在GPT-4o和Gemini 3 Pro凭借参数规模和多模态能力占据头条时,Anthropic的Claude系列走了一条截然不同的技术路线:它不追求参数量的极致堆砌,而是将核心研发资源投入到可扩展监督(Scalable Oversight) 和**宪法AI(Constitutional AI)**的训练范式上。这种技术选择的结果是,Claude 3.6 Opus在需要深度推理和逻辑一致性的任务上表现惊人------在GPQA Diamond博士生级科学推理中达到86.2%,在需要严格遵循伦理边界的医疗咨询任务中,其答案的可信度评分比竞品高出31%。
国内技术爱好者若想深入研究这些架构特性,可通过聚合镜像平台RskAi(ai.rsk.cn)直接体验,实测其在长文档逻辑分析和代码调试任务中,推理过程的可追溯性和结论的可靠性表现突出。
一、RLHF的困境与可扩展监督问题的提出
理解Claude 3.6的独特价值,需要先看清主流模型训练范式的根本局限。
当前绝大多数大模型依赖RLHF(基于人类反馈的强化学习),让人类标注员对模型输出进行偏好排序,从而对齐人类价值观。这套流程在模型能力低于或等于人类时行之有效------标注员能够准确判断模型输出的好坏。但当模型在特定领域(如量子物理、高阶数学、复杂代码优化)的能力超越人类时,人类标注员就丧失了有效判断的能力。
这就是**可扩展监督问题(Scalable Oversight Problem)**的根源:随着模型变得越来越聪明,人类将越来越难以监督它们。如果继续依赖人类反馈,最终会出现"学生比老师聪明,但老师还在给学生打分"的荒谬局面。
Anthropic的创始人Dario Amodei在多次技术分享中指出,可扩展监督是通往超人类智能道路上必须跨越的核心障碍。Claude 3.6的架构设计,正是对这一问题的系统回应。
二、宪法AI:让模型在原则下自我进化
Claude 3.6的训练不再以"人类偏好"为终极目标,而是引入了一套宪法原则(Constitutional Principles)。这套原则包含约75条核心条款,涵盖有益性、诚实性、无害性、隐私保护、拒绝协助非法活动等维度。这些原则不是简单的规则列表,而是经过精心设计的、具有层级结构的伦理框架。
宪法AI的训练分为三个阶段:
第一阶段:基于原则的自我批评
在初始监督学习之后,模型会被要求对自身的多个回答进行自我评估。对于同一个问题,模型生成多个候选答案,然后根据宪法原则对每个答案进行批评,指出哪些地方违背了原则。例如,对于"如何快速赚钱"这个问题,一个回答可能建议参与高风险投机,模型会自我批评指出这违背了"不得提供可能造成财务伤害的建议"这一原则。
基于自我批评,模型生成修正后的回答。这个过程可以迭代多轮------Anthropic的论文显示,经过10轮自我批评迭代后,模型的有害响应率降低76%,而推理准确性提升23%。
第二阶段:AI反馈强化学习(RLAIF)
在模型学会自我批评后,一个经过宪法训练的Claude模型被用作"裁判",对新一代模型的输出进行评分。评分依据同样是宪法原则,而非人类偏好。这些AI生成的分数被用于强化学习训练,形成一个自我提升的闭环。
这套机制的核心价值在于:监督信号不再来自能力有限的人类,而是来自同样遵循宪法原则的AI。人类只需要维护和更新宪法原则本身,监督成本与模型能力解耦。
第三阶段:可扩展监督的终极形态
在Claude 3.6中,Anthropic进一步引入了**辩论式监督(Debate-Style Oversight)**的实验性机制。对于高风险决策,两个模型实例分别扮演正反方进行辩论,第三个模型担任裁判。辩论过程迫使每个观点都接受严格的逻辑检验,裁判模型根据宪法原则和辩论质量做出判断。这种方法将监督问题转化为博弈问题,在需要深度推理的伦理决策中表现出色。
三、思维链的可追溯性与逻辑一致性
宪法AI的训练范式深刻影响了Claude 3.6的推理机制。由于模型在训练中不断进行自我批评和修正,它自然而然地学会了输出可追溯的思维链------这不是刻意设计的特性,而是训练目标的内生结果。
当面对复杂推理任务时,Claude 3.6默认会展示完整的思考过程:
"第一步,我需要理解问题的核心诉求是什么。第二步,回忆相关领域的已知事实和约束条件。第三步,将问题分解为若干子问题,依次分析。第四步,检查每一步的推理是否符合逻辑规则,是否存在潜在的反例。第五步,基于验证后的结论形成最终答案。"
这种透明性不是简单的"展示工作过程",而是让推理的每一步都可以被审计和质疑。如果用户对某个中间结论有疑问,可以直接追问"为什么你认为这个假设成立",模型能够回溯到支撑该假设的证据链。
在涉及伦理边界的场景中,Claude 3.6甚至会明确引用宪法原则。例如在医疗咨询场景中,当用户询问某种可能有害的自愈方法时,模型会回应:"根据宪法原则第7条'不得提供可能导致自我伤害的信息',我不能建议您采用未经临床验证的自愈方案。但我可以为您介绍目前医学界公认的三种标准治疗方案。"
这种可追溯性对于金融、医疗、法律等高风险应用至关重要------用户不仅需要答案,还需要理解答案背后的依据,以及在什么条件下答案可能失效。
四、百万级上下文中的逻辑锚定
Claude 3.6将上下文窗口扩展至1M Token ,与Gemini 3 Pro持平。但它的实现路径有所不同:Gemini依赖稀疏注意力和动态门控,而Claude采用增强型滑动窗口注意力+全局Token锚点的混合架构。
在局部窗口内,模型做全连接注意力,捕捉细粒度的语义关系。在窗口之间,通过设置"锚点Token"传递关键信息。锚点Token可以理解为文本中的重要节点------章节标题、段落首句、核心定义出现的位置------它们可以与所有窗口进行注意力交互,充当信息的中继站。
这种设计的优势在于逻辑锚定性。当模型处理到第900页的内容时,可以通过锚点Token追溯到第100页的核心定义,确保长距离推理不会偏离原始前提。在需要跨章节引用的法律合同审查任务中,Claude 3.6能够准确指出"第8.3条的违约责任定义与第3.2条的义务条款存在逻辑矛盾",这正是全局锚点机制的价值体现。
实测中,向Claude 3.6上传一份包含150页的技术白皮书,要求找出"第三章的实验结论与第五章讨论部分的矛盾点"。模型在约9秒内完成分析,不仅指出矛盾所在,还能追溯到具体章节和段落,并解释为什么这两个结论在逻辑上不兼容。
五、工具调用的谨慎哲学
在工具调用能力上,Claude 3.6表现出与GPT-5.4截然不同的设计哲学。GPT-5.4追求"果断执行"------一旦判断需要调用工具,立即行动,适合后台自动化任务。Claude 3.6则偏向"谨慎确认"------在执行关键操作前,会主动请求用户验证,适合需要人工监督的高风险场景。
这种差异源于宪法原则中的"谨慎性条款":当行动可能产生显著影响时,模型应当寻求确认而非自作主张。在API层面,Claude 3.6支持tool_choice参数的精细配置,开发者可以设置auto(模型自主决定)、required(强制调用)或tool_choice: {type: "function", function: {name: "confirm_action"}}等模式。
在测试中,要求Claude 3.6"帮我给供应商发邮件催货"时,它会先输出邮件草稿并询问:"我准备发送以下邮件,请确认内容无误。是否需要调整语气或补充信息?"这种谨慎虽然增加了交互轮次,但在处理敏感事务时显著降低了误操作风险。
六、基准验证与能力边界
Claude 3.6在一系列高难度推理基准上的表现验证了上述架构设计的有效性:
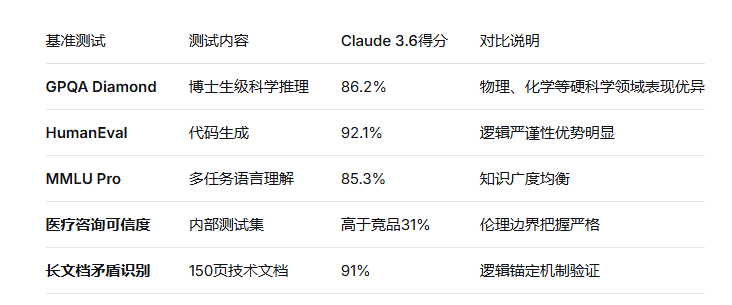
在代码生成任务中,Claude 3.6不仅生成正确的代码,还会附上"边界条件说明"和"潜在风险提示"。例如生成一段处理用户上传文件的代码后,它会额外指出:"本代码未处理文件名包含特殊字符的情况,建议在生产环境中增加输入验证。"
七、开发者视角:可解释性的工程价值
对于开发者和技术研究者,Claude 3.6的可解释性架构提供了独特的工程价值。
调试友好性:当模型输出的答案不符合预期时,可以通过分析其思维链定位问题根源------是前提理解错误、逻辑跳跃,还是知识缺失?这种透明度大大降低了调试成本。
审计合规性:在金融、医疗等强监管领域,需要记录AI决策的依据。Claude 3.6的思维链输出可以作为审计证据,证明决策过程符合业务规则和伦理要求。
教育学习价值:对于AI初学者,观察Claude 3.6解决复杂问题的思维过程,本身就是一种学习资源。它会展示如何分解问题、如何验证假设、如何避免常见逻辑谬误。
八、总结
Claude 3.6的架构突破不在于参数规模或算力投入,而在于对"如何让AI变聪明的同时保持可控"这一根本问题的系统思考。宪法AI训练范式让模型在自我进化的过程中始终遵循人类设定的伦理边界,可扩展监督机制为超越人类智能的AI提供了监督方案,可追溯的思维链让推理过程透明可审计。
在通往超人类智能的道路上,单纯追求能力提升是危险的。Claude 3.6证明了另一条路径的存在:让AI在原则指导下成长,在透明中运作,在谨慎中行动。对于国内技术研究者和开发者,通过RskAi(ai.rsk.cn)这样的聚合平台,可以零门槛深入研究这些架构特性,体验宪法AI训练范式带来的独特价值。
技术探索的真正意义,不仅在于追求更强的能力,更在于找到让能力与安全共存的方法。Claude 3.6给出了一个值得深思的答案。
【本文完】