1 岛屿数量
初始化:创建和网格大小一致的visited数组,标记格子是否被访问过(避免重复计数)。
遍历网格:逐个检查每个格子:
如果当前格子是陆地('1')且未被访问 → 岛屿数 + 1,同时启动 DFS。
DFS 核心:从当前陆地格子出发,向上下左右四个方向递归探索:
超出网格边界 → 直接返回。
是未访问的陆地 → 标记为已访问,继续递归探索该格子的四个方向。
返回结果:最终统计的岛屿数即为答案。
java
class Solution {
// 定义四个方向:上、下、左、右(二维数组,每个元素是[x方向偏移, y方向偏移])
private int[][] dirs = {{0,1}, {0, -1}, {1, 0}, {-1, 0}};
// 主方法:计算岛屿数量
public int numIslands(char[][] grid) {
// 处理边界情况:网格为空或行数为0,直接返回0
if (grid == null || grid.length == 0) {
return 0;
}
int m = grid.length; // 网格的行数
int n = grid[0].length; // 网格的列数
boolean[][] visited = new boolean[m][n]; // 标记格子是否被访问过
int res = 0; // 记录岛屿数量
// 遍历网格的每一个格子
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
// 找到未访问的陆地格子 → 发现新岛屿
if (!visited[i][j] && grid[i][j] == '1') {
res++; // 岛屿数+1
// 启动DFS,标记该岛屿的所有相连陆地为已访问
dfs(visited, grid, i, j);
}
}
}
return res; // 返回最终岛屿数量
}
// DFS方法:递归标记当前陆地所在的整个岛屿为已访问
// visited:访问标记数组;grid:原始网格;x/y:当前格子的坐标
public void dfs(boolean[][] visited, char[][] grid, int x, int y) {
// 第一步:先标记当前格子为已访问(原代码遗漏了这一步,会导致计数错误!)
visited[x][y] = true;
// 遍历四个方向
for (int[] dir : dirs) {
// 计算下一个格子的坐标
int nextX = x + dir[0];
int nextY = y + dir[1];
// 边界检查:下一个格子超出网格范围 → 跳过
if (nextX < 0 || nextY < 0 || nextX >= grid.length || nextY >= grid[0].length) {
continue;
}
// 下一个格子是未访问的陆地 → 递归处理
if (!visited[nextX][nextY] && grid[nextX][nextY] == '1') {
// 标记为已访问
visited[nextX][nextY] = true;
// 递归探索该格子的四个方向
dfs(visited, grid, nextX, nextY);
}
}
}
}2 腐烂的橘子
收集所有初始腐烂橘子作为 BFS 起点,按 "分钟(层)" 扩散,每轮只处理当前分钟的腐烂橘子;用hasRotten标记本轮是否有新鲜橘子被腐烂,只有有腐烂时才计时;最后判断是否所有新鲜橘子都腐烂,返回时间或 - 1。
hasRotten=false 意味着本轮(当前分钟)没有任何新鲜橘子被传染腐烂
例如:
腐烂橘子周围全是 "水(0)" 或 "已腐烂橘子(2)
所有新鲜橘子都已腐烂,仅剩 "空转" 的腐烂橘子
初始无新鲜橘子(全是 0/2)
java
class Solution {
// 定义上下左右四个扩散方向(x/y轴偏移量)
private static int[][] dirs = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
public int orangesRotting(int[][] grid) {
// 1. 初始化基础变量
int m = grid.length, n = grid[0].length; // 网格的行、列数
int freshCount = 0, time = 0; // freshCount:新鲜橘子数;time:耗时
Queue<int[]> que = new LinkedList<>(); // BFS队列,存腐烂橘子坐标[x,y]
// 2. 遍历网格,初始化队列和新鲜橘子数
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (grid[i][j] == 1) {
freshCount++; // 统计新鲜橘子
} else if (grid[i][j] == 2) {
que.offer(new int[] {i, j}); // 初始腐烂橘子入队(多源BFS起点)
}
}
}
// 3. 核心:多源BFS按层扩散
while (!que.isEmpty()) { // 只要队列有腐烂橘子,就继续扩散
int size = que.size(); // 关键:记录当前层(当前分钟)的腐烂橘子数
boolean hasRotten = false; // 标记「本轮(本分钟)是否有新鲜橘子被腐烂」
// 处理当前层的所有腐烂橘子(同一分钟的扩散)
for (int loop = 0; loop < size; loop++) {
int[] cur = que.poll(); // 取出当前腐烂橘子的坐标
int x = cur[0], y = cur[1];
// 向四个方向扩散
for (int[] dir : dirs) {
int nextX = x + dir[0]; // 下一个格子的x坐标
int nextY = y + dir[1]; // 下一个格子的y坐标
// 边界检查:超出网格范围 → 跳过
if (nextX < 0 || nextY < 0 || nextX >= m || nextY >= n) {
continue;
}
// 找到「未腐烂的新鲜橘子」→ 传染它
if (grid[nextX][nextY] == 1) {
grid[nextX][nextY] = 2; // 标记为腐烂
freshCount--; // 新鲜橘子数-1
que.add(new int[] {nextX, nextY}); // 新腐烂的橘子入队(下一轮扩散)
hasRotten = true; // 标记:本轮有橘子被腐烂
}
}
}
// 4. 时间计数:只有本轮有腐烂,才加1分钟
if (hasRotten) {
time++;
}
}
// 5. 结果判断:所有新鲜橘子都腐烂→返回时间;否则返回-1
return freshCount == 0 ? time : -1;
}
}3 课程表
统计每个节点的入度(入度 = 0 表示无先修课程,可直接学习);
用队列存储所有入度为 0 的节点,逐个处理:
取出节点,加入结果列表;
遍历该节点的所有后继节点(依赖该节点的课程),将其后继节点的入度 - 1;
若后继节点入度变为 0,加入队列。
最终若结果列表长度等于课程数 → 无环(可完成);否则 → 有环(不可完成)。
java
class Solution {
public boolean canFinish(int numCourses, int[][] prerequisites) {
// 1. 初始化入度数组:indegree[i] 表示课程i的先修课程数(即节点i的入度)
int[] indegree = new int[numCourses];
// 2. 初始化邻接表:pre.get(from) 存储所有依赖from的课程(即from的后继节点)
// 比如 pre.get(b) 包含a,表示课程a依赖课程b(b→a)
List<List<Integer>> pre = new LinkedList<>();
for (int i = 0; i < numCourses; i++) {
pre.add(new LinkedList<>()); // 每个课程对应一个空列表,存储后继课程
}
// 3. 填充邻接表和入度数组
int len = prerequisites.length; // 先修关系的数量
for (int i = 0; i < len; i++) {
// prerequisites[i] = [a, b] → 修a前必须修b → 有向边 b→a
int from = prerequisites[i][1]; // 边的起点(先修课程b)
int to = prerequisites[i][0]; // 边的终点(后续课程a)
pre.get(from).add(to); // 邻接表:b的后继节点添加a
indegree[to]++; // a的入度+1(多了一个先修课程b)
}
// 4. 初始化队列:存储所有入度为0的课程(无先修,可直接学习)
Queue<Integer> que = new LinkedList<>();
// 存储拓扑排序的结果(学完的课程)
List<Integer> res = new LinkedList<>();
// 遍历所有课程,将入度为0的课程加入队列
for (int i = 0; i < numCourses; i++) {
if (indegree[i] == 0) {
que.add(i);
}
}
// 5. 核心:处理队列,执行拓扑排序
while (!que.isEmpty()) {
int cur = que.poll(); // 取出当前可学习的课程(入度为0)
res.add(cur); // 标记该课程已学完,加入结果
// 遍历当前课程的所有后继课程(依赖当前课程的课程)
for (int node : pre.get(cur)) {
indegree[node]--; // 后继课程的先修数-1(当前课程已学完)
// 若后继课程的先修数变为0(所有先修都学完),加入队列等待学习
if (indegree[node] == 0) {
que.add(node);
}
}
}
// 6. 判断是否能学完所有课程:
// 结果列表长度 == 课程数 → 无环,可完成;否则有环,不可完成
if (res.size() == numCourses) {
return true;
}
return false;
}
}4 实现Tire(前缀树)

children:长度为 26 的数组,是 Trie 高效的核心原因。因为题目限定仅处理小写字母,用 c - 'a' 可将字符直接转为 0-25 的索引,O (1) 时间访问子节点(比 HashMap 快)。
isEnd:比如插入 "apple" 后,最后一个字符 'e' 对应的节点 isEnd=true,表示从根到该节点的路径是一个完整字符串;而 'p' 节点的 isEnd=false,仅表示是前缀。
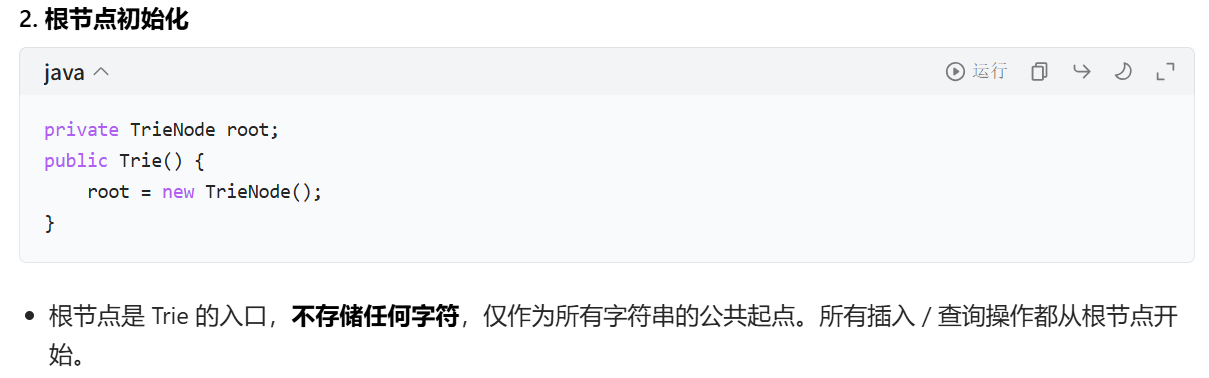
插入:从根出发,逐字符创建节点,最后标记结尾
搜索:字符匹配路径,最终检查 isEnd(确保是完整字符串)
前缀匹配:仅逐字符匹配路径,无需检查 isEnd
java
class Trie {
// 定义Trie节点类
private class TrieNode {
TrieNode[] children;
boolean isEnd;
public TrieNode() {
children = new TrieNode[26]; // 仅处理小写字母,索引0-25对应a-z
isEnd = false; // 初始不是任何字符串的结尾
}
}
private TrieNode root; // 根节点(空节点,不存字符)
// 初始化Trie
public Trie() {
root = new TrieNode();
}
// 插入字符串
public void insert(String word) {
TrieNode curr = root;
for (char c : word.toCharArray()) {
int index = c - 'a'; // 字符转索引(a→0,b→1...z→25)
if (curr.children[index] == null) {
curr.children[index] = new TrieNode(); // 无节点则创建
}
curr = curr.children[index]; // 移动到子节点
}
curr.isEnd = true; // 标记字符串结尾
}
// 搜索完整字符串
public boolean search(String word) {
TrieNode curr = root;
for (char c : word.toCharArray()) {
int index = c - 'a';
if (curr.children[index] == null) {
return false; // 字符不存在,直接返回false
}
curr = curr.children[index];
}
return curr.isEnd; // 必须是完整字符串(isEnd=true)
}
// 搜索前缀
public boolean startsWith(String prefix) {
TrieNode curr = root;
for (char c : prefix.toCharArray()) {
int index = c - 'a';
if (curr.children[index] == null) {
return false; // 前缀字符不存在
}
curr = curr.children[index];
}
return true; // 只要前缀遍历完,无论是否结尾都返回true
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/