从"能效压榨"到"认知规模化生产"
摘要:人工智能革命并不是对前三次工业革命的简单续写,也不能被粗略理解为"又一轮工具升级"。更准确地说,它是在既有物理约束之上,把原本依附于碳基个体的认知能力,第一次大规模地资本化、工程化、平台化,从而改写生产函数的关键变量。前三次工业革命主要围绕能量转换效率、机械能力和信息传输能力展开,而人工智能革命则推动劳动者、劳动资料和劳动对象三要素的系统重构,使数据、算法、算力和组织协同成为新的生产率核心来源。与传统工业工具不同,数据与行业 Know-how 在被模型调用后并不会像燃料一样枯竭,反而可能在反馈与再训练中持续沉淀,形成企业的数据飞轮。本文在吸收技术史、政治经济学和企业管理视角的基础上,提出:AI 的真正冲击不只在于替代部分岗位,更在于重组任务结构、重估组织形态、重塑国家竞争力,并倒逼新的社会契约与治理框架形成。
关键词:人工智能革命;生产力范式;生产力三要素;人机协同;数据要素;企业管理
一、问题意识:AI 不是普通意义上的"技术扩散"
核心导读:AI 的革命性不在于脱离物理世界,而在于把认知能力变成可复制、可沉淀、可放大的生产力。
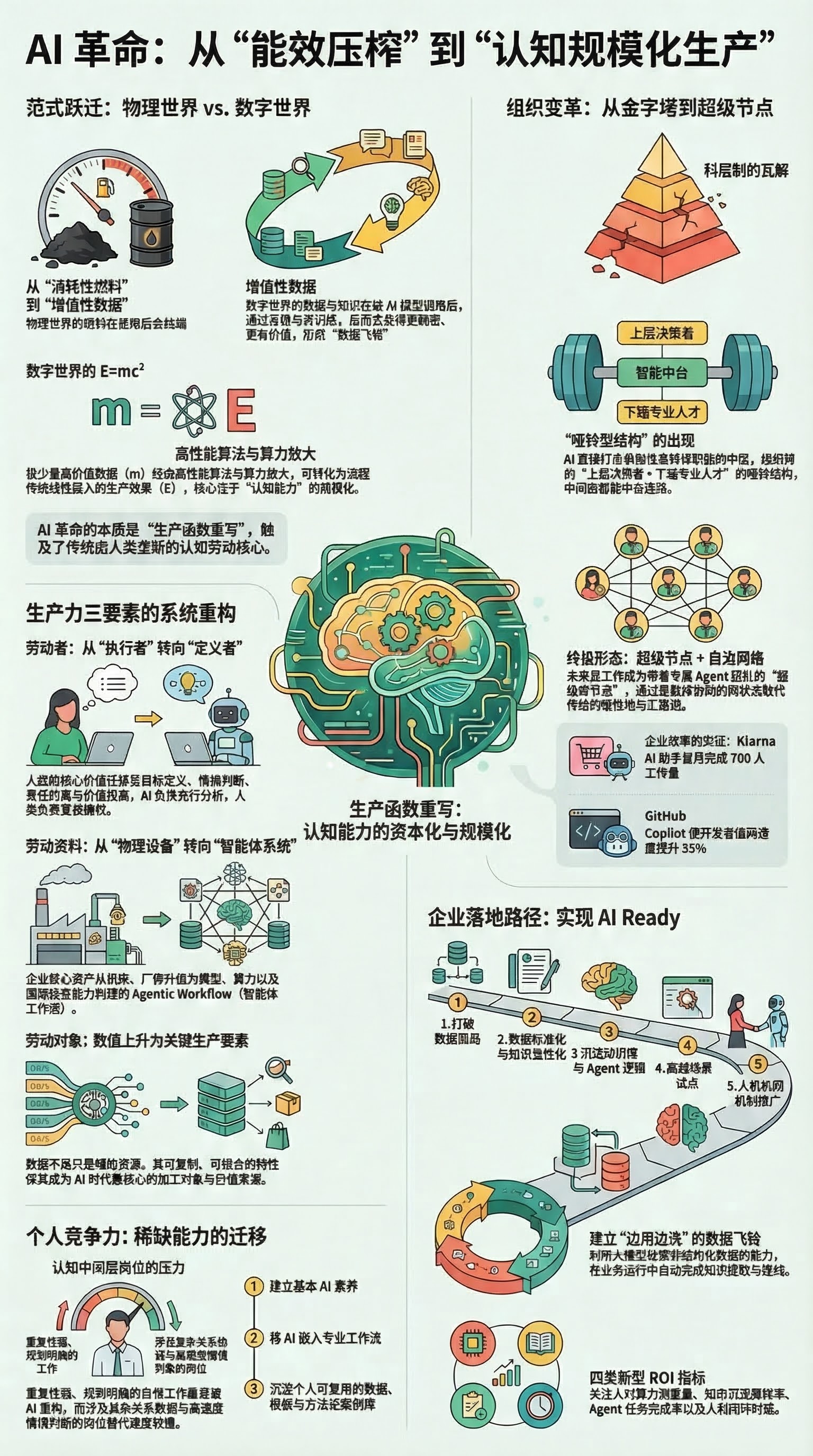
如果用一句话概括人工智能革命的本质,那就是:人类第一次把"认知能力"从个体身上相对剥离出来,变成一种可以复制、调用、组合和审计的生产能力。
过去两百多年,人类生产力跃迁的主线,是不断提高能量转换效率和信息处理效率。从蒸汽机到电力系统,再到半导体与互联网,技术进步当然极其深刻,但其底层逻辑大体仍是围绕物理系统展开的效率改良。无论是热机效率、发电效率,还是芯片制程和通信速度,其提升都受到材料、能耗、热耗散和系统复杂度的约束。
因此,我们保留"从化学能效率压榨走向更高阶生产范式"的判断,但对这一命题作一个更严谨的修正:AI 并没有突破热力学第二定律,也没有脱离物理基础设施;它依然依赖芯片、电力、网络和冷却系统。AI 的革命性在于,它改变了经济系统中最稀缺要素的结构,使生产率增长越来越依赖数据、算法、算力和组织重构,而不再主要依赖热效率或单个劳动者的经验积累。
换言之,若把 E=mc² 继续用于讨论 AI,那么它更适合作为一种修辞隐喻,而不是严格的科学公式:极少量高价值数据、知识和任务定义,经由高性能算法与算力放大后,可以转化为远超传统线性劳动投入的生产效果。但这种"放大"是否真正形成生产力,最终仍取决于场景、流程、治理和制度安排。
更进一步说,数字世界里的 E=mc² 与物理世界有一个关键差异。在物理世界中,燃料燃烧是消耗性的,质量转化为能量之后便不再存在;而在数字世界中,数据和行业 Know-how 被模型调用并转化为生产力之后,并不会像煤炭和石油一样枯竭。相反,它们往往会在使用、纠错、反馈和再训练过程中变得更稠密、更结构化、更有价值。企业一次次调用模型处理客户、合同、代码、知识库和业务流程,本质上不仅是在"消耗算力",也是在积累下一轮更高质量的训练素材和工作流资产。从这个意义上说,数字经济并没有真的打破物理定律,但它确实拥有一种近似"打破质量守恒"的商业特权:你的 m 在释放 E 之后,并不必然减少,反而可能因为反馈飞轮而增值。
这也是为什么许多人低估了 AI 对企业资产负债表的影响。过去,很多知识与经验沉淀在员工个体、部门墙和口头默契之中,难以规模化复用;现在,越来越多的流程、知识、判断标准和客户交互可以被记录、结构化、再训练,转化为一种可累积的认知资本。这种资本不是物理学意义上的"永动机",但在商业上足以形成持续强化的数据飞轮。
同样地,技术圈常说的 Scaling Law 若只停留在论文语境,对企业管理者的说服力其实有限。它在商业上的真实含义并不神秘,核心就是:当数据、算力和模型规模达到某个临界点后,能力边界会突然塌陷,边际拓展成本会突然失真。 过去,企业开发一个财务系统通常只能处理财务,开发一个客服系统通常只能处理客服,能力边界清晰,拓展成本大体线性;而大模型的"涌现能力"意味着,只要底座能力足够强,它不仅把原任务做得更好,还可能顺带获得写代码、读合同、做分析、生成方案等相邻能力。换言之,人类第一次接近这样一种局面:解决未知问题的能力,开始可以被规模化计算出来。
图 1:从能效革命到认知规模化生产
第一次工业革命
蒸汽与机械化
第二次工业革命
电力与流水线
第三次工业革命
半导体 计算机 互联网
共同主线
提高能量与信息处理效率
AI 革命
认知能力工程化
生产函数重写
组织 分配 治理结构重构
图 2:数字世界的 E=mc² 更像数据飞轮
m: 业务数据 行业Know-how
c^2: 算法与算力放大
E: 智能输出与生产力
业务落地
人工反馈 纠错 审计
数据更稠密 更结构化
高质量认知资产沉淀
二、历史参照:前三次工业革命主要是"能效革命",AI 更像"生产函数重写"
核心导读:前三次工业革命主要提高能效,AI 则开始改写"谁来处理信息、谁来做判断、谁来协同执行"。
前三次工业革命并非没有重塑社会关系,但其主要突破口都相对清晰:
- 第一次工业革命以蒸汽机为代表,本质是热能向机械能的大规模转换。
- 第二次工业革命以电力、内燃机和流水线为代表,本质是能源分配和组织协同效率的大幅提高。
- 第三次工业革命以半导体、计算机和互联网为代表,本质是信息处理与传输成本的大幅下降。
这些革命的共同点是:它们主要提升的是"人如何更高效地驱动物理世界"。而 AI 革命更进一步,它开始进入"谁来处理信息、谁来做判断、谁来生成方案、谁来协同执行"的层面,触及了传统上由人类垄断的认知劳动核心。
这就是为什么 AI 带来的不是简单的自动化,而是生产函数的重写。过去,企业扩大产出,往往需要同步增加设备、能源和受过训练的人;现在,很多知识型任务在完成一次高固定成本训练或部署之后,可以以极低的复制成本持续调用。这里的"极低"不是绝对意义上的零,而是相对于培养同等级人类专家所需的时间成本、组织成本和再生产成本而言,呈现出前所未有的下降趋势。
为了避免概念漂浮,可以用下表概括两类革命的区别:
| 维度 | 前三次工业革命 | AI 革命 |
|---|---|---|
| 核心突破 | 能源、机械、通信效率提升 | 认知能力的工程化与规模化调用 |
| 主要约束 | 热效率、材料性能、传输损耗 | 数据质量、算力供给、模型能力、组织落地 |
| 劳动力角色 | 执行、操作、监督机械系统 | 定义目标、设计流程、校验结果、承担责任 |
| 成本结构 | 设备与人工成本同步扩张 | 高固定成本、低复制成本的认知服务 |
| 价值来源 | 物理生产能力扩张 | 数据、算法、工作流和组织协同的复利效应 |
三、AI 革命的核心:生产力三要素的系统重构
核心导读:AI 真正重构的不是单个工具,而是劳动者、劳动资料与劳动对象之间的关系。
如果说第一篇文稿的优势在于提出了"智力能源化"的强命题,那么要让论证更扎实,就必须把这一命题落到生产力三要素上。
1. 劳动者:从"执行者"转向"定义者、调度者、审计者"
在传统工业体系中,劳动者既是体力供给者,也是认知判断者。AI 进入生产系统后,劳动者的价值重心开始迁移。未来更有竞争力的人,不再只是完成任务的人,而是能够定义任务、拆解流程、调度工具、校验结果、承担责任的人。
这并不意味着人类被完全边缘化。恰恰相反,随着 AI 参与决策、生成内容和提出方案,人类在以下环节的重要性上升:
- 目标定义:决定"做什么、为什么做、做到什么标准"。
- 情境判断:识别模型在特定场景中的适用边界与失效条件。
- 责任归属:在医疗、金融、政务、制造等高风险场景中,最终责任不能外包给模型。
- 价值判断:效率、合规、公平、品牌、伦理之间的权衡,仍然需要人来拍板。
一个典型例子是医疗影像与超声分析。相关研究显示,AI 可以在特定任务上达到不低于人工初评的效果,但真正可落地的模式并不是"AI 替代医生",而是"AI 先行分析 + 人类医生复核确权"的协作结构。也就是说,AI 不是简单消灭职业,而是重写职业的任务边界和责任结构。
2. 劳动资料:从物理设备升级为"模型 + 算力 + 工作流"系统
传统工业时代的核心劳动资料是机器、厂房、流水线和信息系统。AI 时代的核心劳动资料,则越来越表现为模型、算力、数据系统、智能体以及围绕这些能力构建的业务工作流。
企业采购一台机床,本质上是在购买固定物理能力;企业部署一个大模型或一套 Agent 工作流,本质上是在购买一种可不断迁移、迭代、组合的认知能力。前者更像单点设备,后者更像认知基础设施。
但必须强调,AI 不会自动转化为生产力。很多企业在这一步最容易犯的错误,是把模型接入误当成数字化转型完成。真正形成生产力,至少需要四个条件同时成立:
- 有可被结构化描述的业务流程。
- 有足够质量的数据、知识库或规则体系。
- 有明确的人机接口与复核机制。
- 有能衡量 ROI 的管理闭环。
没有流程再造,AI 往往只会变成更昂贵的聊天工具;没有责任界面,AI 也难以进入核心业务链条。
3. 劳动对象:数据从辅助资源上升为关键生产要素
AI 时代的劳动对象不再只是自然资源、零部件和标准化信息,还包括海量业务数据、行业知识、用户行为、设备日志和场景反馈。数据的意义不只是"被记录",更在于它可以被持续训练、迭代和反哺系统。
与土地、矿产等传统要素不同,数据具有可复制、可组合、可多场景复用的特征;但与此同时,数据也存在权属复杂、质量不一、隐私与安全风险高等问题。正因为如此,数据在 AI 时代既是生产要素,也是治理对象。谁能更高质量地采集、清洗、标注、流通和使用数据,谁就更可能获得持续的模型优势和组织优势。
图 3:AI 对生产力三要素的系统重构
AI 进入生产系统
劳动者
劳动资料
劳动对象
执行者
定义者 调度者 审计者
机器 厂房 信息系统
模型 算力 数据系统 Agent 工作流
物质资源 标准化信息
数据资产 流程资产 行业 Know-how
企业竞争力重心迁移
四、从工具革命到组织革命:企业经营管理进入"阵痛重构期"
核心导读:企业的难点不在"有没有模型",而在能否把组织、数据与风控改造成可持续调用的人机系统。
对企业而言,AI 真正的冲击并不只在某个岗位能否被替代,而在于整个经营管理逻辑正在从"围绕人配置资源",转向"围绕人机系统设计流程"。这并不是温和的效率改善,而更像一次带有阵痛的组织再造。很多企业管理者之所以感到焦灼,并不是因为他们看不懂模型,而是因为他们已经意识到:一旦 AI 真正进入客服、研发、法务、财务、供应链和经营分析环节,传统的科层结构、人才结构和责任结构都会被迫重写。
1. 商业案例已经证明:AI 开始重写人力配置逻辑
AI 对企业不是一个遥远趋势,而是已经发生的经营现实。2024 年 2 月 27 日,Klarna 官方宣布,其 AI 客服助手上线首月完成了 230 万次对话,处理了约三分之二的客服聊天量,工作量相当于 700 名全职客服人员;到 2025 年 6 月 12 日,Klarna 进一步披露,这套系统已能处理每月约 130 万次客户互动,对应约 800 名全职人员的工作量。与此同时,GitHub 在官方受控实验中发现,使用 Copilot 的开发者完成特定编码任务的速度平均快了 55%。
这两个案例的重要性不在于"AI 能不能写点东西",而在于它们分别击中了企业最敏感的两条成本链:客服和研发。前者是规模化服务成本,后者是高薪知识劳动成本。一旦 AI 能在这两条链路上稳定释放价值,企业就很难继续用传统的人力配置模型来理解增长。
更值得注意的是,企业 AI 的产品形态也在快速变化。早期企业采购的是"对话框"和"副驾驶",也就是 Chat 与 Copilot:员工提出问题,系统给出建议,最终仍需人类持续盯住每一步操作。但当前更前沿的方向,已经明显转向 Agentic Workflow,即让 AI 不只是回答问题,而是能够围绕目标自动拆解任务、调用工具、检查结果、必要时回退重试,并交付可用结果。微软研究部门推出的 GitHub Agentic Workflows,以及 Azure Logic Apps 已经提供的 autonomous agentic workflows,都说明这一趋势已经从概念走向产品化。企业未来购买的不应只是"更强的对话框",而应是能稳定完成竞品分析、代码审查、财务对账或知识检索的"数字员工工作流"。
因此,所谓"从雇佣到调度",并不是一句口号,而是企业竞争力来源的实质迁移。未来企业的核心能力将越来越体现为:
- 问题定义能力。
- 数据资产沉淀能力。
- 智能体编排能力。
- 人机协同的审计与风控能力。
这意味着,企业未来的竞争力不只是"有多少人才",而是"能否把人才经验沉淀为系统能力,并通过模型和 Agent 持续放大"。
2. 最大的阵痛不在一线,而在中层与科层制
传统企业为什么大多长成金字塔?因为信息传递很贵,监督执行也很贵,所以企业需要大量中层承担汇报、转译、协调、追踪和控制的角色。中层之所以重要,很大程度上并不是因为他们掌握了不可替代的专业能力,而是因为他们长期充当着"信息二传手"和"组织缓冲层"。
AI 恰恰会直接打击这套结构中最容易被压缩的部分。凡是主要承担信息整合、汇报搬运、流程催办和低复杂度协调职能的中层岗位,都将面临显著压力。未来组织更可能演化为一种"哑铃型结构":上端是少量能够定义战略、掌控资源并承担责任的核心决策者;下端是高度专业化的一线人才;中间则由强 AI 中台、自动化流程和 Agent 系统承担大量原本属于科层传递的工作。
这并不意味着中层会整体消失,而是意味着中层必须升级。未来还能稳定创造价值的中层,不再靠传话和控流程,而要靠业务判断、跨部门整合、复杂冲突协调以及人机协同治理。
但"哑铃型"更像是从工业科层制向 AI 原生组织过渡时的一种中间形态。随着 Agent 普及,未来更高阶的组织结构未必仍然呈现明显的上下分层,而更像一种"超级节点 + 自治网络(Hub-and-Spoke)"的人机共生网络。每一个核心员工不再只是一个岗位,而是一个带着自己专属 Agent 团队的"超级节点"。他们围绕项目目标调用企业中台的算力、知识、工具和数据,与其他节点敏捷协同。中层管理者之所以会"消失",其本质并不是管理活动完全消失,而是传统科层制的审批流、传话流和层层汇报流被智能体协同的网状工作流取代。
图 4:企业组织形态从金字塔走向"哑铃型"
传统金字塔组织
信息传递成本高
大量中层负责汇报 转译 监督
AI 进入核心流程
信息处理与协调成本下降
哑铃型组织
少量核心决策者
强AI中台与Agent系统
专业化一线人才
图 5:更高阶的 AI 原生组织更像"超级节点 + 自治网络"
企业数据与算力中台
超级节点A
员工 + 专属Agent团队
超级节点B
员工 + 专属Agent团队
超级节点C
员工 + 专属Agent团队
项目任务1
项目任务2
项目任务3
3. 真正的起点,不是买模型,而是先做到 AI Ready
很多企业今天最大的误区,是一边焦虑,一边采购。买了模型、买了算力、甚至买了顾问,最后却发现系统跑不起来、业务接不上、员工不买账、老板看不到 ROI。问题往往并不在于模型不够强,而在于企业自己还没有准备好。
没有高质量的数据,就没有可被点燃的 m;没有流程标准化,就无法把模型能力嵌入业务;没有知识显性化,暗知识就永远困在老员工脑子里;没有统一的数据口径和权限治理,AI 最终只会接到一堆互相冲突的输入。换句话说,没有高质量的数据治理,就无法真正引爆算力与算法。
但这里也必须警惕一个常见误区:不要用旧 IT 时代的"完美主义"来阻碍 AI 落地。传统数字化转型往往要求先完成主数据治理、数据仓库、标准字段和口径统一,然后才允许上层应用启动;而大模型时代最大的红利之一,恰恰是它显著降低了企业利用非结构化数据的门槛。过去需要投入大量预算清洗的旧 PDF、会议录音、销售聊天记录、方案文档、客服对话和历史邮件,现在可以借助 RAG、多模态理解和知识检索直接进入可用状态。企业完全可以从复杂、零散、未充分结构化的数据中先提取价值,再在使用过程中持续优化。
因此,真正的 AI Ready,不是等到所有数据都完美结构化之后才接入 AI,而是建立一条"边用边洗"的数据飞轮:让 AI 在处理凌乱的日常业务中,自动帮企业完成知识提取、标签化、去重、归档和提纯。换句话说,AI Ready 的底层逻辑不再是"一次性建完美系统",而是"在真实业务中持续提纯认知资产"。
对管理者而言,更现实的路径不是一开始追求"全公司 AI 化",而是先完成以下几步:
- 先打破数据孤岛,建立统一数据口径。
- 再把关键流程标准化,把暗知识显性化。
- 随后沉淀知识库、规则库、提示词模板和 Agent 编排逻辑。
- 在高频、标准化、可量化 ROI 的场景中做试点验证。
- 最后再把人机协同机制、日志留痕和权限分级推广到跨部门场景。
企业之间未来拉开差距的,不会只是"有没有接大模型",而是"能不能把 AI 嵌进日常经营的成本、效率、质量和风控体系"。
图 6:企业 AI Ready 的落地路径
企业启动 AI 转型
打破数据孤岛
统一数据口径
流程标准化
暗知识显性化
权限 标签 知识库治理
模型接入与 Agent 编排
试点验证 ROI
跨部门复制
系统级生产力形成
4. 从"好用"到"可用":幻觉治理与数字合规
企业真正开始用 AI 之后,管理者最先遇到的通常不是"效果不惊艳",而是"风险不敢放"。第一类风险是幻觉风险。模型能写、能说、能总结,不代表它总是对的。一旦 AI 进入合同审查、财务分析、投标文件、研发决策等高风险场景,哪怕只有少量事实错误,也足以造成直接损失。第二类风险是数字合规风险。企业最宝贵的往往不是服务器,而是流程、客户、报价、代码、知识库和行业 Know-how。如果员工直接把这些内容喂给外部公有云模型,而企业又没有边界控制机制,那就等于用自己的资产反向训练别人。
因此,企业要真正把 AI 用起来,至少要建立三道防火墙:
- 高风险场景保留"AI 生成 + 人类复核"机制。
- 核心数据、代码和知识库实行分级授权与留痕审计。
- 涉及机密资产的场景优先采用私有化、专属实例或受控调用。
很多企业不是死于不用 AI,而是死于在没有治理框架的情况下,过早把 AI 接入关键链路。
图 7:企业使用 AI 的风险治理闭环
是
否
AI 接入关键业务链路
识别场景风险等级
是否高风险场景
AI 生成建议
人工复核确权
审计留痕
执行或发布
受控自动化执行
数据分级授权
私有化 专属实例 受控调用
5. AI 时代需要新的 ROI 指标,而不只是传统投资回报率
传统 ROI 在 AI 早期往往并不好算,因为很多收益不是单次项目利润,而是组织学习速度、知识沉淀速度和流程自动化程度的复利效应。也正因此,企业不能只盯着"这个模型一年节省了多少人力成本",还要开始建立更适合 AI 时代的经营指标。
可以考虑至少引入以下四类指标:
- 人均算力调度量(Compute-per-Employee):衡量一个员工能够稳定调用多少数字生产力,而不只是看其个人工时。
- 知识沉淀周转率:衡量一线经验、会议结论、项目复盘和客户洞察被转化为系统 AI 资产的速度。
- Agent 任务完成率:衡量智能体在真实业务场景中端到端交付可用结果的比例。
- 人机闭环时延:衡量从任务发起、AI 处理、人工复核到最终发布的总耗时,反映组织的人机协同效率。
微软 Foundry 已开始把 Task Completion、Task Adherence、Tool Selection 等维度用于 agent 系统评估,这为企业内部 KPI 设计提供了现成参考。谁在这些指标上领先,谁就更可能掌握数字时代的成本优势、速度优势和定价权。
五、AI 不只是替代岗位,更在重组就业结构、分配逻辑与社会契约
核心导读:AI 不只是替代工作,而是在重组任务、技能、工资结构与收益分配逻辑。
AI 对劳动市场的影响,既不能被夸大为"人类马上失业",也不能被简单安慰为"技术总会创造更多工作"。更准确的判断是:AI 正在引发一轮强烈的任务重组、技能重估和收益再分配。
世界经济论坛 2025 年 1 月发布的《未来就业报告 2025》预计,到 2030 年全球将新增约 1.7 亿个岗位,同时替代约 9200 万个岗位,净增约 7800 万个岗位。这个判断说明,问题不在于工作总量会不会瞬间消失,而在于:
- 新岗位出现的速度,是否快于旧岗位消失的速度。
- 新岗位所需技能,是否能被原有劳动者在可接受时间内完成迁移。
- 由 AI 带来的效率收益,是否能通过制度安排转化为更广泛的社会福祉。
1. "卢德谬误"并未失效,但适用条件改变了
历史上,许多关于机器取代人的恐慌最终被证明过度,因为技术替代旧任务的同时也创造了新行业、新职业和新消费需求。但 AI 与传统机械化的差异在于,它开始进入曾经被视为人类"最后比较优势"的认知领域。也正因此,复职效应是否足够强,不再只是技术问题,而是教育体系、产业结构、社会保障和制度设计问题。
2. 中间层认知岗位将承受最大压力
重复性强、规则明确、文本和表格密集、判断标准相对稳定的白领工作,会成为 AI 最先重构的区域。相比之下,涉及复杂关系协调、线下组织、情感互动、现场责任和高强度情境判断的岗位,替代速度通常更慢。
因此,未来分化更可能发生在两端:一端是掌握模型、数据、系统设计能力的人;另一端是依然需要强现实世界互动能力的人。最承压的,往往是中间层的标准化认知劳动。
图 8:AI 时代的任务重组与岗位分化
AI 进入认知劳动
重复性 规则化任务自动化
复杂情境 责任型任务保留
中间层标准化岗位承压
高判断力 强互动岗位相对稳固
技能折旧加速
人机协同能力升值
劳动市场重新分化
3. 对个人而言,真正稀缺的能力正在迁移
在生成成本快速下降的时代,真正稀缺的将不再是"会不会生产内容",而是:
- 定义问题的能力:能否把模糊需求转化为清晰任务。
- 系统架构能力:能否把多个工具、流程和人组织成闭环。
- 判断与审美能力:能否在大量可生成内容中识别高质量输出。
- 责任承担能力:能否在关键节点做最终判断并承担后果。
普通人若要提高在 AI 时代的竞争力,更可行的路径不是盲目追逐"学会所有模型",而是先完成三个层次的升级:先建立基本 AI 素养,再把 AI 嵌入自己的专业工作流,最后沉淀出个人可复用的数据、模板、方法和案例库。
图 9:个人在 AI 时代的能力升级路径
建立基本AI素养
掌握主流工具边界
嵌入专业工作流
沉淀模板 案例库 知识库
形成个人Agent体系
从执行者走向定义者与调度者
六、国家竞争与制度供给:AI 时代比拼的不只是技术,更是"能源 + 算力 + 数据 + 治理"
核心导读:国家竞争的关键已从单点技术,转向能源、算力、数据和治理的组合能力。
AI 革命越深入,就越不能只从模型效果看问题。国家层面的真实竞争,正在同时发生在四个维度上:
- 能源能力:AI 训练与推理的底层是电力、芯片和冷却体系。
- 算力能力:没有稳定、可负担、可调度的算力,模型能力难以形成规模化应用。
- 数据能力:高质量行业数据与可信流通机制,决定模型是否真正可用。
- 治理能力:没有规则、标准和责任框架,AI 很难进入高价值、高风险场景。
1. 技术竞争正在快速进入"物理世界"
AI 的价值已经不只体现在内容生成上,而是开始进入科学发现、工业控制和复杂决策支持。
例如,Google DeepMind 在 2023 年公布的 GNoME 系统发现了约 220 万种新晶体结构,其中约 38 万种被预测为稳定材料,这意味着 AI 正在加速材料科学的搜索效率。又如,发表于 Nature 的研究表明,深度强化学习已被用于托卡马克等离子体磁控实验,AI 开始介入高复杂度物理系统控制。这些案例说明,AI 的意义不只是"写文案更快",而是在向科学研究和工业底层能力渗透。
2. 制度竞争已经开始成形
从中国政策演进看,AI 发展已从"鼓励创新"转向"创新与治理并重"。
- 2023 年 8 月 15 日,《生成式人工智能服务管理暂行办法》施行,标志着我国对生成式 AI 的基础治理框架开始落地。
- 2025 年 3 月 14 日,《人工智能生成合成内容标识办法》发布,并于 2025 年 9 月 1 日起施行,治理重点进一步从模型备案延伸到生成内容标识与传播环节。
- 2025 年 4 月,国家数据局印发构建数据基础制度更好发挥数据要素作用 2025 年工作要点,说明数据产权、流通、收益分配和治理机制正在加速完善。
- 2025 年 8 月 26 日,国务院发布《关于深入实施"人工智能+"行动的意见》,明确到 2027 年率先实现人工智能与六大重点领域广泛深度融合,把 AI 的讨论从技术议题推进为国家层面的产业和治理议题。
3. 更有效的政策重点应放在四件事上
如果要把 AI 真正转化为国家与产业竞争力,未来政策更应集中在以下四个方向:
- 加快高质量数据要素市场建设:重点不只是"有数据",而是有权属清晰、质量可评估、流通可追溯的数据。
- 推动普惠算力与行业基础模型建设:避免 AI 红利长期只被少数平台垄断。
- 建立分行业的人机权责规则:特别是在医疗、金融、政务、教育和制造等高风险场景,明确"谁授权、谁复核、谁负责"。
- 推进全民 AI 素养与在岗再培训:把 AI 适应力从少数技术岗位的能力,转化为全社会的基础能力。
图 10:AI 国家竞争力的四维结构
国家 AI 竞争力
能源能力
算力能力
数据能力
治理能力
稳定电力 冷却 芯片供应
可负担 可调度算力
高质量行业数据与流通机制
权责规则 标准 合规体系
七、结论:AI 革命的本质,是把"认知"纳入大规模生产体系
核心导读:技术奇观只有与组织能力和制度能力结合,才会变成稳定、可持续的社会生产力。
把两篇文稿综合起来看,最有价值的判断可以归结为一句话:AI 革命不是简单提高某个工具的效率,而是在重构生产力、组织形态和社会分配机制。
它延续了工业革命以来不断追求效率提升的历史趋势,但又明显超出了单纯"能效革命"的范畴。因为这一次,真正被工程化、资本化和平台化的,不只是能源和机器,而是部分认知能力本身。
对企业来说,未来的分水岭不是会不会采购某个模型,而是能否把 AI 变成数据资产、流程资产和组织能力。对个人来说,未来的核心竞争力不再只是"做得多快",而是"定义得多准、判断得多稳、组合得多强"。对国家来说,竞争不只发生在实验室,更发生在能源、算力、数据制度、治理能力和教育体系之中。
因此,AI 革命最深刻的挑战,既不是"机器会不会完全替代人",也不是"生产力会不会自动爆炸",而是:人类能否在效率跃迁的同时,构建与之匹配的新管理逻辑、新分配机制和新文明秩序。
只有当技术能力、组织能力与制度能力同时成熟时,人工智能才会从"惊艳的技术奇观"真正转化为"稳定的社会生产力"。
参考资料
- 潍柴动力,2024 年 4 月 20 日发布全球首款本体热效率 53.09% 柴油机:https://m.en.weichai.com/media_center/jtdt/202404/t20240420_104521.htm
- Google DeepMind, Millions of new materials discovered with deep learning : https://deepmind.google/en/blog/millions-of-new-materials-discovered-with-deep-learning/
- Nature ,Magnetic control of tokamak plasmas through deep reinforcement learning :https://www.nature.com/articles/s41586-021-04301-9
- Nature ,Blinded, randomized trial of sonographer versus AI cardiac function assessment :https://www.nature.com/articles/s41586-023-05947-3
- World Economic Forum, The Future of Jobs Report 2025 :https://www.weforum.org/reports/the-future-of-jobs-report-2025
- 国务院,2025 年 8 月 26 日《关于深入实施"人工智能+"行动的意见》:https://www.gov.cn/zhengce/zhengceku/202508/content_7037862.htm
- 国务院公报,《国务院关于深入实施"人工智能+"行动的意见》:https://www.gov.cn/gongbao/2025/issue_12266/202509/content_7039598.html
- 国家数据局,2025 年工作要点:https://www.nda.gov.cn/sjj/swdt/sjdt/0428/20250428132338848329482_pc.html
- 中央网信办,《人工智能生成合成内容标识办法》:https://www.cac.gov.cn/2025-03/14/c_1743654685899683.htm
- 科技部等十部门,《科技伦理审查办法(试行)》相关发布:https://www.moe.gov.cn/jyb_xwfb/s5147/202310/t20231011_1085003.html
- Klarna,2024 年 2 月 27 日 AI 客服助手首月数据:https://www.klarna.com/international/press/klarna-ai-assistant-handles-two-thirds-of-customer-service-chats-in-its-first-month/
- Klarna,2025 年 6 月 12 日更新 AI 客服助手与 AI CEO Hotline 数据:https://www.klarna.com/international/press/klarna-opens-direct-line-to-ceo-sebastian-siemiatkowski-powered-by-ai/
- GitHub,Research: quantifying GitHub Copilot's impact on developer productivity and happiness :https://github.blog/news-insights/research/research-quantifying-github-copilots-impact-on-developer-productivity-and-happiness/
- Microsoft Research,GitHub Agentic Workflows :https://www.microsoft.com/en-us/research/project/agentic-workflows/
- Microsoft Learn,Create Autonomous AI Agentic Workflows - Azure Logic Apps :https://learn.microsoft.com/en-us/azure/logic-apps/create-autonomous-agent-workflows
- OpenAI,Knowledge Retrieval: Trusted, cited answers from your data :https://openai.com/solutions/blueprints/knowledge-retrieval/
- OpenAI,Rakuten pairs data with AI to unlock customer insights and value :https://openai.com/index/rakuten-2024/
- Microsoft Learn,Agent Evaluators for Generative AI :https://learn.microsoft.com/en-us/azure/foundry/concepts/evaluation-evaluators/agent-evaluators