CAN 总线传输策略
1. 方案概述
本方案采用 基于 CAN ID 优先级竞争 + 本节点低优先级事件让步 策略,
重点是在保障高优先级命令/事件响应时间要求的前提下,对低优先级事件进行本地抑制,
从而缓解多节点事件风暴下的总线压力。
该方案并不以精确控制系统总线占用率为目标,而是聚焦以下三个问题:
- 尽可能缩短 高优先级命令/事件 的最坏响应时间
- 降低本节点低优先级事件对总线的持续占用
- 当检测到多节点低优先级事件风暴 时,主动抑制本节点 低优先级事件队列 的发送速率
本方案采用的 CAN 总线基础参数如下:
| 参数名称 | 参数取值 |
|---|---|
| 系统规模 | 32 节点 |
| 总线速率 | 20 kbps |
| 帧类型 | 扩展帧(Extended Frame) |
2. 设计目标与设计判据
本方案将总线占用率作为容量评估和参数设计时的工程参考,但不把它作为最终设计目标 。
对本方案而言,更重要的是以下判据:
- 高优先级命令/事件的最坏响应时间是否满足要求
- 低优先级事件在总线重载情况下出现更长时延时,系统是否仍可接受
- 当出现多节点低优先级事件风暴时,节点本地抑制是否足以显著降低本节点的发送压力
因此,方案是否成立,不能只看某个固定总线占用率,而应综合以下因素判断:
- 容量基线是否为参数设计提供了合理约束
- 高优先级命令/事件的响应时间是否优先得到保障
- 低优先级事件的本地抑制是否在风暴场景下有效
3. 方案主体
本系统采用 基于优先级竞争 + 节点本地低优先级让步 作为实现基线。
其基本取舍如下:
- 高优先级关键命令/事件的响应时间保障是第一目标
- 设计接受低优先级事件在重载下出现更长时延
3.1 核心原则
在发送路径上,所有节点仍通过原生 CAN ID 优先级竞争总线。
重要实现要求:
- 每个节点的本地发送路径必须保持优先级语义
- 本地待发送消息中优先级最高者必须进入 CAN 总线仲裁
- 如果本地 FIFO 发送行为破坏上述假设,则该实现不可接受
- 一个应用层事件可以由一个或多个 CAN 帧构成
- 同一事件内的帧按原生 CAN 竞争发送
T_yield仅在低优先级事件完整发送结束后应用
3.2 队列结构
每个节点维护两个发送队列:
HighPriorityQueueLowPriorityQueue
队列选择规则:
- 若
HighPriorityQueue非空,始终从HighPriorityQueue发送 - 仅当
HighPriorityQueue为空时,LowPriorityQueue才可发送
这形成了严格的两级本地优先级结构。
3.3 高优先级事件发送规则
高优先级事件发送规则如下:
HighPriorityQueue始终使用T_yield = 0- 同一事件内的帧之间绝不插入
T_yield - 高优先级事件在原生 CAN 仲裁下逐帧连续发送
- 一个高优先级事件完成后,若
HighPriorityQueue仍非空,可立即继续下一个高优先级事件
含义:
- 高优先级关键命令/事件保留最强的原生 CAN 优先级优势
- 该方案有意不为高优先级事件引入主动退让等待
3.4 低优先级事件发送规则
低优先级事件发送规则如下:
T_yield仅 作用于LowPriorityQueue- 同一低优先级事件内的帧之间不 插入
T_yield T_yield仅在整个低优先级事件发送完成后应用
含义:
- 低优先级事件在事件内部保持连续发送
- 节点本地让步仅发生在低优先级事件边界
- 发送抑制的目标是限制本节点低优先级事件的持续发送速率,不是实现全局公平
3.5 事件发送流程
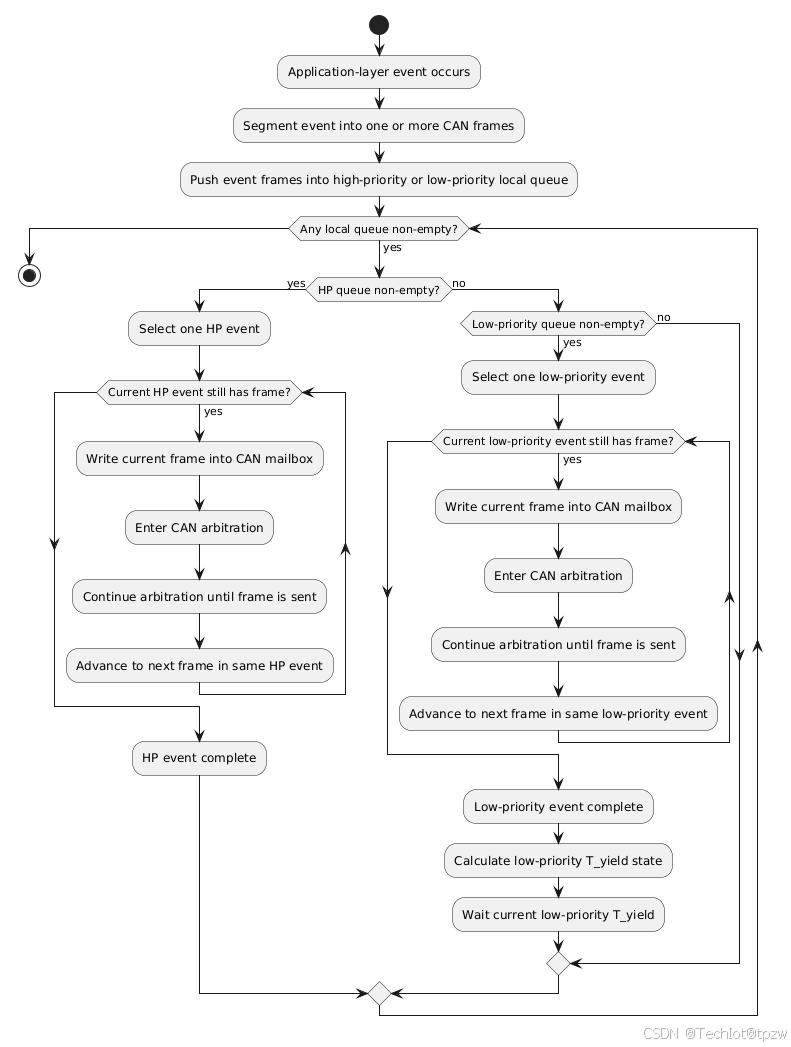
3.6 T_yield 的含义
T_yield 用于:
- 降低本节点低优先级事件 对总线的持续占用,是节点本地低优先级发送抑制
- 在参与多节点低优先级事件风暴时,降低本节点的发送压力
- 在低优先级事件完成后,给其他节点和更高优先级事件更多仲裁机会
- 它不是用于总线占用率的闭环控制
4. 运行时观测与状态机
为了判断何时需要对低优先级事件加大抑制,所选实现采用基于帧计数的轻量观测模型。
4.1 观测窗口
观测周期: 500ms
4.2 有效接收帧计数
rxFrames 不是 接收到的全部 CAN 帧原始计数。
rxFrames 表示当前观测窗口中,经过应用层过滤后的有效事件接收帧 计数。
它排除不应参与低优先级事件风暴判定的帧,包括:
- reply / response 类帧
- 高优先级事件帧
- 其他按应用层策略排除的事件类别
因此,rxFrames 是用于风暴判定的观测变量,不是总线抓包原始计数。
4.3 本节点发送成功帧计数
selfTxFrames 表示当前观测窗口内,本节点成功发送的帧数量。
4.4 总观测总线帧数
计算公式:busFrames = rxFrames + selfTxFrames
这是用于当前低优先级事件风暴判定的总帧活动工程近似值。
4.5 总线忙碌度估计
基于工程近似 8 ms/frame :
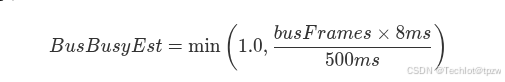
这是忙碌度估计值,不是物理层总线占用率测量。
其目的是判断总线是否已进入高活动状态,以驱动低优先级发送抑制决策。
4.6 低优先级事件 T_yield 状态机
4.6.1 Normal 状态
默认状态:
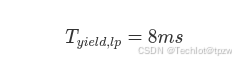
含义:
- 总线尚未达到风暴级忙碌状态
- 低优先级事件仅使用小幅事件后本地让步
4.6.2 Busy-Self 状态
进入 Busy-Self 条件:
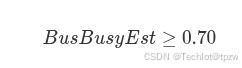
且 Storm-MultiNode 不满足。
动作:
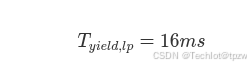
含义:
- 总线已经较忙
- 但当前窗口尚未满足完整多节点风暴条件
- 因此对低优先级事件做中等强度抑制
4.6.3 Storm-MultiNode 状态
确认最终条件集:

三者同时满足则进入 Storm-MultiNode。
动作:
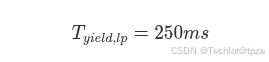
含义:
- 总线已处于高忙碌状态
- 其他节点仍持续发送有效事件
- 本节点在当前窗口内也表现出持续参与
- 因此判定本节点参与了多节点持续低优先级事件风暴
- 本节点低优先级事件必须被强抑制
4.6.4 Storm-MultiNode 状态维持
Storm-MultiNode 不是一次进入后永久保持 ,而是基于当前 500 ms 观测窗口持续重评估。
也就是说,每经过一个新的观测窗口,节点都会重新计算:
BusBusyEstrxFramesselfTxFrames
只要这三个条件在新的观测窗口中仍同时满足,节点就继续保持 Storm-MultiNode 状态,并继续使用:
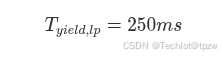
在 32 节点持续低优先级事件积压场景下,这种状态具有较强的自维持性。
原因是:
- 在
T_{yield,lp} = 250 ms时,单节点本地输出上界约为3.88 frames/s - 换算到一个
500 ms观测窗口内,单节点平均约可发送1.94帧 - 对 32 节点系统而言,这意味着持续参与发送的节点在连续观测窗口中较容易接近或达到
selfTxFrames >= 2 - 同时,多节点并发发送使
rxFrames >= 8与BusBusyEst >= 0.70也较容易持续满足
因此,在多节点持续低优先级事件风暴尚未缓解之前,Storm-MultiNode 通常具有较强的维持趋势,但并不意味着所有节点都会在每个窗口内稳定满足该条件。
该状态的退出条件也同样明确:只要后续观测窗口中任一条件不再满足,节点就会退回到较低抑制状态,而不是继续保持 250 ms 让步。
5. 参数依据与模型验证
本节给 T_yield 参数和 32 节点系统验证进行理论推导。
5.1 CAN 总线容量基线
工程基线如下:
- 扩展帧平均长度:约 160 bit (按 CAN 2.0B 扩展数据帧 + 8 字节数据 估算的工程近似值)
- 帧发送时间:160 / 20000 ≈ 8 ms
- 理论最大吞吐:20000 / 160 ≈ 125 frames/s
- 建议稳定工程吞吐预算:约 75 frames/s
基于上述假设,可得到以下结论:
- 总线在物理满载下约可承载 125 frames/s
- 为给仲裁抖动、事件突发和系统余量留出空间,长期工程预算更适合按 75 frames/s 估算
- 最终是否可接受,仍取决于仲裁、优先级分配、队列行为以及关键消息的最坏响应时间要求
需要说明的是,状态机中的 BusBusyEst >= 0.70 不是"稳定工程预算"门限,而是"高忙碌状态"识别门限。按当前近似模型,它约对应 87.5 frames/s。因此,该门限的作用是识别总线已进入明显繁忙区间,并触发更强的本地低优先级发送抑制,而不是把系统长期控制在 75 frames/s 附近。
5.2 32 节点模型验证
5.2.1 单节点低优先级事件注入模型
对于持续低优先级事件积压、且低优先级事件按单帧模型处理 的节点,其本地输出上限近似为:
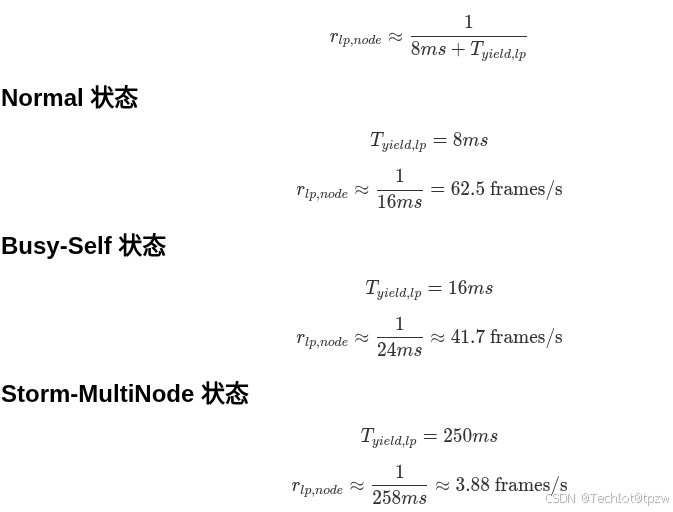
在单帧低优先级事件模型下,这意味着:
- 进入 Storm-MultiNode 后,单节点低优先级事件输出能力降至其
125 frames/s(无让步本地理论上限)的约 1/32 - 或降至
8ms让步本地速率62.5 frames/s的约 1/16 - 从工程角度看:该节点持续向总线叠加低优先级发送压力的能力显著下降
5.2.2 32 节点全低优先级事件积压验证
若 32 节点均处于 Storm-MultiNode 且持续低优先级事件积压:
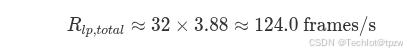
该值约等于物理总线上限 125 frames/s 。
因此:
T_yield = 250 ms足以在理论上显著压低单节点的持续低优先级事件发送能力- 在 32 节点同时持续积压的极端场景下,总注入速率仍可能接近物理上限,因此该结果不应被理解为"系统一定保留了充足余量"
- 这项分析验证的是 Storm-MultiNode 下本地抑制强度具备工程可行性,而不是系统总线一定处于理想负载区间
5.2.3 验证的工程含义
需要明确的是,该验证不证明系统始终处于低负载。
它证明的是一个更具体、也更有工程价值的结论:
- 当节点被确认参与多节点低优先级事件风暴时,将低优先级事件后让步切换为 250 ms,足以显著降低该节点的低优先级发送压力
- 若 32 节点系统内所有风暴参与节点都执行相同策略,可以确认每个节点的持续施压能力都被显著压低,但这并不等价于系统总线一定保留了充分余量
简而言之:
- 低优先级事件本地让步机制是有效的
- 它的效果是强本地抑制,不是总线占用率精确控制
6. 可靠性边界
6.1 CAN ACK
CAN 发送成功仅表示总线上至少一个节点 对该帧进行了 ACK。这不代表主机应用已接收并处理该事件。
6.2 自动重发
若控制器级 CAN 发送失败,硬件自动重发可用于恢复瞬态总线错误。
6.3 事件序号
每个事件帧应包含:
NodeIDSeq
主机通过序号连续性检测事件丢失或重复。
6.4 心跳
每个节点应周期发送心跳,用于主机侧的节点存活和序列进度异常检测。
6.5 可靠性设计边界
本方案不引入应用层 ACK。
因此,当前最小可靠性机制为:
- CAN 硬件 ACK
- 自动重发
- 每事件
Seq - 主机侧连续性检查
- 基于心跳的存活观测
该机制用于:
- 异常检测
- 事件可见性监控
它不是严格的应用层端到端确认机制。
7. 方案摘要
综上所述,传输策略可概括为:
-
节点维护:
HighPriorityQueueLowPriorityQueue
-
HighPriorityQueue始终具有绝对本地优先级 -
HighPriorityQueue始终使用:
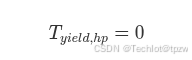
-
同一事件内帧之间不插入
T_yield -
T_yield仅在低优先级事件完整发送后应用 -
观测窗口:500ms
-
帧活动估计: busFrames = rxFrames + selfTxFrames
-
总线忙碌估计:
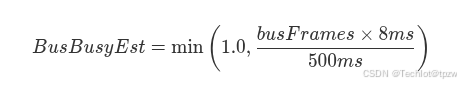
-
rxFrames为应用过滤后的有效事件帧计数,排除 reply 类帧、其他按策略排除的事件类别以及高优先级事件帧 -
低优先级事件
T_yield状态值:
- Normal:
8 ms - Busy-Self:
16 ms - Storm-MultiNode:
250 ms
- Storm-MultiNode 进入条件(同时满足):
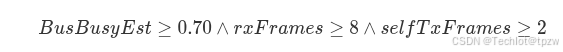
T_yield的作用是抑制本节点低优先级事件的连续发送行为,不是精确控制全网总线占用率- 整体时间表现是否可接受,仍应结合以下因素评估:
- 高优先级关键命令/事件的最坏响应时间
- CAN ID / 优先级分配质量
- 本地队列正确性
- 事件积压容忍度
最终设计结论如下:
- 使用该策略作为系统传输基线,后续根据现场实际情况进行调优
- 使用节点本地低优先级让步发送抑制作为风暴控制机制