RAG = Retrieval-Augmented Generation
检索增强生成。
它的核心思想是:
先从外部知识库检索相关知识,再把这些知识丢给大模型,让大模型基于检索到的内容生成回答。
一句话总结:让大模型"开卷考试",而不是"凭记忆瞎编"。
为什么会有RAG?
大模型本身就像一个学过很多知识,但容易记混、爱胡说八道 的人。直接问它,它可能编造答案、过时、不准确。
就是说模型有两个硬伤:
- 一是知识有滞后性,训练数据截止到某个时间点,不知道最近的事;
- 二是不懂私有数据,压根没见过你公司的内部文档。
RAG就是为了解决这两个问题。
而 RAG 就是:
- 先把我们自己的文档、资料、知识库存起来;
- 用户提问时,先去库里查相关内容;
- 把查到的资料丢给大模型;
- 让大模型只根据这些资料回答,不许自己瞎编。
作用:
- 不胡说八道(减少幻觉)
- 能用最新/私有数据
- 可控、可追溯、可解释
简单来说就是利用外部知识动态补充模型生成能力 ,既能保证回答的准确性,又能在知识库更新时及时反映最新信息 。另外部分业务是内部文档,网上压根没有,可以通过本地知识库来增强 AI的能力。
RAG简单工作流程
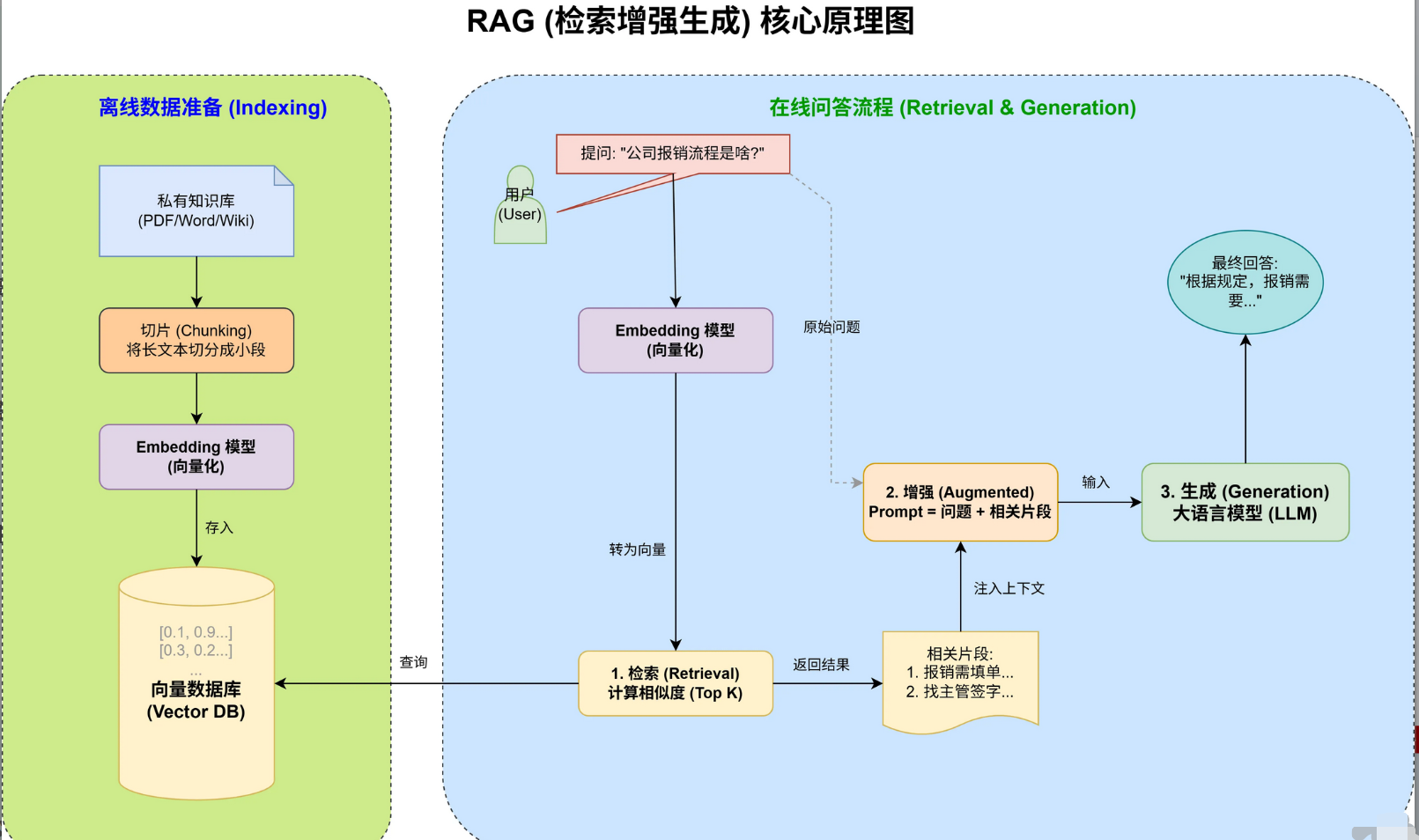
RAG 分为三个核心阶段:
索引构建(离线): 将文档切片 → 向量化 → 存入向量库 / ES。
检索(在线):用户问题向量化 → 相似度检索 → 召回相关知识片段。
生成(在线):将问题 + 检索片段拼接成 Prompt → 大模型生成答案。
整个流程分三步:
第一步是文本向量化。
- 用语义模型把文档和问题转成高维向量(文档切片 → 向量化 ) ,常用的有OpenAI的 text-embedding-3-small/large 等,用Milvus这类向量数据库存储所有文档向量( 存入向量库/ES)。
第二步是向量数据库检索(检索)。
- 用户提问后对问题做向量化(用户问题向量化 ) ,然后在数据库里做最近邻搜索(相似度检索),找出语义最相近的N条内容 ( 召回相关知识片段)。
第三步是构建Prompt (增强)和生成回答(生成)。
- 把用户原始问题 和检索到的内容拼接成上下文输入(问题 + 检索片段拼接成 Prompt),由GPT、Gemini这类大模型综合上下文生成最终输出(大模型生成答案)。
RAG局限性
RAG不是万能的,有几个坑要注意:
1**)检索质量决定上限**。
- 如果向量数据库里的文档本身质量差 或者Embedding模型语义理解不到位,检索出来的东西就是垃圾,大模型再厉害也没用
2)上下文窗口有限。
- 大模型的输入长度是有限的,GPT-5虽然支持400K,但检索出来的内容太多塞不下,就得做截断或者Rerank3)实时性受限于索引更新。
- 知识库更新后需要重新做Embedding入库,如果索引更新不及时,还是会答出过时的内容
RAG 和 Fine-tuning(微调) 区别?
-
微调是给模型"洗脑",微调是改模型权重,成本高、难更新;
-
- 微调是把知识"刻"进模型参数 里,适合需要改变模型行为风格或者学习特定任务模式的场景,比如让模型用特定语气说话。
- 微调一次成本高、知识更新要重新训练;
-
**RAG 是给模型"开卷"。**RAG 不改模型,只查外部知识 ,轻量、实时、安全、易维护。
-
- RAG是把知识放在外部,适合知识会频繁更新、需要引用来源、或者私有数据量大的场景。
- RAG只需要更新知识库,模型不用动。
-
如果你的场景是"让模型知道更多事实",选RAG ;如果是"让模型换一种方式说话",选微调。
一些疑问解决
提问:如果检索出来的文档片段太多,超过了大模型的上下文窗口怎么办?
回答:常见做法有三种。
- 一是做Rerank(重排) ,用一个排序模型对检索结果重新打分,只保留最相关的Top-K条;
- 二是做摘要压缩,对检索出来的长文档先跑一遍摘要,把信息密度提上去;
- 三是分块处理 ,把问题拆成多个子问题分别检索回答,最后再做汇总。
实际项目里Rerank+Top-K截断是最常用的组合。
提问:向量检索找到的内容语义相近,但可能不是真正相关的,怎么解决?
回答:这是语义检索的经典问题,向量相似不等于真正相关。常见解决方案:
- 一是混合检索,把向量检索和关键词检索结合起来,用BM25这类传统检索(es)补一刀;
- 二是加Rerank层(重排) ,用交叉编码器对候选文档做精排,过滤掉语义漂移的结果;
- 三是优化分块策略 ,文档切得太碎 容易丢上下文,切得太大 又不够精准,需要根据业务调整chunk size 和 overlap。
总结
RAG 是检索增强生成,核心是先检索、再生成 。
传统大模型容易出现幻觉,而 RAG 会先从私有知识库中召回相关文档片段,再交给大模型生成回答,让模型基于事实作答 ,提高准确性、可控性和可解释性。
我在之前知识库项目里就是用 RAG 架构,结合向量检索与大模型,实现基于私有文档的可靠智能问答。