
【新智元导读】深夜,OpenAI 祭出「双子星」GPT-5.4 mini 和 nano,实力逼近满血版,速度性价比拉满,用来编码、当「龙虾」主力真香!
OpenAI 一声不吭,又扔了一颗炸弹。
今天,GPT-5.4 mini 和 GPT-5.4 nano 正式发布。
没有预热,没有倒计时,直接上线。
这两个模型要解决的问题很明确:在真实的生产环境里,怎么让 AI 又快又准又便宜地干活?
它们继承了 GPT-5.4 核心优势,速度拉满、成本更低,堪称轻量级模型巅峰之作。
先说最炸裂的数字------
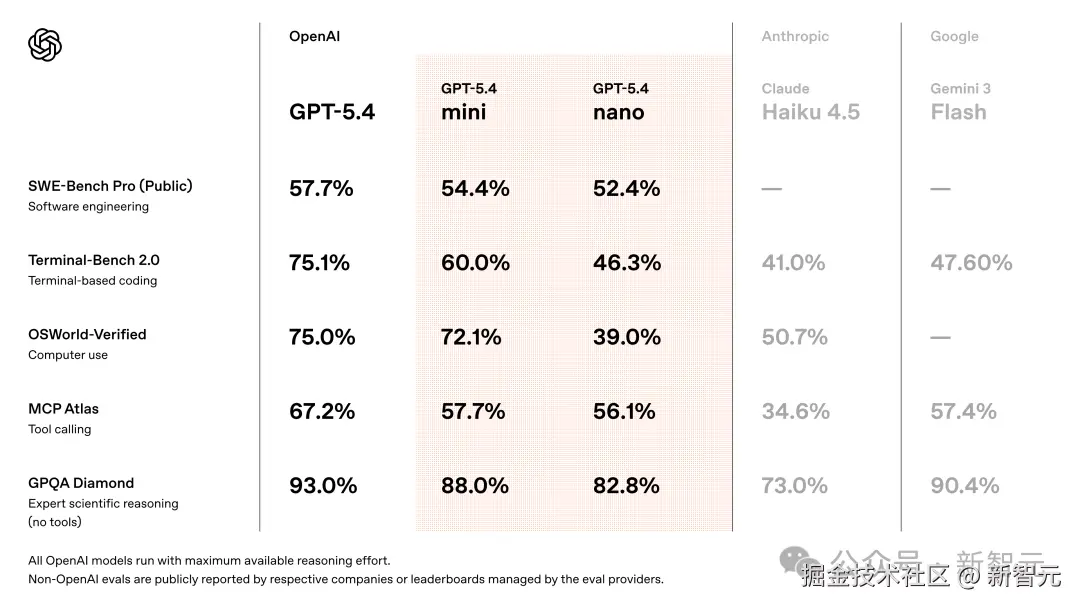
编码(SWE-Bench Pro):GPT-5.4 mini 拿下 54.4%,而满血版 GPT-5.4 是 57.7%;
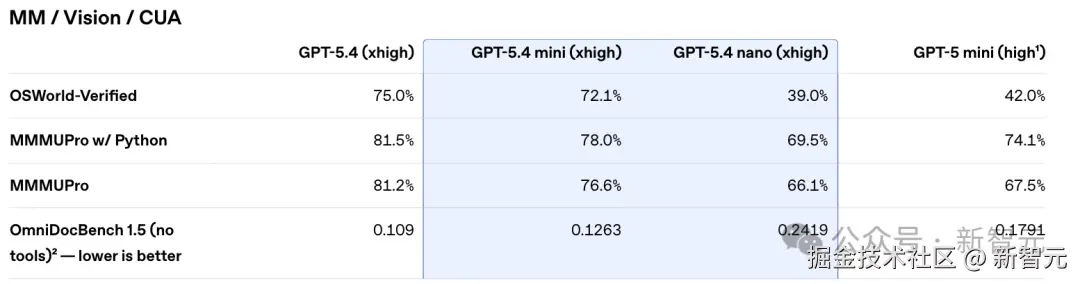
计算机使用(OSWorld-Verified):GPT-5.4 mini 72.1% 的成绩,媲美 GPT-5.4(75%)
另外,在推理、工具调用等任务中,mini 的实力直接逼近 GPT-5.4。
而且,相较于上一代 GPT-5 mini,GPT-5.4 mini 运行速度直接飙升 2 倍!
网友直言,mini 和 nano 完全可以当做「龙虾」的主力模型来用!

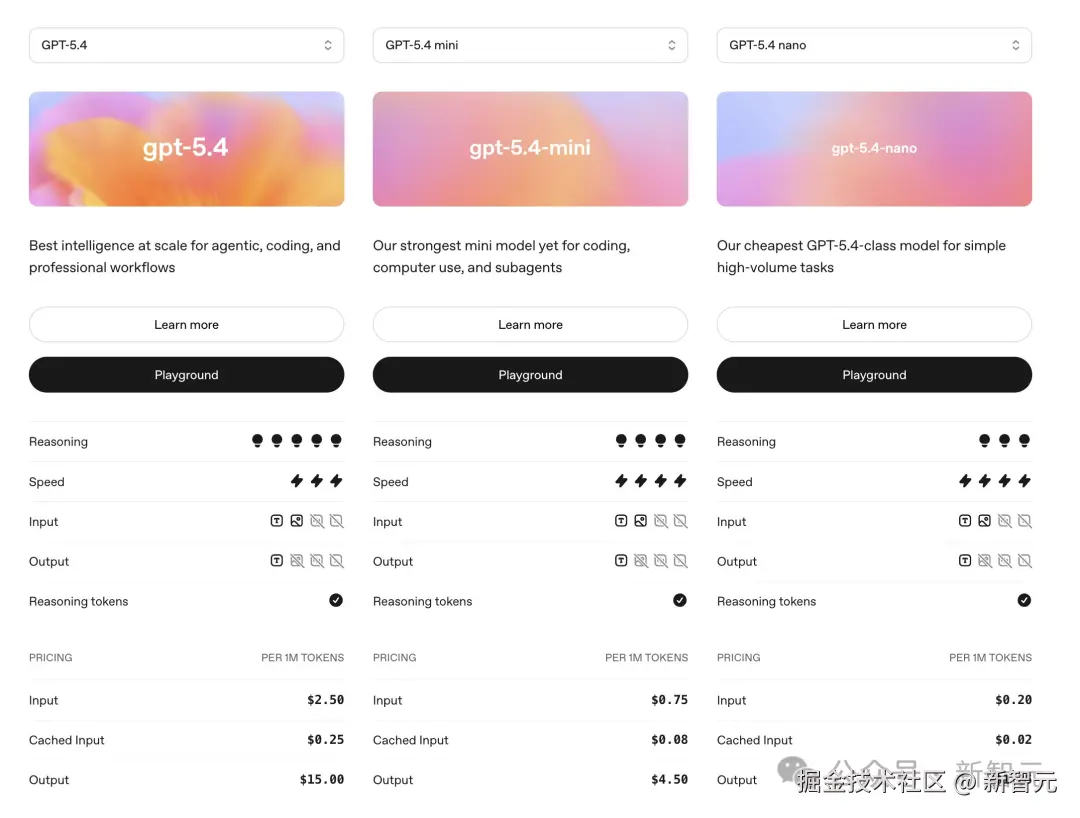
GPT-5.4 mini 有 400k 超大上下文,输入价格 0.75 美元 / 百万 token,输出价格 4.5 美元 / 百万 token;
GPT-5.4 nano 输入价格 0.2 美元 / 百万 token,输出价格 1.25 美元 / 百万 token。
相较于 GPT-5.4,mini 输出价格是其 1/3,而 nano 价格只有 1/12。
如今,快、强、便宜,三个词同时成立了。
而在半年之前,这是完全不可能的。


有人试用后惊叹道,简直太香了!不仅速度快,还要比 Claude 4.6 Opus 便宜 9 倍。


代码恐怖进化
mini 追平「满血」,nano 吊打前代
先看编码。
SWE-Bench Pro 是目前衡量大模型「真实编码能力」最硬核的基准之一,它不考填空题,而是让模型直接修复 GitHub 上的真实软件 Bug。
GPT-5.4 mini 拿下 54.4%,距满血版 GPT-5.4(57.7%)只差 3.3%。
这意味着一个为速度和成本优化的小模型,在解决真实工程问题时,已经摸到了旗舰模型的天花板。
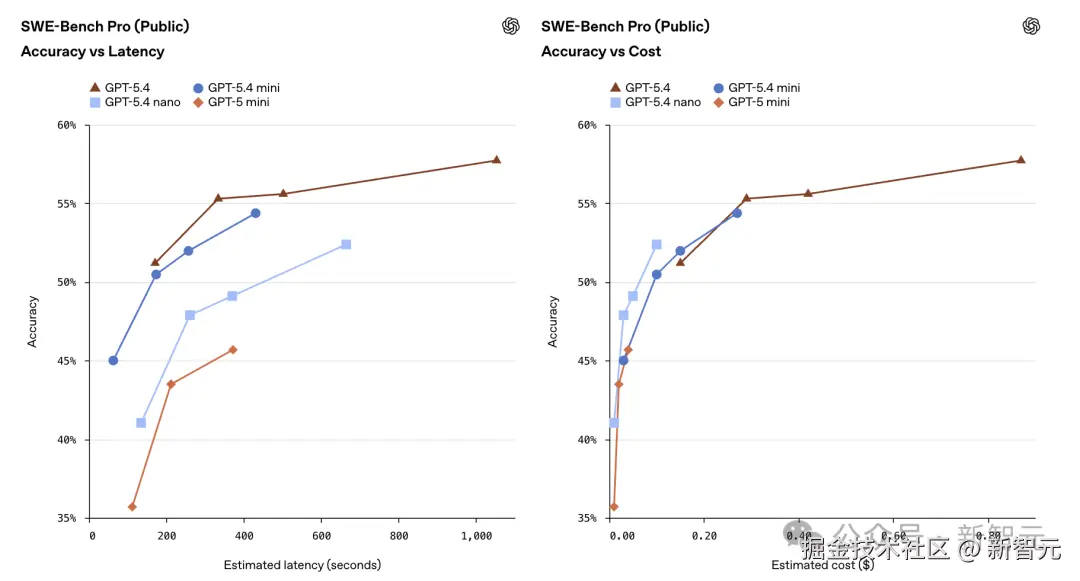
而上一代 GPT-5 mini 仅 45.7%,mini 到 mini 之间,一代之隔就是近 9% 的飞跃。
Terminal-Bench 2.0 的差距更夸张。GPT-5.4 mini 拿下 60.0%,GPT-5 mini 只有 38.2%,提升幅度超过 57%。

即便是最小号的 nano,也在 SWE-Bench Pro 上打出了 52.4%,比上一代 mini 还高出近 7%。
一个定位于「分类和数据提取」的超轻量模型,代码能力居然碾压上一代的中量级选手,这就是蒸馏模型在过去几个月的进化速度。
对开发者来说,这组数据的实际含义非常直接:
那些不需要旗舰模型「满功率思考」的编码任务,比如定向代码修改、前端页面生成、调试循环、代码库检索,现在可以全部交给 mini,速度快一倍,成本低一大截,效果几乎无损。
博士级推理,复杂工具调用双杀
编码只是一个切面,推理和工具调用能力,决定了一个模型能不能真正「干活」。
GPQA Diamond 是一个博士级科学推理基准,GPT-5.4 mini 取得了 88% 的成绩,与 GPT-5.4 仅差 5%。
更值得关注的是「工具调用」能力。
Toolathlon 主要测试模型在复杂工具链中的表现,不只是调一次 API,而是在多步骤任务中正确地组合、排序、使用多种工具。
结果,GPT-5.4 mini 得分 42.9%,完全碾压 GPT-5 mini(26.9%)。

此外,在电信行业专用基准τ2-bench 上,mini 更是打出了 93.4% 的超高分,几乎追平满血版 98.9%,把 GPT-5 mini(74.1%)远远甩在身后。
在另一个工具调用基准 MCP Atlas 上,GPT-5.4 mini 拿到 57.7%,而 GPT-5 mini 只有 47.6%。
这些数字汇成一句话:GPT-5.4 mini 不只是一个「缩小版的聪明模型」,它是一个真正能在生产环境中独立完成复杂任务链的执行者。
「龙虾」主力
小模型也能「看屏幕干活」
GPT-5.4 mini 真正让人意外的,是它在计算机使用上的表现。
人怎么用电脑?眼睛看屏幕上的 UI 元素,大脑判断该点哪里,手去操作鼠标和键盘。
如果 AI 要真正成为你的「赛博助理」,它也得学会这套------快速解析一张信息密集的屏幕截图,定位按钮、输入框和数据列表,然后做出正确操作。
OSWorld-Verified 就是测这个「视觉理解 + 推理 + 操作」三位一体的综合能力的。
在这张榜上,GPT-5.4 mini 拿到了 72.1%,而旗舰版 GPT-5.4 是 75.0%。差距不到 3 个百分点。
反观 GPT-5 mini 只有 42.0%。一代之间,计算机使用能力几乎翻了一倍。
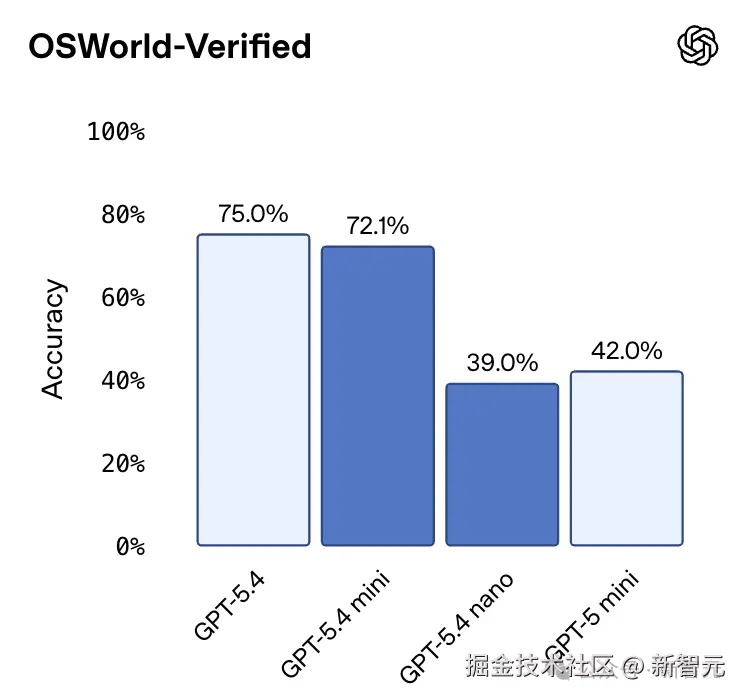
不过,nano 在这项测试中只拿到了 39.0%,甚至略低于上一代 GPT-5 mini 的 42.0%。
这说明计算机使用任务对模型的视觉推理能力有很高的门槛要求,不是单纯缩小模型就能保住的:mini 和 nano 之间存在一道清晰的能力断层。
在 MMMUPro(含 Python 工具)上,mini 拿到 78.0%,旗舰版 81.5%,差距同样很小。
这个基准涵盖了大量需要结合视觉信息和数学 / 代码工具进行推理的复杂题目。
这组结果对一个特定方向有重大意义:AI Agent。
当一个小模型能快速解析信息密集的 UI 截图,并在低延迟下做出正确操作决策时,它就成了构建实时计算机使用 Agent 的理想引擎------成本低,响应快,能力够。
在 TBPN 最新访谈中,奥特曼明确了下一步愿景:
OpenAI 将推出一个进化版的 Codex,新版本不再局限于编程,将演变成一个「控制计算机」的强大工具。
在他设想中,人们可以完全通过手机启动并管理新任务,真正的终极体验是,拥有一个基于统一后端的个人专属的 AI。
它能访问个人所有数据、想法、素材、记忆,并能跨越多个终端,无缝执行任务
子智能体范式
大模型决策,小模型执行
这次发布中,OpenAI 花了不少篇幅阐述一个理念:最好的 AI 系统,不一定要用最大的模型来处理所有事情。
他们提出的架构思路很清晰:
旗舰模型 GPT-5.4 负责规划、协调和最终决策,然后把具体任务分发给 GPT-5.4 mini 子智能体并行执行。
搜索代码库、审查大型文件、处理支持文档,这些不需要「深度思考」但需要「快速完成」的工作,全部交给 mini。

在 Codex 中,这套架构已经落地了。
开发者可以让 GPT-5.4 制定整体方案,然后自动调度 mini 子智能体去执行各个子任务。
而且 mini 在 Codex 中只消耗 GPT-5.4 配额的 30%。
也就是说,同样的预算,你可以跑三倍多的 mini 任务。

这种「分层调度」的思路,其实是整个 AI 行业正在收敛的共识。
与其追求一个无所不能的超大模型,不如构建一个分工明确的模型协作系统。
旗舰模型像总指挥,mini 模型像执行团队,nano 模型像处理琐碎事务的助理。
对开发者来说,这意味着架构设计的思路要变了。
以前是「选一个最强的模型,所有任务都扔给它」;现在是「根据任务复杂度,动态路由到不同层级的模型」。
Hebbia 的 CTO Aabhas Sharma 给出的评价很有代表性:
GPT-5.4 mini 在多项输出任务和引用召回率上,以低得多的成本匹敌甚至超越了竞品模型,还实现了比更大模型更高的端到端通过率。
「更小的模型,更好的效果」,这句话放在两年前像是天方夜谭,现在已经成了工程实践中的真实场景。
全面铺开,免费用户也能用
今天,GPT-5.4 mini 已经全线上线,API、Codex、ChatGPT 三端同步开放。
API 定价为输入 0.75 美元 / 百万 Token,输出 4.50 美元 / 百万 Token,上下文窗口 400K。
支持文本和图像输入、工具使用、函数调用、网络搜索、文件搜索、计算机使用等全套能力。
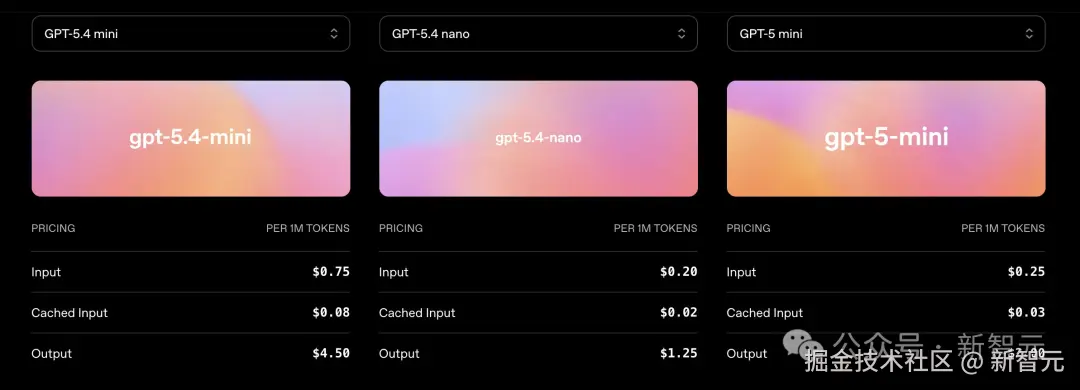
GPT-5.4 nano 仅在 API 中可用,价格为输入 0.20 美元 / 百万 Token,输出 1.25 美元 / 百万 Token。
做个对比。GPT-5.4 nano 的输入价格是 mini 的约四分之一,输出价格也不到 mini 的三分之一。
对于分类、数据提取、排序这类高频但低复杂度的任务来说,nano 的性价比几乎无敌。
在 ChatGPT 端,GPT-5.4 mini 已向免费用户和 Go 用户开放,可以通过菜单中的「Thinking」功能使用。对于付费用户,当 GPT-5.4 Thinking 额度耗尽时,mini 会自动作为降级备选方案。
这个策略很聪明,让免费用户也能体验到强大的推理能力,降低使用门槛的同时扩大用户基盘。
而对付费用户来说,mini 的存在让「额度焦虑」大大缓解。
长上下文是 mini 的短板
当然,mini 不是没有弱点。
在长上下文处理上,GPT-5.4 mini 和旗舰版的差距比其他维度更明显。
OpenAI MRCR v2 测试在 64K-128K 窗口下的 8 针搜索任务中,GPT-5.4 拿到 86.0%,mini 只有 47.7%,差距接近 40 个百分点。在 128K-256K 窗口下,这个差距进一步拉大到 79.3% 对 33.6%。
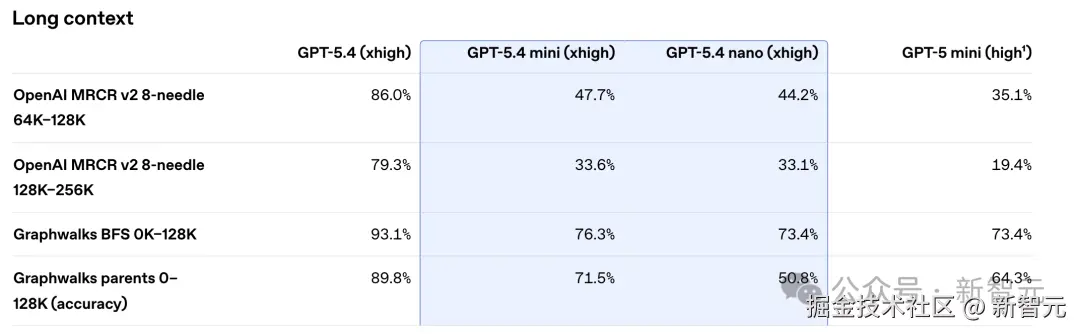
Graphwalks 系列测试也呈现类似趋势。在父节点追踪任务上,GPT-5.4 拿到 89.8%,mini 是 71.5%。
这说明在需要对超长文本进行精确信息检索和逻辑追踪的场景下,mini 的能力上限还是显著低于旗舰版。
对于需要处理大规模文档分析、长对话记忆保持等任务的开发者来说,GPT-5.4 仍然是不可替代的选择。
不过话说回来,这也恰好印证了 OpenAI 的产品分层逻辑:不同的任务,用不同的模型。
mini 不需要在每个维度都追平旗舰,它只需要在自己主攻的方向------速度、编码、工具调用、计算机使用,做到足够好就行。
不是结局,是起点
技术在狂奔,但人的情绪要复杂得多。
今早,奥特曼在 X 上发文:
我对那些逐字逐句写出极其复杂软件的人,充满感激。
现在已经很难想象那曾经需要多大的努力了。谢谢你们把我们带到了今天。
评论区瞬间炸了。
大量开发者读出了另一层意思------感谢你们的贡献,但这个活以后 AI 来干了。
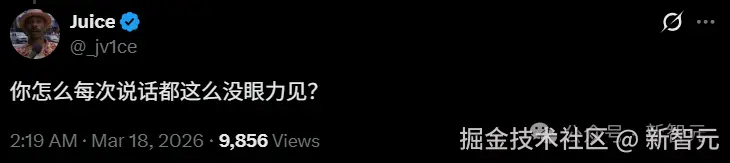
有人回怼:谢谢啊,原来我们的回报就是丢掉工作。
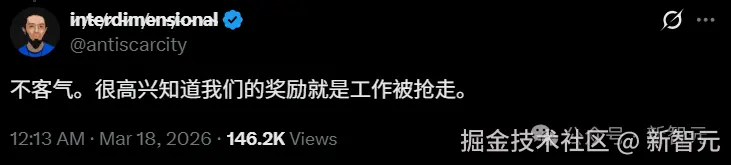
也有人直指训练数据争议:模型本身就是用这些开发者的代码喂出来的,现在反过来替代他们,这算哪门子感激?

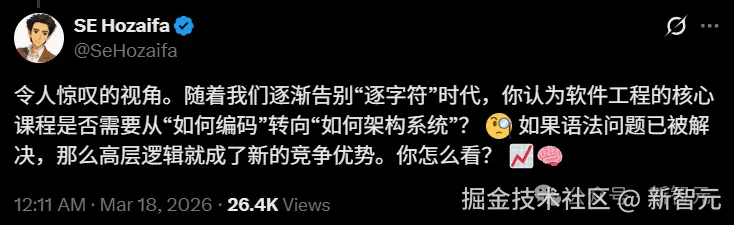
不过也有人借此提了个值得思考的问题:
当语法层面被 AI 解决,软件工程的核心竞争力是不是该从「怎么写代码」转向「怎么设计系统」?
争议归争议,趋势不会因为情绪而停下。
回望科技史,从大型机到 PC,从拨号上网到移动互联网,每一次真正的技术革命都不是靠最强最贵的产品完成的。
革命完成的标志,是技术变得像水和电一样------廉价、无感、无处不在。
GPT-5.4 mini 在 SWE-Bench Pro 上追到了旗舰版的 94%,在 OSWorld 上追到了 96%,在 GPQA Diamond 上追到了 95%。速度是前代的两倍,成本是旗舰版的零头。
- 对普通开发者来说,这意味着曾经只有大厂才玩得起的 AI 能力,现在用 mini 的价格就能接入。
- 对 AI 应用创业者来说,这意味着产品的推理成本可以再降一个数量级。
- 对整个行业来说,这意味着 AI 的渗透速度将进一步加快,因为挡在前面的成本和延迟两道墙,正在被小模型一砖一砖地拆掉。
大模型负责思考,小模型负责执行。旗舰模型定义智力的天花板,小模型打通 AI 走进每一个应用的毛细血管。
这不再是愿景,而是今天就能跑起来的架构。
参考资料: