求 Query 和 Document 合并输入。这意味着它们在通过模型时,每一层都在进行复杂的字词交互(Attention)。
A. 预计算与索引 (Pre-computation & Indexing)
在 Bi-encoder 中,你可以提前把库里的 100 万个示例全部跑一遍模型,得到 100 万个向量(Embedding),并存入向量数据库(如 FAISS)。
当用户输入一个新问题时,你只需要对这一个问题做一次模型推理。
剩下的工作只是在数据库里做向量匹配(Vector Search)。这种数学运算极其简单,配合高效的索引算法,几毫秒就能从百万数据中找到结果。
阶段三:Training LLM Retrievers with Knowledge Distillation
由于基于交叉编码器的 f C E f_{CE} fCE 推理速度慢,需要通过知识蒸馏将能力传递给高效的双编码器检索器 f B i f_{Bi} fBi。
-
概率分布对齐:
- 教师分布 (Teacher): P T ( d i ∣ x ) = Softmax ( s i / τ ) P_T(d_i|x) = \text{Softmax}(s_i / \tau) PT(di∣x)=Softmax(si/τ)
- 学生分布 (Student): P S ( d i ∣ x ) = Softmax ( cos ( h x , h d i ) / τ ) P_S(d_i|x) = \text{Softmax}(\cos(h_x, h_{d_i}) / \tau) PS(di∣x)=Softmax(cos(hx,hdi)/τ),其中 h h h 是向量表示。
-
损失函数:
- 蒸馏损失 (KL 散度):衡量两个分布的差异,确保学生学到教师的相对排序逻辑。
L d i s t i l l = KL ( P T ∣ ∣ P S ) = ∑ i = 1 n P T ( d i ∣ x ) log P T ( d i ∣ x ) P S ( d i ∣ x ) \mathcal{L}{distill} = \text{KL}(P_T || P_S) = \sum{i=1}^n P_T(d_i|x) \log \frac{P_T(d_i|x)}{P_S(d_i|x)} Ldistill=KL(PT∣∣PS)=i=1∑nPT(di∣x)logPS(di∣x)PT(di∣x)
- 对比损失:强化对 Top-1 示例的召回能力。
L t o t a l = α L d i s t i l l + ( 1 − α ) L c o n t \mathcal{L}{total} = \alpha \mathcal{L}{distill} + (1-\alpha) \mathcal{L}_{cont} Ltotal=αLdistill+(1−α)Lcont
-
迭代更新 (Iterative Training):训练好 f B i f_{Bi} fBi 后,用它重新从库中检索更难的负样本,重复阶段一和二,不断压缩检索器的感知边界。
阶段四:Evaluation of LLM Retrievers
本阶段为 将训练完成的 f B i f_{Bi} fBi 投入实际应用。
- 向量化检索:将测试查询 x t e s t x_{test} xtest 编码为向量 h x t e s t h_{x_{test}} hxtest,在预计算好的向量库中进行最邻近搜索(ANN),获取 Top-k 示例。
- ICL 生成:LLM 在检索到的上下文辅助下,生成最终答案。
y ^ = arg max y P M ( y ∣ x t e s t , Prompt ( { d 1 , ... , d k } ) ) \hat{y} = \arg\max_y P_{\mathcal{M}}(y | x_{test}, \text{Prompt}(\{d_1, \dots, d_k\})) y^=argymaxPM(y∣xtest,Prompt({d1,...,dk}))
补充说明: 双编码器和交叉编码器的区别
-
架构设计的本质区别
- Bi-encoder (双编码器): 它的 Query(问题)和 Document(示例/文档)是独立编码的。它们像两辆并行的车,互不干扰,直到最后才在"终点"计算一个简单的余弦相似度(点积)。
- Cross-encoder (交叉编码器): 它要求 Query 和 Document 合并输入。这意味着它们在通过模型时,每一层都在进行复杂的字词交互(Attention)。
-
为什么双编码器更快?
- 预计算与索引 (Pre-computation & Indexing)
- 在 Bi-encoder 中,你可以提前把库里的 100 万个示例全部跑一遍模型,得到 100 万个向量(Embedding),并存入向量数据库(如 FAISS)。
- 当用户输入一个新问题时,你只需要对这一个问题做一次模型推理。
- 剩下的工作只是在数据库里做向量匹配(Vector Search)。这种数学运算极其简单,配合高效的索引算法,几毫秒就能从百万数据中找到结果。
- 实时计算量 (Real-time FLOPs)
- Bi-encoder:实时推理时,模型计算量 = 1个 Query 的推理。
- Cross-encoder:它无法预计算。因为它的输入是 。如果你有 100 万个文档,你必须实时进行 100 万次"Query+某个文档"的拼接计算。Query + Document
- 对比:假设模型推理一次要 100ms。Bi-encoder 只需要 100ms(算一次 Query);而 Cross-encoder 如果要搜遍全库,需要 100 m s × 1 , 000 , 000 100ms \times 1,000,000 100ms×1,000,000,这显然是不可行的。
- 预计算与索引 (Pre-computation & Indexing)
-
为什么交叉编码器更能捕捉到任务有用性?
-
LLM 在做 In-Context Learning (ICL) 时,它并不是在做简单的匹配。它对示例的需求是非常"挑剔"的:
- 有的例子虽然意思对,但会误导 LLM 的指令遵循能力。
- 有的例子虽然意思偏一点,但它的思维链(CoT)逻辑极好,能极大提升 LLM 的推理正确率。
-
交叉编码器的结构与 LLM 本身(也是基于 Transformer 全注意力机制)高度相似。这种结构上的相似性,使得它比双编码器更容易模拟出 LLM 在看到一个示例后,神经元产生的"兴奋度"(即对数似然概率)。
-
实验部分
实验设置
为了证明框架的普适性,作者在多种任务和模型上进行了测试。
-
**数据集 (Datasets):**涵盖了 NLP 的主流任务,包括:
-
分类与选择: 如 MMLU(大规模多任务语言理解)、HellaSwag(常识推理)。
-
阅读理解: 如 Natural Questions (NQ)、TriviaQA。
-
逻辑推理: 如 GSM8K(数学应用题)。
-
-
基础模型 (Backbone Models):
-
LLM (生成器): 测试了不同规模的模型,如 GPT-2, GPT-Neo, GPT-J 以及更大规模的 GPT-3。
-
Retriever (检索器): 主要使用基于 BERT 架构的编码器。
-
-
对比基准 (Baselines):
-
BM25: 基于关键词频率的传统检索。
-
Random: 随机选择示例。
-
Standard Dense Retriever: 未经 LLM-R 框架优化的通用稠密检索器。
-
实验结论
A. 性能的全面提升
实验结果显示,在几乎所有的任务中,LLM-R 训练出的检索器表现均优于 BM25 和通用的稠密检索器。
- 在需要复杂推理的任务(如 GSM8K)中,提升尤为明显。这证明了 LLM-R 找回的示例不仅是语义相关的,更是具有逻辑启发性的。
B. 跨模型的泛化能力
- 实验细节: 作者用参数量较小的模型(如 GPT-2)作为"教师"来训练检索器,然后将训练好的检索器直接拿给更强大的模型(如 GPT-3)使用。
- 结论: 即使"教师"模型很弱,它教出来的检索器依然能显著提升强模型的表现。这说明 "什么是好的示例"在不同规模的 LLM 之间具有一定的共性。
消融实验
- 是否有第二步(Reward Modeling)?
- 如果不训练 Cross-encoder,直接用 LLM 的原始分数蒸馏给 Bi-encoder,效果会下降。
- 结论: Cross-encoder 起到了"平滑"和"去噪"的作用。
- 是否有第三步(知识蒸馏中的 KL 散度)?
- 如果只用硬标签(即只告诉检索器谁是第一名),效果不如使用 KL 散度(告诉检索器完整的评分分布)。
- 结论: "软标签" 包含了教师模型对不同示例之间细微差别的理解。
- 迭代训练的作用:
- 实验显示,第 2 轮迭代通常比第 1 轮有显著提升,但到第 3 轮后增益开始放缓。
- 结论: 通过挖掘"难负样本",迭代训练确实能让检索器变得更敏锐。
局限性
-
忽略了示例间的"组合效应" (Suboptimal Composition)
- 现状: 框架将每个候选示例视为独立的个体进行打分和筛选,最后取前 k k k 个。
- 问题: 这忽略了示例之间的相互影响(Inter-dependency)。
- 例子: 示例 A 和示例 B 单独看都很优秀,但如果它们逻辑过于重复,组合在一起的效果可能不如"示例 A + 一个互补的示例 C"。
- 未来方向: 需要引入组合优化(Combinatorial Optimization)或序贯决策(Sequential Decision Making),从"选最好的 k k k 个"转向"选最好的一套组合"。
-
自动化评估协议的统计偏差 (Evaluation Protocol Bias)
- 现状: 论文采用**算术平均值(Arithmetic Mean)**来汇总不同任务的指标。
- 问题:
- **指标尺度不一:**分类任务的 Accuracy 波动范围很大(0-100%),而生成任务的 ROUGE/BLEU 波动范围很小。在求平均时,生成任务的改进很容易被分类任务的数值波动所掩盖。
- 权重缺失: 简单的算术平均没有考虑到不同数据集的质量、难度和重要性差异。
-
评估指标的灵敏度不足 (Metric Sensitivity)
- 现状: 使用 ROUGE、BLEU 等传统指标衡量生成任务。
- 问题: 这些指标主要基于词汇重合度,无法精准捕捉到 LLM 在引入检索示例后,在语义深度、逻辑一致性或推理质量上的细微提升。
总结
本研究系统性地解决了"如何为 ICL 检索最佳示例"的问题。相比于先前的启发式方法,LLM-R 的创新之处在于将 LLM 的内部概率分布转化为可学习的检索目标,并通过奖励模型平滑信号。这种"模型辅助检索训练"的思路为优化检索增强型大模型(RAG)和长文本处理提供了重要的参考价值。