Python 数据分析入门:认识回归分析与一元线性回归(附 Python 实战案例)
适合人群:Python 初学者 / 数据分析入门 / 机器学习入门 / 教学案例分享
在学习 Python 数据分析或机器学习时,很多人都会很快接触到一个高频词:
回归分析
第一次看到这个词时,很多初学者都会有点疑惑:
- 回归分析到底是什么?
- 它和分类有什么区别?
- 一元线性回归又是什么意思?
- 为什么总说"用一条直线去拟合数据"?
其实,回归分析并没有想象中那么难。你可以先把它理解为:
根据已有数据,研究变量之间的关系,并用这种关系去预测结果。
比如下面这些问题,本质上都属于回归问题:
- 根据房屋面积预测房价
- 根据学习时长预测考试成绩
- 根据广告投入预测销售额
- 根据温度变化预测用电量
如果你刚开始接触数据分析,这篇文章会带你从最基础的角度,真正搞懂:
- 什么是回归分析
- 回归问题和分类问题有什么区别
- 什么是一元线性回归
- 一元线性回归适合什么场景
- 如何用 Python 完成一个简单的一元线性回归案例
一、什么是回归分析?
在现实生活中,很多现象之间都存在关系。
比如:
- 房屋面积越大,房价通常越高
- 学习时间越长,成绩可能越高
- 广告投入越多,销量往往会发生变化
- 体重变化和血压变化之间也可能存在联系
这些关系中,有些是确定关系 ,有些是非确定关系。
1)确定关系
确定关系指的是变量之间有明确的函数关系。
例如:
- 圆的周长和半径之间就有固定公式
2)非确定关系
非确定关系是指:
- 各变量之间虽然存在依赖关系
- 但无法用一个完全准确的函数来表示
比如:
- 人的血压和体重之间存在密切关系
- 但很难找到一个精确表达这种关系的函数
对于这种"不完全确定"的关系,我们通常需要通过大量观测数据,去发现其中的统计规律。
而这正是回归分析要做的事情。
所以可以把回归分析简单理解为:
利用数据统计原理,研究因变量和自变量之间关系,并建立回归方程用于预测的一种方法。
二、回归分析到底研究什么?
回归分析是一种预测性的建模技术,研究的是:
- 因变量(目标)
- 自变量(预测器)
之间的关系。
说得更直白一点:
- 自变量:用来解释或预测结果的因素
- 因变量:我们最终想得到或预测的结果
例如:
| 场景 | 自变量 | 因变量 |
|---|---|---|
| 房价预测 | 房屋面积 | 房价 |
| 成绩预测 | 学习时长 | 考试成绩 |
| 销售预测 | 广告投入 | 销售额 |
回归分析的作用,不只是"预测一个值",它还能帮助我们:
- 发现自变量和因变量之间是否存在显著关系
- 分析多个自变量对一个因变量的影响强度
这也是为什么回归分析在数据分析、商业分析、经济预测中非常常见。
三、回归和分类有什么区别?
很多初学者最容易混淆的两个概念就是:
- 回归
- 分类
它们都属于预测问题,但预测的目标不同。
回归问题
回归问题中,预测值 y 是一个连续变量。
比如:
- 预测房价:680000 元
- 预测成绩:82.5 分
- 预测销售额:12000 元
这些结果都可以在一定范围内连续变化。
分类问题
分类问题中,预测值 y 是一个离散变量,代表类别。
比如:
- 是否挂科
- 是否患病
- 是否为垃圾邮件
这些结果一般是:
- 是 / 否
- 0 / 1
- A类 / B类 / C类
所以记住一句最关键的话:
回归预测连续值,分类预测离散类别。
四、回归分析一般怎么做?
从整体流程来看,回归分析通常包括以下几个步骤:
- 收集一组包含因变量和自变量的数据
- 根据变量之间的关系,初步设定回归模型
- 求解合理的回归系数
- 进行相关性检验,确定变量之间的关系是否明显
- 利用模型对因变量进行预测或解释
这个流程非常适合初学者建立整体认识。
也就是说,回归分析不是"直接套代码",而是一个完整的数据分析过程:
从数据出发,建立模型,再完成预测和解释。
五、什么是一元线性回归?
回归分析有很多种形式。按照自变量和因变量的个数、因变量的类型以及回归线形状等角度,可以分为一元回归分析、多元回归分析、逻辑回归分析等,而线性回归是其中最基础的方法。
其中,最适合入门的一种就是:
一元线性回归
这个名字可以拆开理解。
1)"一元"是什么意思?
"一元"表示只有一个自变量。
比如:
- 用学习时长预测成绩
- 用房屋面积预测房价
- 用广告投入预测销量
这些场景都只用了一个主要影响因素。
2)"线性"是什么意思?
"线性"表示变量之间的关系,可以近似看成一条直线。
也就是说:
- 自变量变化时
- 因变量也会沿着某种线性趋势变化
3)合起来怎么理解?
一元线性回归分析预测法,是根据自变量 X 和因变量 Y 的相关关系,建立 X 与 Y 的线性回归方程进行预测的方法。
它特别适合这样的场景:
- 在多个影响因素中,存在一个变量对结果的影响明显高于其他因素
- 且变量之间大致呈线性趋势
六、为什么说一元线性回归是在"拟合一条直线"?
这是初学者理解回归时最关键的一步。
假设我们有一组数据:
- 学习时间
- 考试成绩
如果把这些数据画成散点图,你通常会看到一种趋势:
- 学习时间越长,成绩往往越高
虽然所有点并不会刚好落在同一条线上,但整体趋势可能比较明显。
这时候,我们就会尝试:
找一条最合适的直线,尽量贴近这些数据点。
这条直线就叫做回归直线。
它不一定经过每一个点,但它可以用来描述整体变化趋势,并用于后续预测。
所以线性回归最核心的思想就是:
用一条直线去近似表示变量之间的关系。
七、小案例:根据学习时长预测考试成绩
为了让概念更直观,下面我们用一个简单的 Python 小案例来演示一元线性回归。
案例背景
假设我们统计了几位学生每天的学习时长,以及他们对应的考试成绩。
现在想做一件事:
根据学习时长,预测考试成绩。
这是一个典型的一元线性回归问题:
- 自变量
X:学习时长 - 因变量
y:考试成绩
八、Python 实战代码
下面这段代码可以直接运行,适合初学者练习。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 1. 准备数据
# 学习时长(小时)
X = np.array([1, 2, 3, 4, 5, 6]).reshape(-1, 1)
# 考试成绩(分)
y = np.array([50, 55, 65, 70, 78, 85])
# 2. 创建线性回归模型
model = LinearRegression()
# 3. 拟合模型
model.fit(X, y)
# 4. 输出模型参数
print("回归系数(斜率):", model.coef_[0])
print("截距:", model.intercept_)
# 5. 进行预测
pred = model.predict([[7]])
print("当学习时长为 7 小时时,预测成绩为:", pred[0])
# 6. 绘制散点图和回归直线
plt.scatter(X, y, color='blue', label='原始数据')
plt.plot(X, model.predict(X), color='red', label='回归直线')
plt.xlabel("Study Hours")
plt.ylabel("Score")
plt.title("Simple Linear Regression")
plt.legend()
plt.show()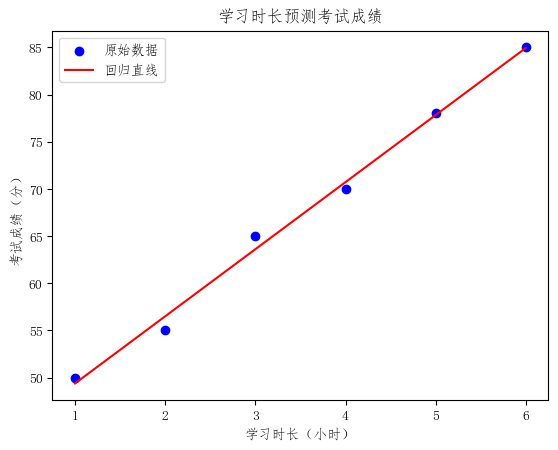
九、代码结果应该怎么理解?
很多初学者第一次跑回归代码时,最大的问题不是"代码不会写",而是:
代码跑出来了,但不知道结果是什么意思。
下面我们简单解释一下。
1)X 和 y 分别表示什么?
python
X = np.array([1, 2, 3, 4, 5, 6]).reshape(-1, 1)
y = np.array([50, 55, 65, 70, 78, 85])这里:
X表示学习时长y表示考试成绩
因为 sklearn 中的模型要求输入特征是二维数组,所以这里用了 .reshape(-1, 1)。
2)model.fit(X, y) 在做什么?
python
model.fit(X, y)这一步表示:
根据已有数据,训练模型,让它找到一条最适合这些数据的直线。
也可以理解为:
- 模型正在学习"学习时长"和"考试成绩"之间的关系
3)回归系数和截距是什么意思?
python
print("回归系数(斜率):", model.coef_[0])
print("截距:", model.intercept_)一元线性回归常见的表达形式可以理解为:
y = ax + b
其中:
a是斜率,也就是回归系数b是截距
它们共同决定了那条回归直线的位置。
如果斜率是正数,通常表示:
- 自变量增大时,因变量也有上升趋势
在这个案例中,就是:
- 学习时长增加,成绩整体呈上升趋势
4)预测结果表示什么?
python
pred = model.predict([[7]])这表示:
- 当学习时长为 7 小时时
- 模型预测考试成绩大概是多少
这正体现了回归分析最核心的用途:
根据已有规律,预测连续值结果。
5)图像怎么看?
代码最后画出了:
- 蓝色散点:原始数据
- 红色直线:回归直线
如果蓝色点大致围绕红线分布,就说明:
- 这组数据存在较明显的线性趋势
- 一元线性回归适合用来描述这种关系
十、一个更贴近教材思路的案例:房屋面积预测房价
除了"学习时长---考试成绩"这个例子,房价预测也是一元线性回归中非常经典的入门案例。资料中也给出了一个类似场景:分析房子的大小(平方英尺)和房价(美元)之间的对应关系。
如果你想把上面的代码场景换成"房屋面积预测房价",可以直接这样写:
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 房屋面积(平方英尺)
X = np.array([800, 1000, 1200, 1400, 1600, 1800]).reshape(-1, 1)
# 房价(美元)
y = np.array([6450, 7450, 8450, 9450, 11450, 15450])
model = LinearRegression()
model.fit(X, y)
print("回归系数(斜率):", model.coef_[0])
print("截距:", model.intercept_)
pred = model.predict([[2000]])
print("面积为 2000 平方英尺时,预测房价为:", pred[0])
plt.scatter(X, y, color='blue', label='原始数据')
plt.plot(X, model.predict(X), color='red', label='回归直线')
plt.xlabel("House Size")
plt.ylabel("Price")
plt.title("House Price Prediction")
plt.legend()
plt.show()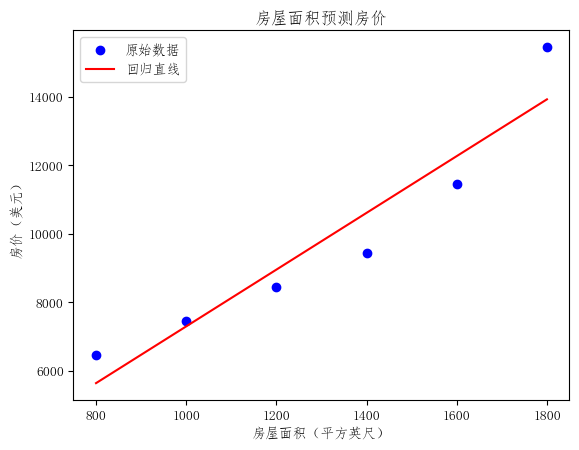
这个例子更容易帮助我们理解:
- 面积越大,房价通常越高
- 虽然每套房子的价格不会完全一致
- 但整体趋势可以尝试用一条直线来刻画
这正是一元线性回归的典型应用场景。
十一、一元线性回归适合什么样的问题?
一元线性回归更适合下面这类场景:
1)有一个主要影响因素
虽然现实问题通常受多个因素影响,但如果有一个因素特别关键,就可以先用一元线性回归做初步分析。
例如:
- 面积对房价影响明显
- 学习时长对成绩影响明显
2)变量之间大致呈线性关系
也就是说:
- 自变量增加时,因变量整体上升或下降
- 数据趋势大致接近一条直线
如果关系明显弯曲,或者变化方式很复杂,那么简单的线性模型可能就不太适合了。
十二、初学者最容易踩的坑
坑1:只要有两个变量就一定能做回归
不一定。
回归分析的前提是变量之间要有一定关系。
如果两个变量根本没有关联,建立回归模型也没有意义。
坑2:一元线性回归适合所有预测问题
不是。
它适用于:
- 一个主要自变量
- 且关系近似线性
如果问题中影响因素很多,就更适合用多元线性回归。
坑3:把回归和分类混淆
再记一次:
- 预测成绩、房价、销量:回归
- 判断是否挂科、是否患病:分类
坑4:学会代码就等于学会回归
这也是很多初学者经常遇到的问题。
真正重要的不只是会写:
python
model.fit(X, y)而是要理解:
- 为什么这个问题适合回归
- 为什么是一元
- 为什么可以用直线来拟合
- 预测结果是不是合理
十三、给初学者的记忆口诀
这部分可以先记住下面几句话:
- 回归分析研究自变量和因变量之间的关系。
- 回归预测连续值,分类预测离散类别。
- 一元线性回归是一个自变量预测一个因变量。
- 线性回归的核心思想,是用一条直线拟合数据趋势。
- 回归不仅能做预测,还能帮助分析变量影响。
十四、练习题:适合课堂,也适合自学
练习1:判断是不是回归问题
下面哪些属于回归问题?
- 预测某学生期末成绩
- 判断某学生是否挂科
- 预测某套房子的价格
- 判断某封邮件是否垃圾邮件
练习2:找出自变量和因变量
请判断下列场景中哪个是自变量,哪个是因变量:
- 用学习时长预测成绩
- 用房屋面积预测房价
- 用广告投入预测销售额
练习3:修改案例数据
请把上面的案例改成你熟悉的业务场景,例如:
- 每天运动时间与体重变化
- 复习时长与测试成绩
- 商品广告投入与销售额
观察回归直线能否反映数据整体趋势。
十五、总结
回归分析是一种预测性的建模方法,主要研究的是:
- 因变量
- 自变量
之间的关系,并通过建立回归模型对结果进行预测或解释。
其中,一元线性回归是最基础的一类回归方法。
它适用于:
- 一个主要自变量
- 一个因变量
- 且变量之间大致呈线性关系的场景
通过这篇文章,我们主要建立了下面几层理解:
- 什么是回归分析
- 回归和分类有什么区别
- 什么是一元线性回归
- 为什么说它是在"拟合一条直线"
- 如何用 Python 完成一个简单的线性回归案例
对于初学者来说,最重要的不是立刻去记复杂公式,而是先理解:
什么问题适合做回归,为什么可以用一条直线来描述数据趋势。
十六、写在最后
如果你正在学习 Python 数据分析,建议先把一元线性回归这部分真正理解透。
因为后面很多内容,都是建立在它的基础之上的,比如:
- 多元线性回归
- 逻辑回归
- 多项式回归
- 岭回归
- Lasso 回归
- 弹性回归
- 逐步回归
只要你把"回归预测连续值""一元表示一个自变量""线性表示直线趋势"这三个点想清楚,后面的学习就会顺很多。